
Évaluer la créativité dans les grands modèles de langage : au-delà du paradigme LoTbench à choix multiples
Dans le grand modèle linguistique ( LLM ), la modélisation de la Leap-of-Thought La capacité, ou la créativité, est aussi importante que la capacité à Chain-of-Thought pour les compétences de raisonnement logique représentées. Toutefois, on observe actuellement une augmentation significative du nombre d'étudiants ciblant les compétences de raisonnement logique. LLM Les discussions approfondies sur la créativité et les méthodes d'évaluation efficaces sont encore relativement rares, ce qui, dans une certaine mesure, limite les possibilités d'évaluation de la créativité. LLM Potentiel de développement des applications créatives.
La raison principale en est qu'il est extrêmement difficile d'élaborer un processus d'évaluation objectif, automatisé et fiable pour le concept abstrait de "créativité".
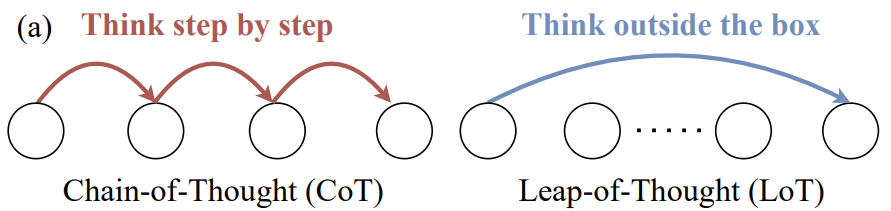
Dans le passé, de nombreuses réponses aux LLM Les tentatives de mesure de la créativité, comme le montre la figure 1, continuent d'utiliser des questions à choix multiples et des questions séquentielles, qui sont couramment utilisées pour évaluer les capacités de raisonnement logique. Ces méthodes permettent de vérifier si le modèle peut identifier l'option prédéfinie "la meilleure" ou "la plus logique", mais elles ne permettent pas d'évaluer la véritable créativité, c'est-à-dire la capacité à générer un contenu nouveau et unique. Mais elles ne permettent pas d'évaluer la véritable créativité, c'est-à-dire la capacité à générer un contenu nouveau et unique.
Par exemple, considérons la tâche de la figure 2 : sur la base de l'image et du texte existant, remplissez le " ? Le contenu doit être créatif et humoristique.
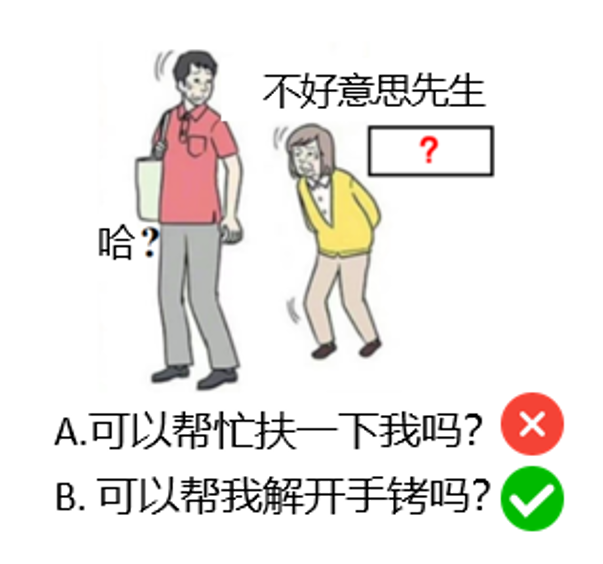
S'il s'agit d'une question à choix multiple, proposez les options "A. Pouvez-vous m'aider ?" et "B. Pouvez-vous m'aider à me libérer de mes menottes ?" et "B. Pouvez-vous me détacher ?". et "B. Pouvez-vous me détacher les menottes ?" et "B. Pouvez-vous m'aider à enlever les menottes ? LLM B sera probablement choisi, non pas parce qu'il fait preuve de créativité, mais simplement parce que l'option B est plus "spéciale" ou "inhabituelle" que l'option A, et que le modèle est capable de faire un choix en reconnaissant des schémas plutôt qu'en faisant preuve de créativité.
évaluation LLM de la créativité, il convient d'examiner le noyau pour en déterminer les caractéristiques.générantLa capacité d'innover en matière de contenu plutôt que dejaugeLa capacité du contenu à être innovant ou non. Les méthodes d'évaluation traditionnelles, telles que le choix multiple, sont davantage axées sur ce dernier aspect et présentent donc des limites. Actuellement, les principales méthodes qui permettent une évaluation directe de la capacité générative sont l'évaluation manuelle et les LLM-as-a-judge (Utiliser LLM (en tant que revue). Les évaluations manuelles, bien que précises et conformes aux valeurs humaines, sont coûteuses et difficiles à mettre à l'échelle. Alors que LLM-as-a-judge La performance de la méthode sur les tâches d'évaluation de la créativité est encore immature et la stabilité des résultats doit être améliorée.
Face à ces défis, des chercheurs de l'université Sun Yat-sen, de l'université de Harvard, du laboratoire Pengcheng et de l'université de gestion de Singapour ont proposé une nouvelle façon de penser. Au lieu de juger directement de la "qualité" du contenu généré, ils examinent la "qualité" du contenu en étudiant les éléments suivants LLM Le "coût" de la production d'une réponse comparable au contenu d'innovations humaines de haute qualité(qui peut être interprété comme l'effort requis ou le coût de l'interaction), a construit un système appelé LoTbench d'un paradigme d'évaluation automatisée et interactive de la créativité à plusieurs tours. La méthode vise à fournir une mesure plus crédible et évolutive de la créativité. Des résultats de recherche connexes ont été publiés dans IEEE TPAMI Journal.

- Titre de la thèse : Un paradigme conscient de la causalité pour évaluer la créativité des grands modèles linguistiques multimodaux
- Lien vers l'article : https://arxiv.org/abs/2501.15147
- Page d'accueil du projet : https://lotbench.github.io
Scène de la mission : La flèche froide japonaise
LoTbench L'étude est basée sur CVPR'24 Une extension du travail présenté à la conférence Let's Think Outside the Box : Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation (Penser en dehors de la boîte : explorer le saut de la pensée dans les grands modèles linguistiques avec une génération d'humour créative). Generation). Les chercheurs ont choisi une forme de tâche dérivée du jeu japonais traditionnel Oogiri, connu sous le nom de "Trolling froid japonais" sur l'Internet chinois, comme le montre la figure 2.
Ce type de tâche exige des participants qu'ils regardent des images et complètent le texte, ce qui rend la combinaison d'images et de texte innovante et humoristique. Cette tâche a été choisie comme base de l'évaluation sur la base des considérations suivantes :
- Exigences élevées en matière de créativité : Il s'agissait d'une demande directe de générer un contenu humoristique créatif, un défi de créativité typique.
- Ajustement du modèle multimodal : L'entrée est graphique, la sortie est textuelle, totalement conforme aux normes multimodales actuelles.
LLMLe champ de compétence de la - Des ressources de données riches : La popularité du "Cold Trolling japonais" dans la communauté en ligne a permis d'accumuler un grand nombre d'exemples de haute qualité de créations humaines et de données avec des informations d'évaluation, ce qui facilite la construction d'ensembles de données d'évaluation.
Ainsi, le "crachat froid japonais" constitue un outil utile pour évaluer les méthodes multimodales d'évaluation de la qualité de l'eau. LLM de la créativité offre une plateforme idéale et unique.
Méthodologie d'évaluation de LoTbench

Contrairement aux paradigmes d'évaluation traditionnels (par exemple, la sélection, le classement), l'approche de l'évaluation de la qualité de l'eau est une approche de la qualité de l'eau. LoTbench L'idée de base est la suivante :Mesurer un LLM Combien de cycles d'interactions sont nécessaires pour générer une réponse d'innovation de qualité humaine qui corresponde à la valeur prédéfinie ( HHCR La réponse est "la même". Ce "nombre de tours" requis reflète LLM La "distance" ou le "coût" pour atteindre un objectif créatif particulier.
Comme le montre la partie droite de la figure 3, pour une valeur donnée de HHCR (math.) genre LoTbench Ce n'est pas une obligation LLM Reproduisez-le exactement, mais regardez plutôt les LLM Est-il possible de générer, en plusieurs séries de tentatives, une idée qui, bien qu'exprimée différemment, possède un noyau créatif et un effet similaires (c'est-à-dire une "idée") ? DAESO - Une approche différente mais un résultat tout aussi satisfaisant).
LoTbench Le déroulement spécifique du processus est illustré à la figure 4 :
- Construction des tâches : Sélectionné à partir des données "Japanese Cold Tweets".
HHCRÉchantillon. Pour chaque tour, il est demandé que l'épreuve à réaliser soitLLMGénérer une réponse sur la base des informations graphiquesRtpour combler les lacunes du texte. - Jugement du DAESO : Juger le produit
RtEst-il pertinent par rapport à l'objectif ?HHCR(dénomméR) a atteint leDAESO. Si oui, enregistrez le nombre actuel de tours pour les calculs ultérieurs de score ; si non, passez à l'étape 3. - Questionnement interactif : Si ce n'est pas le cas
DAESOSi l'essai doit être effectué sur le même navire, il est nécessaire que leLLMUne question générale basée sur l'historique de l'interaction actuelleQt(par exemple, en demandant des indices sur l'orientation créative visée). - Retour d'information sur le système : Le système d'évaluation est basé sur
HHCRLa logique interne duLLMQuestions soulevéesQtRépondez par "oui" ou "non". - Intégration de l'information et itération : Mettez toutes les informations relatives à l'interaction pour ce tour (y compris le
LLM) et l'intégration des invites fournies par le système pour former le tour suivant de l'enquête.history promptSi vous n'êtes pas sûr, revenez à l'étape 1 et recommencez une nouvelle série de tentatives.
Ce processus se poursuit jusqu'à ce que LLM généré DAESO ou que la limite maximale prédéfinie a été atteinte.
Score final de créativité Sc sur la base d'un examen des n classificateur pour les choses ou les personnes individuelles, classificateur général, fourre-tout HHCR Échantillon, conduite m Les résultats ont été calculés à partir des résultats de plusieurs répétitions de l'expérience. Les calculs sont approximativement les suivants (en formules HTML) :
Sc = ( 1 / n ) ∑i=1n [ ( 1 / m ) ∑j=1m ( 1 / ( 1 + kij ) ) ]
Parmi eux.k_ij est le modèle du premier j La deuxième répétition de l'expérience pour le premier i classificateur pour les choses ou les personnes individuelles, classificateur général, fourre-tout HHCR échantillons, en générant avec succès des DAESO Le nombre de tours utilisés pour la réponse.
Ce score de créativité Sc Avec les caractéristiques suivantes :
- Relation inverse : Score et nombre de tours requis
kInversement proportionnel. Plus le nombre de tours est faible, plusLLMPlus vous atteignez rapidement votre niveau de créativité, plus votre score est élevé et plus vous êtes créatif. - Limite inférieure de zéro point : au cas où
LLMNe parvient pas systématiquement à produire dans la limite du nombre maximal de tours.DAESO(équivalent au nombre de tours tendant vers l'infini), son score pour cet échantillon tend vers 0, indiquant une créativité insuffisante dans cette tâche. - Robustesse : Cela se fait par l'utilisation de plusieurs
HHCRLa moyenne des échantillons a été calculée sur plusieurs répétitions de l'expérience, et les notes tiennent compte de la diversité et de la difficulté des idées, ce qui réduit l'effet du hasard dans une seule expérience.
Comment déterminer les "similitudes et les différences" ( DAESO ) ?
DAESO La détermination de la LoTbench L'une des principales difficultés de la méthodologie.
Pourquoi vous en avez besoin ? DAESO Le jugement ? L'une des principales caractéristiques des tâches de créativité est leur ouverture et leur variété. Les humains peuvent proposer des réponses différentes, mais tout aussi créatives et humoristiques, au même scénario de "troll froid japonais". Comme le montre la figure 5, "réveil vibrant" et "téléphone portable vibrant" sont tous deux centrés sur l'idée centrale de "l'objet bat et émet un son en raison de sa vivacité", et produisent des effets humoristiques similaires. L'effet humoristique est similaire.
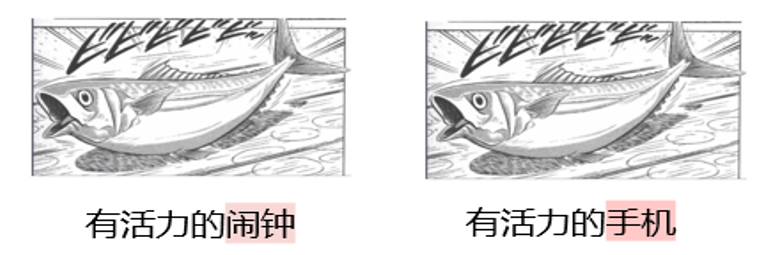
Ces similitudes créatives profondes ne peuvent pas être saisies avec précision par une simple mise en correspondance de la surface du texte ou par des calculs conventionnels de similarité sémantique. Par exemple, bien que "puce énergique" contienne également le mot "énergique", il n'y a pas l'association fonctionnelle de "rappel sonore" impliquée par "réveil" ou "téléphone portable". L'association fonctionnelle "rappel sonore" impliquée par "réveil" ou "téléphone portable" est absente. Il est donc important d'introduire un mécanisme permettant de déterminer les "similitudes et les différences".
Comment réaliser DAESO Le jugement ?
Dans le document, le chercheur suggère que les deux réponses qui doivent satisfaire les exigences de l'UE sont les suivantes DAESO Deux conditions doivent être remplies en même temps :
- La même innovation de base est expliquée : La logique créative ou l'humour qui sous-tend les deux réponses est essentiellement la même.
- Même similarité fonctionnelle : Les deux réponses sont similaires en ce qui concerne la "fonction" ou le "rôle de la scène" qui provoque l'humour.
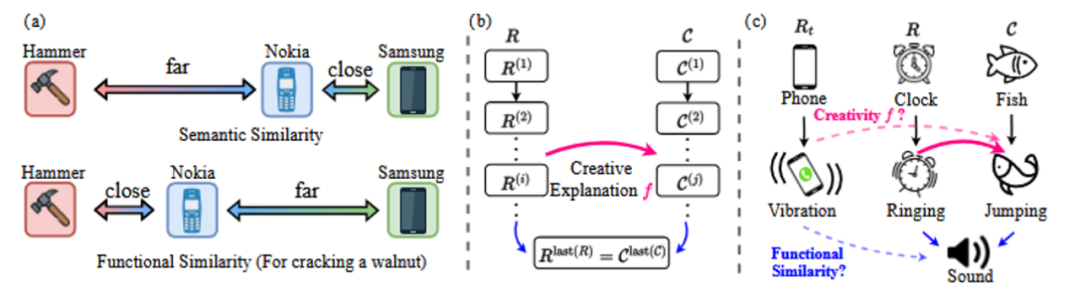
La similarité fonctionnelle est différente de la similarité sémantique pure. Comme le montre l'exemple de la figure 6(a), dans le scénario fonctionnel spécifique "casser des noix", la similarité fonctionnelle entre "téléphone portable Nokia" et "marteau" peut être plus élevée que la similarité sémantique entre "téléphone portable Samsung" et "téléphone portable Samsung". La similarité sémantique entre "téléphone portable Nokia" et "marteau" peut être plus élevée que celle entre "téléphone portable Samsung" et "téléphone portable Samsung".
Le fait de ne rencontrer que la même interprétation de l'innovation centrale peut donner lieu à une réponse qui s'écarte du thème (par exemple, la "puce vibrante" dans l'exemple de la figure 5, qui n'a pas la fonction de "rappel vocal") ; le fait de ne rencontrer que la même similitude fonctionnelle peut ne pas saisir le cœur de l'idée (par exemple, le "tambour vibrant" dans l'exemple de la figure 5, qui est également un objet vocal, mais qui n'a pas la sensation de battre en raison de sa propre "vibration"). Le "tambour énergique" dans l'exemple de la figure 5 est également un objet audible, mais il ne donne pas la sensation de battre en raison de sa propre "vigueur").
concrètement DAESO Lors de la réalisation du jugement, le chercheur fournit d'abord un nouvel ensemble de critères pour chaque HHCR Les échantillons ont été étiquetés avec une explication détaillée de la source de leur humour et de leur créativité. Ensuite, les informations relatives au titre (légende) de l'image ont été combinées et utilisées avec les informations relatives à l'humour et à la créativité. LLM dans l'espace textuel, pour la capacité à HHCR Construire une chaîne de causalité (comme le montre la figure 6(c)) pour analyser sa composition créative. Enfin, concevoir des instructions spécifiques (instruction) pour une autre LLM (par exemple GPT-4o mini ) Sur la base de ces informations, la réponse à mesurer est jugée dans l'espace texte Rt collaboration avec target HHCR Si les deux cas de figure précédents se présentent DAESO État.
Des études ont montré que l'utilisation de GPT-4o mini aller de l'avant DAESO la précision de 80%-90% peut être obtenue à un coût de calcul moindre. Si l'on considère les LoTbench Plusieurs répétitions de l'expérience seront effectuées, avec une seule DAESO L'effet des petites erreurs de jugement sur la note moyenne finale est encore réduit, ce qui garantit la fiabilité de l'évaluation globale.
Résultats de l'évaluation
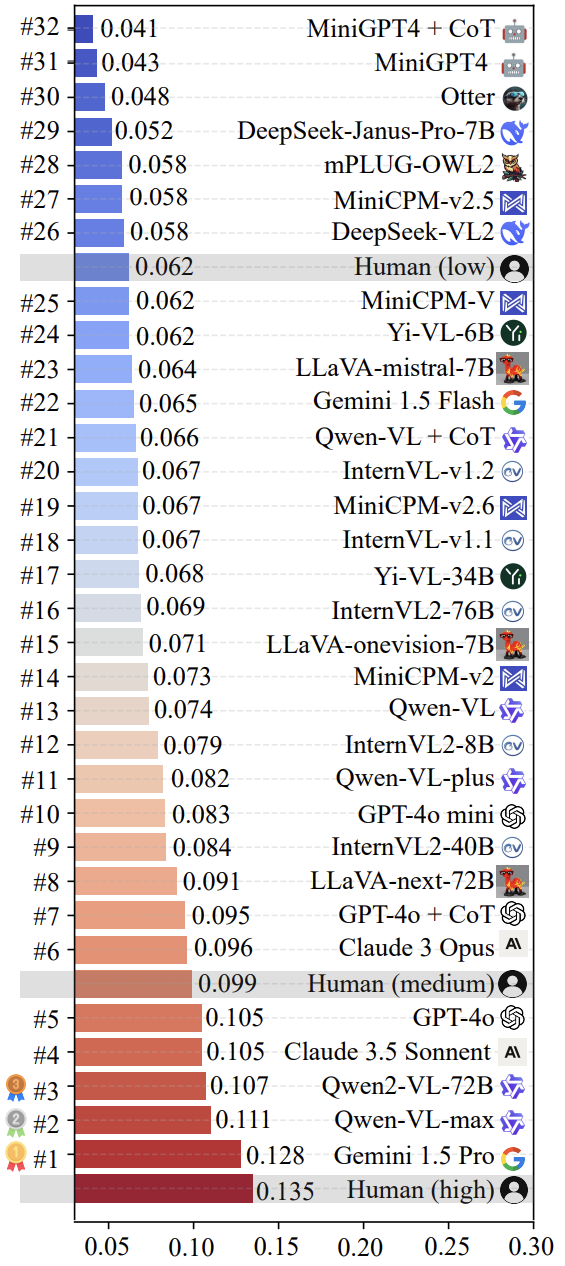
L'équipe de recherche a utilisé LoTbench Un examen de certains des principaux systèmes multimodaux actuels est nécessaire. LLM L'évaluation a été réalisée. Comme le montre la figure 7, les résultats montrent que les résultats sont fondés sur le modèle de la LoTbench La mesure standard de l'existant LLM de la créativité n'est généralement pas considérée comme forte, comparée à une réponse créative humaine de haute qualité ( HHCR ) ne sont toujours pas à la hauteur. Toutefois, par rapport au niveau humain général (qui n'est pas explicitement indiqué dans la figure, mais qui est déduit) ou au niveau humain primaire, certains des principaux niveaux de l LLM (par exemple Gemini 1.5 Pro répondre en chantant Qwen-VL-max ) a fait preuve d'une certaine compétitivité et laisse entrevoir la possibilité d'une nouvelle stratégie de développement. LLM Possède le potentiel de transcender l'humanité en termes de créativité.
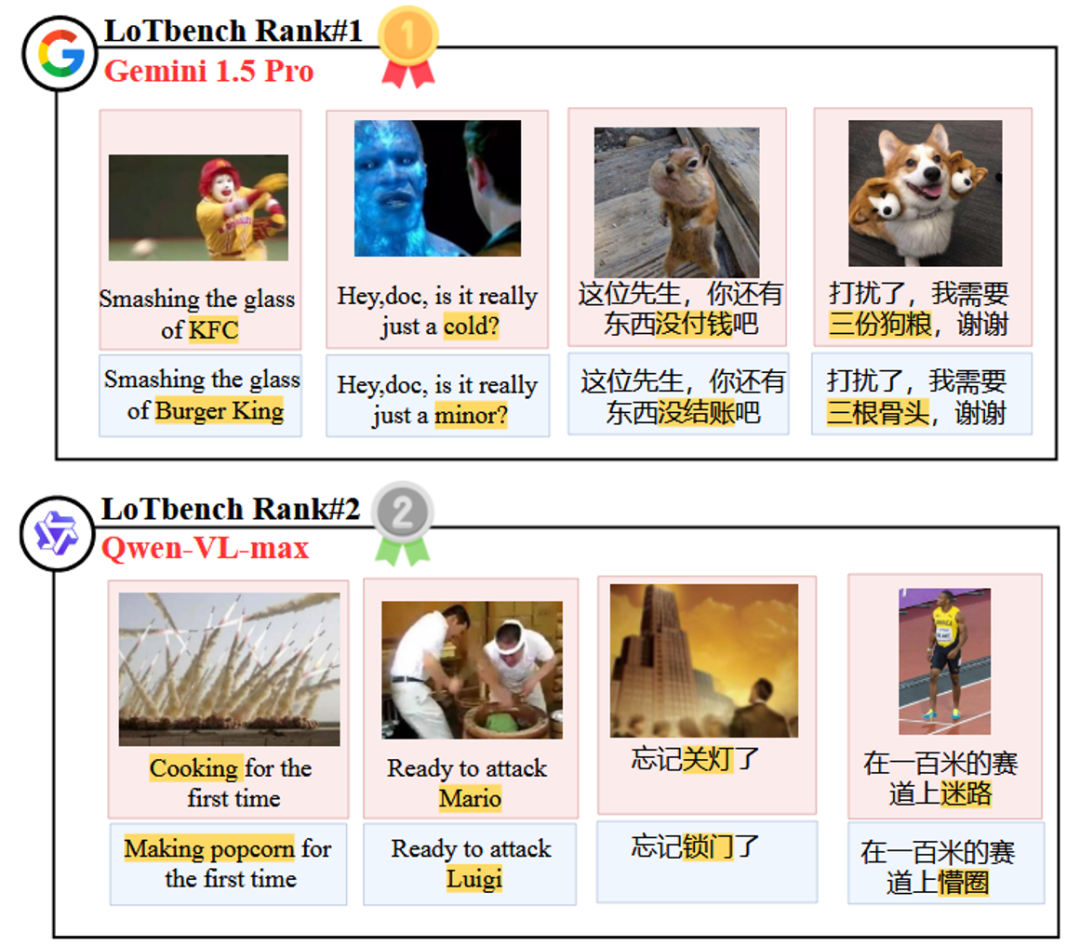
La figure 8 présente les deux premiers de la liste des Gemini 1.5 Pro répondre en chantant Qwen-VL-max composante spécifique au modèle HHCR (marquées en rouge) ont généré DAESO Réponse (en bleu).
Il convient de noter que la récente et très médiatisée affaire de la DeepSeek-VL2 répondre en chantant Janus-Pro-7B Les modèles de séries ont également été évalués. Les résultats ont montré que leur créativité en LoTbench se situe à peu près au niveau du primaire humain. Cela suggère qu'en améliorant la qualité de l'information multimodale, il est possible d'améliorer la qualité de l'information. LLM Il existe encore une marge de manœuvre considérable en ce qui concerne la créativité profonde de la
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...