
Prompt Advanced Tips : Contrôle précis de la sortie LLM et définition de la logique d'exécution avec du pseudo-code
Comme nous le savons tous, lorsque nous devons laisser un grand modèle linguistique effectuer une tâche, nous devons saisir une invite pour guider son exécution, qui est décrite à l'aide du langage naturel. Pour les tâches simples, le langage naturel peut les décrire clairement, par exemple : "Veuillez traduire ce qui suit en chinois simplifié :", "Veuillez générer un résumé de ce qui suit :", etc.
Cependant, lorsque nous sommes confrontés à des tâches complexes, telles que l'obligation pour le modèle de générer un format JSON spécifique, ou lorsque la tâche comporte plusieurs branches, que chaque branche doit exécuter plusieurs sous-tâches et que les sous-tâches sont liées les unes aux autres, les descriptions en langage naturel ne sont pas suffisantes.
thème de discussion
Voici deux questions qui peuvent faire réfléchir avant de poursuivre la lecture :
- Il y a plusieurs longues phrases, chacune d'entre elles devant être divisée en phrases plus courtes ne dépassant pas 80 caractères, puis converties dans un format JSON décrivant clairement la correspondance entre les phrases longues et les phrases courtes.
Par exemple :
[
{
"long": "This is a long sentence that needs to be split into shorter sentences.",
"short": [
"This is a long sentence",
"that needs to be split",
"into shorter sentences."
]
},
{
"long": "Another long sentence that should be split into shorter sentences.",
"short": [
"Another long sentence",
"that should be split",
"into shorter sentences."
]
}
]
- Un texte sous-titré original contenant uniquement des informations sur les dialogues, dont vous devez maintenant extraire les chapitres, les locuteurs, puis lister les dialogues par chapitre et par paragraphe. S'il y a plusieurs locuteurs, chaque dialogue doit être précédé par le locuteur, pas si le même locuteur parle consécutivement. (Il s'agit en fait d'un TPG que j'utilise moi-même pour organiser des scripts vidéo. Collation de scripts vidéo GPT)
Exemple d'entrée :
所以我要引用一下埃隆·马斯克的话,希望你不要介意。 我向你道歉。 但他并不认同这是一个保障隐私和安全的模型。 他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? 不在意? 那是他的观点。 显然,我不这么认为。 我们也不这么认为。 Mira,感谢你能和我们在一起。 我知道你可能稍微有点忙。 我有许多问题想向 Mira 提问,但我们只有 20 分钟。 所以我想先设定一下大家的期望。 我们会专注于一些主题, 包括一些近期的新闻和 Mira 作为首席技术官所负责的一些领域。 希望我们能深入探讨其中的一些话题。 我想我第一个问题是, 考虑到你现在极其忙碌, 以及新闻的攻击, 有些好有些坏, 你大约六年前加入了这个公司。 那时,它是一个截然不同的组织。 你相对低调,不太为人知晓。 你是否怀念那些能够全神贯注工作的日子? 我想说,我们依旧全神贯注在工作中。 只不过工作的内容已经发展变化了,它不仅仅关乎研究。 也是因为,你知道,研究已经得到了很大的进展。 这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中所以,使命依然如一, 我们在研究上也已经取得了很多进展,工作领域也在不断扩大。 公众对此的关注度也很高, 这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。 但你要知道, 鉴于我们所做的事情的重要性,这种关注是非常必要的, 而且这是积极的。
Exemple de sortie :
### 引言 **主持人**: 所以我要引用一下埃隆·马斯克的话,希望你不要介意。我向你道歉,但他并不认同这是一个保障隐私和安全的模型。他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? **Mira**: 那是他的观点。显然,我不这么认为。我们也不这么认为。 ### 欢迎与介绍 **主持人**: Mira,感谢你能和我们在一起。我知道你可能稍微有点忙。我有许多问题想向你提问,但我们只有 20 分钟。所以我想先设定一下大家的期望。我们会专注于一些主题,包括一些近期的新闻和你作为首席技术官所负责的一些领域。希望我们能深入探讨其中的一些话题。 ### 职业生涯回顾 **主持人**: 我想我第一个问题是,考虑到你现在极其忙碌,以及新闻的攻击,有些好有些坏,你大约六年前加入了这个公司。那时,它是一个截然不同的组织。你相对低调,不太为人知晓。你是否怀念那些能够全神贯注工作的日子? **Mira**: 我想说,我们依旧全神贯注在工作中。只不过工作的内容已经发展变化了,它不仅仅关乎研究。也是因为,研究已经得到了很大的进展。这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中。所以,使命依然如一,我们在研究上也已经取得了很多进展,工作领域也在不断扩大。公众对此的关注度也很高,这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。但你要知道,鉴于我们所做的事情的重要性,这种关注是非常必要的,而且这是积极的。
L'essence de Prompt
Vous avez peut-être lu de nombreux articles en ligne sur la façon de rédiger des techniques de Prompt et mémorisé de nombreux modèles de Prompt, mais quelle est l'essence de Prompt ? Pourquoi avons-nous besoin de Prompt ?
L'invite est essentiellement une instruction de contrôle au LLM, décrite en langage naturel, qui permet au LLM de comprendre nos exigences et de transformer les entrées en sorties souhaitées, selon les besoins.
Par exemple, la technique des quelques coups couramment utilisée consiste à laisser le LLM comprendre nos exigences à l'aide d'exemples, puis à se référer aux échantillons pour produire les résultats souhaités. Par exemple, le CoT (Chain of Thought) consiste à décomposer artificiellement la tâche et à limiter le processus d'exécution, de sorte que le LLM puisse suivre le processus et les étapes que nous avons spécifiés, sans être trop diffus ou sauter les étapes clés, et obtenir ainsi de meilleurs résultats.
C'est comme lorsque nous étions à l'école, lorsque le professeur parlait de théorèmes mathématiques, il devait nous donner des exemples qui nous permettaient de comprendre la signification des théorèmes ; lorsque nous faisions des expériences, il devait nous indiquer les étapes des expériences, et même si nous ne comprenions pas les principes des expériences, mais que nous pouvions exécuter les expériences conformément aux étapes, nous pouvions toujours obtenir plus ou moins les mêmes résultats.
Pourquoi les résultats de Prompt sont-ils parfois loin d'être optimaux ?
Ceci est dû au fait que le LLM ne peut pas comprendre exactement nos exigences, qui sont limitées d'une part par la capacité du LLM à comprendre et à suivre des instructions, et d'autre part par la clarté et l'exactitude de la description de notre Prompt.
Comment contrôler précisément la sortie du LLM et définir sa logique d'exécution à l'aide d'un pseudo-code ?
Étant donné que Prompt est essentiellement une instruction de contrôle pour le LLM, nous pouvons écrire Prompt sans nous limiter aux descriptions traditionnelles en langage naturel, mais nous pouvons également utiliser du pseudocode pour contrôler précisément la sortie du LLM et définir sa logique d'exécution.
Qu'est-ce que le pseudo-code ?
Le pseudo-code est une méthode de description formelle des algorithmes, qui se situe entre le langage naturel et le langage de programmation pour décrire les étapes et les processus d'un algorithme. Dans divers livres et articles sur les algorithmes, nous voyons souvent la description du pseudo-code, même si vous n'avez pas besoin de connaître un langage, mais aussi à travers le pseudo-code pour comprendre l'exécution du flux de l'algorithme.
Dans quelle mesure LLM comprend-il le pseudo-code ? En fait, la compréhension du pseudo-code par LLM est assez forte, LLM a été formé avec beaucoup de code de qualité et peut facilement comprendre la signification du pseudo-code.
Comment écrire un pseudo-code Prompt ?
Le pseudo-code est très familier aux programmeurs, et pour les non-programmeurs, vous pouvez écrire du pseudo-code simple en vous rappelant quelques règles de base. Quelques exemples :
- Les variables, qui sont utilisées pour stocker des données, par exemple pour représenter les entrées ou les résultats intermédiaires par des symboles spécifiques.
- Type, utilisé pour définir le type de données, comme les chaînes de caractères, les nombres, les tableaux, etc.
- fonction qui définit la logique d'exécution d'une sous-tâche particulière
- Le flux de contrôle, utilisé pour contrôler le processus d'exécution du programme, tel que les boucles, les jugements conditionnels, etc.
- Si la condition A est remplie, la tâche A est exécutée, sinon la tâche B est exécutée.
- Une boucle for qui exécute une tâche pour chaque élément du tableau.
- Dans une boucle while, lorsque la condition A est remplie, la tâche B est exécutée en continu.
Écrivons maintenant le pseudo-code de l'invite, en utilisant les deux questions de réflexion précédentes comme exemple.
Pseudo-code pour produire un format JSON spécifique
Le format JSON souhaité peut être clairement décrit à l'aide d'un morceau de pseudo-code similaire à la définition de type TypeScript :
Please split the sentences into short segments, no more than 1 line (less than 80 characters, ~10 English words) each.
Please keep each segment meaningful, e.g. split from punctuations, "and", "that", "where", "what", "when", "who", "which" or "or" etc if possible, but keep those punctuations or words for splitting.
Do not add or remove any words or punctuation marks.
Input is an array of strings.
Output should be a valid json array of objects, each object contains a sentence and its segments.
Array<{
sentence: string;
segments: string[]
}>
Organiser les scripts de sous-titres avec du pseudo-code
Si vous imaginez écrire un programme pour accomplir cette tâche, il peut y avoir de nombreuses étapes, telles que l'extraction des chapitres, puis l'extraction des locuteurs, et enfin l'assemblage des dialogues en fonction des chapitres et des locuteurs. À l'aide du pseudo-code, nous pouvons décomposer cette tâche en plusieurs sous-tâches, pour lesquelles il n'est même pas nécessaire d'écrire un code spécifique, mais seulement de décrire clairement la logique d'exécution des sous-tâches. Il suffit de décrire clairement la logique d'exécution des sous-tâches. Il faut ensuite exécuter ces sous-tâches étape par étape et enfin intégrer les résultats obtenus.
Nous pouvons utiliser des variables pour stocker les données, telles que subject,speakers,chapters,paragraphs etc.
Lors de l'édition, nous pouvons également utiliser des boucles "For" pour parcourir les chapitres et les paragraphes, et des instructions "If-else" pour déterminer s'il est nécessaire d'afficher le nom de l'orateur.
Votre tâche consiste à réorganiser les transcriptions vidéo pour les rendre plus lisibles, et à reconnaître les locuteurs pour les dialogues à plusieurs personnes. Voici les pseudo-codes pour le faire
def extract_subject(transcript):
# Find the subject in the transcript and return it as a string.
def extract_chapters(transcript):
# Find the chapters in the transcript and return them as a list of strings.
def extract_speakers(transcript):
# Find the speakers in the transcript and return them as a list of strings.
def find_paragraphs_and_speakers_in_chapter(chapter):
# Find the paragraphs and speakers in a chapter and return them as a list of tuples.
# Each tuple contains the speaker and their paragraphs.
def format_transcript(transcript):
# extract the subject, speakers, chapters and print them
subject = extract_subject(transcript)
print("Subject:", subject)
speakers = extract_speakers(transcript)
print("Speakers:", speakers)
chapters = extract_chapters(transcript)
print("Chapters:", chapters)
# format the transcript
formatted_transcript = f"# {subject}\n\n"
for chapter in chapters:
formatted_transcript += f"## {chapter}\n\n"
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers:
# if there are multiple speakers, print the speaker's name before each paragraph
if speakers.size() > 1:
formatted_transcript += f"{speaker}:"
formatted_transcript += f"{speaker}:"
for paragraph in paragraphs:
formatted_transcript += f" {paragraph}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
Voyons ce qu'il en est :
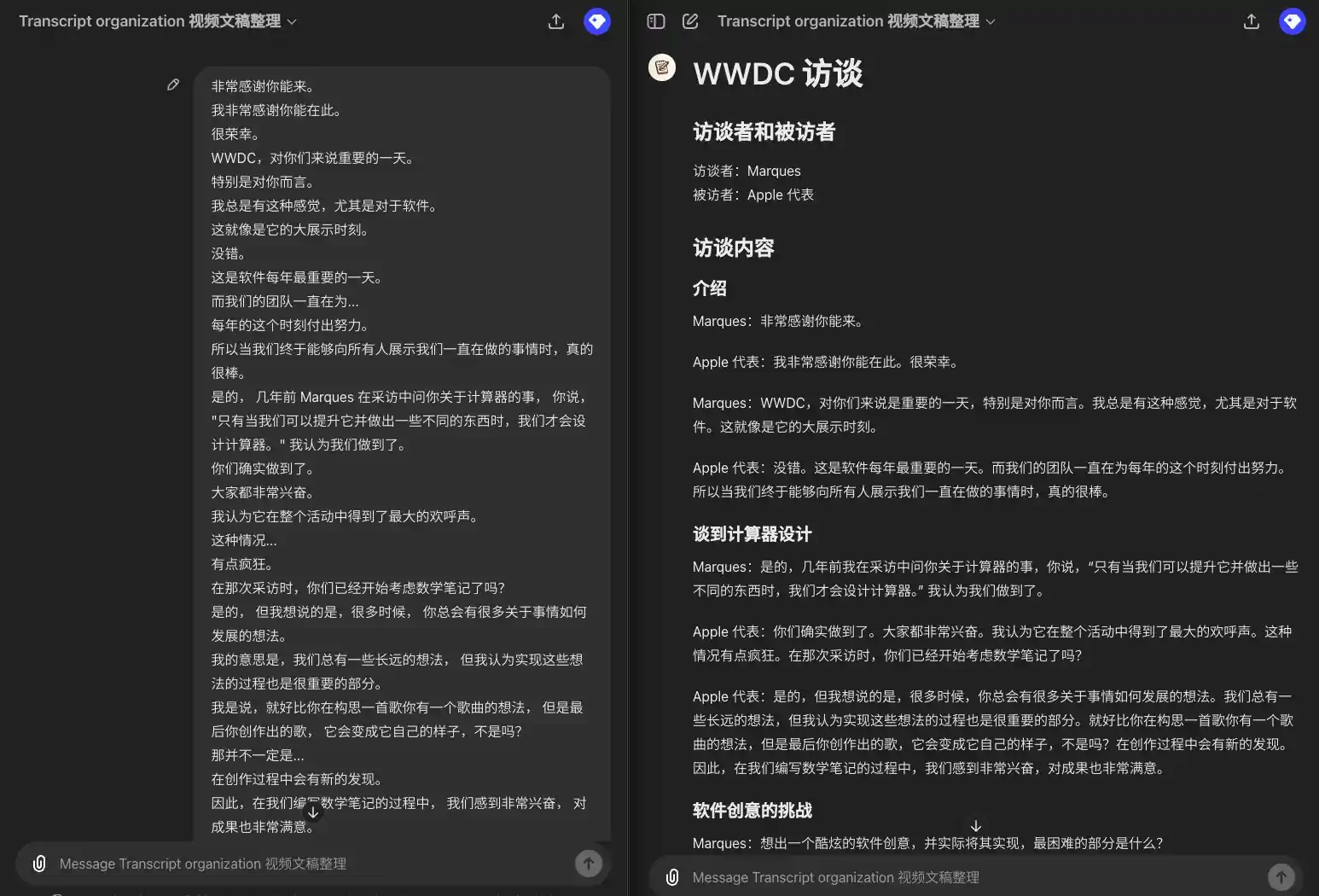
Rassembler les transcriptions d'accès à la WWDC
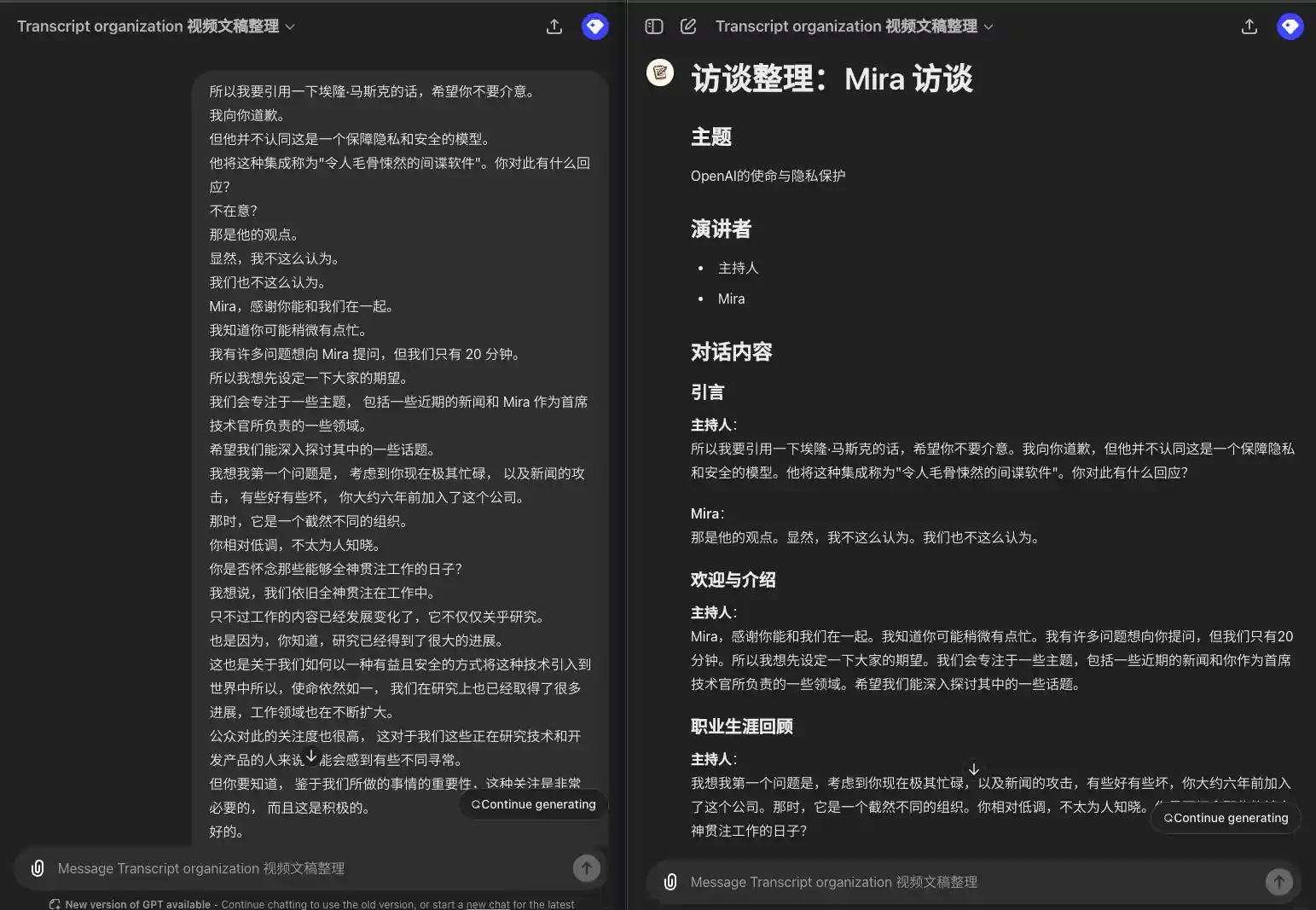
Orateurs multiples, orateurs de spectacle
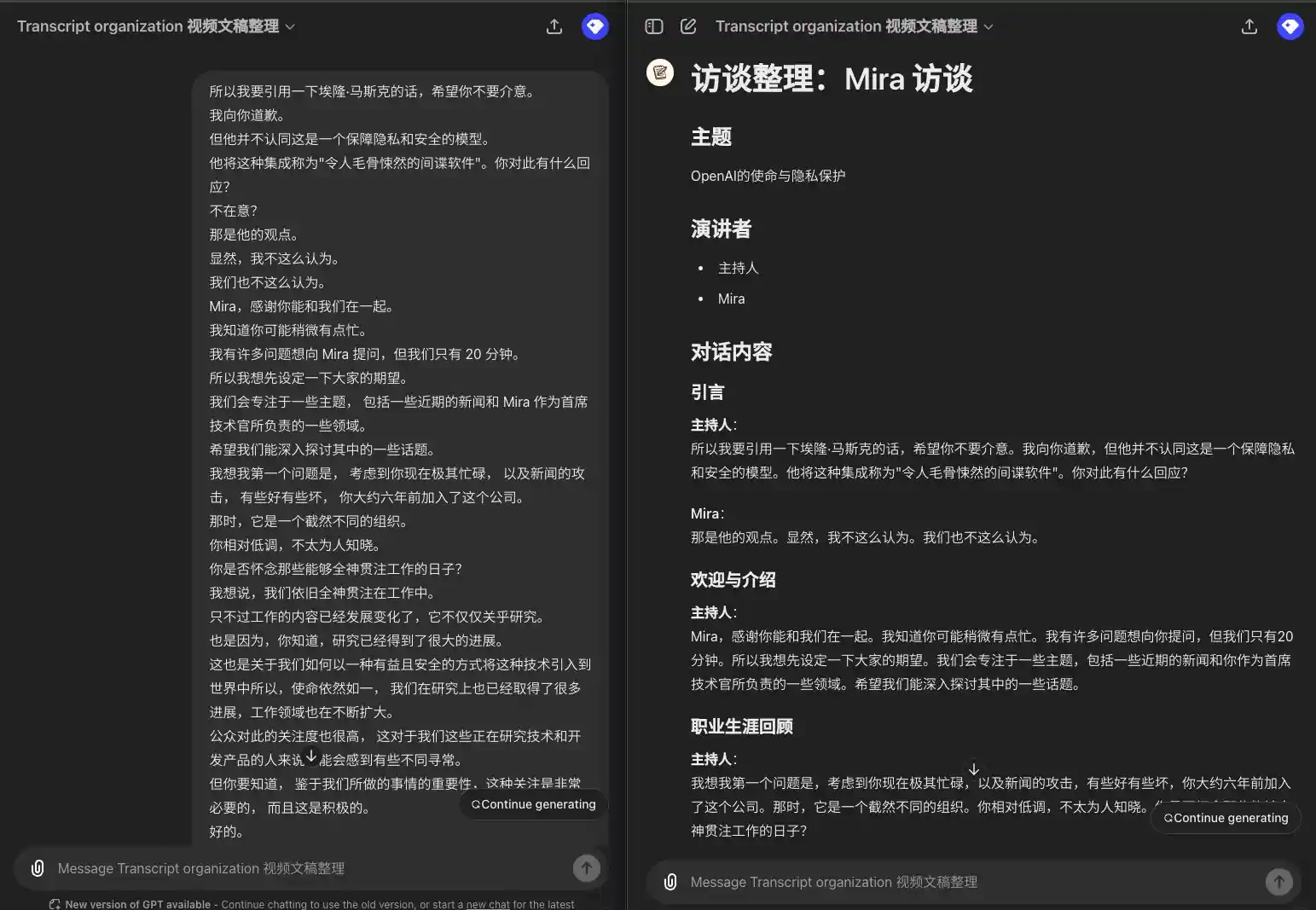
1 Haut-parleur, pas de haut-parleur illustré
Vous pouvez également utiliser le GPT que j'ai généré avec cette invite :Organisation de la transcription GPT
Faire en sorte que ChatGPT dessine plusieurs images à la fois avec un pseudo-code
J'ai également appris récemment une utilisation très intéressante du terme par un net-citoyen taïwanais, Sensei Yoon Sang-chi.Faire en sorte que ChatGPT dessine plusieurs images à la fois avec du pseudo-code.
Maintenant, si vous voulez faire ChatGPT Si vous souhaitez générer plus d'une image à la fois, vous pouvez utiliser le pseudo-code pour décomposer la tâche de génération de plusieurs images en plusieurs sous-tâches, puis exécuter plusieurs sous-tâches à la fois et enfin intégrer le résultat.
下面是一段画图的伪代码,请按照伪代码的逻辑,用DALL-E画图:
images_prompts = [
{
style: "Kawaii",
prompt: "Draw a cute dog",
aspectRatio: "Wide"
},
{
style: "Realistic",
prompt: "Draw a realistic dog",
aspectRatio: "Square"
}
]
images_prompts.forEach((image_prompt) =>{
print("Generating image with style: " + image_prompt.style + " and prompt: " + image_prompt.prompt + " and aspect ratio: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})

résumés
Grâce à l'exemple ci-dessus, nous pouvons voir qu'avec l'aide du pseudo-code, nous pouvons contrôler plus précisément le résultat de sortie de LLM et définir sa logique d'exécution, au lieu de nous limiter à la description en langage naturel. Lorsque nous rencontrons des tâches complexes, ou des tâches avec plusieurs branches, chaque branche doit exécuter plusieurs sous-tâches, et les sous-tâches sont liées les unes aux autres, l'utilisation du pseudo-code pour décrire l'invite sera plus claire et plus précise.
Lorsque nous écrivons une invite, nous nous rappelons qu'une invite est essentiellement une instruction de contrôle pour le LLM, décrite en langage naturel, qui permet au LLM de comprendre ce que nous voulons, puis de transformer les entrées en sorties que nous attendons, selon les besoins. En ce qui concerne la forme de description de l'invite, elle peut être flexible sous de nombreuses formes, telles que few-shot, CoT, pseudo-code, etc.
Plus d'exemples :
Générer des méta-intervites en "pseudo-code" pour un contrôle précis du formatage de la sortie.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...