MiniMax-M1 - Modèle d'inférence Open Source de MiniMax
Qu'est-ce que MiniMax-M1 ?
MiniMax-M1 est un modèle d'inférence open source de l'équipe MiniMax, basé sur une combinaison de l'architecture experte mixte (MoE) et du mécanisme Lightning Attention, avec 456 milliards de paramètres au total. Le modèle supporte 1 million de jeton MiniMax-M1 a un contexte long en entrée et 80 000 jetons en sortie, ce qui le rend adapté aux documents longs et aux tâches de raisonnement complexes. Le modèle est disponible en versions 40K et 80K afin d'optimiser les ressources informatiques et de réduire les coûts de raisonnement. miniMax-M1 surpasse plusieurs modèles open source dans des tâches telles que le génie logiciel, la compréhension de contextes longs et l'utilisation d'outils. La puissance de calcul efficace du modèle et ses capacités de raisonnement robustes en font une base puissante pour la prochaine génération d'agents de modélisation linguistique.

Caractéristiques principales du MiniMax-M1
- traitement contextuel de longue duréeIl peut traiter efficacement des documents longs, des rapports longs, des articles universitaires et d'autres contenus textuels longs, ce qui convient aux tâches de raisonnement complexes.
- Raisonnement efficaceLe système de gestion de l'inférence est un outil de gestion de l'inférence qui permet d'optimiser l'allocation des ressources informatiques, de réduire les coûts de l'inférence et de maintenir des performances élevées.
- Optimisation des tâches pluridisciplinairesLes candidats à l'entrée dans l'Union européenne : ils excellent dans des tâches telles que le raisonnement mathématique, l'ingénierie logicielle, la compréhension du contexte et l'utilisation d'outils sur une longue période.
- appel de fonctionLa fonction d'appel de fonction structurée permet d'identifier et d'émettre des paramètres d'appel de fonction externe, ce qui facilite l'interaction avec des outils externes afin d'améliorer l'automatisation et l'efficacité du travail.
Performance du MiniMax-M1
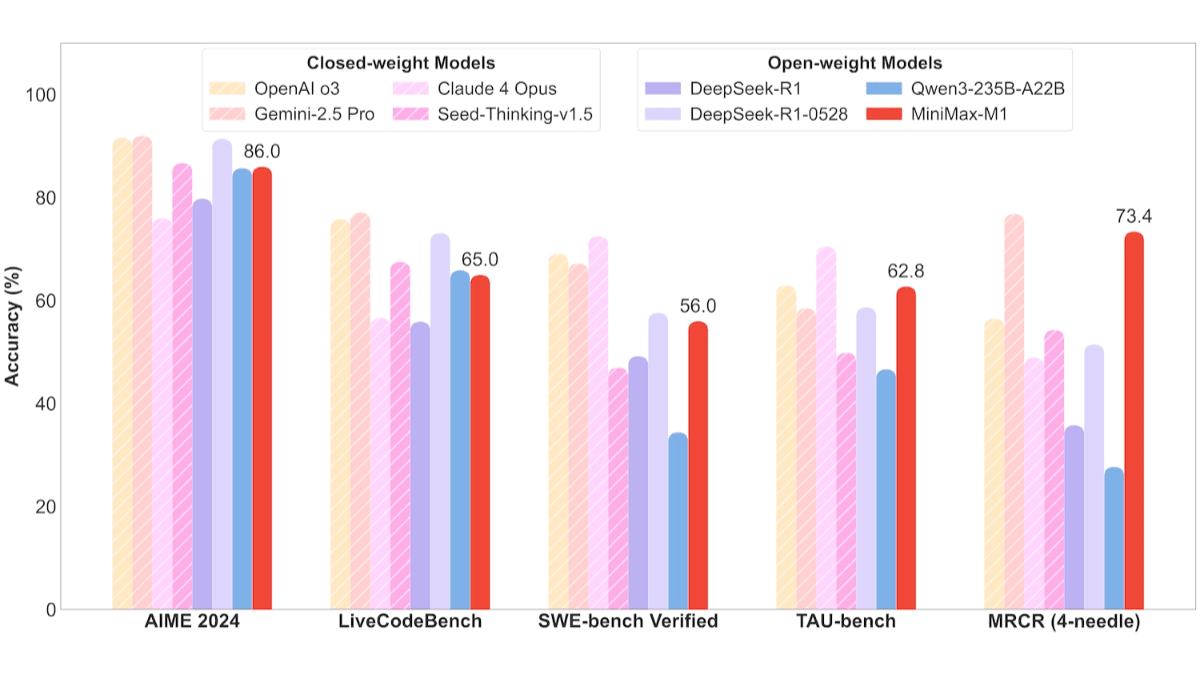
- Tâches d'ingénierie logicielleDans le benchmark SWE, MiniMax-M1-40k et MiniMax-M1-80k ont atteint respectivement 55,61 TP3T et 56,01 TP3T, ce qui est légèrement inférieur aux 57,61 TP3T de DeepSeek-R1-0528 et surpasse de manière significative les autres modèles open source.
- Longues tâches de compréhension contextualiséesEn s'appuyant sur des millions de fenêtres contextuelles, MiniMax-M1 excelle dans les tâches de compréhension de contextes longs, surpassant tous les modèles open source, et même OpenAI o3 et Claude 4 Opus, et se classant au deuxième rang mondial derrière Gemini 2.5 Pro.
- Scénarios d'utilisation des outilsDans le test TAU, MiniMax-M1-40k a devancé tous les modèles open source, en battant Gemini-2.5 Pro.
Adresse du site officiel de MiniMax-M1
- Dépôt GitHub: :https://github.com/MiniMax-AI/MiniMax-M1
- Bibliothèque de modèles HuggingFace: :https://huggingface.co/collections/MiniMaxAI/minimax-m1
- Documents techniques: :https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
Comment utiliser MiniMax-M1
- Appels de l'API: :
- Visiter le site officiel: Visitez MiniMax Site officielPour cela, inscrivez-vous et connectez-vous à votre compte.
- Obtenir la clé APIPour obtenir une clé d'API : Demandez une clé d'API dans l'espace personnel ou sur la page du développeur.
- Utiliser l'APIInvocation du modèle sur la base de requêtes HTTP, conformément à la documentation officielle de l'API. Par exemple, envoyer une requête en utilisant la bibliothèque requests de Python :
import requests
url = "https://api.minimax.cn/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "MiniMax-M1",
"messages": [
{"role": "user", "content": "请生成一段关于人工智能的介绍。"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())- Utilisation du visage de l'étreinte: :
- Installation de la bibliothèque Hugging FaceLes dépendances, telles que les transformateurs et Torch, sont installées.
pip install transformers torch- Modèles de chargementChargement d'un modèle MiniMax-M1 à partir du Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MiniMaxAI/MiniMax-M1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
input_text = "请生成一段关于人工智能的介绍。"
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs, max_length=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))- Utilisation sur MiniMax APP ou Web: :
- Accès au WebLe modèle génère directement la réponse : connectez-vous au site Web MiniMax, saisissez une question ou une tâche sur la page, et le modèle génère directement la réponse.
- TELECHARGER L'APPPour cela, téléchargez l'application MiniMax APP sur votre téléphone portable et interagissez avec elle en utilisant des opérations similaires.
Prix des produits pour MiniMax-M1
- Coût de l'inférence des appels API: :
- 0-32k Longueur d'entrée: :
- coût des intrants: 0,8 $/million de jetons.
- coût de production: jeton de 8 $/million.
- 32k-128k Longueur d'entrée: :
- coût des intrants: 1,2 million de dollars de jetons.
- coût de production: 16 dollars par million de jetons.
- 128k-1M Longueur d'entrée: :
- coût des intrants: 2,4 $/million de jetons.
- coût de production: 24 dollars par million de jetons.
- 0-32k Longueur d'entrée: :
- APP et Web: :
- Utilisation gratuiteMiniMax APP et Web offrent un accès gratuit et illimité, adapté aux utilisateurs généraux et aux utilisateurs sans connaissances techniques.
Avantages principaux du MiniMax-M1
- capacité de traitement en contexte longIl prend en charge des entrées allant jusqu'à 1 million de tokens et des sorties allant jusqu'à 80 000 tokens, ce qui le rend adapté au traitement de longs documents et à des tâches de raisonnement complexes.
- Performances d'inférence efficacesLe système d'inférence de la Commission européenne est le suivant : il fournit deux versions de budget d'inférence de 40K et 80K, combinées avec le mécanisme d'attention éclair pour optimiser les ressources de calcul et réduire les coûts d'inférence.
- Optimisation des tâches pluridisciplinairesLes candidats doivent exceller dans des tâches telles que l'ingénierie logicielle, la compréhension du contexte à long terme, le raisonnement mathématique et l'utilisation d'outils, en s'adaptant à divers scénarios d'application.
- Architecture technologique avancéeLe modèle est basé sur une architecture experte hybride (MoE) et une formation par apprentissage par renforcement à grande échelle (RL) afin d'améliorer l'efficacité des calculs et la performance du modèle.
- un rapport qualité-prix élevéLa performance est proche des principaux modèles internationaux, tout en offrant des stratégies de tarification flexibles, et l'utilisation de l'APP et du Web est gratuite, ce qui réduit l'obstacle à l'utilisation.
Personnes auxquelles MiniMax-M1 est destiné
- développeursLes développeurs de logiciels génèrent efficacement du code, optimisent la structure du code, déboguent les programmes ou génèrent automatiquement de la documentation sur le code.
- Chercheurs et universitairesLes tâches suivantes sont possibles : traiter de longs documents universitaires, effectuer des analyses documentaires ou des analyses de données complexes, utiliser des modèles pour organiser rapidement les idées, produire des rapports et résumer les résultats.
- créateur de contenuLe MiniMax-M1 peut être utilisé par ceux qui doivent créer des contenus longs pour les aider à trouver des idées, à rédiger des ébauches d'histoires, à retoucher des textes ou à créer des fictions longues, entre autres.
- écoliersLe Comité d'experts de l'Union européenne (CEI) : pour avoir fourni des solutions claires et une aide à la rédaction.
- utilisateur professionnelLes entreprises les intègrent dans des solutions d'automatisation, telles que le service client intelligent, les outils d'analyse de données ou l'automatisation des processus d'entreprise.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...