
Qwen3-ASR-Flash - une série de modèles de reconnaissance vocale lancés par Ali Tongyi Qianqian

Qu'est-ce que le Qwen3-ASR-Flash ?
Qwen3-ASR-Flash est le dernier modèle de reconnaissance vocale de haute précision d'Alibaba. Qwen3 Modèle de base, entraîné par des données multimodales massives. Il prend en charge 11 langues et de nombreux accents, y compris des dialectes tels que le mandarin, le sichuan, le minnan, le wu, le cantonais, ainsi que l'anglais britannique et américain. Ses principales caractéristiques sont les suivantes : une précision de reconnaissance de premier plan, une capacité de reconnaissance de chansons époustouflante (taux d'erreur inférieur à 8%), une reconnaissance personnalisée (les utilisateurs peuvent fournir un texte d'arrière-plan pour obtenir des résultats personnalisés), la reconnaissance de langues avec rejet non vocal et une grande robustesse dans des environnements acoustiques complexes. Les utilisateurs peuvent tester le modèle gratuitement via ModelScope, Hugging Face et l'API AliCloud Hundred Refinements.
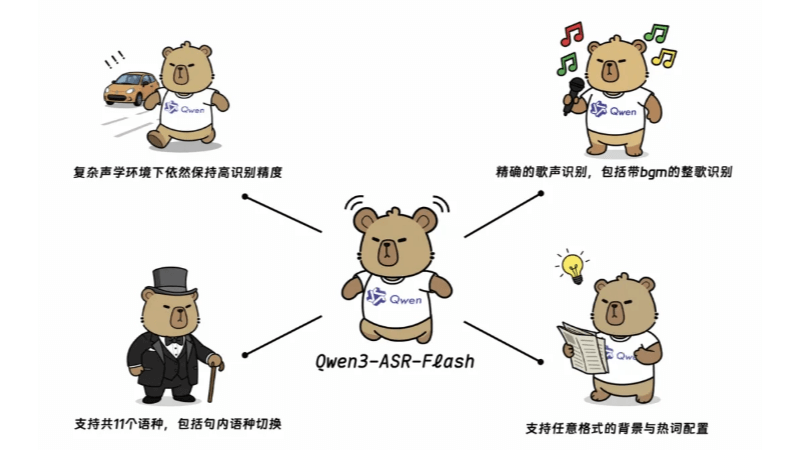
Caractéristiques fonctionnelles de Qwen3-ASR-Flash
- Reconnaissance très préciseLes meilleures performances en anglais, en chinois et dans les benchmarks multilingues, avec une reconnaissance précise de plusieurs langues et dialectes.
- reconnaissance des chansonsLe système prend en charge la reconnaissance de chants clairs et de chansons entières sur fond musical, et le taux d'erreur mesuré est inférieur à 8%.
- Identification personnaliséeL'utilisateur peut fournir un texte de fond dans n'importe quel format, et le modèle peut ajuster les résultats de la reconnaissance en conséquence, sans prétraitement.
- Reconnaissance du langage et rejet non vocalLe système d'information sur les langues : il distingue avec précision les langues parlées et filtre automatiquement les segments non vocaux tels que les silences et les bruits de fond.
- grande robustesseLa précision est maintenue dans des environnements acoustiques complexes et face à des textes difficiles tels que des phrases longues et difficiles et des changements de langue au milieu de la phrase.
Principaux avantages de Qwen3-ASR-Flash
- Reconnaissance très préciseLes résultats sont excellents dans les tests de reconnaissance multilingue et dialectale, avec des taux d'erreur inférieurs à ceux des produits concurrents.
- Prise en charge multilingueLe modèle unique prend en charge 11 langues et plusieurs dialectes, couvrant le mandarin, l'anglais, le français, l'allemand et plus encore.
- Identification personnaliséeLes utilisateurs peuvent fournir un texte de fond dans n'importe quel format, et le modèle peut utiliser intelligemment les informations contextuelles pour produire des résultats de reconnaissance personnalisés.
- reconnaissance des chansonsLe taux d'erreur mesuré est inférieur à 8%, ce qui constitue une excellente performance dans le domaine de la reconnaissance de chansons.
- Reconnaissance du langage et rejet non vocalL'efficacité de la reconnaissance est améliorée par la capacité à distinguer avec précision les langues parlées et à filtrer automatiquement les segments non vocaux, tels que les silences et les bruits de fond.
- grande robustesseLa précision est maintenue dans des environnements acoustiques complexes et face à des textes difficiles tels que des phrases longues et difficiles et des changements de langue au milieu de la phrase.
Quel est le site officiel de Qwen3-ASR-Flash ?
- Site web du projet: https://bailian.console.aliyun.com/?spm=5176.29597918.J_tAwMEW-mKC1CPxlfy227s.1.4f007b08aWhTjW&tab=model#/model-market/detail /group-qwen3-asr-flash?modelGroup=group-qwen3-asr-flash
- Démonstration de l'expérience en ligne: : https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
Personnes auxquelles Qwen3-ASR-Flash est destiné
- Utilisateurs ayant besoin d'une transcription vocale de haute précisionLes utilisateurs de l'Internet : par exemple les journalistes, les organisateurs de conférences, les chercheurs, etc. peuvent convertir rapidement et avec précision le contenu vocal en texte.
- polyglotteL'utilisation de l'anglais comme langue étrangère : par exemple, les apprenants de langues étrangères, les employés de sociétés multinationales, les participants à des conférences internationales, etc. peuvent aider à franchir les barrières linguistiques.
- créateur de contenuLes utilisateurs de l'Internet : par exemple les blogueurs vidéo, les animateurs de podcasts, etc. peuvent générer efficacement des sous-titres et des transcriptions.
- Professionnels du secteurPar exemple, les praticiens des secteurs médical, financier et juridique peuvent utiliser des fonctions de reconnaissance personnalisées pour identifier avec précision la terminologie.
- Personnes ayant des besoins particuliers en matière de reconnaissance vocaleLe modèle de reconnaissance vocale peut être utilisé par plusieurs types d'utilisateurs : les malentendants, qui peuvent mieux comprendre les informations vocales avec l'aide du modèle, et les utilisateurs qui ont besoin de reconnaissance vocale dans des environnements bruyants, tels que le personnel du service clientèle et les journalistes sur le terrain.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...