
MegaPairs : un nouveau modèle d'intégration de vecteurs multimodaux de BGE
Introduction générale
MegaPairs est un projet open source sur GitHub de l'équipe VectorSpaceLab visant à générer des modèles d'intégration multimodale pour les tâches de recherche d'images et de textes à l'aide de techniques de synthèse de données à grande échelle. Le projet est basé sur plus de 26 millions d'ensembles de données hétérogènes KNN triad, entraîné BGE-VL série de modèles , y compris BGE-VL-CLIP (base et grandes versions) et BGE-VL-MLLM (S1 et S2 versions). Parmi eux, BGE-VL-MLLM-S1 améliore les performances de 8,1% sur le benchmark CIRCO de récupération d'images à zéro échantillon (mAP@5) et obtient également de bons résultats dans le benchmark d'intégration multimodale MMEB. Le code et le modèle ont été mis à disposition sur GitHub et Hugging Face, et l'ensemble de données devrait être publié ultérieurement sous licence MIT, avec des données provenant de Recap-Datacomp (licence CC BY 4.0).

Liste des fonctions
- Générer des ensembles de données à grande échelleLe site Web de l'Institut d'études de marché (IEM) : il fournit plus de 26 millions de triplets KNN hétérogènes pour l'apprentissage de modèles d'intégration multimodaux.
- Modèle d'intégration BGE-VL-CLIPIl comprend une version de base et une version étendue, génère des représentations intégrées d'images et de textes, et permet une recherche efficace.
- Modèle d'intégration BGE-VL-MLLMLes versions S1 et S2 sont disponibles et génèrent des encastrements multimodaux très performants qui prennent en charge l'extraction à partir d'un échantillon zéro.
- Prise en charge de la recherche de l'échantillon zéroLes données sur les images et les textes : Générer des embeddings et effectuer des tâches de recherche d'images et de textes sans formation.
- Modèle open source et extension: Fournit des modèles pré-entraînés à Hugging Face, en facilitant le téléchargement, l'utilisation et la mise au point.
Utiliser l'aide
MegaPairs distribue le code et les modèles via GitHub et Hugging Face, ce qui permet aux utilisateurs de générer rapidement des embeddings multimodaux et d'effectuer des tâches de recherche. Vous trouverez ci-dessous un guide pratique détaillé, basé sur les instructions officielles pour BGE-VL-MLLM-S1 (Hugging Face).
Acquisition et installation
- Accéder aux dépôts GitHub: Ouvrir
https://github.com/VectorSpaceLab/MegaPairs, voir les détails du projet. - entrepôt de clonesLe code est téléchargé à partir de l'ordinateur de l'utilisateur : Exécutez la commande suivante dans le terminal pour télécharger le code :
git clone https://github.com/VectorSpaceLab/MegaPairs.git
cd MegaPairs
- Installation des dépendancesPython : En utilisant Python 3.10, créez un environnement virtuel et installez les bibliothèques nécessaires :
python -m venv venv
source venv/bin/activate # Linux/Mac
venv\Scripts\activate # Windows
pip install torch transformers==4.41.2 sentencepiece
Demande d'accolade transformers==4.41.2 répondre en chantant sentencepiece.
4. Télécharger les modèles: Obtenir BGE-VL-MLLM-S1 de Hugging Face :
- Visitez le site https://huggingface.co/BAAI/BGE-VL-MLLM-S1
- Téléchargement automatique via un script Python (voir ci-dessous).
Utilisation des fonctions principales
1. utilisation de séries de données
Le jeu de données MegaPairs, qui contient 26 millions de triples pour l'entraînement des modèles d'intégration multimodale, n'a pas encore été entièrement publié et devrait l'être dans le cadre de l'initiative Visage étreint Offre.
- Méthode d'acquisitionLes résultats de l'étude sont disponibles sur le site web de la Commission européenne : gardez un œil sur la mise à jour officielle, téléchargez-la et utilisez-la pour l'entraînement ou la validation du modèle.
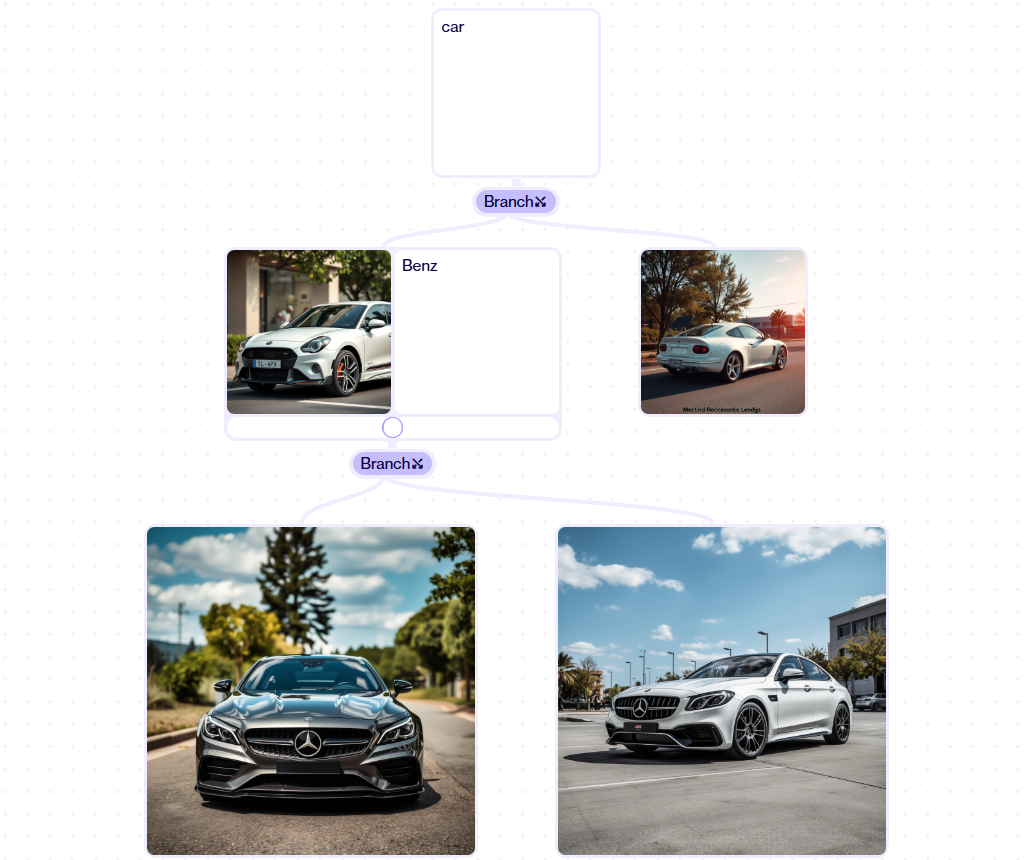
- format des donnéesL'application de l'image ternaire (image d'interrogation, description textuelle, image cible) permet de générer et d'extraire des images intégrées.
2) Génération de l'intégration multimodale (BGE-VL-MLLM-S1)
BGE-VL-MLLM-S1 est le modèle d'intégration principal pour générer des représentations intégrées d'images et de textes et compléter la recherche. Le code officiel est le suivant :
- Modèles de chargement:
import torch
from transformers import AutoModel, AutoProcessor
model_name = "BAAI/BGE-VL-MLLM-S1"
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
model.eval()
model.cuda() # 使用 GPU 加速
- Générer l'intégration et la récupération:
from PIL import Image # 准备输入 query_image = Image.open("./cir_query.png").convert("RGB") query_text = "Make the background dark, as if the camera has taken the photo at night" candidate_images = [Image.open("./cir_candi_1.png").convert("RGB"), Image.open("./cir_candi_2.png").convert("RGB")] # 处理查询数据 query_inputs = processor( text=query_text, images=query_image, task_instruction="Retrieve the target image that best meets the combined criteria by using both the provided image and the image retrieval instructions: ", return_tensors="pt", q_or_c="q" ) query_inputs = {k: v.cuda() for k, v in query_inputs.items()} # 处理候选数据 candidate_inputs = processor( images=candidate_images, return_tensors="pt", q_or_c="c" ) candidate_inputs = {k: v.cuda() for k, v in candidate_inputs.items()} # 生成嵌入并计算相似度 with torch.no_grad(): query_embs = model(**query_inputs, output_hidden_states=True).hidden_states[-1][:, -1, :] candi_embs = model(**candidate_inputs, output_hidden_states=True).hidden_states[-1][:, -1, :] query_embs = torch.nn.functional.normalize(query_embs, dim=-1) candi_embs = torch.nn.functional.normalize(candi_embs, dim=-1) scores = torch.matmul(query_embs, candi_embs.T) print(scores) # 输出相似度得分- Interprétation des résultats:
scoresreprésente la similarité entre l'intégration de la requête et l'intégration du candidat, plus le score est élevé, plus la correspondance est importante.
- Interprétation des résultats:
3) Génération d'encastrements avec BGE-VL-CLIP
BGE-VL-CLIP (base/large) peut également générer des encastrements multimodaux :
- Charger et exécuter:
from transformers import AutoModel model_name = "BAAI/BGE-VL-base" model = AutoModel.from_pretrained(model_name, trust_remote_code=True) model.set_processor(model_name) model.eval() with torch.no_grad(): query = model.encode(images="./cir_query.png", text="Make the background dark") candidates = model.encode(images=["./cir_candi_1.png", "./cir_candi_2.png"]) scores = query @ candidates.T print(scores)
4. mise au point du modèle
Les utilisateurs peuvent affiner le modèle à l'aide de l'ensemble de données :
- Préparation des données: Préparer des paires ou des triples d'images et de textes.
- processus de mise au pointLe code de l'UE sera publié, disponible à l'adresse suivante
transformers(utilisé comme expression nominale)TrainerAPI. - valider (une théorie)Les résultats de l'évaluation de l'impact de l'action de l'UE sur l'environnement peuvent être testés à l'aide des indices de référence CIRCO ou MMEB.
Fonction en vedette Fonctionnement
Génération et récupération de l'intégration de l'échantillon zéro
Le BGE-VL-MLLM-S1 prend en charge le fonctionnement avec zéro échantillon :
- Saisissez des images et du texte, générez des encastrements et récupérez-les directement sans formation.
- Mise à jour du mAP@5 de 8.1% sur CIRCO.
Haute performance et évolutivité
- représentationsLes résultats de l'étude sont les suivants : Génération d'excellents encastrements multimodaux sur MMEB, encore optimisés pour la version S2.
- évolutivitéLa qualité de l'intégration s'améliore au fur et à mesure que le volume de données augmente, et 500 000 échantillons permettent déjà d'obtenir de meilleurs résultats que les modèles traditionnels.
mise en garde
- exigences en matière de matérielGPU recommandé (16 Go de mémoire vidéo ou plus).
- version de la dépendance: Utilisation
transformers==4.41.2répondre en chantantsentencepiece. - Soutien à la documentationLes pages GitHub et Hugging Face sont également disponibles.
- Aide à la communauté: Poser une question dans GitHub Issues ou Hugging Face Discussions.
Grâce aux étapes ci-dessus, l'utilisateur peut générer l'intégration multimodale et mener à bien la tâche de recherche.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...