
Mise à l'échelle du calcul du temps de test : chaîne de pensée sur les modèles vectoriels
Depuis qu'OpenAI a lancé le modèle o1.Mise à l'échelle de l'informatique en temps réel(Scaling Reasoning) est devenu l'un des sujets les plus brûlants dans les cercles de l'IA. Pour simplifier, au lieu d'accumuler de la puissance de calcul dans la phase de pré-entraînement ou de post-entraînement, il est préférable de dépenser davantage de ressources informatiques dans la phase d'inférence (c'est-à-dire lorsque le modèle de langage étendu génère des résultats). o1 Le modèle divise un problème important en une série de petits problèmes (c'est-à-dire une chaîne de pensée), de sorte que le modèle puisse penser comme un être humain, étape par étape, pour évaluer différentes possibilités, faire une planification plus détaillée, réfléchir sur lui-même avant de donner une réponse, etc. Le modèle est autorisé à penser comme un humain, à évaluer différentes possibilités, à faire une planification plus détaillée, à réfléchir sur lui-même avant de donner une réponse, etc. De cette manière, le modèle n'a pas besoin d'être ré-entraîné et la performance ne peut être améliorée que par des calculs supplémentaires pendant le raisonnement.Au lieu de faire apprendre le modèle par cœur, il faut le faire réfléchir davantage-- Cette stratégie est particulièrement efficace dans les tâches d'inférence complexes, avec une amélioration significative des résultats, et la récente publication par Alibaba du modèle QwQ confirme cette tendance technologique : améliorer les capacités du modèle en élargissant le calcul au moment de l'inférence.
👩🏫 Dans le présent document, la mise à l'échelle fait référence à l'augmentation des ressources informatiques (par exemple, arithmétiques ou temporelles) au cours du processus de raisonnement. Il ne s'agit pas d'une mise à l'échelle horizontale (informatique distribuée) ou d'un traitement accéléré (réduction du temps de calcul).

Si vous avez également utilisé le modèle o1, vous aurez certainement l'impression que le raisonnement en plusieurs étapes prend plus de temps parce que le modèle nécessite de construire des chaînes de pensée pour résoudre le problème.
Chez Jina AI, nous nous concentrons davantage sur les Embeddings et les Rerankers que sur les Grands Modèles de Langage (LLM) :Est-il possible d'appliquer le concept de "chaînes de pensée" au modèle d'intégration ?
Bien que cela puisse ne pas être intuitif à première vue, cet article explorera une nouvelle perspective et démontrera comment le calcul à l'échelle du temps d'essai peut être appliqué au système de calcul à l'échelle du temps d'essai, et comment il peut être appliqué à l'échelle du temps d'essai.jina-clipafin de permettre une meilleure compréhension des Images délicates hors domaine (OOD) La catégorisation est effectuée pour résoudre des tâches autrement impossibles.
Nous avons expérimenté la reconnaissance de Pokémon, qui reste un véritable défi pour les modèles vectoriels. Un modèle comme CLIP, bien que performant dans l'appariement image-texte, a tendance à se retourner lorsqu'il rencontre des données hors domaine (OOD) qu'il n'a jamais vues auparavant.
Cependant, nous avons constaté queLa précision de la classification des données hors domaine peut être améliorée en augmentant le temps d'inférence du modèle et en employant une stratégie de classification multi-objectifs semblable à une chaîne de pensée qui ne nécessite pas de réglage du modèle.
Étude de cas : classification des images de Pokémon
🔗 Google Colab : https://colab.research.google.com/drive/1zP6FZRm2mN1pf7PsID-EtGDc5gP_hm4Z#scrollTo=CJt5zwA9E2jB
Nous avons utilisé l'ensemble de données TheFusion21/PokemonCards, qui contient des milliers d'images de cartes Pokemon.Il s'agit d'une tâche de classification d'imagesqui entre un jeu de Pokémon recadré (dont la description textuelle a été supprimée) et produit le nom correct du Pokémon. Mais cela est difficile pour le modèle CLIP Embedding, et ce pour plusieurs raisons :
- Les noms et l'apparence des Pokémon sont relativement nouveaux dans le modèle, et il est facile de renverser le scénario avec une catégorisation directe.
- Chaque Pokémon a ses propres caractéristiques visuellesLes CLIP sont mieux compris, comme les formes, les couleurs et les poses.
- Le style des cartes est cependant uniformeMais les différents arrière-plans, poses et styles de dessin ajoutent à la difficulté.
- Cette tâche nécessitePrendre en compte simultanément plusieurs caractéristiques visuellesLa question de l'accès à l'information, comme la chaîne de pensée complexe du LLM, se pose.

Nous avons supprimé toutes les informations textuelles (titre, pied de page, description) des cartes, afin d'éviter que les modèles ne trichent et ne trouvent les réponses directement dans le texte, car les étiquettes de ces classes de Pokémon sont leurs noms, comme Absol, Aerodactyl.
Méthodologie de base : comparaison directe des similitudes
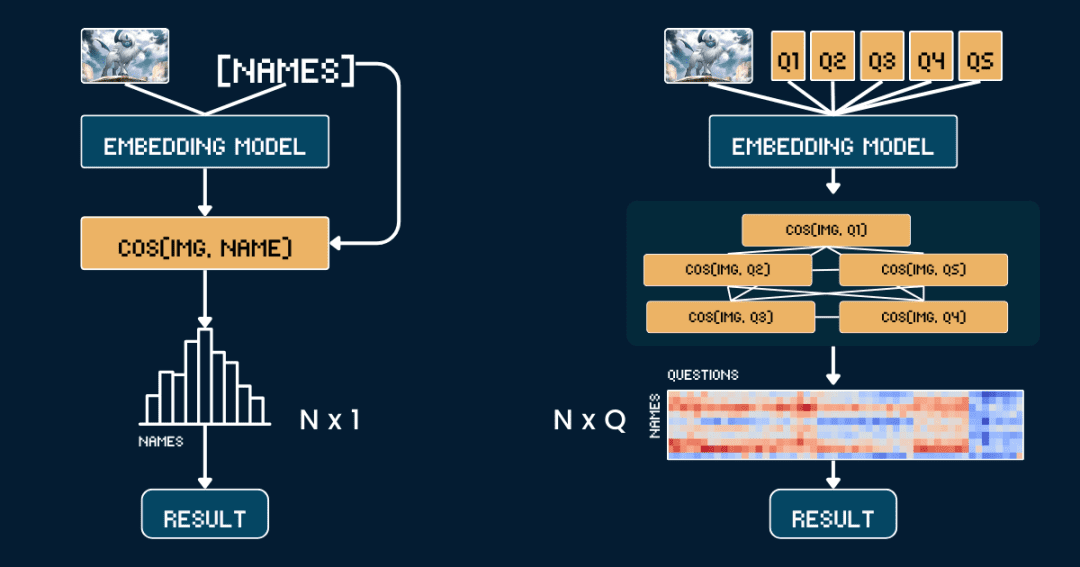
Commençons par la méthodologie de base la plus simple, la Comparaison directe des similitudes entre les images et les noms de Pokémon.
Tout d'abord, il est préférable de supprimer toutes les informations textuelles des cartes, afin que le modèle CLIP n'ait pas à deviner la réponse directement à partir du texte. Ensuite, nous utilisons jina-clip-v1 répondre en chantant jina-clip-v2 Le modèle code l'image et le nom du Pokémon séparément pour obtenir leurs représentations vectorielles respectives. Enfin, la similarité cosinus entre les vecteurs de l'image et les vecteurs du texte est calculée, et le nom qui présente la plus grande similarité est considéré comme étant celui du Pokémon dont il s'agit.
Cette approche équivaut à une correspondance univoque entre l'image et le nom, sans tenir compte d'autres informations ou attributs contextuels. Le pseudo-code suivant décrit brièvement le processus.
# 预处理 cropped_images = [crop_artwork(img) for img in pokemon_cards] # 去掉文字,只保留图片 pokemon_names = ["Absol", "Aerodactyl", ...] # 宝可梦名字# 用 jina-clip-v1 获取 embeddings image_embeddings = model.encode_image(cropped_images) text_embeddings = model.encode_text(pokemon_names) # 计算余弦相似度进行分类 similarities = cosine_similarity(image_embeddings, text_embeddings) predicted_names = [pokemon_names[argmax(sim)] for sim in similarities] # 哪个名字相似度最高,就选哪个 # 评估准确率 accuracy = mean(predicted_names == ground_truth_names)
Avancé : application des chaînes de pensée à la classification des images
Cette fois, au lieu de faire correspondre directement les images et les noms, nous avons divisé l'identification des Pokémon en plusieurs parties, comme dans le jeu "Pokémon Connect".
Nous avons défini cinq ensembles d'attributs clés : la couleur primaire (par exemple, "blanc", "bleu"), la forme primaire (par exemple, "un loup", "un reptile ailé"), les caractéristiques clés (par exemple, "une corne blanche", "de grandes ailes"), la taille du corps (par exemple, "une forme de loup à quatre pattes", "des ailes larges"). un reptile ailé"), les caractéristiques principales (par exemple, "une corne blanche", "de grandes ailes"), la taille du corps (par exemple, "une forme de loup à quatre pattes", "ailé et élancé"). ), la taille du corps (par exemple, "forme de loup à quatre pattes", "ailé et élancé") et les scènes de fond (par exemple, "espace extra-atmosphérique", "forêt verdoyante").
Pour chaque ensemble d'attributs, nous avons conçu un mot indicateur spécial, tel que "Le corps de ce Pokémon est principalement de couleur {}", puis nous avons rempli les options possibles.Ensuite, nous utilisons le modèle pour calculer les scores de similarité entre l'image et chaque option, et nous convertissons les scores en probabilités à l'aide de la fonction softmax, qui donne une meilleure mesure de la confiance du modèle.
La chaîne de pensée complète (CoT) se compose de deux parties :classification_groups répondre en chantant pokemon_rulesLa première définit le cadre de questionnement : chaque attribut (par exemple, la couleur, la forme) correspond à un modèle de question et à un ensemble d'options de réponse possibles. Le second enregistre les options à associer à chaque Pokémon.
Par exemple, la couleur d'Absol doit être "blanc" et sa forme "loup". Nous verrons plus tard comment construire une structure CoT complète, et le pokemon_system ci-dessous est un exemple concret de CoT :
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
En bref, au lieu de comparer les similitudes une seule fois, nous procédons maintenant à des comparaisons multiples, en combinant les probabilités de chaque attribut afin de pouvoir émettre un jugement plus raisonnable.
# 分类流程
def classify_pokemon(image):
# 生成所有提示
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# 获取向量及其相似度
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# 将相似度转换为每个属性组的概率
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# 根据匹配的属性计算每个宝可梦的得分
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get) # 返回得分最高的宝可梦
Analyse de la complexité des deux méthodes
Analysons maintenant la complexité. Supposons que nous voulions trouver le nom qui correspond le mieux à l'image donnée parmi N noms de Pokémon :
La méthode de base nécessite le calcul de N vecteurs de texte (un pour chaque nom) et d'un vecteur d'image, suivi de N calculs de similarité (les vecteurs d'image sont comparés à chaque vecteur de texte).Par conséquent, la complexité de la méthode de référence dépend principalement du nombre de calculs N des vecteurs de texte.
Notre méthode CoT doit calculer Q vecteurs de texte, où Q est le nombre total de toutes les combinaisons question-option, et 1 vecteur d'image. Ensuite, Q calculs de similarité (comparaison des vecteurs d'image avec les vecteurs de texte pour chaque combinaison question-option) doivent être effectués.Par conséquent, la complexité de la méthode dépend principalement de Q.
Dans cet exemple, N = 13 et Q = 52 (5 groupes d'attributs avec une moyenne d'environ 10 options par groupe). Les deux méthodes doivent calculer des vecteurs d'image et effectuer des étapes de classification, et nous arrondissons ces opérations communes dans la comparaison.
Dans le cas extrême, si Q = N, notre méthode dégénère effectivement en une méthode de référence. La clé pour étendre efficacement le calcul du temps d'inférence est donc la suivante :
Concevez le problème de manière à augmenter la valeur de Q. Veillez à ce que chaque question fournisse des indices utiles pour nous aider à la circonscrire. Il est préférable de ne pas répéter les mêmes informations d'une question à l'autre afin de maximiser le gain d'informations.
Résultats
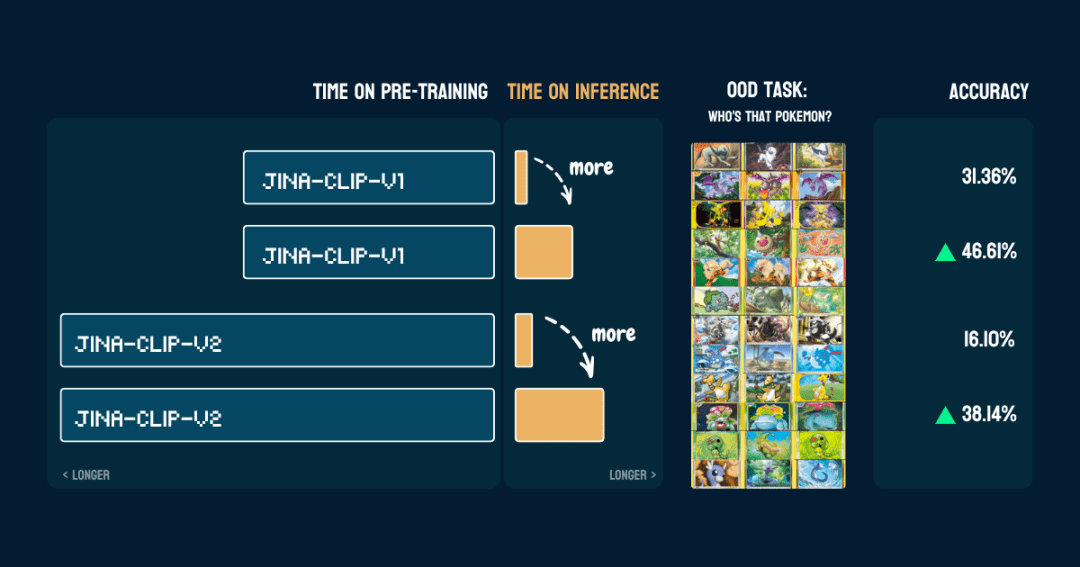
Nous l'avons évalué sur 117 images de test contenant 13 Pokémon différents. Les résultats en termes de précision sont les suivants :

Elle montre également qu'une fois que lespokemon_systemIl est bien construit.Le même CoT peut être utilisé directement sur un modèle différent sans modifier le code et sans réglage fin ou formation supplémentaire.
Intéressant.jina-clip-v1La précision de base du modèle pour la classification Pokémon est alors plus élevée (31,36%) car il a été entraîné sur l'ensemble de données LAION-400M contenant des données Pokémon. Tandis que jina-clip-v2Le modèle a été entraîné sur DFN-2B, qui est un ensemble de données de meilleure qualité, mais qui filtre également plus de données et supprime probablement le contenu lié à Pokémon, ce qui explique sa précision de base plus faible (16,10%).
Attendez, comment cette méthode fonctionne-t-elle ?
👩🏫 Passons en revue ce que nous avons fait.
Nous avons commencé avec des modèles vectoriels fixes pré-entraînés qui ne pouvaient pas traiter les problèmes de non-distribution avec des échantillons nuls. Mais lorsque nous avons construit un arbre de classification, ils ont soudainement pu le faire. Quel est le secret de cette réussite ? S'agit-il de quelque chose qui s'apparente à l'intégration d'un apprenant faible dans l'apprentissage automatique traditionnel ? Il convient de noter que notre modèle vectoriel peut passer de "mauvais" à "bon" non pas grâce à l'apprentissage intégré en soi, mais grâce à la connaissance du domaine externe contenue dans l'arbre de classification. Vous pouvez classer à plusieurs reprises des milliers de questions avec zéro échantillon, mais si les réponses ne contribuent pas au résultat final, cela n'a aucun sens. C'est comme un jeu de "tu me dis, je devine" (vingt questions), où vous devez progressivement réduire la solution à chaque question. C'est donc cette connaissance externe ou ce processus de pensée qui est la clé de la réussite.- Comme dans notre exemple, la clé réside dans la façon dont le système Pokemon est construit.Cette expertise peut provenir d'humains ou de grands modèles linguistiques.
pokemon_systemla qualité des.Il existe de nombreuses façons de construire ce système CoT, du manuel à l'entièrement automatisé, chacune ayant ses propres avantages et inconvénients.1. construction manuelle
2. la construction assistée par le LLM
我需要一个宝可梦分类系统。对于以下宝可梦:[Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...],创建一个包含以下内容的分类系统:
1. 基于以下视觉属性的分类组:
- 宝可梦的主要颜色
- 宝可梦的形态
- 宝可梦最显著的特征
- 宝可梦的整体体型
- 宝可梦通常出现的背景环境
2. 对于每个分类组:
- 创建一个自然语言提示模板,用 "{}" 表示选项
- 列出所有可能的选项
- 确保选项互斥且全面
3. 创建规则,将每个宝可梦映射到每个属性组中的一个选项,使用索引引用选项
请以 Python 字典格式输出,包含两个主要部分:
- "classification_groups": 包含每个属性的提示和选项
- "pokemon_rules": 将每个宝可梦映射到其对应的属性索引
示例格式:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color.",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # "white" 的索引
...
},
...
}
}
LLM génère rapidement un premier projet, mais il nécessite également une vérification et des corrections manuelles.
Une approche plus fiable serait Génération combinée de LLM et validation manuelle. Le LLM est d'abord autorisé à générer une version initiale, puis il vérifie et modifie manuellement les groupements d'attributs, les options et les règles, avant de renvoyer les modifications au LLM pour qu'il continue à les affiner jusqu'à ce qu'il soit satisfait. Cette approche permet de concilier efficacité et précision.
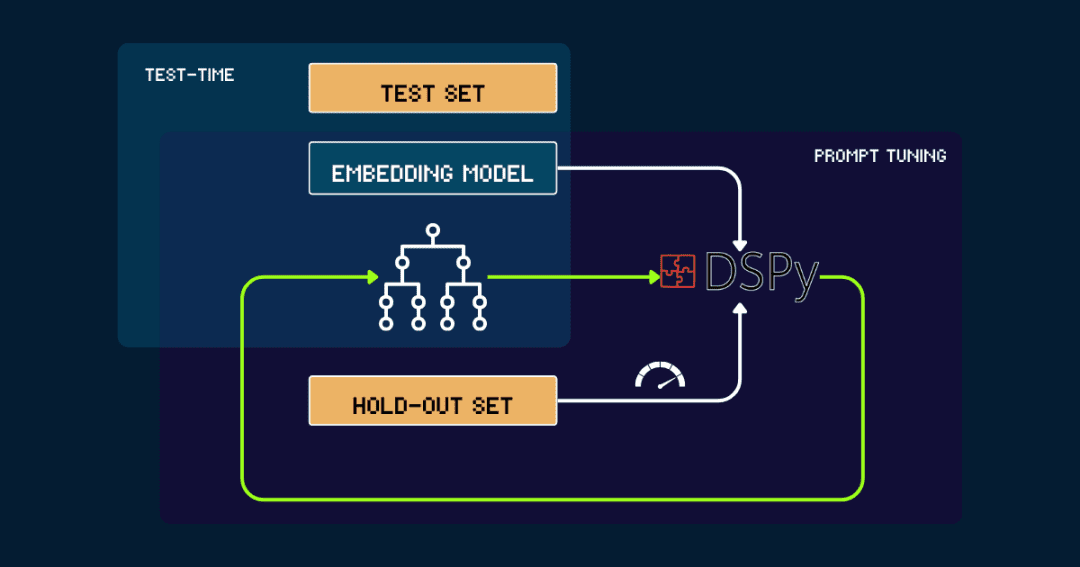
3) Constructions automatisées avec DSPy
Pour des constructions entièrement automatisées pokemon_systemqui peut être optimisé itérativement avec DSPy.
Commençons par un simple pokemon_system Il est ensuite évalué avec les données de l'ensemble d'exclusion, signalant la précision à DSPy en tant que retour d'information. Il est ensuite évalué avec les données de l'ensemble d'exclusion, signalant la précision à DSPy en tant que retour d'information. pokemon_systemrépéter ce cycle jusqu'à ce que les performances convergent et qu'il n'y ait plus d'amélioration significative.
Le modèle vectoriel est fixé tout au long du processus. Avec DSPy, il est possible de trouver automatiquement la meilleure conception de pokemon_system (CoT) et de ne la régler qu'une fois par tâche.
Pourquoi mettre à l'échelle le calcul du temps de test sur des modèles vectoriels ?
Il est trop coûteux à transporter en raison du coût de l'augmentation constante de la taille des modèles pré-entraînés.
Collection Jina Embeddings, dejina-embeddings-v1,v2,v3 jusqu'à (un moment) jina-clip-v1,v2Et jina-ColBERT-v1,v2Chaque mise à niveau s'appuie sur des modèles plus grands, davantage de données préformées et des coûts croissants.
prendrejina-embeddings-v1Pour une diffusion en juin 2023, avec 110 millions de paramètres, la formation coûtera entre 5 000 et 10 000 dollars. D'ici à ce que jina-embeddings-v3En ce qui concerne la formation des mannequins, les performances se sont beaucoup améliorées, mais c'est encore principalement en injectant de l'argent dans les ressources. Aujourd'hui, le coût de formation des meilleurs modèles est passé de milliers de dollars à des dizaines de milliers de dollars, et les grandes entreprises doivent même dépenser des centaines de millions de dollars. Certes, plus on investit dans la préformation, meilleurs sont les résultats du modèle, mais le coût est trop élevé, la rentabilité est de plus en plus faible, et le développement de l'ultime modèle doit tenir compte de la durabilité.
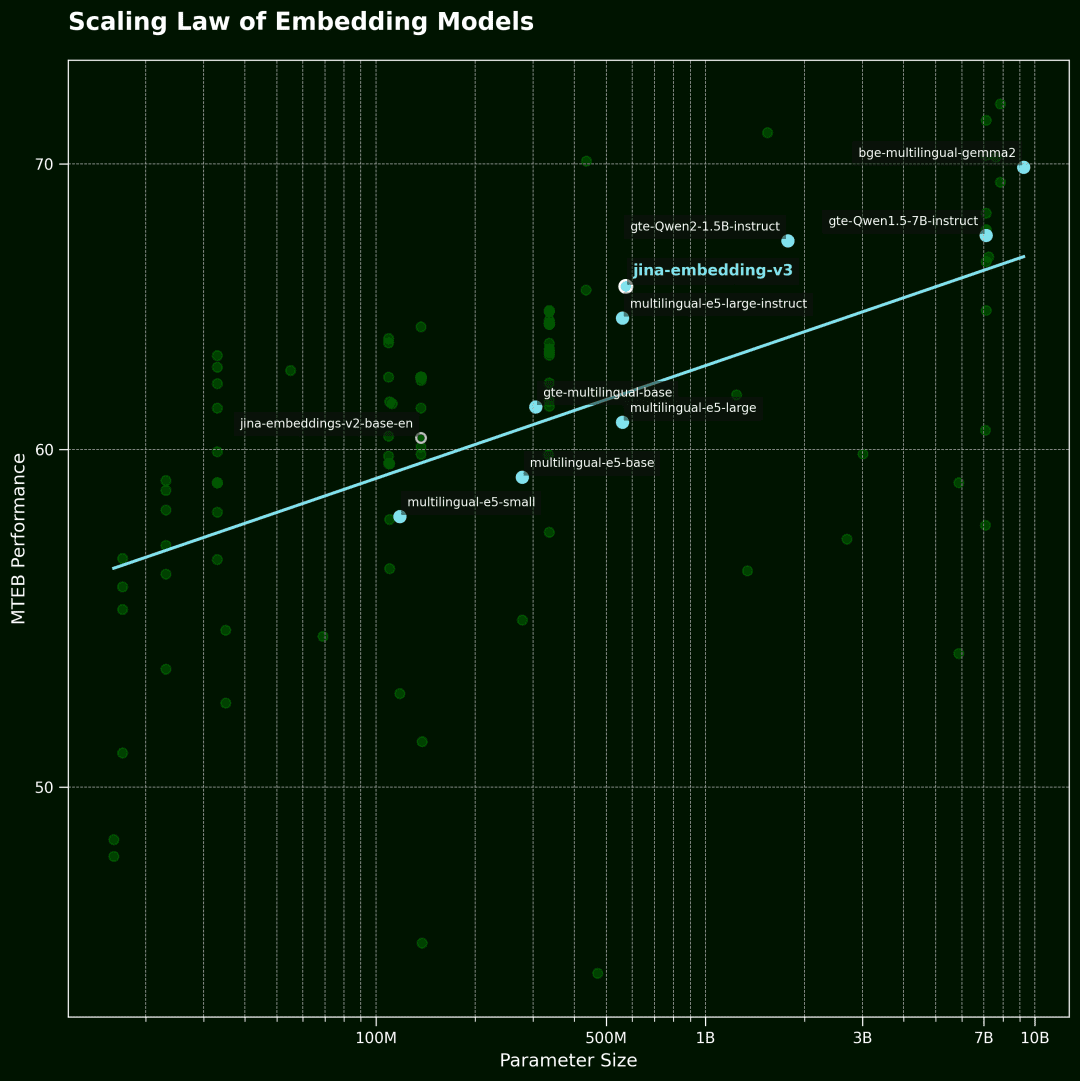
modélisation vectorielle Loi d'échelle
Cette figure montre ensuite le modèle vectoriel Scaling Law.L'axe horizontal représente le nombre de paramètres du modèle et l'axe vertical la performance moyenne de la MTEB. Chaque point représente un modèle vectoriel. La ligne de tendance représente la moyenne de tous les modèles, et les points bleus sont des modèles multilingues.
Les données ont été sélectionnées parmi les 100 premiers modèles vectoriels du classement de la MTEB. Pour garantir la qualité des données, nous avons éliminé les modèles qui ne divulguaient pas d'informations sur la taille du modèle et certaines soumissions non valides.
D'autre part, les modèles vectoriels sont désormais très puissants : multilingues, multitâches, multimodaux, avec d'excellentes capacités d'apprentissage à partir d'un échantillon zéro et de suivi des instructions.Cette polyvalence ouvre de nombreuses possibilités d'amélioration algorithmique et d'extension du calcul au moment de l'inférence.
La question clé est la suivante :Combien les utilisateurs sont-ils prêts à payer pour une requête qui les intéresse vraiment ?? Si le simple fait de faire durer un peu plus longtemps l'inférence d'un modèle fixe pré-entraîné peut améliorer considérablement la qualité des résultats, je suis sûr que de nombreuses personnes trouveront que cela en vaut la peine.
A notre avis.Le calcul du temps d'inférence étendu offre un grand potentiel inexploité dans le domaine de la modélisation vectoriellece qui constituera probablement une avancée importante pour la recherche future.Au lieu de viser un modèle plus grand, il est préférable de consacrer plus d'efforts à la phase d'inférence et d'explorer des méthodes de calcul plus astucieuses pour améliorer les performances. -- Il s'agit peut-être d'un itinéraire plus économique et plus efficace.
rendre un verdict
existent jina-clip-v1/v2 Lors de l'expérimentation, nous avons observé les phénomènes clés suivants :
nous Sur les données non vues par le modèle et en dehors du domaine (OOD)(math.) genreDe meilleures précisions de reconnaissance ont été obtenues, sans qu'il soit nécessaire d'affiner le modèle ou de l'entraîner davantage. Le système est exploité par l'intermédiaire du Raffinement itératif des critères de recherche de similarité et de classificationet d'obtenir ainsi une capacité de différenciation plus fine. en introduisant Ajustement dynamique des indices et raisonnement itératif(analogue à une "chaîne de pensée"), nous transformons le processus de raisonnement du modèle vectoriel d'une simple requête en une chaîne de pensée plus complexe.
Ce n'est qu'un début : le potentiel de Scaling Test-Time Compute va bien au-delà !mais il reste encore un vaste espace à explorer. Par exemple, nous pouvons développer des algorithmes plus efficaces pour réduire l'espace des réponses en choisissant itérativement la stratégie la plus efficace, semblable à la stratégie des solutions optimales dans le jeu des "vingt questions". En élargissant le calcul du temps de raisonnement, nous pouvons pousser les modèles vectoriels au-delà des goulets d'étranglement existants, en débloquant des tâches complexes et fines qui semblaient auparavant hors de portée, et en poussant ces modèles vers des applications plus larges.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...