
Lancement de Qwen2.5-VL : prise en charge de la compréhension des vidéos longues, de la localisation visuelle, de la sortie structurée, paramétrage fin en Open Source

1.Introduction du modèle
Au cours des cinq mois qui ont suivi la publication de Qwen2-VL, de nombreux développeurs ont élaboré de nouveaux modèles à partir du modèle de langage visuel Qwen2-VL, fournissant un retour d'information précieux à l'équipe Qwen. Pendant ce temps, l'équipe Qwen s'est concentrée sur la construction de modèles visuels de langage plus utiles. Aujourd'hui, l'équipe Qwen est heureuse de présenter le dernier membre de la famille Qwen : Qwen2.5-VL.
Améliorations majeures :
- Comprendre les choses visuellement : Qwen 2.5-VL est non seulement capable de reconnaître des objets courants tels que des fleurs, des oiseaux, des poissons et des insectes, mais aussi d'analyser des textes, des diagrammes, des icônes, des graphiques et des mises en page dans des images.
- Agenticity : Qwen2.5-VL joue directement le rôle d'un agent visuel, avec la fonctionnalité d'un outil de raisonnement et de commande dynamique qui peut être utilisé sur des ordinateurs et des téléphones mobiles.
- Comprendre les vidéos longues et capturer les événements : Qwen 2.5-VL peut comprendre des vidéos de plus d'une heure, et cette fois-ci, il a la nouvelle capacité de capturer les événements en localisant les clips vidéo pertinents.
- Capacité de localisation visuelle dans différents formats : Qwen2.5-VL peut localiser avec précision des objets dans une image en générant des boîtes de délimitation ou des points, et peut fournir une sortie JSON stable pour les coordonnées et les attributs.
- Générer une sortie structurée : pour les données numérisées telles que les factures, les formulaires, les tableaux, etc., Qwen 2.5-VL prend en charge la sortie structurée de leur contenu, ce qui est utile dans les domaines de la finance, des affaires et autres.
Modèle d'architecture :
- Formation à la résolution dynamique et à la fréquence d'images pour la compréhension de la vidéo :
L'extension de la résolution dynamique à la dimension temporelle par l'utilisation d'un échantillonnage dynamique du nombre d'images par seconde permet au modèle de comprendre la vidéo à différents taux d'échantillonnage. En conséquence, l'équipe de Qwen a mis à jour mRoPE avec l'alignement de l'ID et du temps absolu dans la dimension temporelle, ce qui permet au modèle d'apprendre l'ordre et la vitesse temporels, et d'acquérir finalement la capacité de repérer des moments spécifiques.
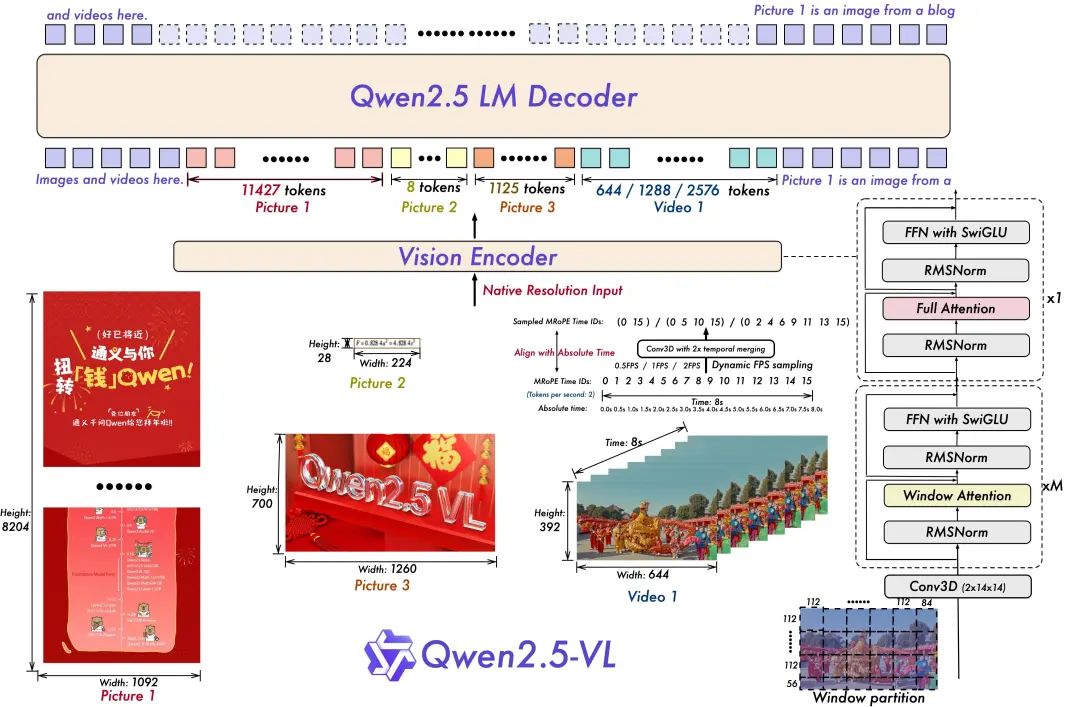
- Codeur visuel rationalisé et efficace
L'équipe Qwen a amélioré la vitesse de formation et d'inférence en introduisant stratégiquement le mécanisme d'attention fenêtrée dans ViT. L'architecture de ViT a été optimisée avec SwiGLU et RMSNorm pour l'aligner sur la structure du LLM Qwen 2.5.
Il y a trois modèles dans cette source ouverte, avec des paramètres de 3 milliards, 7 milliards et 72 milliards. Ce repo contient le modèle 72B ajusté à la commande. Qwen2.5-VL Modèles.
Ensemble de modèles :
https://www.modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
Expérience en matière de modélisation :
https://chat.qwenlm.ai/
Tech Blog :
https://qwenlm.github.io/blog/qwen2.5-vl/
Adresse du code :
https://github.com/QwenLM/Qwen2.5-VL
2.effet de modélisation
évaluation de la modélisation
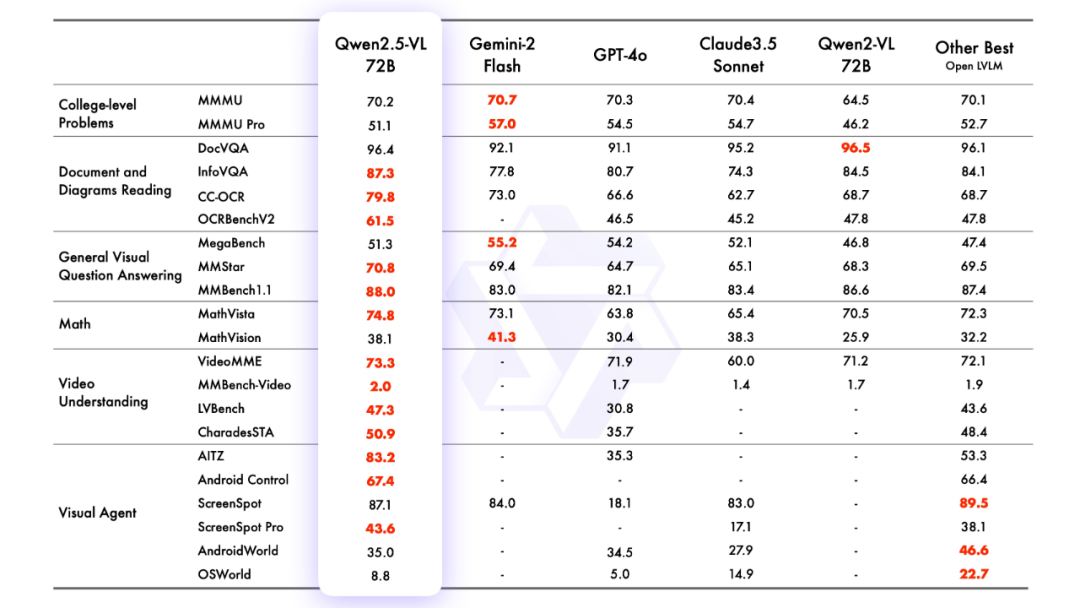
M. José María González
3.raisonnement modélisé
Raisonner avec des transformateurs
Le code de Qwen2.5-VL se trouve dans les derniers transformateurs, et il est recommandé de le compiler à partir des sources en utilisant la commande :
pip install git+https://github.com/huggingface/transformersUne boîte à outils est fournie pour faciliter l'utilisation de différents types d'entrées visuelles, comme vous le feriez avec une API. Il s'agit notamment de base64, d'URL, d'images et de vidéos entrelacées. Il peut être installé à l'aide de la commande suivante :
pip install qwen-vl-utils[decord]==0.0.8Raisonnement sur le code :
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
# Download and load the model
model_dir = snapshot_download("Qwen/Qwen2.5-VL-3B-Instruct")
# Default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# Optional: Enable flash_attention_2 for better acceleration and memory saving
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# Load the default processor
processor = AutoProcessor.from_pretrained(model_dir)
# Optional: Set custom min and max pixels for visual token range
# min_pixels = 256 * 28 * 28
# max_pixels = 1280 * 28 * 28
# processor = AutoProcessor.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
# )
# Define input messages
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Prepare inputs for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generate output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# Print the generated output
print(output_text)
Appelé directement à l'aide de l'API-Inférence de Magic Hitch
L'API-Inférence de la plateforme Magic Match est également la première à prendre en charge la série de modèles Qwen2.5-VL. Les utilisateurs de Magic Match peuvent l'utiliser directement via l'appel API. La manière spécifique d'utiliser l'API-Inférence peut être trouvée sur la page du modèle (par exemple https://www.modelscope.cn/models/Qwen/Qwen2.5-VL-72B-Instruct) :

Ou consultez la documentation sur l'inférence API :
https://www.modelscope.cn/docs/model-service/API-Inference/intro
Voici un exemple de l'image suivante, appelant l'API en utilisant le modèle Qwen/Qwen2.5-VL-72B-Instruct :

from openai import OpenAI
# Initialize the OpenAI client
client = OpenAI(
api_key="<MODELSCOPE_SDK_TOKEN>", # ModelScope Token
base_url="https://api-inference.modelscope.cn/v1"
)
# Create a chat completion request
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-72B-Instruct", # ModelScope Model-Id
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/bird-vl.jpg"
}
},
{
"type": "text",
"text": (
"Count the number of birds in the figure, including those that "
"are only showing their heads. To ensure accuracy, first detect "
"their key points, then give the total number."
)
},
],
}
],
stream=True
)
# Stream the response
for chunk in response:
print(chunk.choices[0].delta.content, end='', flush=True)
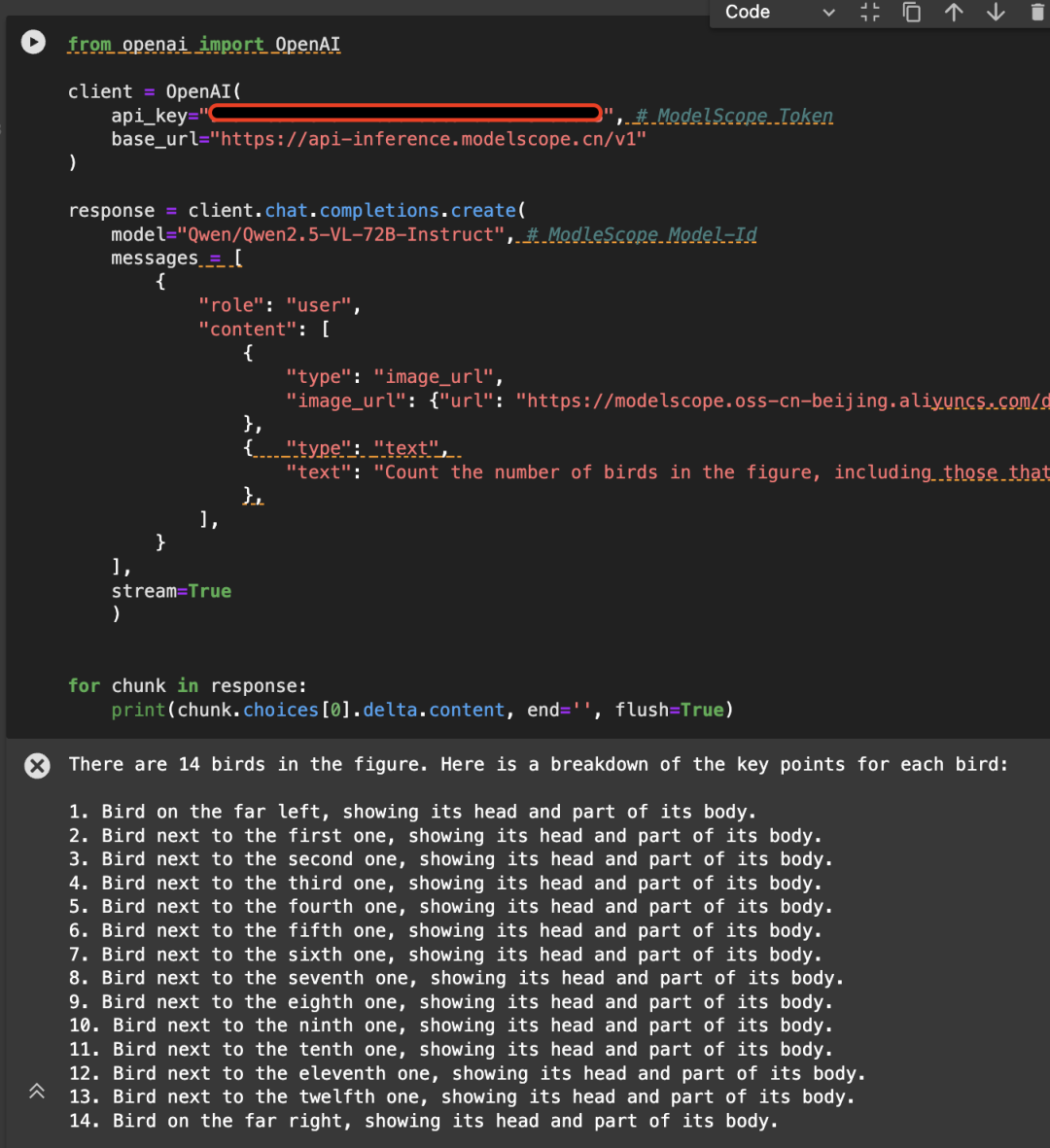
4. mise au point du modèle
Nous présentons l'utilisation de ms-swift sur Qwen/Qwen2.5-VL-7B-Instruct fine-tuning. ms-swift est la communauté magic ride officiellement fournie par le grand modèle et le cadre de déploiement multimodal du grand modèle fine-tuning. ms-swift open source address :
https://github.com/modelscope/ms-swift
Ici, nous montrerons des démonstrations de réglage fin exécutables et nous donnerons le format de l'ensemble de données défini par l'utilisateur.
Assurez-vous que votre environnement est prêt avant de commencer à le peaufiner.
git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
Le script de réglage fin de l'OCR de l'image est le suivant :
MAX_PIXELS=1003520 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#20000 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
Ressources de mémoire vidéo pour la formation :

Le script de mise au point de la vidéo se trouve ci-dessous :
# VIDEO_MAX_PIXELS等参数含义可以查看:
# https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html#id18
nproc_per_node=2
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=$nproc_per_node \
VIDEO_MAX_PIXELS=100352 \
FPS_MAX_FRAMES=24 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset swift/VideoChatGPT:all \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--deepspeed zero2
Ressources de mémoire vidéo pour la formation :

Le format du jeu de données personnalisé est le suivant (le champ système est facultatif), il suffit de spécifier `--dataset ` :
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "xxx/x.png"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<video>视频中是什么"}, {"role": "assistant", "content": "视频中是一只小狗在草地上奔跑"}], "videos": ["/xxx/x.mp4"]}
Le script de mise au point de la tâche de mise à la terre est le suivant :
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset 'AI-ModelScope/coco#20000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--dataset_num_proc 4
Ressources de mémoire vidéo pour la formation :

Le format de l'ensemble de données personnalisées de la tâche de mise à la terre est le suivant :
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>描述图像"}, {"role": "assistant", "content": "<ref-object><bbox>和<ref-object><bbox>正在沙滩上玩耍"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["一只狗", "一个女人"], "bbox": [[331.5, 761.4, 853.5, 1594.8], [676.5, 685.8, 1099.5, 1427.4]]}}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>找到图像中的<ref-object>"}, {"role": "assistant", "content": "<bbox><bbox>"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["羊"], "bbox": [[90.9, 160.8, 135, 212.8], [360.9, 480.8, 495, 532.8]]}}
Une fois la formation terminée, l'inférence est effectuée sur l'ensemble de validation de la formation à l'aide de la commande suivante.
Ici, `--adapters` doit être remplacé par le dernier dossier de points de contrôle généré par l'entraînement. Puisque le dossier adapters contient les fichiers de paramètres pour l'entraînement, il n'est pas nécessaire de spécifier `--model` en plus :
CUDA_VISIBLE_DEVICES=0swift infer--adapters output/vx-xxx/checkpoint-xxx--stream false--max_batch_size 1--load_data_args true--max_new_tokens 2048
Pousser le modèle vers ModelScope :
CUDA_VISIBLE_DEVICES=0swift export--adapters output/vx-xxx/checkpoint-xxx--push_to_hub true--hub_model_id '<your-model-id>'--hub_token '<your-sdk-token>'
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...