Molmo : une série de modèles multimodaux de langage ouvert construits par Ai2
Introduction générale
Molmo est un modèle de langage ouvert multimodal développé par l'Allen Institute for AI (Ai2). Le modèle combine des capacités de traitement de données textuelles et visuelles pour reconnaître des objets dans des images et générer des descriptions précises. Molmo obtient de bons résultats dans un certain nombre de tests de référence, démontrant sa puissance en particulier dans des tâches complexes telles que la lecture de documents et le raisonnement visuel.Ai2 a posté ces documents sur Hugging FaceModèles et ensembles de donnéeset prévoit de lancer d'autres modèles et des rapports techniques détaillés dans les mois à venir, afin de fournir davantage de ressources aux chercheurs. Rapport technique.
La principale innovation de Molmo est l'utilisation d'un tout nouvel ensemble de données de description d'images, avec des modèles entraînés sur PixMo, un ensemble de données d'un million de paires image-texte hautement sélectionnées. Ces ensembles de données ont été collectés exclusivement par des annotateurs humains au moyen de descriptions vocales. En outre, Molmo introduit un ensemble diversifié d'ensembles de données pour le réglage fin, y compris des données innovantes de pointage en 2D qui permettent à Molmo de répondre à des questions en utilisant non seulement le langage naturel, mais aussi des indices non verbaux.

Molmo est basé sur Qwen2-72B et utilise CLIP d'OpenAI comme base visuelle pour améliorer la capacité du modèle à traiter les images et le texte.
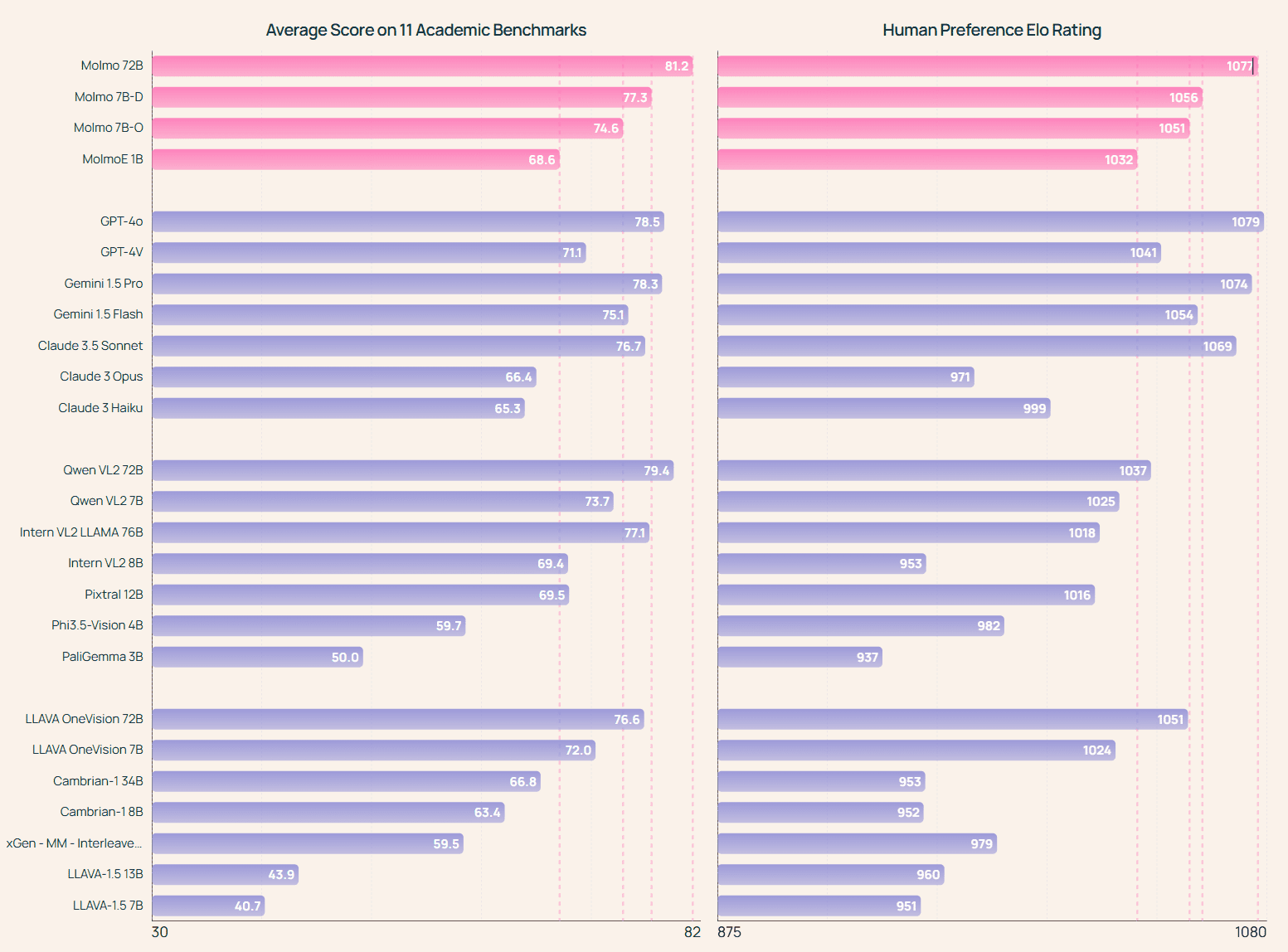
Molmo-72B : a obtenu le meilleur score au test de référence académique et s'est classé deuxième à l'évaluation manuelle, à peine moins que le GPT-4o. Il a également surpassé plusieurs systèmes propriétaires à la pointe de la technologie, dont le Gémeaux 1.5 Pro, Flash et Claude 3.5 Sonnet : MolmoE-1B : le modèle Molmo le plus efficace, basé sur notre LLM expert hybride OLMoE-1B-7B entièrement ouvert, qui est presque aussi performant que GPT-4V dans les benchmarks académiques et les évaluations manuelles. Les deux modèles Molmo-7B : leurs performances se situent entre GPT-4V et GPT-4o à la fois dans les benchmarks académiques et dans les évaluations manuelles, et ils surpassent de manière significative le modèle Pixtral 12B récemment publié dans les deux benchmarks.
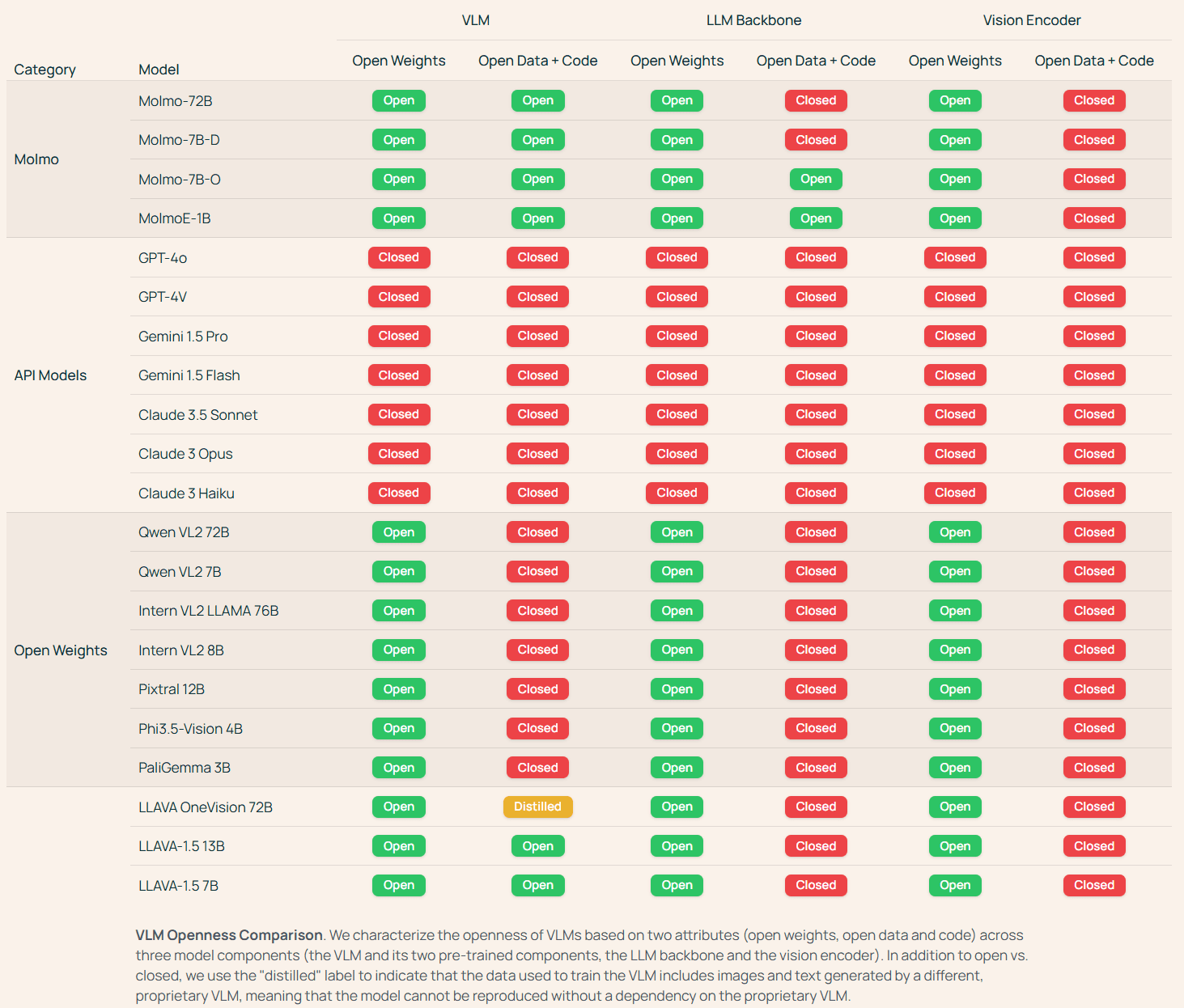
Ouvrir davantage de poids et de modèles de données
Liste des fonctions
- Reconnaissance d'images : capacité à reconnaître des objets dans une image et à en générer une description.
- Génération de texte : génère des descriptions textuelles pertinentes sur la base d'un texte ou d'une image d'entrée.
- Traitement de données multimodales : combinaison de données textuelles et visuelles pour des tâches complexes.
- Ressources open source : des ressources open source pour les modèles et les ensembles de données sont disponibles pour les chercheurs.
- Démonstration en ligne : fournit une fonction de démonstration en ligne où les utilisateurs peuvent télécharger des images et générer des descriptions.
Utiliser l'aide
Lignes directrices pour l'utilisation
- reconnaissance d'imagesCliquez sur le bouton "Télécharger une image" sur la page d'accueil du site web et sélectionnez le fichier image à reconnaître. Après le téléchargement, le système génère automatiquement une description de l'image.
- Génération de texteLe système génère alors la description de texte appropriée en fonction du contenu saisi.
- Traitement multimodal des donnéesLes utilisateurs peuvent télécharger des images et du texte, et le système combine les deux et génère une description complète.
- ressource open sourceLes ressources de la plateforme Hugging Face sont disponibles pour la recherche de modèles Molmo, le téléchargement et l'utilisation des ressources open source fournies.
- Démonstration en ligneDémonstration en ligne : Cliquez sur le bouton "Démonstration en ligne" sur la page d'accueil du site web pour accéder à la page de démonstration. Les utilisateurs peuvent télécharger des images ou saisir du texte pour découvrir les fonctionnalités de Molmo en temps réel.
Fonction Opération Déroulement
- reconnaissance d'images: :
- Ouvrez le site web de Molmo et cliquez sur le bouton "Télécharger une image".
- Sélectionnez le fichier image à reconnaître et cliquez sur "Télécharger".
- Attendez que le système traite et génère une description de l'image.
- Visualiser et enregistrer la description générée.
- Génération de texte: :
- Dans la zone de texte, saisissez le texte ou la question pour lequel vous souhaitez générer une description.
- Cliquez sur le bouton "Générer" et attendez que le système se mette en route.
- Affichez la description textuelle générée et modifiez-la ou enregistrez-la si nécessaire.
- Traitement multimodal des données: :
- Téléchargez l'image et le texte en même temps et cliquez sur le bouton "Traiter".
- Le système combine le traitement d'images et de textes pour générer une description complète.
- Visualiser et sauvegarder la description du composite généré.
- Utilisation de ressources open source: :
- Visitez la plateforme Hugging Face et recherchez les modèles Molmo.
- Téléchargez le modèle et le jeu de données, suivez les instructions pour l'installation et l'utilisation.
- Utilisez l'exemple de code et la documentation fournis pour le développement secondaire ou la recherche.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...