MiMo-VL - Le modèle multimodal open source de Xiaomi
Qu'est-ce que MiMo-VL ?
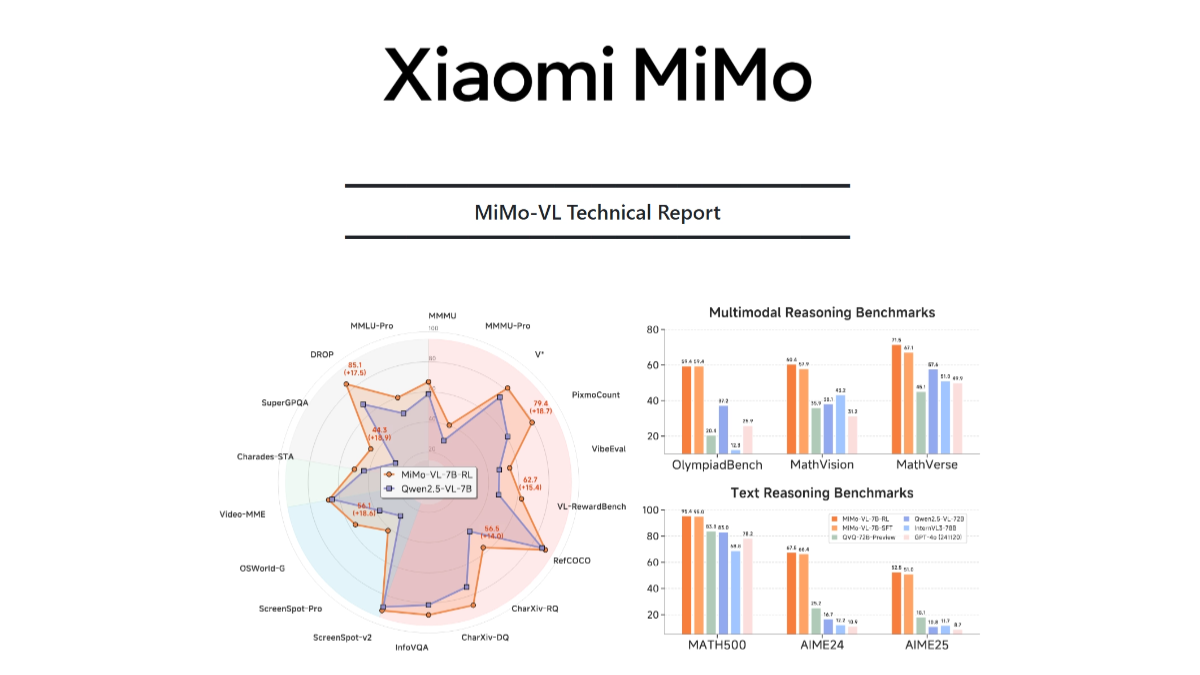
MiMo-VL est le grand modèle multimodal open-source de Xiaomi, qui se compose d'un codeur visuel, d'une couche de projection multimodale et d'un modèle de langage. Le codeur visuel est basé sur Qwen2.5-ViT, qui prend en charge la résolution d'entrée native et préserve plus de détails ; le modèle de langage est MiMo-7B, développé par Xiaomi, optimisé pour le raisonnement complexe. Le modèle est basé sur une stratégie de pré-entraînement en plusieurs étapes, entraînée avec 2,4 tonnes de données multimodales, couvrant des types de données tels que des paires image-texte, des paires vidéo-texte et des séquences d'opérations de l'interface utilisateur graphique. Basé sur l'algorithme hybride d'apprentissage par renforcement en ligne (MORL), l'inférence du modèle, la performance perceptuelle et l'expérience de l'utilisateur sont améliorées dans tous les aspects. MiMo-VL est performant dans l'inférence d'images complexes, l'interaction avec l'interface graphique, la compréhension de vidéos et l'analyse de documents longs, par exemple, il atteint 66,7% sur MMMU-val, surpassant Gemma 3 27B ; 59,4% sur OlympiadBench 59,4% sur OlympiadBench, dépassant le modèle 72B.
Caractéristiques principales de MiMo-VL
- Raisonnement sur les images complexes et quizLes élèves sont capables de comprendre avec précision le contenu d'images complexes et de donner des explications et des réponses raisonnables.
- Fonctionnement et interaction de l'interface graphiqueLe système de gestion de l'information (GUI) : il prend en charge jusqu'à plus de 10 étapes d'opérations GUI afin de comprendre et d'exécuter des instructions complexes.
- Vidéo et compréhension de la langueLa langue : comprendre le contenu des vidéos, raisonner et faire des quiz en lien avec la langue.
- Analyse et raisonnement de documents longsLa recherche sur les documents longs : traitement des documents longs pour le raisonnement complexe et l'extraction d'informations.
- Optimisation de l'expérience utilisateurAmélioration de l'inférence, de la performance perceptuelle et de l'expérience de l'utilisateur basée sur l'apprentissage par renforcement hybride en ligne.
Adresse du site officiel de MiMo-VL
- Dépôt Github: :https://github.com/XiaomiMiMo/MiMo-VL
- Bibliothèque de modèles HuggingFace: :https://huggingface.co/collections/XiaomiMiMo/mimo-vl
- Documents techniques: :https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report
Comment utiliser MiMo-VL
- Plate-forme d'étreinte: :
- Accès à la bibliothèque de modèles Hugging FaceAccès aux MiMo-VL : Accès aux MiMo-VLBibliothèque de modèles de visages étreintsPage.
- Modèles de chargementUtilisation de la bibliothèque Python de Hugging Face pour charger le modèle MiMo-VL. Exemple :
from transformers import AutoModelForVision2Seq, AutoProcessor
model = AutoModelForVision2Seq.from_pretrained("XiaomiMiMo/mimo-vl")
processor = AutoProcessor.from_pretrained("XiaomiMiMo/mimo-vl")- Traitement des données d'entréeLes données d'entrée telles que les images, les vidéos ou le texte sont prétraitées en fonction du processeur.
- Générer une sortieLes données traitées sont introduites dans le modèle et la sortie du modèle est obtenue.
- Dépôt GitHub: :
- Cloner des dépôts GitHub: AccèsDépôt GitHub, cloner le référentiel localement.
git clone https://github.com/XiaomiMiMo/MiMo-VL.git- Installation des dépendancesInstaller les dépendances Python requises selon le fichier requirements.txt dans le référentiel.
pip install -r requirements.txt- code en cours d'exécutionLes instructions du référentiel : Suivez les instructions du référentiel pour exécuter un exemple de code ou ouvrir une application.
Les principaux avantages du MiMo-VL
- Forte capacité de fusion multimodaleLes données multimodales : traitement de données multimodales telles que des images, des vidéos et du texte pour comprendre des scénarios complexes.
- Excellentes performances en matière d'inférenceExcellentes performances dans plusieurs benchmarks, telles que 66,71 TP3T sur MMMU-val et 59,41 TP3T sur OlympiadBench.
- Optimisation de l'expérience utilisateurLe modèle est basé sur l'apprentissage par renforcement mixte en ligne (MORL). Les comportements du modèle sont ajustés de manière dynamique en fonction des commentaires de l'utilisateur afin d'améliorer l'expérience de ce dernier.
- Large éventail de scénarios d'applicationLes applications sont multiples : service client intelligent, maison intelligente, recherche scientifique, etc.
- Source ouverte et soutien de la communautéLes services de recherche et de développement : fournir un code source ouvert et un soutien communautaire pour faciliter la recherche et le développement des développeurs.
Personnes auxquelles MiMo-VL est destiné
- Chercheurs en IA: se concentre sur la recherche dans les domaines de la fusion multimodale, du raisonnement complexe, de la vision et de la compréhension du langage.
- Développeurs et ingénieurs: Le développement d'applications intelligentes telles que le service client intelligent, la maison intelligente, les soins de santé intelligents, etc. nécessite l'intégration de fonctionnalités multimodales.
- scientifique des donnéesLes données multimodales : Traitement et analyse des données multimodales pour améliorer la performance des modèles et l'efficacité du traitement des données.
- Éducateurs et étudiantsLes aides à l'enseignement et à l'apprentissage, par exemple la résolution de problèmes de mathématiques, l'apprentissage de la programmation, etc.
- Professionnels de la santéLes services d'aide à l'analyse des images médicales et à la compréhension des textes afin d'améliorer l'efficacité et la précision des diagnostics.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...