Guide rapide des mots clés couramment utilisés par les chefs de produit
Introduction Bienvenue dans le manuel de référence rapide des mots-clés du chef de produit. Ce manuel est un recueil de conseils et d'astuces que les chefs de produit peuvent être amenés à utiliser dans leur travail quotidien. Le contenu couvre l'amélioration des compétences de base, l'étude de cas, l'application du cadre de gestion, la sélection des outils, le lancement du produit, le traitement du retour d'information des utilisateurs, l'analyse des données...

























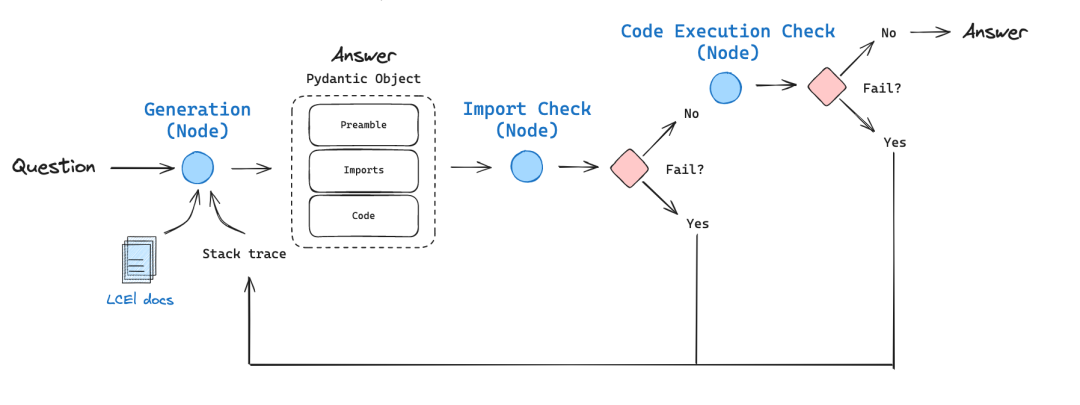

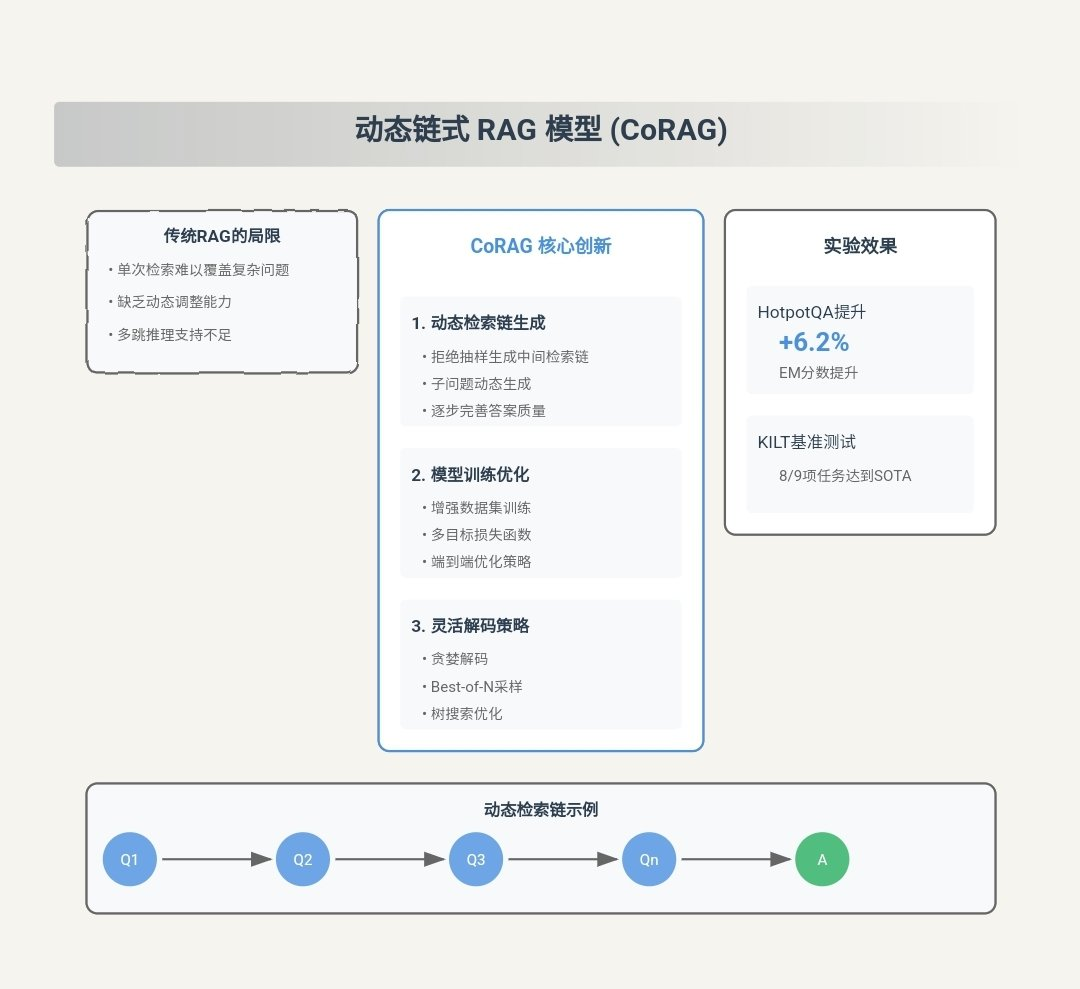
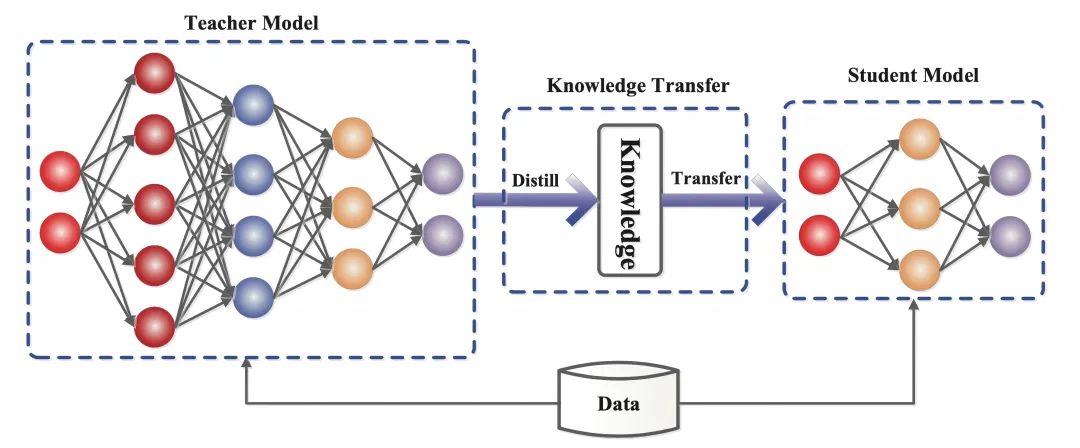

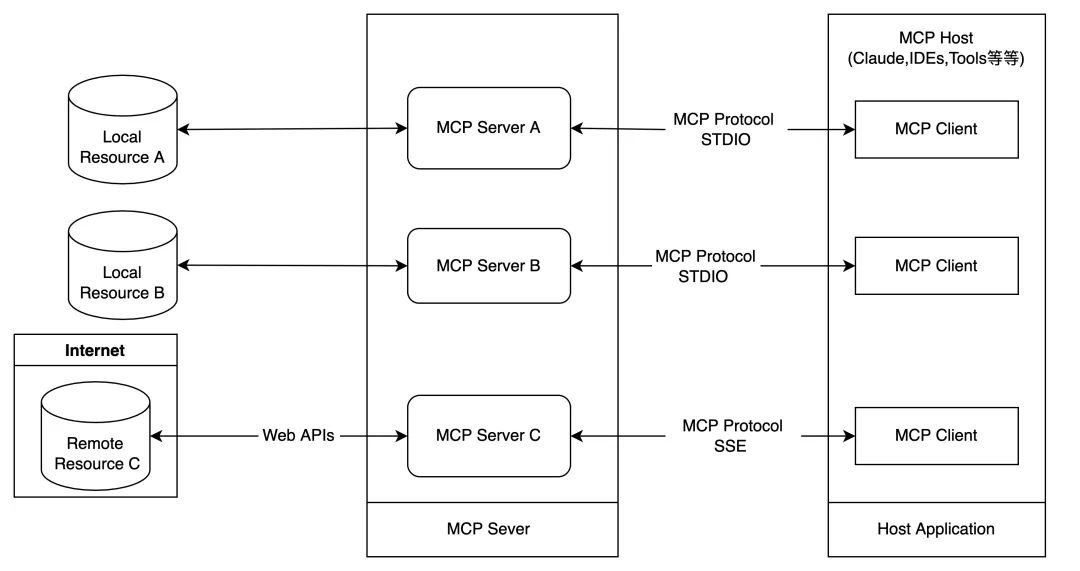

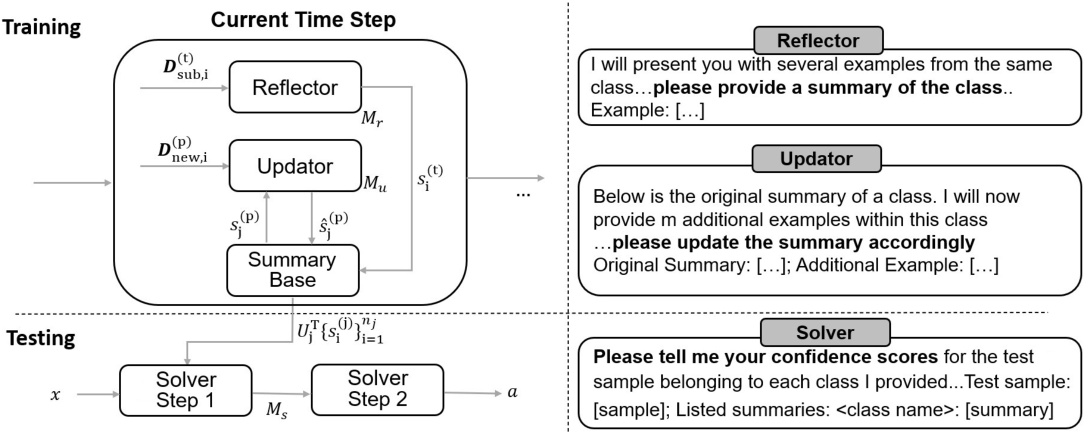
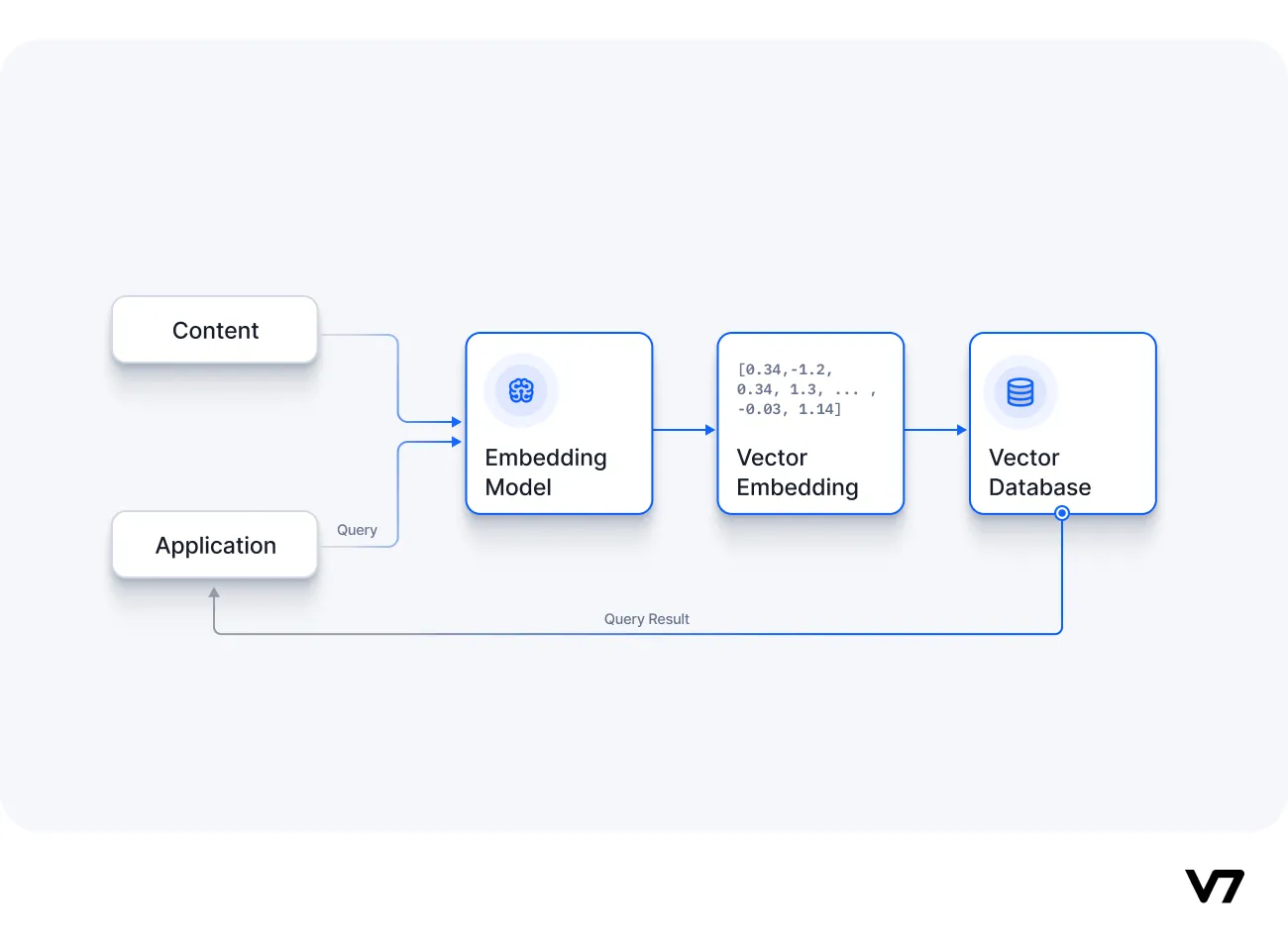
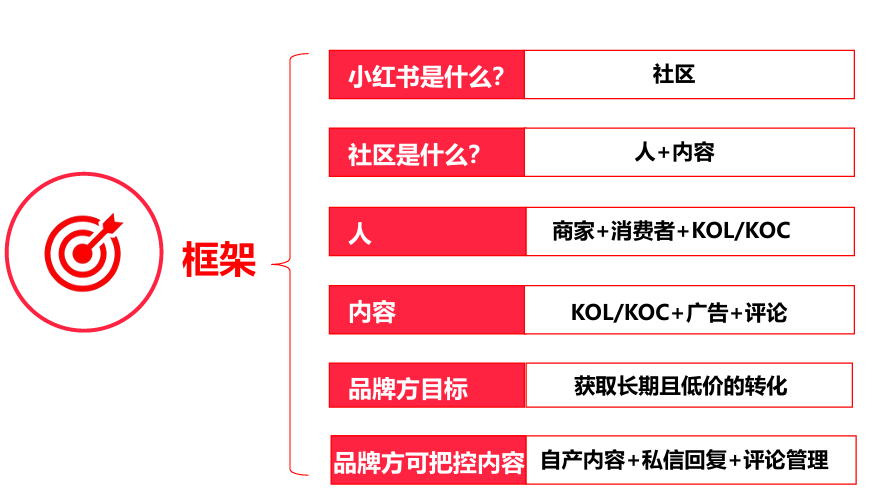
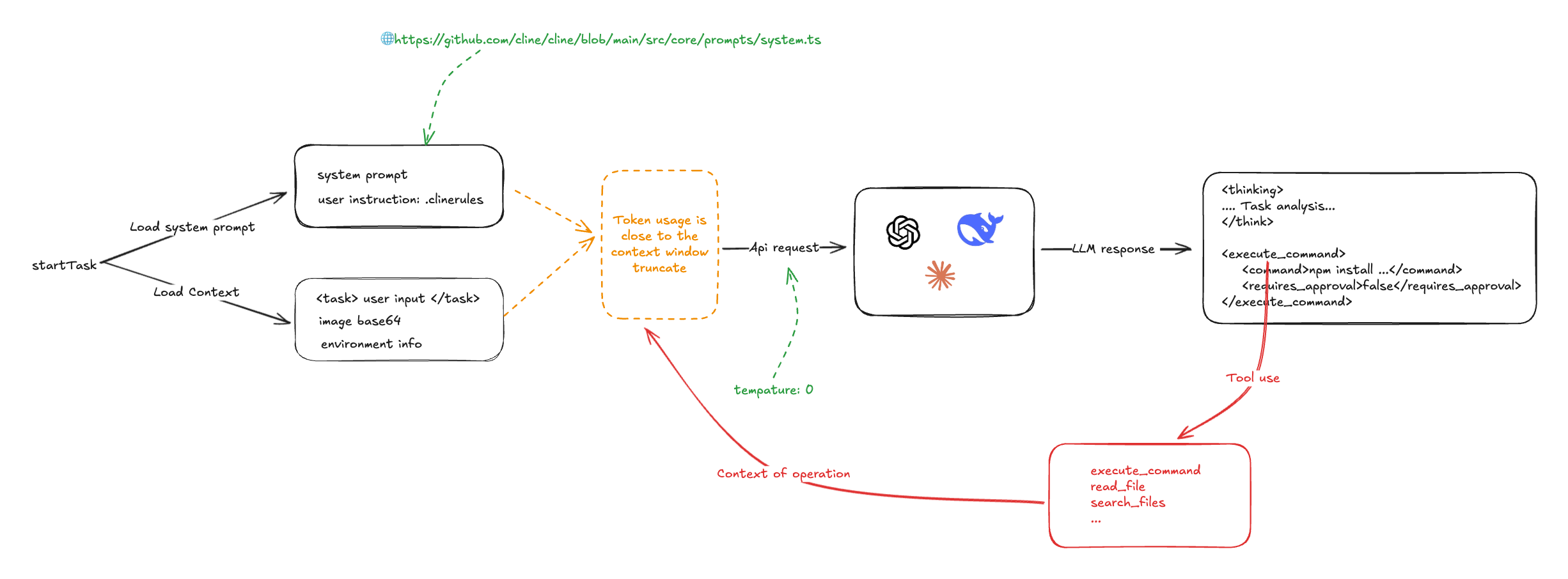

![[转]从零拆解一款火爆的浏览器自动化智能体,4步学会设计自主决策Agent](https://aisharenet.com/wp-content/uploads/2025/01/e0a98a1365d61a3.png)