MiDashengLM - Le modèle de compréhension sonore open source de Xiaomi

Qu'est-ce que MiDashengLM ?
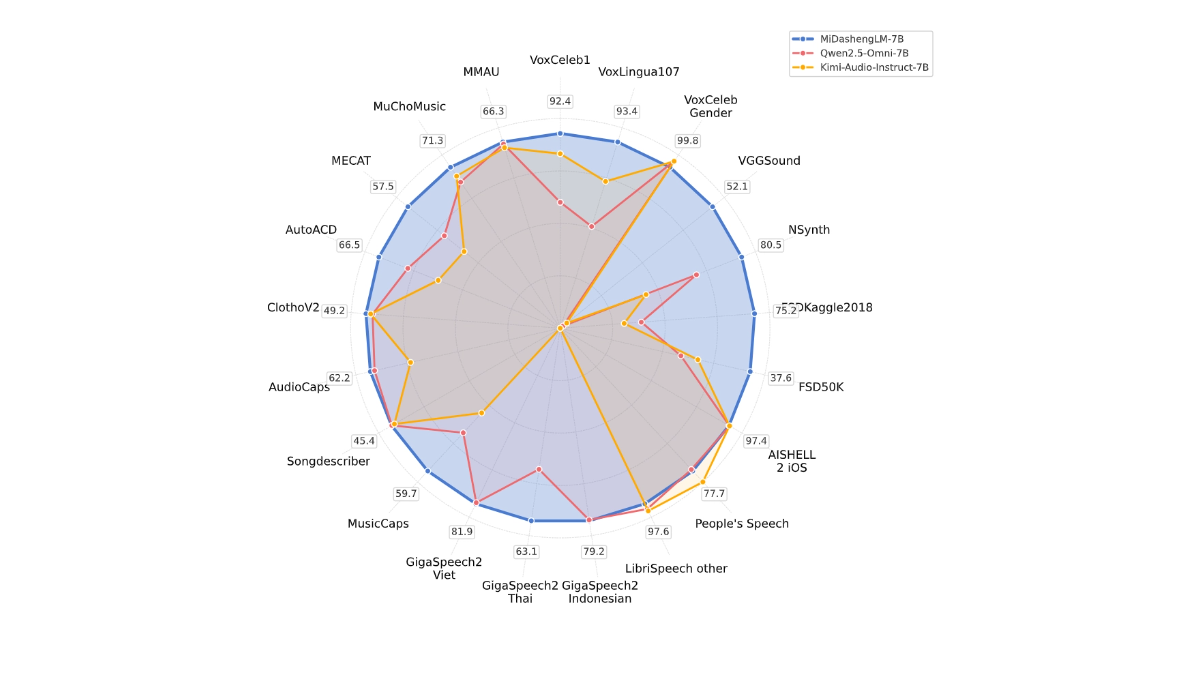
MiDashengLM est le grand modèle open source de Xiaomi pour une compréhension efficace des sons, avec la version de paramètre spécifique MiDashengLM-7B, qui se concentre sur le traitement et la compréhension audio. Le modèle est construit sur la base de l'encodeur audio Xiaomi Dasheng et du décodeur Qwen2.5-Omni-7B Thinker, qui peut unifier la compréhension de la parole, du son ambiant et de la musique. Le modèle a une excellente efficacité d'inférence, avec le premier modèle de compréhension de la parole, du son ambiant et de la musique. Jeton Les données de formation de MiDashengLM sont entièrement libres, ce qui permet une utilisation à la fois académique et commerciale, et fournit un support puissant pour améliorer l'expérience d'interaction multimodale.
Principales caractéristiques de MiDashengLM
- Contenu audio vers texteLe modèle traduit différents types de sons, tels que des voix, des bruits de la nature ou de la musique, en descriptions textuelles qui aident les gens à comprendre rapidement ce qui se passe réellement dans l'audio.
- Identifier les catégories audioLe modèle peut déterminer si un élément audio est de la parole, un son ambiant ou de la musique, etc., tout comme l'étiquetage de l'audio pour faciliter son utilisation dans différents scénarios.
- reconnaissance vocaleLe texte : Il convertit en texte ce que dit une personne, prend en charge plusieurs langues et est particulièrement adapté aux assistants vocaux ou aux appareils intelligents.
- Questions et réponses audioLe modèle répond aux questions basées sur le contenu audio, par exemple en demandant "Quel était ce son ?" dans la voiture, et le modèle répond.
- interaction multimodaleLa capacité à comprendre les informations audio et autres (texte, images, etc.) conjointement, ce qui permet des interactions plus intelligentes et plus naturelles avec l'appareil.
Adresse du site officiel de MiDashengLM
- Dépôt GitHub: : https://github.com/xiaomi-research/dasheng-lm
- Bibliothèque de modèles HuggingFace: : https://huggingface.co/mispeech/midashenglm-7b
- Documents techniques: : https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- Démonstration de l'expérience en ligne: : https://huggingface.co/spaces/mispeech/MiDashengLM-7B
Comment utiliser MiDashengLM
- Expérience en ligneVisitez la démo de l'expérience en ligne de MiDashengLM.
- Téléchargement de fichiers audioTélécharger un fichier audio (les formats pris en charge sont WAV, MP3, etc.).
- En attente de traitementLe modèle traite automatiquement l'audio après l'avoir téléchargé et génère les résultats.
- Voir les résultatsLes résultats de la description ou de la classification générés par le modèle peuvent être consultés une fois le traitement terminé.
Les points forts de MiDashengLM
- Performances d'inférence efficacesL'efficacité de l'inférence de MiDashengLM est extrêmement élevée, la latence du premier jeton est très faible et le débit est considérablement amélioré, ce qui le rend adapté aux scénarios d'interaction en temps réel.
- Compréhension audio puissanteIl permet une compréhension unifiée d'un large éventail de sons, y compris la parole, les sons ambiants et la musique, en évitant les limites des méthodes traditionnelles.
- Données et modèles Open SourceLes données et les modèles de formation sont entièrement libres, ce qui facilite la recherche et le développement secondaire par les développeurs et permet une utilisation académique et commerciale.
- Large éventail de scénarios d'applicationLes applications sont multiples : cockpit intelligent, maison intelligente, assistant vocal, création de contenu audio, éducation et apprentissage, etc.
- Optimisation technologiqueMiDashengLM : Basé sur un codeur et un décodeur audio optimisés, MiDashengLM excelle dans le traitement de tâches audio complexes tout en réduisant la charge de calcul.
- Stratégies de formationUne stratégie de formation basée sur l'alignement des descriptions audio génériques et l'analyse multi-expert garantit que le modèle apprend les associations sémantiques profondes de l'audio et améliore la généralisation.
Personnes auxquelles MiDashengLM est destiné
- Chercheurs en intelligence artificielleLe modèle fournit aux chercheurs des modèles de compréhension audio et des données de formation en libre accès afin de faciliter la recherche et l'innovation dans des domaines connexes.
- Développeurs d'appareils intelligentsPour les équipes qui développent des produits tels que des cockpits intelligents, des maisons intelligentes, des assistants vocaux, etc., le modèle est rapidement intégré au produit afin d'améliorer l'expérience d'interaction.
- Créateurs de contenu audioLes créateurs audio utilisent des modèles pour générer automatiquement des descriptions et des étiquettes audio afin d'améliorer l'efficacité de la création de contenu.
- Éducateurs et apprenantsdans le domaine de l'apprentissage des langues et de l'éducation musicale, en apportant une aide à la prononciation et des conseils théoriques afin d'aider les apprenants à mieux acquérir les connaissances..
- utilisateur professionnelLe système d'information sur la santé : Une solution efficace pour les entreprises qui ont besoin d'une fonctionnalité de compréhension audio compatible avec une utilisation commerciale et qui peut être utilisée pour le développement de produits et l'optimisation de services.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...