
LongBench v2 : évaluer un texte long +o1 ?

Évaluation des grands modèles pour une "compréhension et un raisonnement profonds" dans le monde réel, les textes longs et les tâches multiples
Ces dernières années, des progrès significatifs ont été réalisés dans l'étude de grands modèles de langage pour les textes longs, la longueur de la fenêtre contextuelle des modèles ayant été étendue des 8k initiaux à 128k ou même 1M tokens. Cependant, une question clé demeure : ces modèles comprennent-ils réellement les textes longs qu'ils traitent ? En d'autres termes, sont-ils capables de comprendre, d'apprendre et de raisonner en profondeur sur la base des informations contenues dans les textes longs ?
Pour répondre à cette question et faire progresser les modèles de textes longs pour la compréhension et le raisonnement profonds, une équipe de chercheurs de l'université de Tsinghua et de Smart Spectrum a lancé LongBench v2, un test de référence conçu pour évaluer les capacités de compréhension et de raisonnement profonds des LLM dans le cadre d'une utilisation multitâche de textes longs dans le monde réel.
Nous pensons que LongBench v2 fera progresser l'exploration de la manière dont l'augmentation du calcul du temps d'inférence (par exemple, le modèle o1) peut aider à résoudre les problèmes de compréhension profonde et d'inférence dans les scénarios de textes longs.
spécificités
LongBench v2 présente plusieurs caractéristiques significatives par rapport aux benchmarks existants pour la compréhension de textes longs :
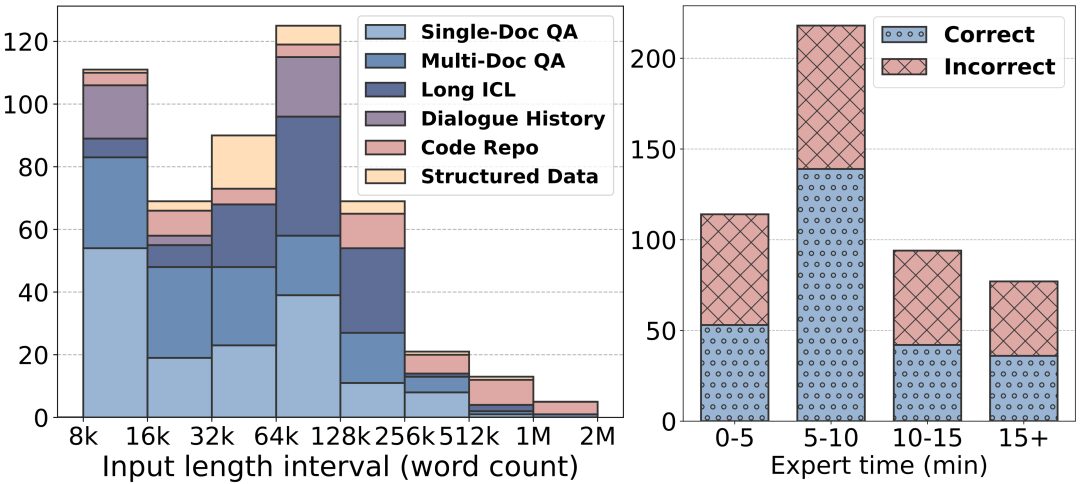
Des textes plus longs : la longueur des textes de LongBench v2 varie de 8k à 2M mots, la plupart des textes ayant une longueur inférieure à 128k.
Difficulté plus élevée : LongBench v2 contient 503 questions difficiles à choix multiples - des questions auxquelles même des experts humains utilisant l'outil de recherche dans les documents auraient du mal à répondre correctement dans un court laps de temps. Les experts humains n'ont obtenu en moyenne que 53,71 TP3T de précision (251 TP3T au hasard) dans le temps imparti de 15 minutes.
Couverture élargie des tâches : LongBench v2 couvre six catégories de tâches principales, notamment l'interrogation d'un seul document, l'interrogation de plusieurs documents, l'apprentissage du contexte d'un texte long, la compréhension de l'historique d'un dialogue long, la compréhension d'un référentiel de codes et la compréhension de données structurées longues, avec un total de 20 sous-tâches couvrant une variété de scénarios du monde réel.
Fiabilité accrue : afin de garantir la fiabilité de l'évaluation, toutes les questions de LongBench v2 sont au format à choix multiples et sont soumises à un processus rigoureux d'étiquetage manuel et de révision afin de garantir la haute qualité des données.
Processus de collecte des données
Pour garantir la qualité et la difficulté des données, LongBench v2 utilise un processus rigoureux de collecte de données qui comprend les étapes suivantes :
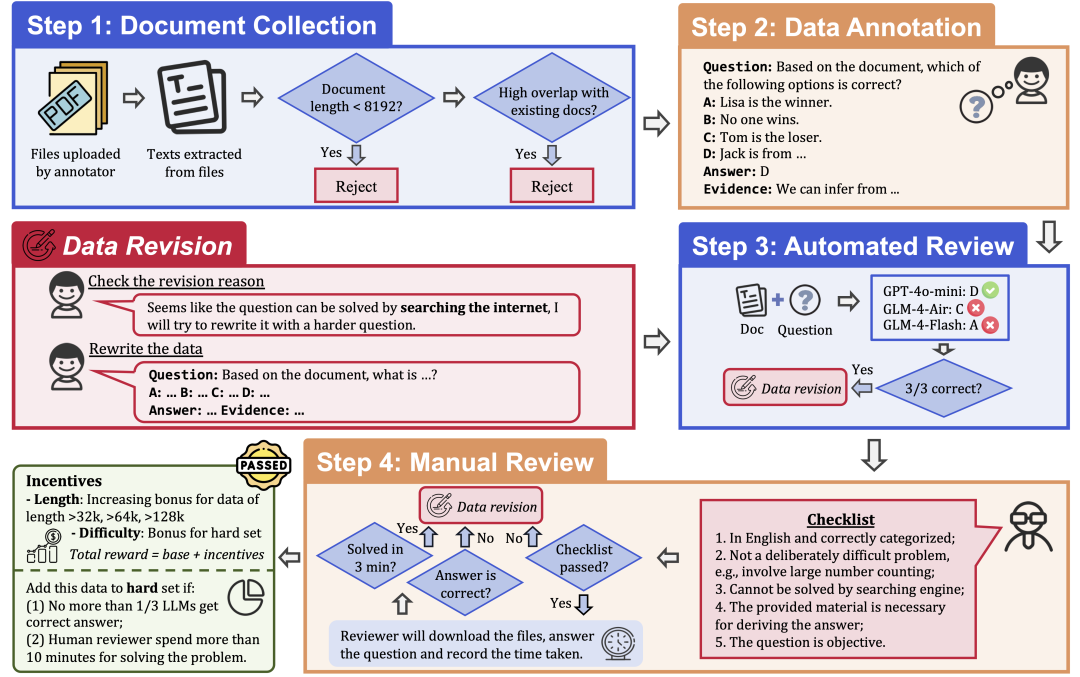
Collecte de documents : recruter 97 annotateurs issus d'universités de premier plan, de formations et de niveaux académiques variés, pour collecter des documents longs qu'ils ont personnellement lus ou utilisés, tels que des documents de recherche, des manuels, des romans, etc.
Étiquetage des données : sur la base des documents collectés, l'étiqueteur pose une question à choix multiples comportant quatre options, une réponse correcte et les preuves correspondantes.
Examen automatique : les données annotées ont été examinées automatiquement à l'aide de trois LLM (GPT-4o-mini, GLM-4-Air et GLM-4-Flash) avec des fenêtres contextuelles de 128k, et si les trois modèles répondaient correctement à la question, celle-ci était considérée comme trop simple et devait être réétiquetée.
Examen humain : les données qui passent l'examen automatisé sont soumises à un examen humain effectué par 24 experts humains professionnels qui tentent de répondre à la question et de déterminer si la question est appropriée et la réponse correcte. Si l'expert est capable de répondre correctement à la question en 3 minutes, la question est considérée comme trop simple et doit être réétiquetée. En outre, si l'expert estime que la question elle-même n'est pas appropriée ou que la réponse est incorrecte, la question sera renvoyée pour être corrigée.
Révision des données : les données qui ne passent pas l'audit seront renvoyées à l'annotateur pour être révisées jusqu'à ce qu'elles passent toutes les étapes de l'audit.
Résultats de l'évaluation
L'équipe a évalué 10 LLM à code source ouvert et 6 LLM à code source fermé en utilisant LongBench v2. Deux scénarios ont été pris en compte dans l'évaluation : zéro-coup et zéro-coup+CoT (c'est-à-dire laisser le modèle produire d'abord la chaîne de pensée, puis laisser le modèle produire la réponse choisie).
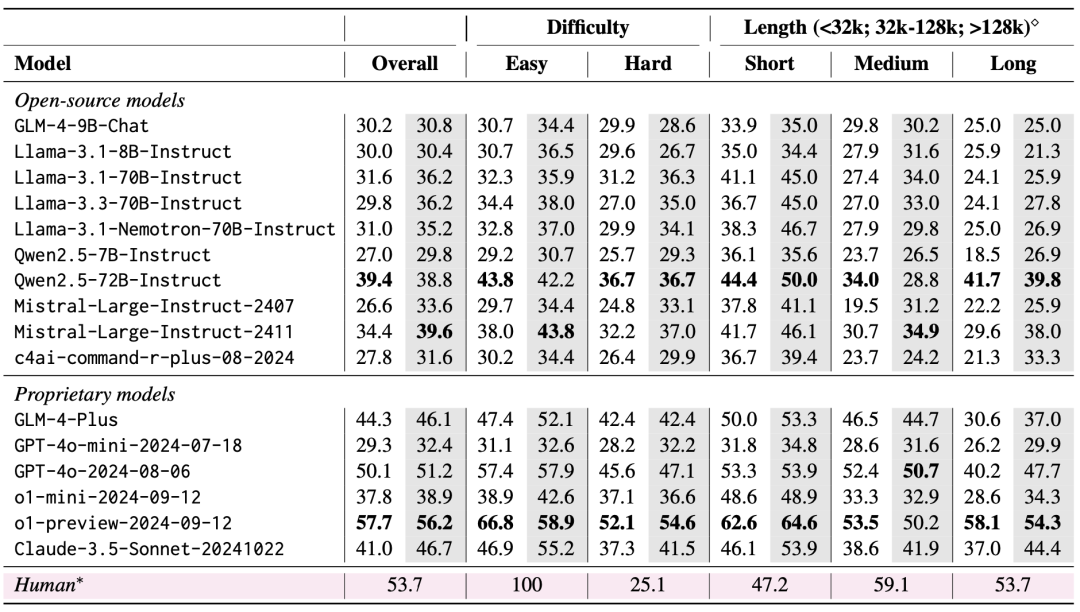
Les résultats de l'évaluation montrent que LongBench v2 est un grand défi pour les LLM actuels, avec même le modèle le plus performant atteignant une précision de seulement 50,1% avec une réponse directe, tandis que le modèle o1-preview, qui introduit une chaîne d'inférence plus longue, atteint une précision de 57,7%, qui surpasse l'expert humain de 4%.
1. l'importance de la mise à l'échelle du temps de calcul de l'inférence
Une conclusion très importante des résultats de l'évaluation est que la performance des modèles sur LongBench v2 peut être améliorée de manière significative par la mise à l'échelle de l'inférence temporelle (Scaling Inference-Time Compute). Par exemple, le modèle o1-preview réalise des gains significatifs sur des tâches telles que le quiz multi-documents, l'apprentissage de textes longs et la compréhension de référentiels de code en intégrant plus d'étapes d'inférence par rapport à GPT-4o.
Cela suggère que LongBench v2 impose des exigences plus élevées aux capacités de raisonnement des modèles actuels et que l'augmentation du temps consacré à la réflexion et au raisonnement sur le raisonnement semble être une étape naturelle et essentielle pour relever les défis du raisonnement textuel sur de longues durées.
2) RAG + Expériences en contexte long

On constate que les deux modèles, Qwen2.5 et GLM-4-Plus, ne présentent pas d'amélioration significative des performances, voire une dégradation, lorsque le nombre de blocs récupérés dépasse un certain seuil (32k tokens, soit environ 64 blocs de 512 de long).
Cela suggère que le simple fait d'augmenter la quantité d'informations récupérées ne permet pas toujours d'améliorer les performances. En revanche, le GPT-4o est capable d'utiliser efficacement des contextes d'extraction plus longs avec une performance optimale de RAG Les performances sont atteintes pour une longueur de recherche de 128k.
En résumé, le RAG est d'une utilité limitée lorsqu'il est confronté à des tâches de Q&R textuelles longues qui nécessitent une compréhension et un raisonnement profonds, en particulier lorsque le nombre de blocs récupérés dépasse un certain seuil. Le modèle doit avoir des capacités de raisonnement plus fortes plutôt que de s'appuyer uniquement sur les informations extraites afin de traiter efficacement les problèmes difficiles de LongBench v2.
Cela implique également que les orientations futures de la recherche doivent se concentrer davantage sur la manière d'améliorer les capacités de compréhension et de raisonnement du modèle pour les textes longs, plutôt que de s'appuyer uniquement sur la recherche externe.
Nous espérons que LongBench v2 repoussera les limites de la compréhension des textes longs et des techniques de raisonnement. N'hésitez pas à lire notre article, à utiliser nos données et à en apprendre davantage !
Page d'accueil : https://longbench2.github.io
Thèse : https://arxiv.org/abs/2412.15204
Données et codes : https://github.com/THUDM/LongBench
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...