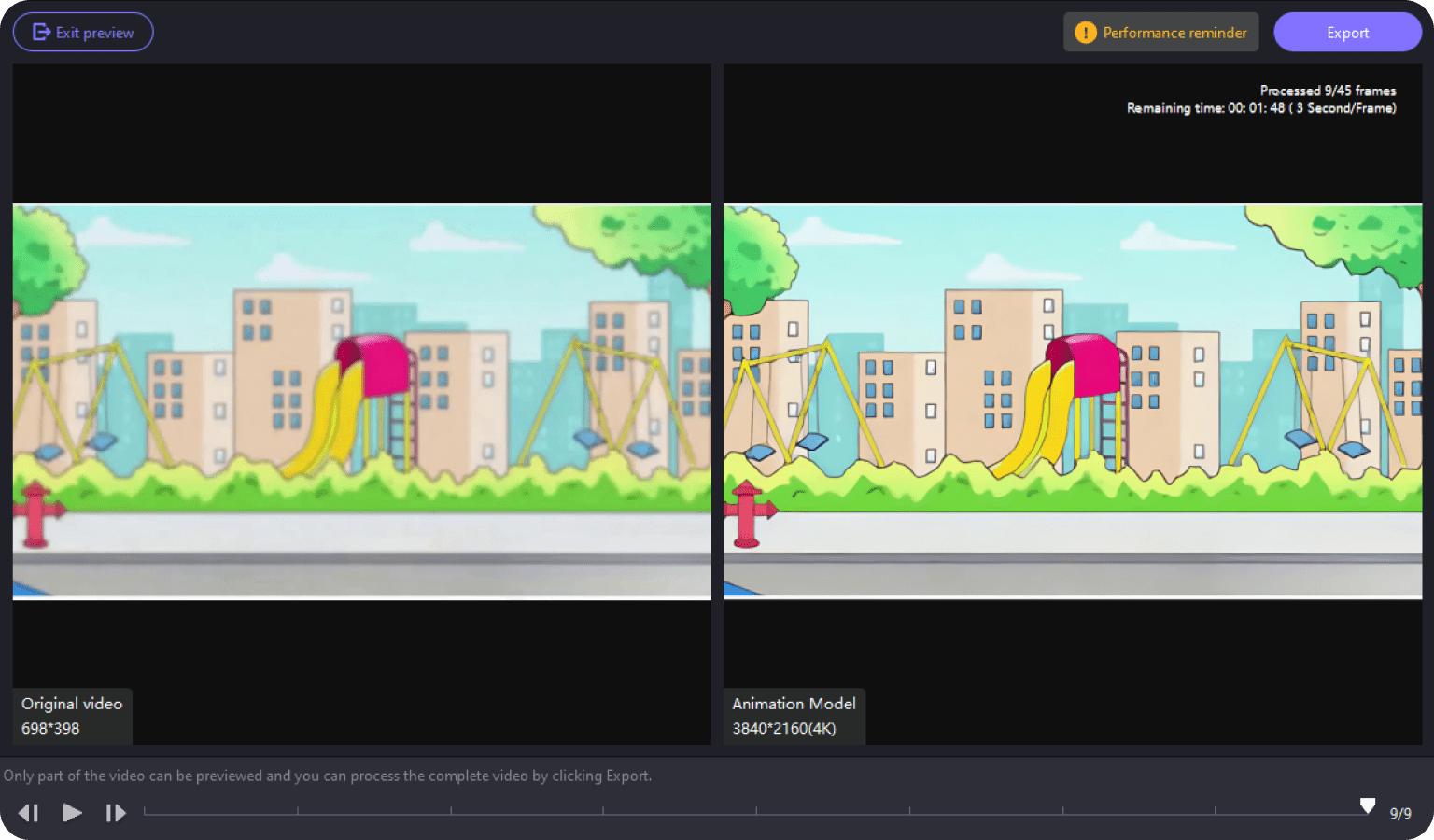
ScrapeGraphAI : un seul mot pour l'exploration du web, pas besoin d'écrire des règles outil intelligent d'extraction de contenu web
Introduction générale
ScrapeGraphAI est une bibliothèque innovante d'exploration du web en Python qui combine astucieusement la modélisation des grands langages (LLM) et la logique graphique directe pour créer des pipelines d'exploration pour les sites web et les documents locaux. Le caractère unique de cet outil réside dans son équilibre parfait entre simplicité et puissance : l'utilisateur décrit simplement les informations qu'il souhaite extraire, et ScrapeGraphAI automatise toute la complexité du processus d'exploration. Le projet prend en charge le traitement de documents dans un large éventail de formats, notamment XML, HTML, JSON et Markdown. En fournissant des SDK pour Python et Node.js, il permet aux développeurs d'intégrer facilement la fonctionnalité d'exploration du web dans leurs projets.ScrapeGraphAI est plus qu'un simple outil d'exploration du web, il fournit également des fonctionnalités riches telles que l'exploration parallèle de plusieurs pages, la génération de discours, la génération automatique de scripts Python et d'autres fonctionnalités avancées.

La logique graphique est un concept technique essentiel de ScrapeGraphAI, qui fait référence à une méthode de traitement structurée pour l'extraction de données sur le web. Plus précisément, il s'agit d'une méthode de traitement structurée pour l'extraction de données sur le web :
- Représentation des structures de données :
- Pensez au contenu web comme à une structure graphique
- Le document HTML est converti en une collection de nœuds et d'arêtes.
- Chaque élément HTML est un nœud et les relations entre les éléments sont représentées par des arêtes
- Flux de traitement :
- Construire d'abord l'arborescence DOM de la page
- Analyse des relations hiérarchiques et associatives entre les nœuds
- Utiliser l'IA (Big Language Modelling) pour comprendre les besoins des utilisateurs
- Trouver le chemin optimal d'extraction des données en fonction de la structure du graphe
Liste des fonctions
- Extraction intelligente d'une seule page : l'extraction de contenu peut être effectuée à l'aide d'une simple invite de l'utilisateur et d'une source d'entrée.
- Multi-Page Parallel Crawl : permet d'extraire des informations de plusieurs pages web en même temps.
- Extraction des résultats des moteurs de recherche : permet d'extraire des informations des N premiers résultats du moteur de recherche.
- Fonction de conversion vocale : permet de convertir des contenus web en fichiers audio
- Génération automatique de scripts : des scripts Python peuvent être générés pour l'extraction de contenu.
- Prise en charge de LLM multiples : compatible avec OpenAI, Groq, Azure, Gemini et d'autres API, ainsi qu'avec les modèles natifs d'Ollama.
- Traitement sémantique avancé : prise en charge d'outils de traitement sémantique tels que Graphviz
- Gestion des navigateurs : intégrée à une variété d'outils et de services de gestion des navigateurs.
- Prise en charge de l'intégration de l'API : fournir une interface API complète et une prise en charge du SDK
Utiliser l'aide
1. les étapes de l'installation
- Installation des fondations
pip install scrapegraphai
playwright install
Il est recommandé d'installer le logiciel dans un environnement virtuel afin d'éviter les conflits de bibliothèques.
- Installation de dépendances optionnelles
- Installer davantage de modèles linguistiques :
pip install scrapegraphai[other-language-models]
- Installation d'options de traitement sémantique :
pip install scrapegraphai[more-semantic-options]
- Installer l'option navigateur :
pip install scrapegraphai[more-browser-options]
2. utilisation de base
Vous trouverez ci-dessous un exemple d'utilisation de SmartScraperGraph (le pipeline de scraping le plus couramment utilisé) :
import json
from scrapegraphai.graphs import SmartScraperGraph
# 配置抓取管道
graph_config = {
"llm": {
"api_key": "YOUR_OPENAI_APIKEY",
"model": "openai/gpt-4o-mini",
},
"verbose": True,
"headless": False,
}
# 创建SmartScraperGraph实例
smart_scraper_graph = SmartScraperGraph(
prompt="Extract me all the news from the website",
source="https://www.wired.com",
config=graph_config
)
# 运行管道
result = smart_scraper_graph.run()
print(json.dumps(result, indent=4))
3. description de l'utilisation des fonctions avancées
- l'exploration multi-pages
- Utilisez SmartScraperMultiGraph pour extraire des informations de plusieurs pages en même temps.
- Prise en charge des appels LLM parallèles pour améliorer l'efficacité du traitement
- Extraction des résultats de recherche
- Utilisez SearchGraph pour extraire des informations directement à partir des résultats des moteurs de recherche.
- Permet de définir le nombre de résultats d'extraction
- transcription phonétique
- Utilisez SpeechGraph pour convertir du contenu web en fichiers audio.
- Prise en charge de plusieurs options de synthèse vocale
- Génération automatique de scripts
- ScriptCreatorGraph génère des scripts Python pour l'extraction de contenu.
- Prise en charge de la génération de scripts à page unique et à pages multiples
- Intégration du LLM
- Prise en charge de plusieurs services LLM : OpenAI, Groq, Azure, Gemini
- Prise en charge des modèles Ollama natifs (nécessite l'installation d'Ollama et le téléchargement préalable des modèles)
4) Précautions
- Assurez-vous que la clé API est configurée correctement avant de l'utiliser.
- Il est recommandé de l'exécuter dans un environnement virtuel afin d'éviter les conflits de dépendance.
- Lorsque vous utilisez des modèles locaux, vous devez installer et télécharger les modèles correspondants à l'avance.
- Respecter les conditions d'utilisation du site et la politique de crawl
- Veillez à contrôler la fréquence du crawling, afin d'éviter la pression sur le site cible.
5. dépannage
- Si vous rencontrez un conflit de dépendance, il est recommandé de recréer l'environnement virtuel
- Vérification de la configuration de la clé en cas d'échec de l'appel à l'API
- Vérification de la connectivité du réseau et de la disponibilité du site cible en cas d'échec de l'exploration d'une page
6. l'accès à l'aide
- Documentation officielle : https://scrapegraph-ai.readthedocs.io/
- Documentation sur le Docusaurus : https://docs-oss.scrapegraphai.com/
- Support communautaire Discord : https://discord.gg/uJN7TYcpNa
- GitHub Issue Tracker : https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...