Évaluation de l'utilisation des modèles d'inférence dans les systèmes modulaires RAG
Dans cet article, nous présentons le travail récent de Kapa.ai sur le système Retrieval-Augmented Generation (RAG) d'OpenAI dans le contexte de l'initiative "Retrieval-Augmented Generation" (RAG). o3-mini Rapport de synthèse sur l'exploration du modèle étymologique du raisonnement.

Kapa.ai est un assistant d'IA alimenté par un modèle de langage à grande échelle (LLM) qui RAG Le processus est intégré à la base de connaissances, ce qui permet de répondre aux questions techniques des utilisateurs et de traiter les demandes d'assistance technique.
Construire et maintenir un système RAG stable et polyvalent n'est pas une tâche facile. De nombreux paramètres et réglages affectent la qualité du résultat final, et il existe des interactions complexes entre ces facteurs :
- Modèles de mots clés
- Taille du contexte
- Extension des requêtes
- morceau
- réorganiser
- attendez une minute !
Lors de l'adaptation d'un système RAG, en particulier lors de l'intégration de nouveaux modèles, il est essentiel de réexaminer et d'optimiser ces paramètres pour maintenir de bonnes performances. Cependant, cette tâche ne prend pas seulement du temps, mais nécessite également une grande expérience.
ressembler Profondeur de l'eau-R1 De nouveaux modèles de raisonnement tels que l'o3-mini d'OpenAI ont obtenu des résultats impressionnants en utilisant des invites intégrées de la chaîne de pensée (CoT) pour "réfléchir" à un problème, raisonner étape par étape et même s'auto-corriger si nécessaire. Les modèles seraient plus performants dans les tâches complexes qui nécessitent un raisonnement logique et des réponses vérifiables. À lire aussi :DeepSeek R1 dans RAG : un résumé de l'expérience pratique ,Les résultats de la génération de code au niveau du projet sont disponibles ! o3/Claude 3.7 est en tête, R1 est dans le peloton de tête !
Kapa.ai propose donc une idée : si les modèles d'inférence peuvent décomposer des problèmes complexes et s'autocorriger, pourraient-ils être appliqués aux processus RAG pour traiter des tâches telles que l'expansion des requêtes, la recherche de documents et le réordonnancement ? En construisant une boîte à outils de recherche d'informations et en la confiant aux modèles d'inférence, il pourrait être possible de construire un système plus adaptatif qui réduirait la nécessité d'un réglage manuel des paramètres.
Ce paradigme est parfois appelé Modular Retrieval-Augmented Generation (Modular RAG). Dans cet article, nous partageons les résultats de la recherche récente de Kapa.ai dans le refactoring du processus RAG standard en un processus basé sur un modèle d'inférence.
supposer que...
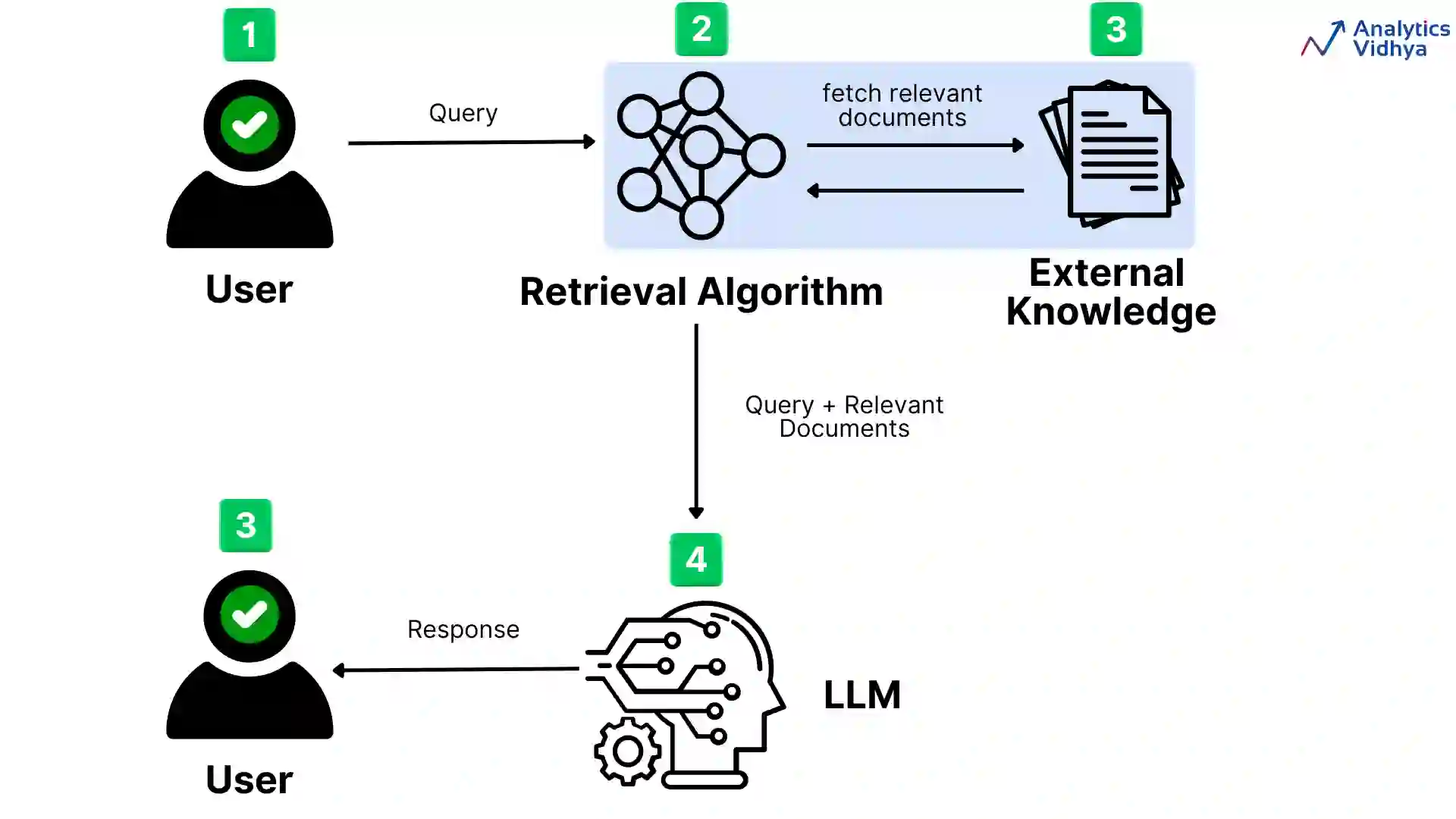
L'objectif principal de Kapa.ai en explorant cette idée est de simplifier le processus RAG et de réduire la dépendance à l'égard de l'ajustement manuel des paramètres. Les composants essentiels du processus RAG sont l'intégration dense et la recherche de documents. Un processus RAG typique de haut niveau est le suivant :
- Recevoir les invites de l'utilisateur.
- Prétraitement des requêtes pour améliorer la recherche d'informations.
- Les documents pertinents sont trouvés grâce à des recherches de similarités dans des bases de données vectorielles.
- Réorganiser les résultats et utiliser les documents les plus pertinents.
- Générer une réponse.

Chaque étape du processus est optimisée par des heuristiques telles que des règles de filtrage et des ajustements de tri pour hiérarchiser les données pertinentes. Ces optimisations codées en dur définissent le comportement du processus mais limitent également sa capacité d'adaptation.
Pour que le modèle d'inférence puisse utiliser les différents composants du processus RAG, Kapa.ai a dû configurer le système différemment. Au lieu de définir une séquence linéaire d'étapes, chaque composant est traité comme un module distinct que le modèle doit appeler.

Dans cette architecture, au lieu de suivre un processus fixe, les modèles dotés de capacités de raisonnement peuvent contrôler leur propre flux de travail de manière plus dynamique. En utilisant des outils, les modèles peuvent décider quand et à quelle fréquence effectuer des recherches complètes ou simplifiées, et quels paramètres de recherche utiliser. En cas de succès, cette approche pourrait remplacer les cadres d'orchestration RAG traditionnels tels que LangGraph.
En outre, un système plus modulaire offre des avantages supplémentaires :
- Les modules individuels peuvent être remplacés ou mis à niveau sans qu'il soit nécessaire de revoir complètement le processus.
- Une séparation plus claire des tâches facilite la gestion du débogage et des essais.
- Différents modules (par exemple, des extracteurs avec différents enchâssements) peuvent être testés et remplacés pour comparer les performances.
- Les modules peuvent être étendus indépendamment pour différentes sources de données.
- Cela pourrait potentiellement permettre à Kapa.ai de construire différents modules personnalisés pour des tâches ou des domaines spécifiques.
Enfin, Kapa.ai souhaite également étudier si cette approche peut aider à "court-circuiter" plus efficacement les requêtes abusives ou hors sujet. Les cas les plus difficiles impliquent généralement une ambiguïté, c'est-à-dire qu'il n'est pas clair si la requête est pertinente pour le produit. Les requêtes abusives sont souvent délibérément conçues pour échapper à la détection. Si les cas les plus simples peuvent déjà être traités efficacement, Kapa.ai espère que le modèle d'inférence permettra d'identifier et de résoudre plus rapidement les problèmes les plus complexes.
configuration du test
Pour expérimenter ce flux de travail, Kapa.ai a construit un système RAG en bac à sable contenant les composants nécessaires, des données statiques et une suite d'évaluation avec LLM comme arbitre. Dans une configuration, Kapa.ai a utilisé un processus linéaire fixe typique avec des optimisations codées en dur.
Pour le processus modulaire RAG, Kapa.ai a utilisé le modèle o3-mini comme modèle d'inférence et a exécuté diverses configurations du processus sous différentes politiques afin d'évaluer les approches qui ont fonctionné et celles qui n'ont pas fonctionné :
- Utilisation de l'outil : Kapa.ai tente de donner au modèle un accès complet à tous les outils et à l'ensemble du processus, et tente également de limiter l'utilisation des outils à une combinaison d'un seul outil avec un processus linéaire fixe.
- Conseils et paramétrage : Kapa.ai a testé à la fois des signaux ouverts avec un minimum d'instructions et des signaux très structurés. Kapa.ai a également expérimenté différents degrés d'appels d'outils pré-paramétrés, plutôt que de laisser le modèle déterminer ses propres paramètres.
Dans tous les tests effectués par Kapa.ai, le nombre d'appels d'outils a été limité à un maximum de 20 - pour une requête donnée, le modèle ne permet d'utiliser qu'un maximum de 20 appels d'outils.Kapa.ai a également effectué tous les tests avec des forces d'inférence moyennes et élevées :
- Moyen : Étapes plus courtes de la chaîne de pensée (CoT)
- Plus haut : Des étapes plus longues du CdT avec un raisonnement plus détaillé
Au total, Kapa.ai a réalisé 58 évaluations de différentes configurations modulaires de RAG.
en fin de compte
Les résultats des expériences ont été mitigés. Dans certaines configurations, Kapa.ai a observé des améliorations modestes, notamment dans la génération de code et, dans une certaine mesure, dans l'affacturage. Cependant, des paramètres clés tels que la qualité de la recherche d'informations et l'extraction de connaissances sont restés largement inchangés par rapport au flux de travail traditionnel de Kapa.ai réglé manuellement.
Un problème récurrent tout au long du processus de test est que le raisonnement par chaîne de pensée (CoT) ajoute de la latence. Si un raisonnement plus approfondi permet au modèle de décomposer des requêtes complexes et de s'auto-corriger, cela se fait au prix d'un temps supplémentaire pour les appels itératifs à l'outil.
Le plus grand défi identifié par Kapa.ai est le "raisonnement ≠ expérience fallacy" : le modèle de raisonnement, bien qu'il soit capable de penser étape par étape, manque d'expérience a priori avec les outils de recherche. Même avec des conseils rigoureux, il a eu du mal à récupérer des résultats de haute qualité et à distinguer les bons des mauvais résultats. Le modèle a souvent hésité à utiliser les outils fournis par Kapa.ai, comme dans les expériences que Kapa.ai a menées l'année dernière avec le modèle o1. Cela met en évidence un problème plus large : les modèles d'inférence sont bons pour la résolution de problèmes abstraits, mais l'optimisation de l'utilisation d'outils sans formation préalable reste un défi de taille.
Principales conclusions
- L'expérience a révélé une "erreur de raisonnement ≠ expérience" évidente : le modèle de raisonnement lui-même ne "comprend" pas l'outil de recherche. Il comprend la fonction et l'objectif de l'outil, mais ne sait pas comment l'utiliser, alors que les humains possèdent cette connaissance tacite après avoir utilisé l'outil. Contrairement aux processus traditionnels, où l'expérience est encodée dans l'heuristique et l'optimisation, le modèle de raisonnement doit être explicitement formé à l'utilisation efficace de l'outil.
- Bien que le modèle o3-mini soit capable de gérer des contextes plus larges, Kapa.ai observe qu'il ne fournit pas d'amélioration significative par rapport à des modèles tels que 4o ou Sonnet en termes d'extraction de connaissances. La simple augmentation de la taille du contexte n'est pas une panacée pour améliorer les performances de recherche.
- L'augmentation de la force d'inférence du modèle n'améliorera que marginalement la précision des faits. Les ensembles de données de kapa.ai se concentrent sur le contenu technique pertinent pour les cas d'utilisation du monde réel, plutôt que sur des problèmes de concours de mathématiques ou des défis de codage avancés. L'impact de la force d'inférence peut varier selon le domaine et peut produire des résultats différents pour les ensembles de données contenant des requêtes plus structurées ou plus complexes sur le plan informatique.
- Un domaine dans lequel le modèle excelle est la génération de codes, ce qui suggère que les modèles d'inférence peuvent être particulièrement bien adaptés aux domaines qui nécessitent des résultats structurés et logiques plutôt qu'une simple recherche.
- Les modèles de raisonnement n'ont pas de connaissances liées aux outils.
Raisonnement ≠ sophisme empirique
La principale conclusion de ces expériences est que le modèle d'inférence ne possède pas naturellement de connaissances spécifiques à l'outil. Contrairement aux processus RAG finement réglés, qui encodent la logique de recherche dans des étapes prédéfinies, les modèles d'inférence traitent chaque appel de recherche à partir de zéro. Cela conduit à l'inefficacité, à l'indécision et à une utilisation sous-optimale de l'outil.
Pour atténuer ce problème, plusieurs stratégies peuvent être envisagées. Il peut être utile d'affiner la stratégie de repérage, c'est-à-dire d'élaborer des instructions spécifiques à l'outil de manière à fournir des indications plus explicites au modèle. Le pré-entraînement ou la mise au point des modèles pour l'utilisation d'outils pourrait également les familiariser avec des mécanismes de récupération spécifiques.
En outre, une approche hybride peut être envisagée, dans laquelle des heuristiques prédéfinies s'occupent de certaines tâches et des modèles d'inférence interviennent de manière sélective en cas de besoin.
Ces idées en sont encore au stade de la spéculation, mais elles indiquent des moyens de combler le fossé entre la capacité de raisonnement et la mise en œuvre effective de l'outil.
résumés
Bien que le RAG modulaire basé sur l'inférence n'ait pas montré d'avantages significatifs par rapport aux processus traditionnels dans le contexte des cas d'utilisation de Kapa.ai, l'expérience a fourni des indications précieuses sur son potentiel et ses limites. La flexibilité d'une approche modulaire reste attrayante. Elle peut améliorer l'adaptabilité, simplifier les mises à niveau et s'adapter dynamiquement à de nouveaux modèles ou sources de données.
Pour l'avenir, un certain nombre de technologies prometteuses méritent d'être explorées plus avant :
- Utiliser différentes stratégies de repérage et de préformation/réglage pour améliorer la façon dont le modèle comprend et interagit avec l'outil de récupération.
- Utiliser les modèles de raisonnement de manière stratégique dans certaines parties du processus, par exemple pour des cas d'utilisation spécifiques ou des tâches telles que la réponse à des questions complexes ou la génération de codes, plutôt que d'orchestrer l'ensemble du flux de travail.
À ce stade, les modèles de raisonnement comme o3-mini n'ont pas surpassé les processus RAG traditionnels pour les tâches de recherche de base dans des contraintes de temps raisonnables. Au fur et à mesure que les modèles progressent et que les stratégies d'utilisation des outils évoluent, les systèmes modulaires de RAG basés sur le raisonnement peuvent devenir une alternative viable, en particulier pour les domaines qui nécessitent des flux de travail dynamiques à forte intensité logique.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...