Comment tester efficacement les indices du LLM - Un guide complet de la théorie à la pratique

I. La cause première du mot-clé du test :
- Le LLM est très sensible aux indices, et des changements subtils dans la formulation peuvent conduire à des résultats très différents.
- Des mots-clés non testés peuvent être générés :
- désinformation
- Réponses non pertinentes
- Coûts inutiles de l'API
Deuxièmement, un processus systématique d'optimisation des mots repères :
- phase préparatoire
- Enregistrement des demandes de LLM avec l'outil d'observation
- Suivre les indicateurs clés : utilisation, latence, coût, temps de réponse, etc.
- Anomalies de surveillance : augmentation des taux d'erreur, augmentation soudaine des coûts de l'API, diminution de la satisfaction des utilisateurs.
- Processus de test
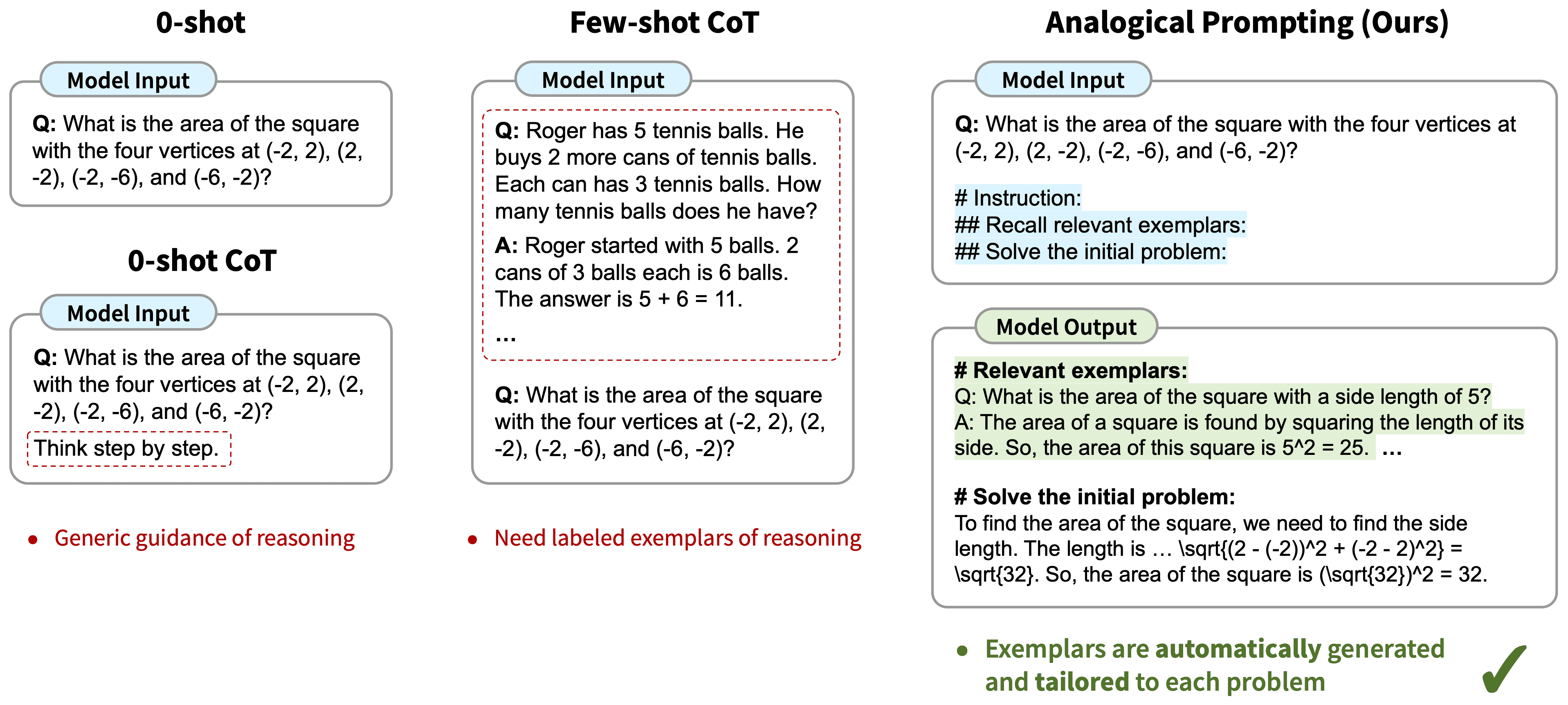
- Créer de multiples variantes de mots-clés, en utilisant des techniques telles que le raisonnement en chaîne et les exemples multiples.
- Testé à l'aide de données réelles :
- Des ensembles de données en or : des données d'entrée soigneusement sélectionnées et des résultats attendus
- Échantillonnage des données de production : le défi de mieux refléter les scénarios réels
- Évaluation comparative des effets des différentes versions
- Déploiement du programme optimal dans l'environnement de production
III. une analyse approfondie des trois principales méthodes d'évaluation :
- Un véritable retour d'information de la part des utilisateurs
- Avantage : reflète directement l'utilisation réelle de l'effet
- Caractéristiques : elles peuvent être collectées par le biais d'évaluations explicites ou de données comportementales implicites.
- Limites : le développement prend du temps, le retour d'information peut être subjectif.
- évaluation manuelle
- Scénarios d'application : tâches subjectives nécessitant un jugement fin
- Méthodes d'évaluation :
- Oui/Non jugement
- Score 0-10
- Comparaison des tests A/B
- Limites : nécessite beaucoup de ressources et est difficile à mettre à l'échelle
- Évaluation automatisée du LLM
- Scénarios applicables :
- Classification des tâches
- Validation des sorties structurées
- Contrôle des contraintes
- Éléments clés :
- Contrôle de la qualité des messages-guides d'évaluation eux-mêmes
- Fournir des conseils sur l'évaluation à l'aide de l'apprentissage par échantillonnage
- Paramètre de température fixé à 0 pour assurer la cohérence
- Points forts : évolutif et efficace
- Mise en garde : possibilité d'hériter d'un modèle biaisé
- Scénarios applicables :
IV. recommandations pratiques pour un cadre d'évaluation :
- Clarifier les dimensions de l'évaluation :
- Précision : le problème a-t-il été résolu correctement ?
- Fluidité : grammaire et naturel
- Pertinence : si elle correspond à l'intention de l'utilisateur
- Créativité : imagination et engagement
- Cohérence : coordination avec les résultats historiques
- Stratégies d'évaluation spécifiques pour différents types de tâches :
- Catégorie assistance technique : accent mis sur la précision et le professionnalisme dans la résolution des problèmes
- Catégorie "Création littéraire" : l'accent est mis sur l'originalité et le ton de la marque
- Tâches structurées : l'accent est mis sur le formatage et l'exactitude des données
V. Points clés pour une optimisation continue :
- Créer une boucle de rétroaction complète
- Maintenir un état d'esprit d'expérimentation itérative
- Prise de décision fondée sur des données
- Équilibrer l'amélioration de l'impact et l'investissement dans les ressources
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...