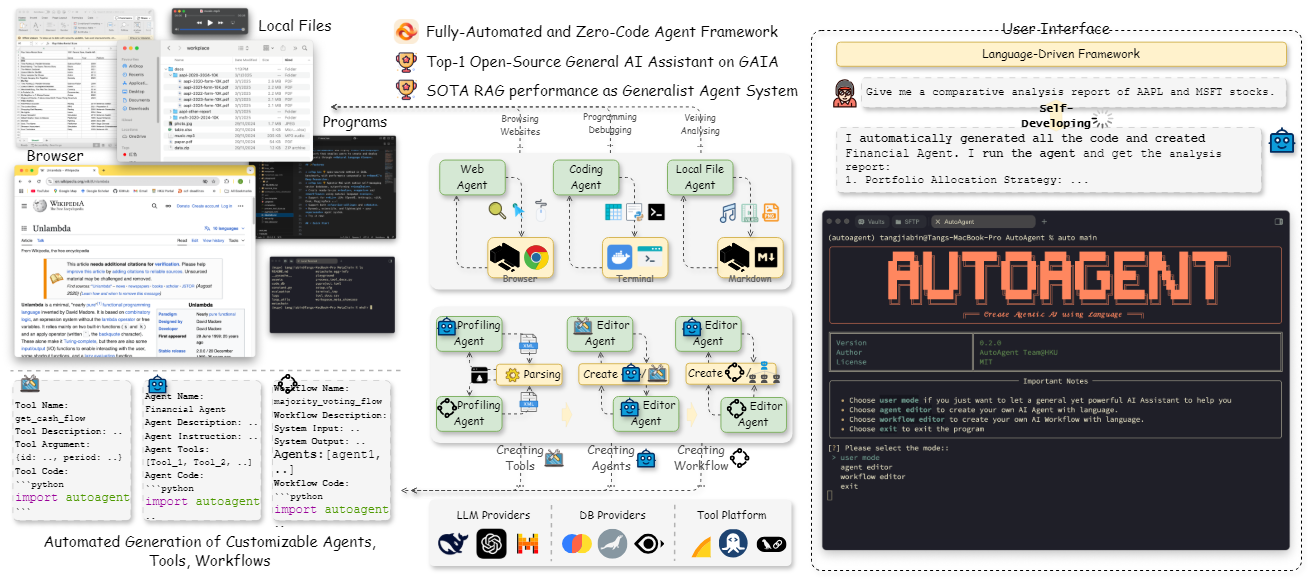
Long-VITA : un modèle de langage visuel prenant en charge les sorties contextuelles très longues
Introduction générale
Long-VITA est un macromodèle multimodal open source développé par l'équipe VITA-MLLM, qui se concentre sur les tâches visuelles et linguistiques traitant de contextes très longs. Il est capable d'analyser simultanément des images, des vidéos et du texte et prend en charge jusqu'à 1 million d'images, de vidéos et de textes. jeton Le modèle Long-VITA a été conçu pour des scénarios tels que la compréhension de vidéos, l'analyse syntaxique d'images à haute résolution et le raisonnement multimodal de l'intelligentsia. Comparé à d'autres modèles, Long-VITA est performant dans les tâches à contexte court, tout en offrant des avantages décisifs dans le traitement des séquences longues. Développé en collaboration avec le Tencent YouTuber Lab, l'université de Nanjing et l'université de Xiamen, le projet est entièrement formé sur des ensembles de données libres, prend en charge les plateformes NPU et GPU et vise à fournir à la communauté libre un outil puissant pour la recherche multimodale sur les longs contextes. Le code du modèle, la méthode d'entraînement et les poids ont été rendus publics, ce qui permet aux chercheurs et aux développeurs d'explorer les applications de pointe de l'IA multimodale.

Liste des fonctions
- Traitement contextuel extrêmement longLe système d'analyse de la scène : Il prend en charge les entrées d'images, de vidéos et de textes jusqu'à 1 million de jetons ou 4K images pour l'analyse de scènes complexes.
- compréhension multimodaleLes services de traitement des images, des vidéos et du texte permettent d'analyser simultanément plusieurs types de données.
- Raisonnement distribué efficace: Raisonnement efficace pour des entrées très longues grâce au parallélisme contextuel.
- Formation à l'utilisation d'ensembles de données en libre accèsLes modèles d'évaluation de la qualité de l'air : Utiliser 17 millions d'échantillons publics pour garantir la reproductibilité et la transparence des modèles.
- Support multiplateformeCompatible avec Ascend NPU et Nvidia GPU pour une adaptation flexible à différents environnements matériels.
- Optimisation du contexte court: Maintenir des performances de premier plan dans les tâches multimodales traditionnelles, en s'adaptant aux exigences des séquences longues et courtes.
- Modélisation du langage par masque de LogitsLe projet de recherche de l'Institut de recherche et de développement de l'Union européenne (IRU) : conception innovante d'une tête de modèle linguistique pour améliorer le raisonnement sur les longues séquences.
Utiliser l'aide
Long-VITA est un projet open source qui permet aux utilisateurs d'obtenir du code et des poids de modèle via un dépôt GitHub et de les déployer pour une utilisation locale ou sur un serveur. Voici un guide détaillé pour aider les utilisateurs à démarrer et à explorer ses puissantes fonctionnalités.
Processus d'installation
- entrepôt de clones
Ouvrez un terminal et entrez la commande suivante pour cloner le dépôt Long-VITA :git clone https://github.com/VITA-MLLM/Long-VITA.git cd Long-VITA
Cette opération permet de télécharger l'ensemble du code et de la documentation du projet.
- Créer un environnement virtuel
Utilisez Conda pour créer un environnement Python distinct et garantir l'isolation des dépendances :conda create -n long-vita python=3.10 -y conda activate long-vita - Installation des dépendances
Installez les paquets Python nécessaires à votre projet :pip install --upgrade pip pip install -r requirements.txtSi un raisonnement accéléré est nécessaire, Flash Attention peut être installé en plus :
pip install flash-attn --no-build-isolation - Télécharger le modèle de poids
Long-VITA est disponible en plusieurs versions (par exemple, 16K, 128K, 1M tokens) qui peuvent être téléchargées à partir de Hugging Face :- Long-VITA-16K. lien (sur un site web)
- Long-VITA-128K. lien (sur un site web)
- Long-VITA-1M. lien (sur un site web)
Après le téléchargement, placez le fichier weights dans le répertoire racine du projet ou dans le chemin spécifié.
- Configuration de l'environnement matériel
- GPU NvidiaCUDA : Assurez-vous que CUDA et cuDNN sont installés et que les variables d'environnement sont définies :
export CUDA_VISIBLE_DEVICES=0 - Ascend NPUConfiguration de l'environnement MindSpeed ou Megatron : Configurez votre environnement MindSpeed ou Megatron conformément à la documentation officielle.
- GPU NvidiaCUDA : Assurez-vous que CUDA et cuDNN sont installés et que les variables d'environnement sont définies :
Utilisation
Long-VITA prend en charge deux modes de fonctionnement principaux, l'inférence et l'évaluation, et les étapes suivantes sont décrites.
raisonnement en cours d'exécution
- Préparation de la saisie des données
- imagerie: Placez un fichier image (par ex.
.jpgpeut-être.png(informatique) mettre (dans)assetDossier. - vidéoPrise en charge des formats vidéo les plus courants (par ex.
.mp4), placé dans le chemin spécifié. - copies: Rédiger des questions ou des instructions, enregistrer en tant que
.txtou le saisir directement sur la ligne de commande.
- imagerie: Placez un fichier image (par ex.
- Exécuter des commandes de raisonnement
Pour illustrer la compréhension des images, exécutez la commande suivante :CUDA_VISIBLE_DEVICES=0 python video_audio_demo.py \ --model_path [模型权重路径] \ --image_path asset/sample_image.jpg \ --model_type qwen2p5_instruct \ --conv_mode qwen2p5_instruct \ --question "描述这张图片的内容。"Pour l'entrée vidéo, ajouter
--video_pathParamètres :--video_path asset/sample_video.mp4 - Voir la sortie
Le modèle produira des résultats au point final, tels que des descriptions d'images ou des contenus d'analyse vidéo.
Évaluation des performances
- Préparation des ensembles de données d'évaluation
Téléchargez l'ensemble de données de référence (par exemple Video-MME) et organisez la structure des fichiers comme vous le souhaitez. - Exécuter le script d'évaluation
Évaluer à l'aide du script fourni :bash script/evaluate.sh [模型路径] [数据集路径]
Fonction en vedette Fonctionnement
Traitement contextuel extrêmement long
- procédure:
- Sélectionnez le modèle Long-VITA-1M pour vous assurer que le nombre total de jetons des données d'entrée (par exemple, une longue vidéo ou plusieurs images HD) ne dépasse pas 1 million.
- utiliser
--max_seq_len 1048576définit la longueur maximale de la séquence. - Exécutez l'inférence et observez comment le modèle gère les tâches à séquence longue (par exemple, la génération de résumés vidéo).
- exemple typiqueLe modèle permet d'entrer une vidéo d'une heure, de poser la question "Résumez l'intrigue principale de la vidéo" et d'obtenir un résumé concis.
compréhension multimodale
- procédure:
- Préparer des entrées multimodales telles que image + texte ou vidéo + question.
- Spécifier les deux sur la ligne de commande
--image_pathrépondre en chantant--questionComme :--image_path asset/sample_image.jpg --question "图片中的人物是谁?" - Le modèle combinera des informations visuelles et textuelles pour générer des réponses.
- exemple typiqueLe modèle : : Entrez la photo d'une célébrité et la question "Qu'est-ce qu'il fait ?". Le modèle décrira l'action sur la photo.
inférence distribuée
- procédure:
- Pour configurer un environnement multi-GPU, modifiez le paramètre
CUDA_VISIBLE_DEVICES=0,1,2,3. - Exécuter avec l'option parallèle contextuelle :
python -m torch.distributed.launch --nproc_per_node=4 video_audio_demo.py [参数] - Le modèle attribue automatiquement les tâches à plusieurs appareils afin d'accélérer le traitement.
- Pour configurer un environnement multi-GPU, modifiez le paramètre
- exemple typique: : Le raisonnement distribué peut réduire le temps nécessaire de plusieurs heures à quelques minutes lorsqu'il s'agit de traiter de très longues vidéos.
mise en garde
- Veillez à ce que votre matériel dispose de suffisamment de mémoire. Une entrée de 1 million de jetons peut nécessiter plus de 32 Go de mémoire vidéo.
- Les données d'entrée doivent être prétraitées (par exemple, extraction d'images vidéo) pour répondre aux exigences du modèle.
- Vérifiez votre connexion internet, vous avez besoin d'une connexion internet stable et à haut débit pour télécharger des poids.
Avec ces étapes, les utilisateurs peuvent facilement déployer Long-VITA et expérimenter son contexte ultra-long et ses capacités de compréhension multimodale pour la recherche, le développement ou le test d'applications d'IA multimodales.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...