
Publication de l'OpenAI : Applications et bonnes pratiques pour les modèles d'inférence en IA
Dans le domaine de l'IA, le choix du modèle est crucial. openAI, un leader de l'industrie, offre une famille de modèles de deux types principaux :modèle d'inférence (Modèles de raisonnement) et Modèle GPT (modèles GPT). La première est représentée par les modèles de la série o, tels que o1 répondre en chantant o3-miniCe dernier est connu pour sa famille de modèles GPT, tels que le GPT-4o. Pour exploiter pleinement le potentiel de l'IA, il est essentiel de comprendre les différences entre ces deux types de modèles et les scénarios d'application dans lesquels ils excellent.
Le présent article se penche sur cette question :
- Principales différences entre les modèles d'inférence de l'OpenAI et les modèles GPT.
- Quand donner la priorité à l'utilisation des modèles d'inférence de l'OpenAI.
- Comment utiliser efficacement les modèles d'inférence pour obtenir des performances optimales.
L'autre jour, les ingénieurs de Microsoft ont publié une Ingénierie des indices pour les modèles d'inférence OpenAI O1 et O3-mini Il est donc possible de comparer les différences d'application entre les deux.
Modèles d'inférence et modèles GPT : stratèges et exécutants
Les modèles d'inférence de la série o de l'OpenAI, par opposition aux modèles GPT familiers, présentent leurs propres forces dans différents types de tâches et requièrent différentes stratégies de repérage. Il est important de comprendre que ces deux types de modèles ne sont pas simplement meilleurs ou pires, mais qu'ils ont des capacités différentes. Cela reflète les efforts continus de l'OpenAI pour repousser les limites des capacités de ses modèles afin de répondre aux besoins d'applications de plus en plus complexes qui nécessitent un raisonnement approfondi.
OpenAI a spécialement entraîné les modèles de la série o, dont le nom de code interne est Planners, à réfléchir plus longuement et plus profondément, ce qui leur permet d'exceller dans des domaines tels que la formulation de stratégies, la planification de problèmes complexes et la prise de décisions fondées sur de grandes quantités d'informations ambiguës. La capacité de ces modèles à accomplir des tâches avec un haut degré de précision et d'exactitude les rend idéaux pour les domaines qui dépendent traditionnellement d'experts humains, tels que les domaines spécialisés des mathématiques, des sciences, de l'ingénierie, des services financiers et des services juridiques.
En revanche, les modèles GPT d'OpenAI (dont le nom de code interne est "Workhorses") sont plus économiques et à faible latence, et sont conçus pour l'exécution directe de tâches. Dans la pratique, il est courant d'utiliser une combinaison de ces deux types de modèles : utiliser les modèles de la série O pour formuler une macro-stratégie de résolution de problèmes, puis exécuter efficacement des sous-tâches spécifiques à l'aide des modèles GPT, en particulier dans les scénarios où la vitesse et le rapport coût-efficacité sont plus importants que la précision absolue. Cette répartition des tâches reflète la maturité de la philosophie de conception des modèles d'IA, qui sépare la planification de l'exécution.
Comment choisir le bon modèle ? Comprendre ses besoins
Pour choisir un modèle, il est essentiel de définir les exigences fondamentales de votre scénario d'application :
- Rapidité et coût. Si la vitesse et la rentabilité sont vos priorités, le modèle GPT est généralement le choix le plus rapide et le plus économique.
- Des tâches clairement définies. Pour les applications ayant des objectifs clairs et des limites de tâches bien définies, le modèle GPT est capable d'exceller dans les tâches d'exécution.
- Précision et fiabilité. Si votre application exige le plus haut niveau de précision et de fiabilité des résultats, les modèles de la série o sont les décideurs les plus fiables.
- Résolution de problèmes complexes. Face à l'ambiguïté et à la complexité, les modèles de la série o sont capables de faire face efficacement.
Ainsi, si la vitesse et le coût sont des considérations primordiales, et que vos cas d'utilisation impliquent principalement des tâches simples et bien définies, les modèles GPT d'OpenAI sont idéaux. En revanche, si la précision et la fiabilité sont essentielles et que vous résolvez des problèmes complexes en plusieurs étapes, les modèles de la série o d'OpenAI peuvent être mieux adaptés à vos besoins.
Dans de nombreux flux de travail d'IA dans le monde réel, la meilleure pratique consiste à utiliser une combinaison de ces deux modèles : la famille de modèles o agit comme un "planificateur" responsable de la planification et de la prise de décision de l'agent, tandis que la famille de modèles GPT agit comme un "exécuteur" responsable de l'exécution de tâches spécifiques. Cette stratégie de combinaison permet d'exploiter pleinement les points forts des deux types de modèles.

Par exemple, les modèles GPT-4o et GPT-4o mini d'OpenAI peuvent être utilisés dans des scénarios de service à la clientèle, où les informations sur les clients sont d'abord utilisées pour classer les détails de la commande, identifier les problèmes de commande et les politiques de retour, puis ces points de données sont introduits dans le modèle o3-mini, qui prend la décision finale sur la faisabilité d'un retour sur la base de politiques prédéfinies.
Scénarios d'application des modèles d'inférence : exceller dans la complexité et l'ambiguïté
OpenAI a développé quelques modèles typiques d'applications réussies de ses modèles d'inférence grâce à la collaboration avec les clients et à des observations internes. La liste suivante de scénarios d'application n'est pas exhaustive, mais se veut un guide pratique pour vous aider à mieux évaluer et tester les modèles de la série o d'OpenAI.
1. naviguer dans des tâches ambiguës : comprendre l'intention à partir d'informations fragmentées
Les modèles de raisonnement sont particulièrement efficaces pour traiter les tâches comportant des informations incomplètes ou dispersées. Même lorsqu'ils sont sollicités avec des informations limitées, les modèles d'inférence peuvent comprendre efficacement l'intention réelle de l'utilisateur et traiter les ambiguïtés des instructions de manière appropriée. Il convient de mentionner que les modèles d'inférence ne se précipitent généralement pas pour faire des suppositions imprudentes ou essayer de combler les lacunes d'information par eux-mêmes, mais qu'ils posent plutôt des questions de clarification de manière proactive pour s'assurer que les exigences de la tâche sont bien comprises. Il s'agit là d'un bon exemple des avantages des modèles de raisonnement lorsqu'ils sont confrontés à l'incertitude et à des tâches complexes.
Hebbia, une plateforme de connaissances en IA pour les secteurs juridique et financier, a déclaré : "Les capacités d'inférence supérieures de o1 permettent à Matrix, la plateforme multi-agents d'OpenAI, de traiter efficacement des documents complexes et de générer des réponses détaillées, bien structurées et informatives. Par exemple, o1 permet à Matrix d'identifier facilement, à l'aide de simples invites, la somme d'argent disponible dans le cadre d'un contrat de crédit avec une capacité de paiement restreinte. Aucun autre modèle n'a atteint ce niveau de performance. Dans les tests intensifs de repérage complexe de contrats de crédit du 52%, o1 a obtenu des résultats plus significatifs que les autres modèles".
-Hebbia, une entreprise de plateforme de connaissances en IA pour les secteurs juridique et financier.
2. recherche d'informations : trouver l'aiguille dans la botte de foin, localiser l'endroit où elle se trouve
Confronté à des quantités massives d'informations non structurées, le modèle d'inférence fait preuve d'une grande compréhension des informations et est capable d'extraire avec précision les informations les plus pertinentes par rapport à la question, répondant ainsi efficacement à la question de l'utilisateur. Cela met en évidence les performances supérieures des modèles d'inférence dans la recherche d'informations et le filtrage d'informations clés, en particulier lorsqu'il s'agit d'ensembles de données à grande échelle.
Endex, une plateforme d'intelligence financière basée sur l'IA, partage : "Pour analyser en profondeur les acquisitions d'entreprises, le modèle o1 a été utilisé pour examiner des dizaines de documents de l'entreprise, y compris des contrats et des accords de location, dans le but de trouver des clauses potentielles qui pourraient avoir un impact négatif sur l'accord. Le modèle a été chargé de repérer les clauses clés. Ce faisant, o1 a identifié avec précision une clause clé de "changement de contrôle" dans une note de bas de page : une clause qui exigeait le remboursement immédiat d'un prêt de 75 millions de dollars en cas de vente de l'entreprise. Le grand souci du détail d'o1 permet aux agents d'IA d'OpenAI de soutenir efficacement le travail des professionnels de la finance en identifiant avec précision les informations essentielles à leur mission".
--Endex, plateforme d'intelligence financière AI
3. découverte des relations et identification des nuances : approfondir la valeur des données
L'OpenAI a constaté que les modèles d'inférence sont particulièrement efficaces pour analyser des documents denses et non structurés de plusieurs centaines de pages, tels que des contrats juridiques, des états financiers et des déclarations d'assurance. Ces modèles sont efficaces pour extraire des informations de documents complexes, établir des liens entre différents documents et prendre des décisions déductives basées sur des faits implicites dans les données. Cela montre que les modèles d'inférence présentent des avantages significatifs pour le traitement de documents complexes et l'extraction d'informations approfondies.
Blue J, une plateforme d'IA pour la recherche fiscale, mentionne : "La recherche fiscale nécessite souvent l'intégration d'informations provenant de plusieurs documents pour former une conclusion finale convaincante. Après avoir remplacé le modèle GPT-4o par le modèle o1, OpenAI a constaté que o1 est plus performant pour raisonner sur les interactions entre les documents, et est capable de tirer des conclusions logiques qui ne sont pas apparentes dans un seul document. En conséquence, en passant au modèle o1, OpenAI a constaté une amélioration impressionnante de 4 fois la performance de bout en bout.
--Blue J, plateforme d'IA pour la recherche fiscale
Les modèles de raisonnement sont également capables de comprendre des politiques et des règles nuancées et de les appliquer à des tâches spécifiques pour parvenir à des conclusions raisonnables.
BlueFlame AI, une plateforme d'IA pour la gestion des investissements, donne un exemple : "Dans le domaine de l'analyse financière, les analystes sont souvent amenés à traiter des situations complexes liées aux droits des actionnaires et doivent avoir une compréhension approfondie des complexités juridiques associées. OpenAI a testé une dizaine de modèles provenant de différents fournisseurs en se posant une question difficile mais courante : comment le comportement de financement affectera-t-il les actionnaires existants, en particulier lorsqu'ils exercent leur privilège anti-dilution ? Cette question nécessite de raisonner sur les valorisations de l'entreprise avant et après le financement et de traiter les complexités de la dilution cyclique - une question qui prendrait même aux meilleurs analystes financiers 20 à 30 minutes pour s'y retrouver. OpenAI a constaté que les modèles o1 et o3-mini résolvaient parfaitement ce problème ! Les modèles ont même généré un tableau de calcul clair montrant en détail l'impact du comportement de financement sur des actionnaires de 100 000 dollars."
--BlueFlame AI, une plateforme d'IA pour la gestion des investissements
4. la planification de l'agence en plusieurs étapes : un plan stratégique pour les opérations, une stratégie pour le succès
Les modèles d'inférence jouent un rôle crucial dans la planification des agents et la formulation des stratégies. L'OpenAI a observé que les modèles d'inférence, lorsqu'ils sont positionnés en tant que "planificateurs", sont capables de générer des solutions détaillées en plusieurs étapes à des problèmes complexes. Par la suite, le système peut sélectionner et affecter le modèle GPT ("exécuteur") le plus approprié pour exécuter chaque étape, en fonction des exigences variables en matière de latence et d'intelligence. Cela démontre une fois de plus les avantages de l'utilisation d'une combinaison de modèles, le modèle d'inférence agissant comme le "cerveau" pour la planification de la stratégie et le modèle GPT comme les "bras et les jambes" pour l'exécution.
Argon AI, une plateforme de connaissances en IA pour l'industrie pharmaceutique, révèle que "OpenAI utilise le modèle o1 comme planificateur dans son infrastructure d'agents, ce qui lui permet d'orchestrer d'autres modèles dans le flux de travail afin d'accomplir efficacement des tâches à plusieurs étapes. OpenAI a constaté que le modèle o1 est très efficace pour choisir le bon type de données et décomposer les problèmes complexes et de grande envergure en modules plus petits et gérables, de sorte que les autres modèles puissent se concentrer sur des exécutions spécifiques."
--Argon AI, une plateforme de connaissances en IA pour l'industrie pharmaceutique
Lindy.AI, un assistant IA de travail, a partagé, "Le modèle o1 fournit un support puissant pour les nombreux flux de travail d'agent de Lindy, l'assistant IA de travail d'OpenAI. Le modèle est capable d'utiliser des appels de fonction pour extraire des informations clés du calendrier ou du courrier électronique d'un utilisateur afin de l'aider automatiquement à planifier des réunions, à envoyer des courriers électroniques et à gérer d'autres aspects de ses tâches quotidiennes. OpenAI a transféré toutes les étapes de l'agent de Lindy qui posaient problème vers le modèle o1 et a observé que la fonctionnalité de l'agent de Lindy est devenue impeccable presque du jour au lendemain !
--Lindy.AI, l'assistant de l'IA au travail
5. raisonnement visuel : connaissance de l'information contenue dans l'image
A partir d'aujourd'hui.o1 est le seul modèle d'inférence qui prenne en charge les capacités d'inférence visuelle. o1 avec GPT-4o La différence significative entre leso1 Même les informations visuelles les plus difficiles, telles que des graphiques ou des tableaux à la structure complexe ou des photographies de mauvaise qualité, peuvent être traitées efficacement. Cela souligne l'importance de o1 Des avantages uniques dans le domaine du traitement de l'information visuelle.
Safetykit, une plateforme de surveillance des marchands par l'IA, mentionne : "OpenAI s'engage à automatiser les examens de risque et de conformité pour des millions de produits en ligne, y compris les répliques de bijoux de luxe, les espèces en voie de disparition et les articles réglementés. Dans la tâche de classification d'images la plus difficile d'OpenAI, le modèle GPT-4o n'était précis qu'à 50%. et
o1Le modèle atteint une précision impressionnante de 88% sans aucune modification des processus existants d'OpenAI".-Safetykit, plateforme de surveillance des commerçants par l'IA
Les tests internes d'OpenAI ont également montré queo1 Le modèle est capable d'identifier les accessoires et les matériaux à partir de dessins architecturaux très détaillés et de générer une nomenclature complète. L'un des phénomènes les plus surprenants observés par OpenAI est que le modèleo1 Le modèle est capable d'établir des connexions entre différentes images - par exemple, il peut prendre la légende d'une page d'un dessin d'architecture et l'appliquer exactement à une autre page sans instructions explicites. Dans l'exemple ci-dessous, nous pouvons voir que pour la "Colonne en bois 4x4 PT", le modèleo1 Le modèle a pu identifier correctement que "PT" signifiait "pressure treated" (traité sous pression) en se basant sur la légende. Il s'agit d'une bonne démonstration de l'efficacité de la o1 dans la compréhension d'informations visuelles complexes et le raisonnement inter-documents.

6. examen du code, débogage et amélioration de la qualité : recherche de l'excellence, optimisation du code
Les modèles d'inférence excellent dans l'examen et l'amélioration du code et sont particulièrement efficaces pour traiter les bases de code à grande échelle. Compte tenu de la latence relativement élevée des modèles d'inférence, les tâches de révision de code sont généralement exécutées en arrière-plan. Cela suggère que, malgré la latence, les modèles d'inférence ont des applications importantes dans l'analyse du code et le contrôle de la qualité, en particulier pour les scénarios qui ne nécessitent pas de performances élevées en temps réel.
La startup CodeRabbit, spécialisée dans l'examen de code d'IA, révèle que "OpenAI offre des services d'examen de code d'IA automatisés sur des plateformes d'hébergement de code telles que GitHub et GitLab. Le processus d'examen du code est intrinsèquement insensible à la latence, mais il nécessite une compréhension approfondie des changements de code dans plusieurs fichiers. C'est là que le modèle o1 excelle - il détecte de manière fiable les changements subtils dans la base de code qui pourraient être facilement manqués par un réviseur humain. Après avoir adopté les modèles de la série o, OpenAI a vu ses conversions de produits multipliées par trois.
-CodeRabbit, la startup de révision de code par l'IA
même si GPT-4o répondre en chantant GPT-4o mini peut être mieux adapté aux scénarios de codage à faible latence. o3-mini excelle dans les cas d'utilisation de la génération de code insensible à la latence. Cela signifie que le modèle o3-mini Elle présente également un potentiel dans le domaine de la génération de code, en particulier dans les scénarios d'application qui exigent une qualité de code élevée et qui sont relativement indifférents à la latence.
Startups de complétion de code pilotées par l'IA Codeium a commenté : "Même face à des tâches de codage difficiles, la
o3-miniLes modèles sont également capables de générer de manière cohérente un code concluant et de haute qualité, et donnent très souvent la bonne solution lorsque le problème est bien défini. D'autres modèles peuvent ne convenir qu'à des itérations de code rapides et de petite taille, mais le modèleo3-miniLes modèles sont spécialisés dans la planification et l'exécution de systèmes complexes de conception de logiciels".--Codeium, la startup d'extension de code pilotée par l'IA
7. évaluation des modèles et benchmarking : évaluation objective et sélection des meilleurs parmi les meilleurs
L'OpenAI a également constaté que les modèles d'inférence étaient performants dans l'analyse comparative et l'évaluation d'autres modèles de réponse. La validation des données est essentielle pour garantir la qualité et la fiabilité des ensembles de données, en particulier dans des domaines sensibles tels que les soins de santé. Les méthodes de validation traditionnelles s'appuient sur des règles et des modèles prédéfinis, mais des méthodes comme le o1 répondre en chantant o3-mini Ces modèles avancés sont capables de comprendre le contexte et de raisonner à son sujet, ce qui permet des méthodes de vérification plus souples et plus intelligentes. Cela suggère que les modèles d'inférence peuvent agir comme des "arbitres" pour évaluer la qualité des résultats d'autres modèles, ce qui est essentiel pour l'optimisation itérative des systèmes d'intelligence artificielle.
Braintrust, la plateforme d'évaluation de l'IA, note que "de nombreux clients utilisent la fonction LLM-as-a-judge de la plateforme Braintrust dans le cadre de leur processus d'évaluation. Par exemple, une entreprise de soins de santé peut utiliser un outil tel que
gpt-4oUn tel modèle principal permet de résumer le problème de l'histoire du patient et d'utiliser ensuite les données de la base de données.o1pour évaluer la qualité des résumés. Un client de Braintrust a constaté qu'en utilisant4oLe score F1 est de 0,12 lorsque le modèle est utilisé en tant qu'arbitre, et le passage au modèleo1Après la modélisation, le score F1 a grimpé à 0,74 ! Dans ces cas d'utilisation, ils ont constaté que lao1Le pouvoir de raisonnement du modèle permet de saisir les nuances des résultats finaux, en particulier dans les tâches de notation les plus difficiles et les plus complexes".--Braintrust, une plateforme d'évaluation de l'IA
Conseils pour encourager efficacement les modèles de raisonnement : la simplicité avant tout
Les modèles de raisonnement ont tendance à être plus performants lorsqu'ils reçoivent des instructions claires et concises. Certaines techniques traditionnelles d'ingénierie des indices, telles que l'instruction au modèle de "penser étape par étape", peuvent ne pas être efficaces pour améliorer les performances, et peuvent même parfois être contre-productives. Voici quelques bonnes pratiques, ou vous pouvez simplement vous référer aux exemples de repères pour commencer.
- Les messages du développeur remplacent les messages du système. à travers (une brèche)
o1-2024-12-17le modèle d'inférence a commencé à prendre en charge les messages des développeurs, plutôt que les messages traditionnels du système, afin de se conformer au comportement de la chaîne d'instructions décrite dans la spécification du modèle. - Les questions doivent être simples et directes. Les modèles de raisonnement sont capables de comprendre et de répondre à des instructions claires et concises. Par conséquent, des instructions claires et directes sont plus efficaces pour les modèles de raisonnement que des techniques complexes d'ingénierie des indices.
- Éviter les chaînes de pensée Conseil. Il n'est pas nécessaire d'inviter le modèle de raisonnement à "réfléchir étape par étape" ou à "expliquer votre processus de raisonnement" puisqu'il possède déjà des capacités de raisonnement en interne. Cette redondance peut au contraire dégrader les performances du modèle.
- Utilisez des délimiteurs pour améliorer la clarté. L'utilisation de séparateurs tels que Markdown, les balises XML et les titres de section pour étiqueter clairement les différentes parties de l'entrée aide le modèle à comprendre avec précision le contenu des différentes sections.
- Donner la priorité aux tentatives de prélèvement d'indices nuls avant d'envisager des indices de moindre importance : la Les modèles d'inférence produisent généralement de bons résultats sans avoir besoin de quelques exemples. Par conséquent, il est recommandé d'essayer d'abord de rédiger des astuces sans exemples. Si vous avez des exigences plus complexes concernant les résultats de sortie, il peut être utile d'inclure quelques exemples d'entrées et de sorties souhaitées dans vos astuces. Toutefois, il est important de veiller à ce que les exemples soient parfaitement cohérents avec les instructions de l'invite, car les écarts entre les deux peuvent entraîner des résultats médiocres.
- Fournir des orientations claires et précises. S'il existe des contraintes explicites susceptibles de limiter l'éventail des réponses du modèle (par exemple, "Proposer une solution avec un budget inférieur à 500 dollars"), il convient de formuler clairement ces contraintes dans l'invitation.
- Clarification de l'objectif final. Dans les instructions, soyez aussi précis que possible dans la description des critères selon lesquels les réponses réussies seront jugées, et encouragez le modèle à continuer à raisonner et à itérer jusqu'à ce que vos critères de réussite soient satisfaits.
- Contrôle du formatage Markdown. à travers (une brèche)
o1-2024-12-17À partir de la version 1, les modèles d'inférence de l'API évitent de générer des réponses avec le formatage Markdown par défaut. Si vous souhaitez que le modèle inclue le formatage Markdown dans ses réponses, ajoutez la chaîneFormatting re-enabled.
Exemples d'utilisation de l'API du modèle d'inférence
Les modèles de raisonnement sont uniques dans leur processus de "réflexion". Contrairement aux modèles de langage traditionnels, les modèles d'inférence réfléchissent profondément en interne et construisent une longue chaîne de raisonnement avant de donner une réponse. Comme l'indique la description officielle de l'OpenAI, ces modèles réfléchissent en profondeur avant de répondre à l'utilisateur. Ce mécanisme permet aux modèles d'inférence d'exceller dans des tâches telles que la résolution d'énigmes complexes, le codage, le raisonnement scientifique et la planification en plusieurs étapes des flux de travail des agents.
Comme le modèle GPT d'OpenAI, OpenAI propose deux modèles d'inférence pour répondre à des besoins différents :o3-mini Le modèle se distingue par sa taille plus petite et sa vitesse plus élevée, tandis que la jeton Les coûts sont également relativement faibles ; et o1 Les modèles, quant à eux, échangent une plus grande échelle et une vitesse légèrement plus lente contre une résolution plus puissante des problèmes.o1 Les modèles génèrent généralement des réponses de meilleure qualité lorsqu'il s'agit de tâches complexes et présentent de meilleures performances de généralisation dans différents domaines.
démarrage rapide
Pour aider les développeurs à démarrer rapidement, OpenAI fournit une interface API facile à utiliser. Voici un exemple de démarrage rapide de l'utilisation du modèle d'inférence dans les complétions de chat :
Utilisation de modèles d'inférence dans les complétions de chat
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
reasoning_effort: "medium",
messages: [
{
role: "user",
content: prompt
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
"""
response = client.chat.completions.create(
model="o3-mini",
reasoning_effort="medium",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o3-mini",
"reasoning_effort": "medium",
"messages": [
{
"role": "user",
"content": "编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,格式为 \"[1,2],[3,4],[5,6]\",并以相同的格式打印转置矩阵。"
}
]
}'
Intensité du raisonnement : contrôle de la profondeur de la réflexion dans le modèle
Dans l'exemple ci-dessus, lereasoning_effort Le paramètre (affectueusement appelé "jus" au cours du développement de ces modèles) est utilisé pour guider le modèle dans la quantité de calculs d'inférence qu'il effectue avant de générer une réponse. L'utilisateur peut spécifier pour ce paramètre low,medium peut-être high Une des trois valeurs. Où.low se concentre sur la rapidité et la réduction des coûts des jetons, tandis que le modèle high invite le modèle à un raisonnement plus approfondi et plus complet, mais augmente la consommation de jetons et le temps de réponse. La valeur par défaut est fixée à mediumL'intensité de l'inférence, qui est un élément essentiel de l'analyse des données, vise à trouver un équilibre entre la vitesse et la précision de l'inférence. Les développeurs peuvent ajuster l'intensité de l'inférence en fonction des besoins des scénarios d'application réels afin d'obtenir des performances optimales et un bon rapport coût-efficacité.
Comment fonctionne le raisonnement : une analyse approfondie du processus de "pensée" des modèles
Le modèle d'inférence s'appuie sur les jetons d'entrée et de sortie traditionnels en introduisant les éléments suivants Raisonnement sur les jetons Ce concept. Ces jetons d'inférence sont analogues au "processus de pensée" du modèle, et le modèle les utilise pour décomposer sa compréhension des indices de l'utilisateur et pour explorer de multiples chemins possibles pour générer des réponses. Ce n'est qu'une fois la génération des jetons d'inférence terminée que le modèle produit la réponse finale, un jeton complémentaire visible par l'utilisateur, et rejette le jeton d'inférence du contexte.
La figure suivante montre un exemple de dialogue en plusieurs étapes entre un utilisateur et un assistant. À chaque étape du dialogue, les jetons d'entrée et de sortie sont conservés, tandis que les jetons d'inférence sont rejetés par le modèle.
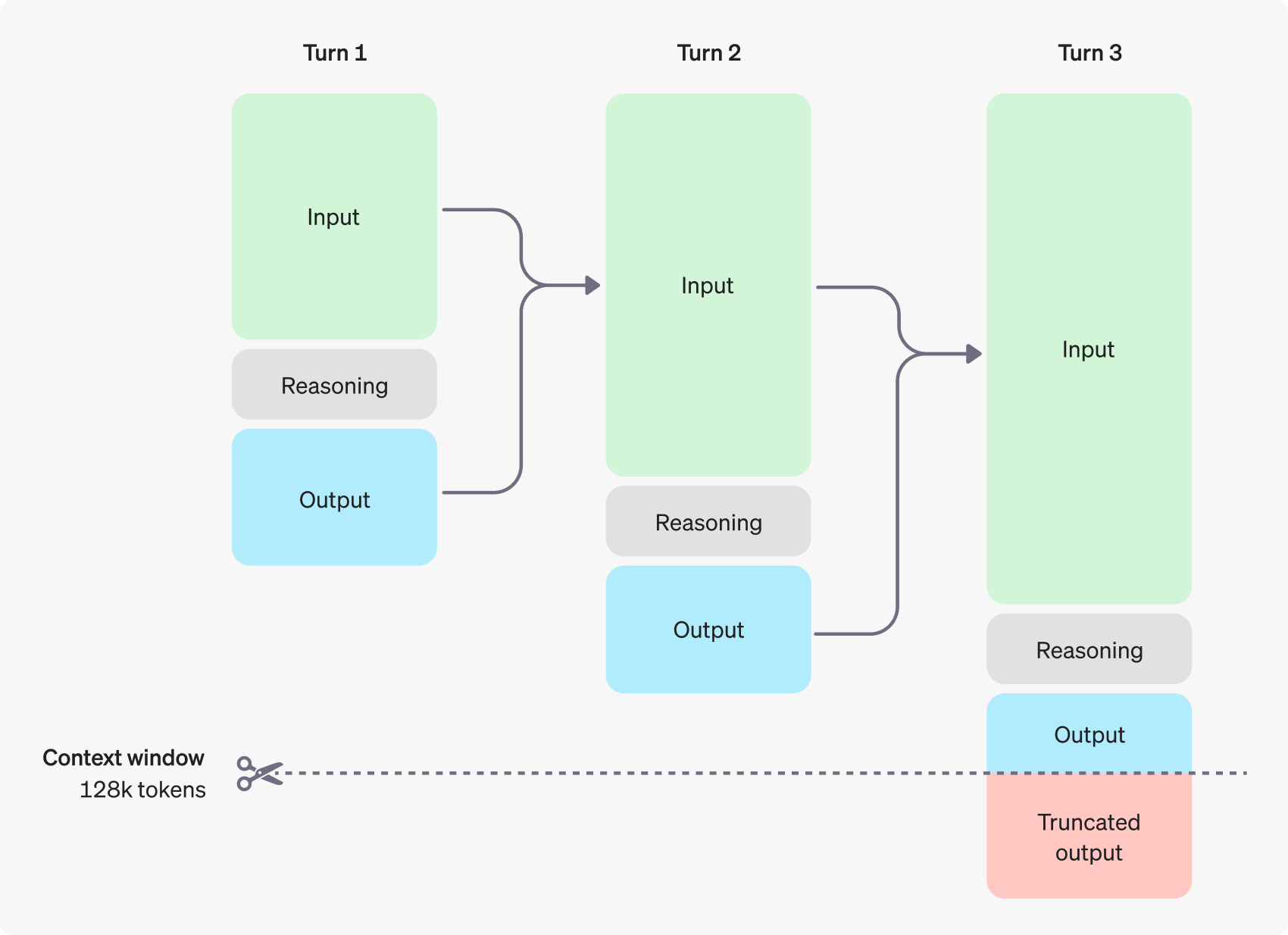
Il convient de noter que, bien que les jetons d'inférence ne soient pas visibles via l'interface API, ils occupent toujours l'espace de la fenêtre contextuelle du modèle et comptent dans l'utilisation totale des jetons, et doivent être payés tout comme les jetons de sortie. Par conséquent, dans la pratique, les développeurs doivent tenir compte de l'impact des jetons d'inférence et gérer la fenêtre contextuelle du modèle et la consommation de jetons de manière appropriée.
Gestion des fenêtres contextuelles : veiller à ce que les modèles disposent d'un espace de réflexion suffisant
Lors de la création d'une demande de complétion, il est important de s'assurer que la fenêtre de contexte dispose de suffisamment d'espace pour les jetons d'inférence générés par le modèle.En fonction de la complexité du problème, le modèle peut avoir besoin de générer des centaines ou des dizaines de milliers de jetons d'inférence.L'utilisateur peut créer les jetons d'inférence via l'objet d'utilisation de l'objet de réponse de complétion du chat dans la fenêtre d'utilisation de l'objet de réponse de complétion du chat. completion_tokens_details pour connaître le nombre exact de jetons d'inférence utilisés par le modèle pour une requête particulière :
{
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
Les longueurs des fenêtres contextuelles pour les différents modèles sont disponibles pour l'utilisateur sur la page Référence du modèle. Une évaluation et une gestion correctes de la fenêtre contextuelle sont essentielles pour garantir le bon fonctionnement du modèle d'inférence.
Contrôle des coûts : ajustement et optimisation de la consommation de jetons
Pour gérer efficacement le coût du modèle d'inférence, les utilisateurs peuvent utiliser la fonction max_completion_tokens qui limite le nombre total de jetons générés par le modèle, y compris les jetons d'inférence et les jetons complémentaires.
Dans les modèles antérieurs, lemax_tokens Ce paramètre contrôle à la fois le nombre de jetons générés par le modèle et le nombre de jetons visibles par l'utilisateur, qui sont toujours les mêmes. Cependant, pour les modèles d'inférence, le nombre total de jetons générés par le modèle peut dépasser le nombre de jetons finalement vus par l'utilisateur en raison de l'introduction de jetons d'inférence internes.
Il faut tenir compte du fait que certaines applications peuvent s'appuyer sur des max_tokens est cohérent avec le nombre de jetons renvoyés par l'API, OpenAI a introduit un paramètre spécial de type max_completion_tokens Ce paramètre explicite garantit une transition en douceur pour les applications existantes qui utilisent le nouveau modèle, en évitant les problèmes de compatibilité potentiels. Pour tous les modèles précédents, le paramètremax_tokens La fonction du paramètre reste inchangée.
Laisser de l'espace pour le raisonnement : éviter les interruptions de la "pensée".
Si le nombre de jetons générés atteint la limite de la fenêtre contextuelle ou le nombre de jetons défini par l'utilisateur, le système de gestion des jetons est activé. max_completion_tokens l'API renverra une réponse d'achèvement du chat avec la valeur finish_reason Le champ est fixé à length. Cela peut se produire avant que le modèle ne génère des jetons complémentaires visibles par l'utilisateur, ce qui signifie que l'utilisateur peut avoir à payer pour des jetons d'entrée et des jetons d'inférence, mais qu'il ne recevra finalement aucune réponse visible.
Pour éviter cela, assurez-vous toujours que la fenêtre contextuelle dispose de suffisamment d'espace, ou placez le bouton max_completion_tokens est ajusté à une valeur plus élevée. openAI recommande de réserver de l'espace pour au moins 25 000 jetons pour les processus d'inférence et de sortie lors des premiers essais de ces modèles d'inférence. Au fur et à mesure que les utilisateurs se familiarisent avec le nombre de jetons d'inférence requis pour leurs invites, cette taille de tampon peut être ajustée de manière appropriée pour un contrôle plus granulaire des coûts.
Suggestion de conseil : libérer le potentiel des modèles de raisonnement
L'utilisateur doit être conscient de certaines différences essentielles lorsqu'il demande des modèles d'inférence et des modèles GPT. Dans l'ensemble, le modèle d'inférence tend à donner de meilleurs résultats pour les tâches pour lesquelles seules des instructions de haut niveau sont fournies. En revanche, le modèle GPT donne généralement de meilleurs résultats lorsque des instructions très précises sont reçues.
- Modèles de raisonnement comme les collègues seniors expérimentés -- On peut faire confiance aux utilisateurs pour régler les détails spécifiques de manière autonome en leur disant simplement ce qu'ils veulent réaliser.
- Le modèle GPT s'apparente davantage à un assistant junior -- Ils fonctionnent mieux lorsqu'ils disposent d'instructions claires et détaillées pour la création d'un résultat spécifique.
Pour en savoir plus sur les meilleures pratiques d'utilisation des modèles d'inférence, consultez le guide officiel de l'OpenAI.
Exemple de conseil : démonstration d'un scénario d'application
Codage (refonte du code)
Les modèles de la série o d'OpenAI démontrent de puissantes capacités de compréhension algorithmique et de génération de code. L'exemple suivant montre comment le modèle o1 peut être utilisé pour remanier des critères spécifiques Réagir Composant.
remanier le code
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Code (planification de projet)
Le modèle de série o d'OpenAI permet également de développer des plans de projet en plusieurs étapes. L'exemple suivant montre comment utiliser le modèle o1 pour créer une structure complète de système de fichiers pour une application Python et générer du code Python qui implémente la fonctionnalité requise.
Planifier et créer un projet Python
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Recherche STEM
Les modèles de la série o d'OpenAI ont démontré d'excellentes performances dans la recherche STEM (science, technologie, ingénierie et mathématiques). Ces modèles donnent souvent des résultats impressionnants pour des messages-guides conçus pour soutenir des tâches de recherche de base.
Soulever les questions liées à la recherche en sciences fondamentales
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
exemple officiel
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...