
Comment choisir le bon modèle d'intégration ?
Retrieval Augmented Generation (RAG) est une classe d'applications dans l'IA générative (GenAI) qui soutient l'utilisation de ses propres données pour augmenter les connaissances d'un modèle LLM (par exemple ChatGPT).
RAG Trois modèles d'IA différents sont couramment utilisés, à savoir le modèle Embedding, le modèle Rerankear et le modèle Big Language. Dans cet article, nous verrons comment choisir le bon modèle d'intégration en fonction de votre type de données, de votre langue ou d'un domaine spécifique (par exemple, le domaine juridique).
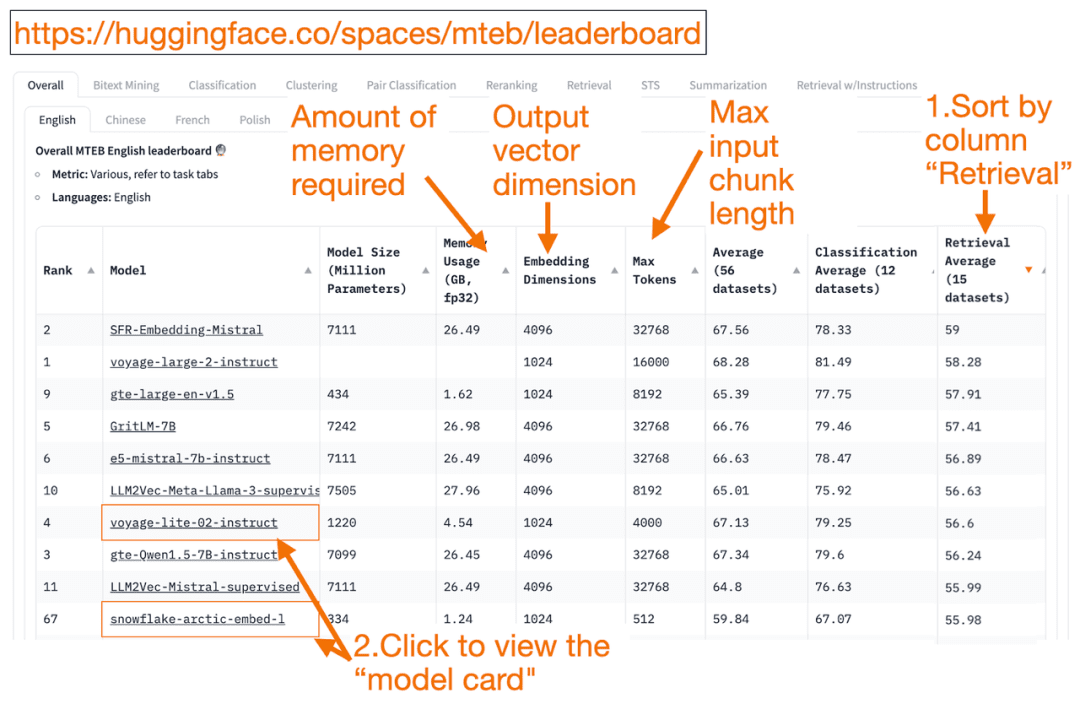
1. données textuelles : classement de la MTEB
Visage étreint Classement de la MTEB est une liste unique de modèles d'intégration de texte ! Vous pouvez connaître les performances moyennes de chaque modèle.
Vous pouvez trier la colonne "Moyenne de récupération" par ordre décroissant, ce qui correspond le mieux à la tâche de recherche vectorielle. Recherchez ensuite le modèle le mieux classé et le moins gourmand en mémoire.
- La dimension du vecteur d'intégration est la longueur du vecteur, c'est-à-dire y dans f(x)=y, que le modèle produira.
- le plus grand Jeton Le nombre est la longueur du bloc de texte d'entrée, c'est-à-dire x dans f(x)=y , que vous pouvez entrer dans le modèle.
En plus de l'adoption de la Récupération Outre le tri des tâches, vous pouvez également filtrer selon les critères suivants :
- Langue : le français, l'anglais, le chinois et le polonais sont pris en charge. (par exemple : task=récupération.
Langue=chinois)
- Textes dans le domaine juridique.
(par exemple, tâche=recherche, langue=juridique)
Il convient de noter que certaines données d'entraînement n'ayant été rendues publiques que récemment, certains des modèles d'intégration de la MTEB peuvent êtreapparemment appropriéCependant, les modèles réellement inadaptés dont les classements sont gonflés peuvent en réalité avoir des performances différentes. C'est pourquoi HuggingFace a publié uneblog (mot d'emprunt)Les points clés pour déterminer si le classement d'un modèle est crédible sont décrits. Après avoir cliqué sur le lien d'un modèle (appelé "fiche de modèle") :
- Recherchez des blogs et des articles qui expliquent comment les modèles sont formés et évalués. Examinez attentivement la langue, les données et les tâches utilisées pour la formation des modèles. Recherchez également les modèles créés par des entreprises de renom. Par exemple, sur la carte de modèle voyage-lite-02-instruct, vous verrez d'autres modèles VoyageAI listés, mais pas celui-ci. C'est un indice ! Ce modèle est un modèle d'ajustement excessif et ne doit pas être utilisé !
- Dans la capture d'écran ci-dessous, je vais essayer le nouveau modèle "snowflake-arctic-embed-1" de Snowflake parce qu'il est bien classé, suffisamment petit pour fonctionner sur mon ordinateur portable et qu'il contient des liens vers des blogs et des articles sur la carte du modèle.
L'avantage d'utiliser HuggingFace est que si vous devez changer de modèle après avoir sélectionné le modèle Embedding, il vous suffit de changer le nom du modèle dans le code !
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from Huggingface
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

2. données d'image : ResNet50
Il peut arriver que vous souhaitiez rechercher des images similaires à l'image saisie. Par exemple, vous pouvez rechercher d'autres images de chats écossais. Dans ce cas, vous pouvez télécharger une photo d'un chat Scottish Fold et demander au moteur de recherche de trouver des images similaires.
ResNet50 est un modèle CNN populaire formé à l'origine par Microsoft en 2015 à l'aide des données ImageNet.
De même, pour lesRecherche vidéoDans ce cas, ResNet50 peut encore convertir la vidéo en vecteurs d'intégration. Ensuite, une recherche de similarité est effectuée sur les images vidéo statiques et la vidéo la plus similaire est renvoyée à l'utilisateur en tant que meilleure correspondance.
3. données audio : PANNs
Comme pour la recherche d'images, vous pouvez également rechercher des sons similaires à partir de clips audio.
PANNs(Pre-trained Audio Neural Networks) sont couramment utilisés comme modèles d'intégration pour la recherche audio, car les PANN sont préformés sur des ensembles de données audio à grande échelle et excellent dans des tâches telles que la classification et l'étiquetage audio.
4. les images multimodales et les données textuelles :
SigLIP ou Unum
Ces dernières années, un certain nombre de modèles d'intégration formés sur un mélange de données non structurées (texte, images, audio ou vidéo) ont vu le jour. Ces modèles sont capables de capturer la sémantique de plusieurs types de données non structurées simultanément dans le même espace vectoriel.
Le modèle d'intégration multimodale permet de rechercher des images à l'aide de texte, de générer des descriptions textuelles d'images ou de rechercher des images.
Lancement de l'OpenAI en 2021 CLIP est le modèle d'intégration standard. Mais comme il était difficile à utiliser parce qu'il exigeait des utilisateurs qu'ils procèdent eux-mêmes à des ajustements, en 2024, Google a introduit le modèle d'intégration. SigLIP(Sigmoïdal-CLIP). Le modèle a obtenu de bonnes performances lors de l'utilisation de l'invite zéro-shot.
Les petits modèles de LLM sont de plus en plus populaires aujourd'hui. En effet, ces modèles ne nécessitent pas de grandes grappes de nuages et peuvent fonctionner sur des ordinateurs portables. Les petits modèles nécessitent moins de mémoire, ont une latence plus faible et s'exécutent plus rapidement que les grands modèles.Unum Des modèles multimodaux de mini-emboîtement sont proposés.
5. données textuelles, audio et vidéo multimodales
La plupart des systèmes RAG texte-audio multimodaux utilisent des LLM génératifs multimodaux, qui convertissent d'abord le son en texte, génèrent des paires son-texte, puis convertissent le texte en vecteurs d'intégration. Vous pouvez ensuite utiliser le RAG pour récupérer le texte comme d'habitude. Dans la dernière étape, le texte est reconverti en son.
OpenAI Chuchotement peut transcrire la parole en texte. En outre, l'équipe d'OpenAI Synthèse vocale (TTS) Les modèles peuvent également convertir du texte en audio.
Le système RAG multimodal texte-vidéo utilise une approche similaire pour cartographier d'abord la vidéo en texte, la convertir en un vecteur d'intégration, rechercher le texte et renvoyer la vidéo comme résultat de la recherche.
OpenAI Sora Le texte peut être converti en vidéo. Comme pour Dall-e, vous fournissez des invites textuelles pendant que LLM génère la vidéo. Sora peut également générer des vidéos à partir d'images fixes ou d'autres vidéos.
Milvus a désormais intégré le modèle d'intégration principal, et vous êtes invités à en faire l'expérience :https://milvus.io/docs/embeddings.md
consultation
Classement de la MTEB : https://huggingface.co/spaces/mteb/leaderboard
Bonnes pratiques de la MTEB : https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Recherche d'images similaires : https://milvus.io/docs/image_similarity_search.md
Recherche d'images vidéo : https://milvus.io/docs/video_similarity_search.md
Recherches audio similaires : https://milvus.io/docs/audio_similarity_search.md
Recherche d'images textuelles : https://milvus.io/docs/text_image_search.md
2024 SigLIP (perte sigmoïde CLIP) Papier : https://arxiv.org/pdf/2401.06167v1
Modèle d'intégration multimodale Unum :
https://github.com/unum-cloud/uform
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...