Tutoriel d'installation et d'utilisation d'Ollama
De nombreux numéros précédents ont été consacrés à la Ollama Les informations contenues dans les tutoriels d'installation et de déploiement sont plutôt dispersées, c'est pourquoi nous avons cette fois-ci mis en place un tutoriel complet en une étape sur la façon d'utiliser Ollama sur un ordinateur local. Ce tutoriel est destiné aux débutants afin d'éviter les pièges de l'utilisation d'Ollama, et pour ceux qui en sont capables, nous recommandons la lecture de la documentation officielle d'Ollama. Je fournirai ensuite un guide étape par étape pour l'installation et l'utilisation d'Ollama.

Pourquoi choisir Ollama pour l'installation locale de grands modèles ?
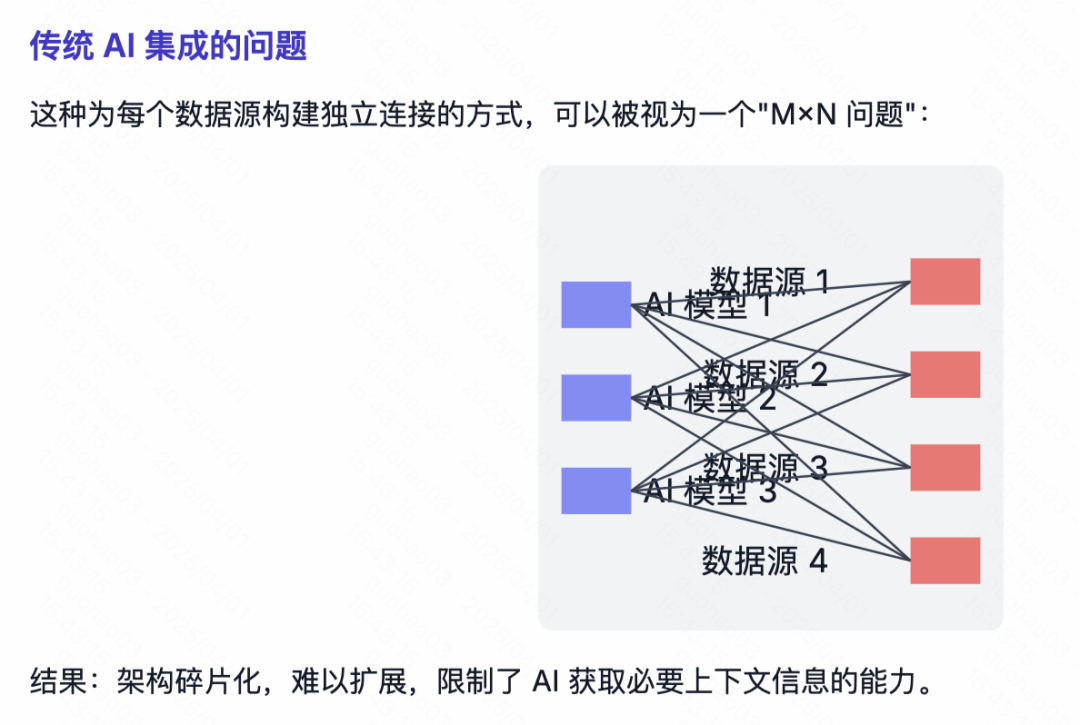
De nombreux nouveaux venus ne comprennent pas, comme moi, qu'il existe d'autres outils plus performants en ligne pour déployer de grands modèles, comme par exemple :Inventaire des cadres LLM similaires à Ollama : options multiples pour les grands modèles déployés localement Pourquoi recommandez-vous d'installer Ollama à la fin ?
Tout d'abord, il est bien sûr facile à installer sur des ordinateurs personnels, mais l'un des points les plus importants est que les performances du modèle pour un déploiement autonome sont mieux optimisées pour les paramètres, et que l'installation n'est pas sujette à des erreurs. Par exemple, la même configuration d'installation sur ordinateur QwQ-32B Utiliser Ollama pour une éventuelle souplesse d'utilisation, changer pour "plus puissant". llama.cpp Il peut être bloqué, et même les réponses en sortie ne sont pas correctes. Il y a de nombreuses raisons à cela et je ne peux pas les expliquer clairement, donc je ne le ferai pas. Sachez simplement qu'Ollama contient llama.cpp à la base, et qu'en raison d'une meilleure optimisation, il fonctionne de manière plus stable que llama.cpp à la place.
Quels types de fichiers modèles volumineux Ollama peut-il traiter ?
Ollama prend en charge les fichiers de modèles dans les deux formats suivants, avec différents moteurs d'inférence :
- Format GGUF: à travers
llama.cppRaisonnement. - format des capteurs de sécurité: à travers
vllmRaisonnement.
En d'autres termes :
- Si un modèle au format GGUF est utilisé, Ollama appellera la fonction
llama.cppEffectuer une inférence efficace par CPU/GPU. - Si un modèle au format safetensors est utilisé, Ollama utilise la fonction
vllmEn plus des GPU, les GPU sont souvent utilisés pour l'inférence à haute performance.
Bien sûr, vous n'avez pas besoin de vous en préoccuper, sachez simplement que la plupart des fichiers que vous installez sont au format GGUF. Pourquoi insistez-vous sur le format GGUF ?
Soutien du GGUF Quantitatif (par exemple Q4, Q6_K)La capacité àMaintient de bonnes performances d'inférence avec des empreintes graphiques et mémorielles très faiblesLes capteurs de sécurité sont généralement des modèles FP16/FP32 complets, mais ils sont beaucoup plus volumineux et occupent plus de ressources. Pour en savoir plus, cliquez ici :Qu'est-ce que la quantification de modèle : explication des types de données FP32, FP16, INT8, INT4.
Configuration minimale requise pour Ollama
Système d'exploitation : Linux : Ubuntu 18.04 ou version ultérieure, macOS : macOS 11 Big Sur ou version ultérieure
RAM : 8GB pour les modèles 3B, 16GB pour les modèles 7B, 32GB pour les modèles 13B
Espace disque : 12 Go pour l'installation d'Ollama et du modèle de base, espace supplémentaire requis pour le stockage des données du modèle, en fonction du modèle que vous utilisez. Il est recommandé de réserver 6 Go d'espace sur le disque C.
CPU : Il est recommandé d'utiliser un processeur moderne doté d'au moins 4 cœurs, et pour le modèle 13B, il est recommandé d'utiliser un processeur doté d'au moins 8 cœurs.
GPU (optionnel) : Vous n'avez pas besoin d'un GPU pour faire fonctionner Ollama, mais cela peut améliorer les performances, en particulier lors de l'exécution de modèles plus importants. Si vous disposez d'un GPU, vous pouvez l'utiliser pour accélérer l'apprentissage de modèles personnalisés.
Installer Ollama
Voir : https://ollama.com/download
Il suffit de choisir en fonction de l'environnement de l'ordinateur, l'installation est très simple, la seule chose à laquelle il faut faire attention ici est que l'environnement du réseau peut entraîner un échec de l'installation.
Installation de macOS : https://ollama.com/download/Ollama-darwin.zip
Installation sous Windows : https://ollama.com/download/OllamaSetup.exe
Installation de Linux :curl -fsSL https://ollama.com/install.sh | sh
Image Docker : (veuillez apprendre par vous-même sur le site officiel)
CPU ou GPU Nvidia :docker pull ollama/ollama
GPU AMD :docker pull ollama/ollama:rocm

Une fois l'installation terminée, vous verrez l'icône Ollama dans le coin inférieur droit de votre bureau, s'il y a une alerte verte dans l'icône, cela signifie que vous devez faire la mise à jour.

Ollama setup
Ollama est très facile à installer, mais la plupart des réglages nécessitent de modifier les "variables d'environnement", ce qui est très rébarbatif pour les nouveaux arrivants, je liste toutes les variables pour ceux qui ont besoin de s'y référer (pas besoin de s'en souvenir) :
| paramètres | Étiquetage et configuration |
|---|---|
| OLLAMA_MODELS | Indique le répertoire dans lequel les fichiers du modèle sont stockés, le répertoire par défaut étantRépertoire de l'utilisateur actuelassumer (bureau) C:\Users%username%.ollama\modelsSystème Windows Il n'est pas recommandé de le placer sur le lecteur CLes disques peuvent être placés sur d'autres disques (par ex. E:\ollama\models) |
| OLLAMA_HOST | est l'adresse réseau sur laquelle le service ollama écoute, et la valeur par défaut est127.0.0.1 Si vous souhaitez permettre à d'autres ordinateurs d'accéder à Ollama (par exemple, d'autres ordinateurs sur un réseau local), l'optionParamètres recommandésêtre bien 0.0.0.0 |
| OLLAMA_PORT | Indique le port par défaut sur lequel le service ollama écoute, dont la valeur par défaut est11434 En cas de conflit de port, vous pouvez modifier les paramètres pour d'autres ports (par exemple, le port d'entrée de l'ordinateur, le port de sortie de l'ordinateur, etc.8080etc.) |
| OLLAMA_ORIGINES | Indique la source de la requête du client HTTP, en utilisant des listes séparées par des virgules. Si l'utilisation locale n'est pas restreinte, il peut être remplacé par un astérisque. * |
| OLLAMA_KEEP_ALIVE | Indique le temps de survie du grand modèle après qu'il a été chargé en mémoire.5mCela représente 5 minutes. (par exemple, un nombre simple de 300 signifie 300 secondes, 0 signifie que le modèle est désinstallé dès que la réponse à la demande a été traitée, et tout nombre négatif signifie qu'il a survécu). Il est recommandé de définir le 24h Le modèle reste en mémoire pendant 24 heures, ce qui augmente la vitesse d'accès. |
| OLLAMA_NUM_PARALLEL | Indique le nombre de demandes simultanées traitées, la valeur par défaut étant1 (c'est-à-dire le traitement en série des demandes en une seule fois) Les recommandations sont adaptées aux besoins réels |
| OLLAMA_MAX_QUEUE | Indique la longueur de la file d'attente de la demande, la valeur par défaut est512 Il est recommandé de s'adapter aux besoins réels, les demandes dépassant la longueur de la file d'attente seront rejetées. |
| OLLAMA_DEBUG | indique la sortie du journal de débogage, qui peut être réglé dans la phase de développement de l'application sur1 (c'est-à-dire qu'il produit des informations de journal détaillées pour le dépannage) |
| OLLAMA_MAX_LOADED_MODELS | Indique le nombre maximum de modèles chargés simultanément dans la mémoire.1 (c'est-à-dire qu'un seul modèle peut être en mémoire) |
1. modifier le répertoire de téléchargement des fichiers de modèles volumineux
Sur les systèmes Windows, les fichiers de modèles téléchargés par Ollama sont stockés par défaut dans un répertoire spécifique sous le dossier de l'utilisateur. Plus précisément, le chemin par défaut est généralementC:\Users\<用户名>\.ollama\models. Ici.<用户名>fait référence au nom d'utilisateur de la connexion actuelle au système Windows.

Par exemple, si le nom de l'utilisateur de connexion au système estyangfanLe chemin de stockage par défaut du fichier de modèle peut être le suivantC:\Users\yangfan\.ollama\models\manifests\registry.ollama.ai. Dans ce répertoire, les utilisateurs peuvent trouver tous les fichiers de modèles téléchargés par Ollama.
Remarque : les chemins d'installation des systèmes plus récents sont généralement les suivants :C:\Users\<用户名>\AppData\Local\Programs\Ollama
Les téléchargements de grands modèles peuvent facilement atteindre plusieurs gigaoctets, si votre espace disque C est réduit, la première chose à faire est de modifier le répertoire de téléchargement des fichiers de grands modèles.
1) Trouver le point d'entrée des variables d'environnement
La méthode la plus simple : Win+R pour ouvrir la fenêtre d'exécution, tapez sysdm.cplSi vous souhaitez utiliser cette option, ouvrez les Propriétés du système, sélectionnez l'onglet Avancé et cliquez sur Variables d'environnement.

Autres méthodes :
1) Démarrer->Paramètres->About->Paramètres avancés du système->Propriétés du système->Variables d'environnement.
2. cet ordinateur -> Clic droit -> Propriétés -> Paramètres système avancés -> Variables d'environnement.
3) Démarrer->Panneau de configuration->Système et sécurité->Système->Paramètres avancés du système->Propriétés du système->Variables d'environnement.
4. boîte de recherche en bas du bureau->Intrants->Variables d'environnement
Lorsque vous entrez, l'écran suivant s'affiche :

2. modifier les variables d'environnement
Cherchez le nom de la variable OLLAMA_MODELS dans Variables système, cliquez sur Nouveau si elle ne s'y trouve pas.


Si OLLAMA_MODELS existe déjà, sélectionnez-le et double-cliquez sur le bouton gauche de la souris, ou sélectionnez-le et cliquez sur "Modifier".

La valeur de la variable est remplacée par le nouveau répertoire, ici j'ai pris les devants et je l'ai changé du lecteur C au lecteur E qui a plus d'espace disque.

Après l'enregistrement, il est recommandé de démarrer l'ordinateur à partir d'une nouvelle fenêtre de démarrage et de l'utiliser à nouveau pour un résultat plus sûr.
2. modifier l'adresse d'accès et le port par défaut
Dans le navigateur, entrez l'URL : http://127.0.0.1:11434/ , vous verrez le message suivant, indiquant qu'il est en cours d'exécution, il y a quelques risques de sécurité ici qui doivent être modifiés, toujours dans les variables d'environnement.

1. modifier OLLAMA_HOST
Si ce n'est pas le cas, ajoutez-en un nouveau, si c'est 0.0.0.0 pour permettre l'accès à l'extranet, changez-le en 127.0.0.1.

2. modifier OLLAMA_PORT
Si vous ne l'avez pas, ajoutez-le et remplacez 11434 par n'importe quel port, tel que:11331(La plage de modification du port est comprise entre 1 et 65535), commencez par 1000 pour éviter tout conflit de port. Notez que l'anglais " :" est utilisé.

N'oubliez pas de redémarrer votre ordinateur pour lire les recommandations sur la sécurité d'Ollama :DeepSeek met le feu à Ollama, votre déploiement local est-il sûr ? Méfiez-vous de l'arithmétique "volée" !
Installation de grands modèles
Aller à l'URL : https://ollama.com/search

Sélectionner le modèle, sélectionner la taille du modèle, copier la commande

Accès aux outils de ligne de commande

Collez la commande pour l'installer automatiquement

Il se télécharge ici, donc si c'est lent, envisagez de passer à un environnement Internet plus heureux !

Si vous souhaitez télécharger de grands modèles qu'Ollama ne propose pas, vous pouvez certainement le faire, la grande majorité d'entre eux sont des fichiers GGUF sur huggingface, et j'ai pris une version quantifiée spéciale de la Profondeur de l'eau-R1 Le 32B est utilisé comme exemple pour la démonstration de l'installation.
1. installer le modèle de version quantitative huggingface format de commande de base
N'oubliez pas le format de commande d'installation suivant
ollama run hf.co/{username}:{reponame}
2. sélection de la version quantitative
Liste de toutes les versions quantitatives : https://huggingface.co/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF/tree/main
Cette installation utilise : Q5_K_M
3. commande d'installation d'épissures

{username}=unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF
{reponame}=Q5_K_M
Splice pour obtenir la commande d'installation complète :ollama run hf.co/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:Q5_K_M
4) Effectuer l'installation dans Ollama
Exécuter la commande d'installation

Il se peut que vous rencontriez des problèmes de réseau (bonne chance), répétez la commande d'installation plusieurs fois...
Cela ne fonctionne toujours pas ? Essayez la commande suivante.hf.co/Modifier la section comme suithttps://hf-mirror.com/(passage à l'adresse miroir nationale), le patchwork final de la commande d'installation complète est le suivant :
ollama run https://hf-mirror.com/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:Q5_K_M
Un tutoriel complet pour cette section est disponible :Déploiement privé sans GPU locaux DeepSeek-R1 32B
Commandes de base d'Ollama
| commande | descriptions |
|---|---|
ollama serve | Lancer Ollama |
ollama create | Création de modèles à partir d'un fichier modèle |
ollama show | Affichage des informations sur le modèle |
ollama run | modèle opérationnel |
ollama stop | Arrêt d'un modèle en cours d'exécution |
ollama pull | Extraction de modèles du registre |
ollama push | Pousser des modèles vers le registre |
ollama list | Liste de tous les modèles |
ollama ps | Liste des modèles en cours d'exécution |
ollama cp | Modèles de réplication |
ollama rm | Supprimer le modèle |
ollama help | Afficher les informations d'aide pour n'importe quelle commande |
| symboliser | descriptions |
|---|---|
-h, --help | Afficher les informations d'aide pour Ollama |
-v, --version | Affichage des informations sur la version |
Lorsque vous saisissez des commandes sur plusieurs lignes, vous pouvez utiliser la commande """ Effectuer un saut de ligne.

utiliser """ Saut de ligne.

Pour mettre fin au service d'inférence de modèle Ollama, vous pouvez utiliser la commande /bye.

Utilisation d'Ollama dans un outil de dialogue d'IA natif
La plupart des outils de dialogue natifs d'IA sont déjà adaptés à Ollama par défaut et ne nécessitent aucun paramétrage. Par exemple Page Assist OpenwebUI.
Cependant, certains outils de dialogue d'intelligence artificielle locale vous demandent de saisir vous-même l'adresse de l'API.http://127.0.0.1:11434/(à noter si le port est modifié)

Certains outils de dialogue d'IA basés sur le web prennent en charge la configuration, par exemple NextChat :

Si vous souhaitez qu'Ollama fonctionne sur votre ordinateur local et soit entièrement exposé à un usage externe, vous devez apprendre cpolar ou ngrok par vous-même, ce qui dépasse le cadre d'une utilisation par des débutants.
L'article semble être très long, en fait, il contient 4 points de connaissance très simples, qui permettent d'apprendre l'utilisation future d'Ollama sans entrave, passons à nouveau en revue :
1. définir les variables d'environnement
2. deux façons d'installer un grand modèle
3. se rappeler les commandes de base d'exécution et de suppression du modèle
4. utilisation pour différents clients
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...