
Chunking tardif x Milvus : comment améliorer la précision du RAG

01.contextes
Dans le développement d'une application RAG, la première étape consiste à fragmenter le document. Une fragmentation efficace du document peut effectivement améliorer la précision du contenu de rappel ultérieur. La méthode de découpage efficace est un sujet de discussion brûlant. Il existe des méthodes telles que le découpage à taille fixe, le découpage à taille aléatoire, le rééchantillonnage par fenêtre glissante, le découpage récursif, le découpage sémantique basé sur le contenu et d'autres méthodes. La méthode Late Chunking proposée par Jina AI aborde le problème du découpage sous un autre angle.
02.Qu'est-ce que le découpage tardif ?
Le découpage traditionnel peut perdre les dépendances contextuelles à longue distance dans les documents lorsqu'il s'agit de longs documents, ce qui constitue un écueil majeur pour la recherche et la compréhension d'informations. En d'autres termes, lorsque les informations clés sont dispersées dans plusieurs blocs de texte, le fragment de texte découpé hors contexte est susceptible de perdre sa signification originale, ce qui se traduit par un rappel ultérieur de moindre qualité.
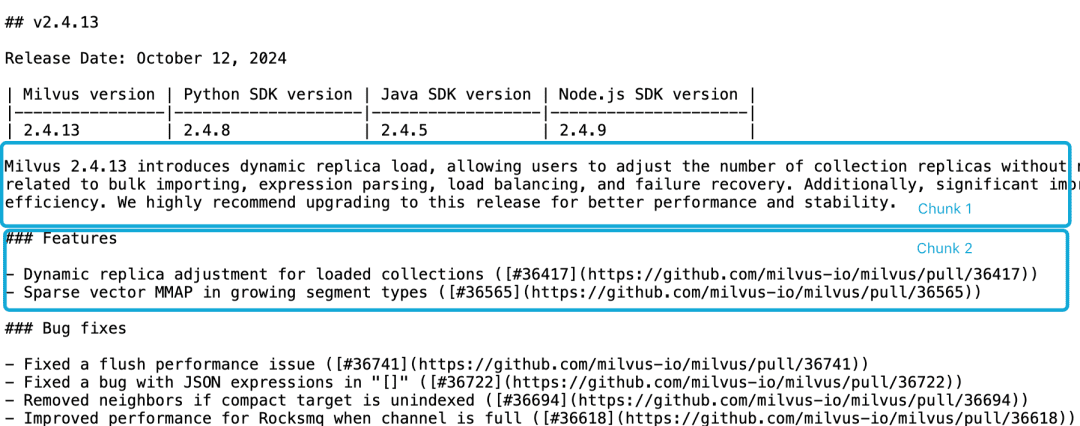
Prenons l'exemple de la note de version 2.4.13 de Milvus, si elle est divisée en deux blocs de documents comme suit, et si nous voulons interroger le documentMilvus 2.4.13有哪些新功能?À ce stade, il est difficile pour le modèle d'incorporation de relier correctement ces références aux entités, ce qui se traduit par un incorporation de mauvaise qualité.
LLM a des difficultés à résoudre un tel problème de corrélation parce que la description fonctionnelle ne se trouve pas dans le même bloc que les informations sur la version et qu'il n'y a pas de document contextuel plus important. Bien qu'il existe un certain nombre d'heuristiques qui tentent d'atténuer ce problème, comme le rééchantillonnage de la fenêtre coulissante, le chevauchement des longueurs de la fenêtre contextuelle et l'analyse de plusieurs documents, comme toutes les heuristiques, ces méthodes sont aléatoires ; elles peuvent fonctionner dans certains cas, mais il n'y a pas de garanties théoriques.
Le découpage traditionnel utilise une stratégie de pré-découpage, c'est-à-dire qu'il commence par le découpage et passe ensuite par le modèle d'intégration. Le texte est d'abord découpé en fonction de paramètres tels que la phrase, le paragraphe ou la longueur maximale prédéfinie. Le modèle d'intégration traite ensuite ces morceaux un par un, à l'aide de méthodes telles que la mise en commun des moyennes, l'analyse de l'information et l'analyse de l'information. jeton Le découpage tardif consiste à passer d'abord par le modèle d'intégration et à le découper ensuite (c'est ce que signifie le terme "tardif"). Le découpage tardif, quant à lui, consiste à passer par le modèle d'intégration avant le découpage (c'est là que le terme tardif prend tout son sens, d'abord la vectorisation et ensuite le découpage), nous prenons d'abord le modèle d'intégration, puis nous le découpons. transformateur La couche est appliquée à l'ensemble du texte, générant une séquence de représentations vectorielles pour chaque jeton qui contient de riches informations contextuelles. Ensuite, ces séquences de vecteurs sont regroupées de façon homogène pour obtenir le bloc d'intégration final qui prend en compte l'ensemble du contexte du texte.
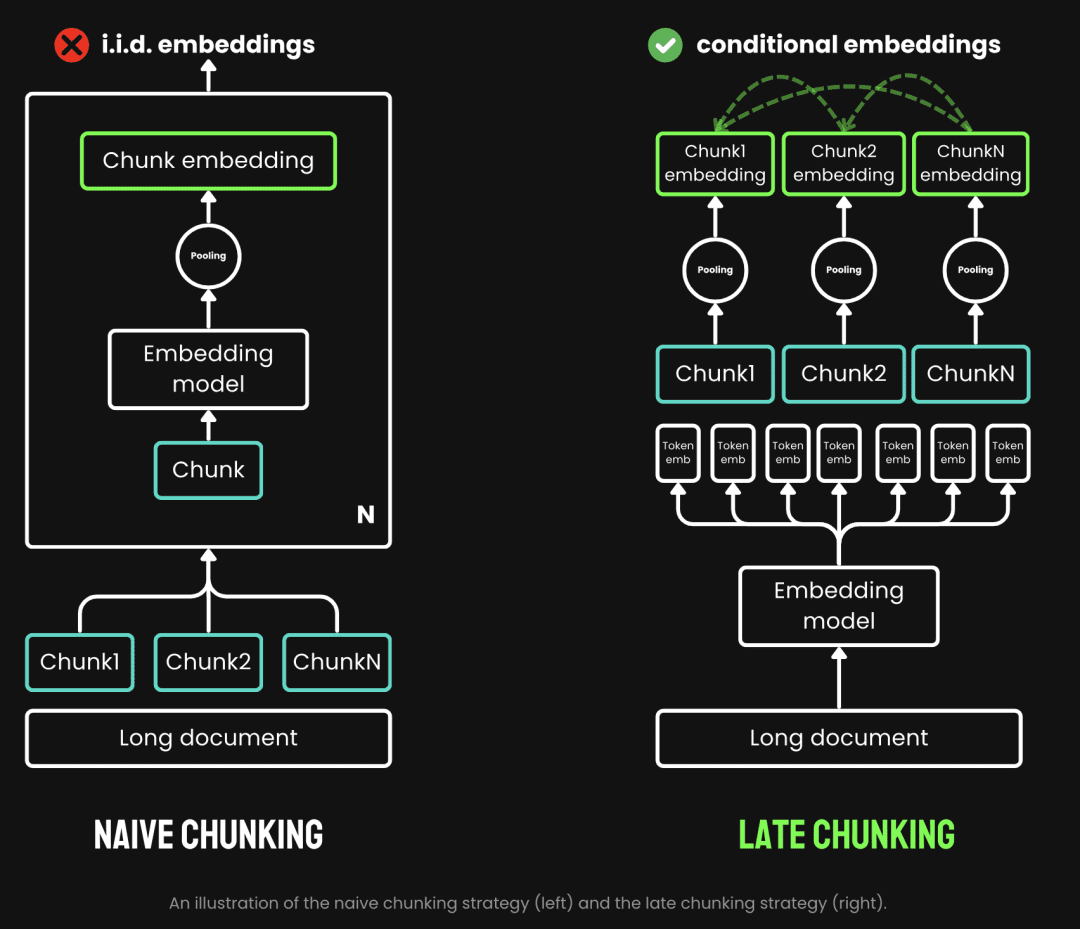
(Source de l'image : https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
Le découpage tardif génère un encapsulage par bloc où chaque bloc encode davantage d'informations contextuelles, ce qui améliore la qualité et la précision de l'encodage. Nous pouvons soutenir les modèles d'intégration de contextes longs en prenant en charge les contextes longs tels que jina-embeddings-v2-base-enIl peut traiter jusqu'à 8192 tokens de texte (l'équivalent de 10 pages de papier A4), ce qui répond essentiellement aux exigences contextuelles de la plupart des textes longs.
En résumé, nous pouvons constater les avantages du découpage tardif dans les applications RAG :
- Précision accrue : en préservant les informations contextuelles, le découpage tardif renvoie un contenu plus pertinent pour les requêtes que le découpage simple.
- Appels LLM efficaces : le découpage tardif réduit la quantité de texte transmise au LLM car il renvoie des morceaux moins nombreux et plus pertinents.
03.Test du découpage tardif
3.1 Mise en œuvre de la base de découpage tardif
Fonction sentence_chunker pour le document original vers le découpage en paragraphes, renvoie le contenu des morceaux et les informations de marquage des morceaux span_annotations (c'est-à-dire le début et la fin du marquage du morceau).
def sentence_chunker(document, batch_size=10000):
nlp = spacy.blank("en")
nlp.add_pipe("sentencizer", config={"punct_chars": None})
doc = nlp(document)
docs = []
for i in range(0, len(document), batch_size):
batch = document[i : i + batch_size]
docs.append(nlp(batch))
doc = Doc.from_docs(docs)
span_annotations = []
chunks = []
for i, sent in enumerate(doc.sents):
span_annotations.append((sent.start, sent.end))
chunks.append(sent.text)
return chunks, span_annotations
La fonction document_to_token_embeddings transmet le modèle jinaai/jina-embeddings-v2-base-en ainsi que le tokeniser, qui renvoie l'Embedding de l'ensemble du document.
def document_to_token_embeddings(model, tokenizer, document, batch_size=4096): tokenized_document = tokenizer(document, return_tensors="pt") tokens = tokenized_document.tokens() outputs = [] for i in range(0, len(tokens), batch_size): start = i end = min(i + batch_size, len(tokens)) batch_inputs = {k: v[:, start:end] for k, v in tokenized_document.items()} with torch.no_grad(): model_output = model(**batch_inputs) outputs.append(model_output.last_hidden_state) model_output = torch.cat(outputs, dim=1) return model_output
La fonction late_chunking regroupe l'Embedding de l'ensemble du document ainsi que les informations de marquage span_annotations des morceaux d'origine.
def late_chunking(token_embeddings, span_annotation, max_length=None): outputs = [] for embeddings, annotations in zip(token_embeddings, span_annotation): if ( max_length is not None ): annotations = [ (start, min(end, max_length - 1)) for (start, end) in annotations if start < (max_length - 1) ] pooled_embeddings = [] for start, end in annotations: if (end - start) >= 1: pooled_embeddings.append( embeddings[start:end].sum(dim=0) / (end - start) ) pooled_embeddings = [ embedding.detach().cpu().numpy() for embedding in pooled_embeddings ] outputs.append(pooled_embeddings) return outputs
Si un modèle est utiliséjinaai/jina-embeddings-v2-base-enEffectuer un découpage tardif
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
# First chunk the text as normal, to obtain the beginning and end points of the chunks.
chunks, span_annotations = sentence_chunker(document)
# Then embed the full document.
token_embeddings = document_to_token_embeddings(model, tokenizer, document)
# Then perform the late chunking
chunk_embeddings = late_chunking(token_embeddings, [span_annotations])[0]
3.2 Comparaison avec les méthodes d'intégration traditionnelles
Prenons l'exemple de la note de version 2.4.13 de milvus.
Milvus 2.4.13 introduit la charge dynamique des répliques, ce qui permet aux utilisateurs d'ajuster le nombre de répliques de la collection sans avoir à libérer et à recharger la collection. collection.
Cette version corrige également plusieurs bogues critiques liés à l'importation en masse, à l'analyse des expressions, à l'équilibrage de la charge et à la reprise sur panne.
En outre, des améliorations significatives ont été apportées à l'utilisation des ressources MMAP et aux performances d'importation, améliorant ainsi l'efficacité globale du système.
Nous recommandons vivement de passer à cette version pour améliorer les performances et la stabilité.
L'incorporation traditionnelle, c'est-à-dire le découpage suivi de l'incorporation, et l'incorporation tardive, c'est-à-dire l'incorporation suivie du découpage, sont effectuées respectivement. Ensuite, les milvus 2.4.13 Comparez les résultats avec ces deux approches d'intégration respectivement
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
milvus_embedding = model.encode('milvus 2.4.13')
for chunk, late_chunking_embedding, traditional_embedding in zip(chunks, chunk_embeddings, embeddings_traditional_chunking):
print(f'similarity_late_chunking("milvus 2.4.13", "{chunk}")')
print('late_chunking: ', cos_sim(milvus_embedding, late_chunking_embedding))
print(f'similarity_traditional("milvus 2.4.13", "{chunk}")')
print('traditional_chunking: ', cos_sim(milvus_embedding, traditional_embeddings))
D'après les résultats, les mots milvus 2.4.13 La similarité entre les résultats du découpage tardif et les documents découpés est plus élevée que celle de l'incorporation traditionnelle, car le découpage tardif effectue d'abord l'incorporation pour l'ensemble du passage du texte, de sorte que ce dernier obtient la même valeur que celle de l'incorporation traditionnelle. milvus 2.4.13 qui, à son tour, améliore de manière significative la similarité des comparaisons de textes ultérieures.
similarity_late_chunking("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
late_chunking: 0.8785206
similarity_traditional("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
traditional_chunking: 0.8354263
similarity_late_chunking("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
late_chunking: 0.84828955
similarity_traditional("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
traditional_chunking: 0.7222632
similarity_late_chunking("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
late_chunking: 0.84942204
similarity_traditional("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
traditional_chunking: 0.6907381
similarity_late_chunking("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
late_chunking: 0.85431844
similarity_traditional("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
traditional_chunking: 0.71859795
3.3 Test du découpage tardif dans Milvus
Importation des données de découpage tardif dans Milvus
batch_data=[]
for i in range(len(chunks)):
data = {
"content": chunks[i],
"embedding": chunk_embeddings[i].tolist(),
}
batch_data.append(data)
res = client.insert(
collection_name=collection,
data=batch_data,
)
Test des requêtes
Nous définissons la méthode d'interrogation par similarité cosinusoïdale, ainsi que l'utilisation de la méthode d'interrogation native Milvus pour le découpage tardif, respectivement.
def late_chunking_query_by_milvus(query, top_k = 3):
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
res = client.search(
collection_name=collection,
data=[query_vector.tolist()],
limit=top_k,
output_fields=["id", "content"],
)
return [item.get("entity").get("content") for items in res for item in items]
def late_chunking_query_by_cosine_sim(query, k = 3):
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
results = np.empty(len(chunk_embeddings))
for i, (chunk, embedding) in enumerate(zip(chunks, chunk_embeddings)):
results[i] = cos_sim(query_vector, embedding)
results_order = results.argsort()[::-1]
return np.array(chunks)[results_order].tolist()[:k]
D'après les résultats, les deux méthodes renvoient le même contenu, ce qui indique que les résultats de la requête concernant le découpage tardif dans Milvus sont exacts.
> late_chunking_query_by_milvus("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
> late_chunking_query_by_cosine_sim("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
04.résumés
Nous présentons le contexte, les concepts de base et la mise en œuvre sous-jacente du découpage tardif tel qu'il est apparu, puis nous constatons que le découpage tardif fonctionne bien en le testant sur Mivlus. Dans l'ensemble, la combinaison de la précision, de l'efficacité et de la facilité de mise en œuvre fait du découpage tardif une approche efficace pour les applications RAG.
Référence.
- https://stackoverflow.blog/2024/06/06/breaking-up-is-hard-to-do-chunking-in-rag-applications
- https://jina.ai/news/late-chunking-in-long-context-embedding-models/
- https://jina.ai/news/what-late-chunking-really-is-and-what-its-not-part-ii/
Exemple de code :
Lien : https://pan.baidu.com/s/1cYNfZTTXd7RwjnjPFylReg?pwd=1234 Code d'extraction : 1234 Le code est exécuté sur la machine aws g4dn.xlarge.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...