
Le mini-modèle Open Source 1,6B "Little Fox", plus performant que les modèles similaires Qwen et Gemma

depuis (un temps) Chatgpt Depuis sa création, le nombre de paramètres LLM (Large Language Models) semble être une course vers le bas pour chaque entreprise. Le nombre de paramètres du GPT-1 était de 117 millions (117M), et sa quatrième génération, le GPT-4, a été actualisé à 1,8 trillion (1800B).
À l'instar d'autres modèles LLM tels que Bloom (176 milliards, 176B) et Chinchilla (70 milliards, 70B), le nombre de paramètres monte en flèche. Le nombre de paramètres influe directement sur les performances et les capacités du modèle, un plus grand nombre de paramètres signifiant que le modèle est capable de traiter des modèles de langage plus complexes, de comprendre des informations contextuelles plus riches et de faire preuve de niveaux d'intelligence plus élevés dans un large éventail de tâches.
Cependant, ces paramètres considérables affectent aussi directement le coût de la formation et l'environnement de développement des MLD, et limitent l'exploration des MLD par la plupart des entreprises de recherche générale, ce qui fait que les grands modèles linguistiques deviennent progressivement une course à l'armement entre les grandes entreprises.
Récemment, l'entreprise d'IA émergente TensorOpera a publié l'outil d'évaluation de la qualité de l'IA.Modèles Open Source de petites langues FOXLe projet a été lancé en décembre 2009, prouvant à l'industrie que les petits modèles linguistiques (SLM) peuvent également faire preuve d'une force suffisante dans le domaine de l'intelligentsia.

FOX est unPetits modèles linguistiques conçus pour l'informatique en nuage et l'informatique de pointe. Contrairement aux grands modèles linguistiques comportant des dizaines de milliards de paramètres, FOX Seulement 1,6 milliard de paramètresC'est un excellent moyen de tirer le meilleur parti de votre ordinateur, mais c'est aussi un excellent moyen de montrer des performances étonnantes sur plusieurs tâches.
Titre de la thèse :
RAPPORT TECHNIQUE FOX-1
Lien vers l'article :
https://arxiv.org/abs/2411.05281

Qui est TensorOpera ?
TensorOpera est une entreprise innovante d'intelligence artificielle basée dans la Silicon Valley, en Californie. Elle a déjà développé l'écosystème d'IA générative TensorOpera® AI Platform et la plateforme fédérale d'apprentissage et d'analyse TensorOpera® FedML. Le nom de l'entreprise, TensorOpera, est une combinaison de technologie et d'art, symbolisant le développement éventuel par GenAI de systèmes d'IA composites multimodaux et multimodèles.

Jared Kaplan, cofondateur et PDG de TensorOpera, a déclaré : "Le modèle FOX a été conçu à l'origine pour réduire considérablement les besoins en ressources informatiques tout en maintenant des performances élevées. Cela permet non seulement de rendre la technologie de l'IA plus accessible, mais aussi de réduire la barrière à l'utilisation pour les entreprises".
Comment fonctionne le modèle Fox ?
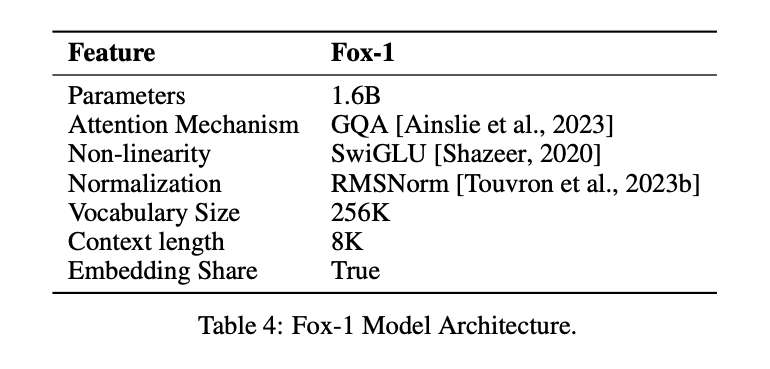
Afin d'obtenir le même effet que le LLM avec un plus petit nombre de paramètres, le modèle Fox-1Décodeur uniquementet introduit plusieurs améliorations et remaniements pour de meilleures performances. Il s'agit notamment de
① couche réseauDans la conception des architectures de modèles, les réseaux neuronaux plus larges et moins profonds ont de meilleures capacités de mémoire, tandis que les réseaux plus profonds et moins épais ont de meilleures capacités d'inférence. Suivant ce principe, Fox-1 utilise une architecture plus profonde que la plupart des SLM modernes. Plus précisément, Fox-1 se compose de 32 couches auto-attentives, soit 781 TP3T de plus que Gemma-2B (18 couches) et 331 TP3T de plus que StableLM-2-1.6B (24 couches) et Qwen1.5-1.8B (24 couches).
② Intégration partagéeFox-1 utilise 2 048 dimensions cachées pour construire un total de 256 000 vocabulaires avec environ 500 millions de paramètres. Les modèles plus importants utilisent généralement des couches d'intégration séparées pour la couche d'entrée (vocabulaire vers expressions intégrées) et la couche de sortie (expressions intégrées vers vocabulaire). Pour Fox-1, la couche d'intégration nécessite à elle seule 1 milliard de paramètres. Pour réduire le nombre total de paramètres, le partage des couches d'intégration d'entrée et de sortie maximise l'utilisation des poids.
(iii) pré-normalisationFox-1 utilise RMSNorm pour normaliser les entrées de chaque couche de transformation ; RMSNorm est le choix préféré pour la prénormalisation dans les modèles linguistiques modernes à grande échelle, et il est plus efficace que LayerNorm.
④ Codage de position rotative (RoPE)Fox-1 accepte par défaut des mots d'entrée d'une longueur maximale de 8K, et pour améliorer les performances dans des fenêtres contextuelles plus longues, Fox-1 utilise un encodage positionnel rotatif, où θ est fixé à 10 000 pour l'encodage. jeton Dépendance positionnelle relative entre
⑤ L'attention portée aux requêtes de groupe (GQA)Fox-1 est équipé de 4 têtes clé-valeur et de 16 têtes d'attention afin d'augmenter la vitesse d'apprentissage et d'inférence et de réduire l'utilisation de la mémoire.
En plus de la modélisation des améliorations structurelles.FOX-1 améliore également la tokenisation et la formation..
la partie du discours (en grammaire chinoise)Fox-1 utilise le classificateur Gemma basé sur SentencePiece, qui fournit un vocabulaire de 256K. L'augmentation de la taille du vocabulaire présente au moins deux avantages principaux. Premièrement, la longueur de l'information cachée dans le contexte est augmentée car chaque jeton encode une information plus dense. Par exemple, un vocabulaire de taille 26 ne peut coder qu'un seul caractère dans [a-z], mais un vocabulaire de taille 262 peut coder deux lettres en même temps, ce qui permet de représenter des chaînes plus longues dans un jeton de longueur fixe. Deuxièmement, un vocabulaire plus étendu réduit la probabilité de mots ou de phrases inconnus, ce qui se traduit dans la pratique par de meilleures performances dans les tâches en aval. Le vocabulaire étendu utilisé par Fox-1 produit moins de jetons pour un corpus de texte donné, ce qui se traduit par de meilleures performances en matière d'inférence.
Fox-1Données de pré-entraînementLes données proviennent de Redpajama, SlimPajama, Dolma, Pile et Falcon, soit un total de 3 billions de données textuelles. Pour pallier l'inefficacité du pré-entraînement pour les longues séquences en raison de son mécanisme d'attention, Fox-1 introduit dans la phase de pré-entraînement une fonction d'attention.Une stratégie d'apprentissage du curriculum en trois phasesFox-1 est un pipeline de pré-entraînement de cours en trois phases, dans lequel la longueur des échantillons d'entraînement est progressivement augmentée de 2K à 8K pour garantir de longues capacités contextuelles à un faible coût. Afin d'être cohérent avec le pipeline de pré-entraînement en trois phases, Fox-1 réorganise les données brutes en trois ensembles différents, y compris les ensembles de données non supervisées et de réglage des instructions, ainsi que les données provenant de différents domaines tels que le code, le contenu Web, les documents mathématiques et scientifiques.
La formation Fox-1 peut être divisée en trois étapes.
- La première phase se compose d'environ 39% échantillons de données au total tout au long du processus de pré-entraînement, où l'ensemble de données de 1,05 trillion de jetons est divisé en échantillons d'une longueur de 2 000, avec une taille de lot de 2 M. Un échauffement linéaire de 2 000époch est utilisé dans cette phase.
- La deuxième phase comprend environ 591 échantillons TTP3T avec 1,58 trillion de jetons et augmente la longueur des morceaux de 2K à 4K et 8K. La longueur réelle des morceaux varie en fonction des différentes sources de données. Étant donné que la deuxième phase est la plus longue et qu'elle implique différentes sources provenant de différents ensembles de données, la taille du lot est également augmentée à 4M afin d'améliorer l'efficacité de la formation.
- Enfin, dans la troisième phase, le modèle Fox est entraîné à l'aide de 6,2 milliards de tokens (environ 0,02% du total) de données de haute qualité, jetant les bases de différentes capacités de tâches en aval, telles que le suivi des ordres, la conversation à bâtons rompus, les questions-réponses spécifiques à un domaine, et ainsi de suite.
Quels ont été les résultats de Fox-1 ?
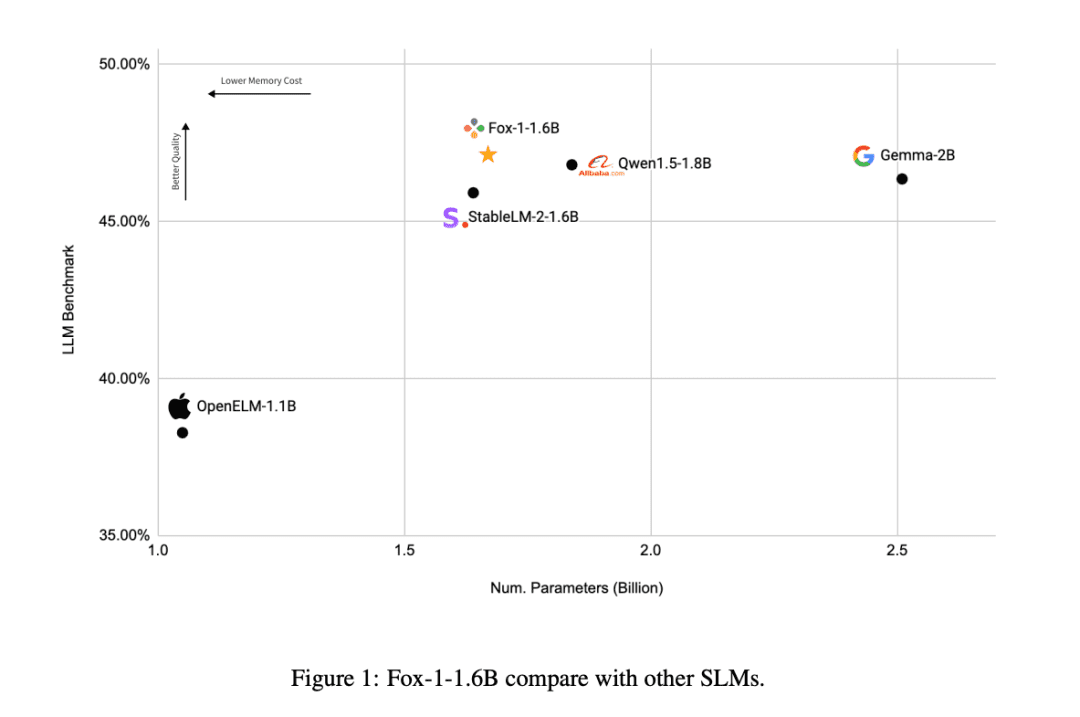
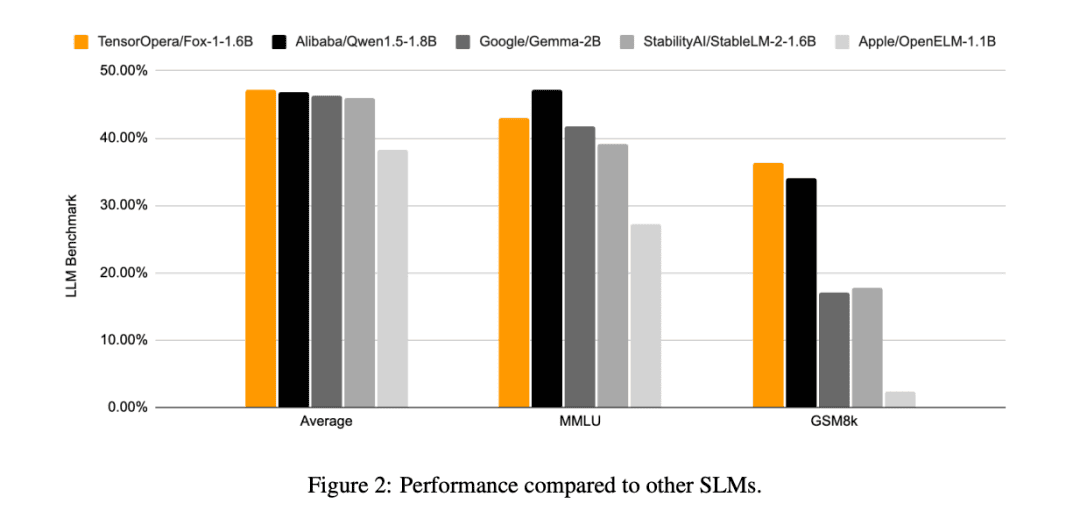
Par rapport aux autres modèles SLM (Gemma-2B, Qwen1.5-1.8B, StableLM-2-1.6B et OpenELM1.1B), FOX-1 réussit mieux dans ARC Challenge (25 coups), HellaSwag (10 coups), TruthfulQA (0 coup), MMLU (5 coups), Winogrande (5 coups), GSM8k (5 coups), GSM8k (5 coups), GSM8k (5 coups) et GSM8k (5 coups). MMLU (5-coups), Winogrande (5-coups), GSM8k (5-coups)Les scores moyens du benchmark pour les six tâches étaient les plus élevés et étaient significativement meilleurs sur le GSM8k.
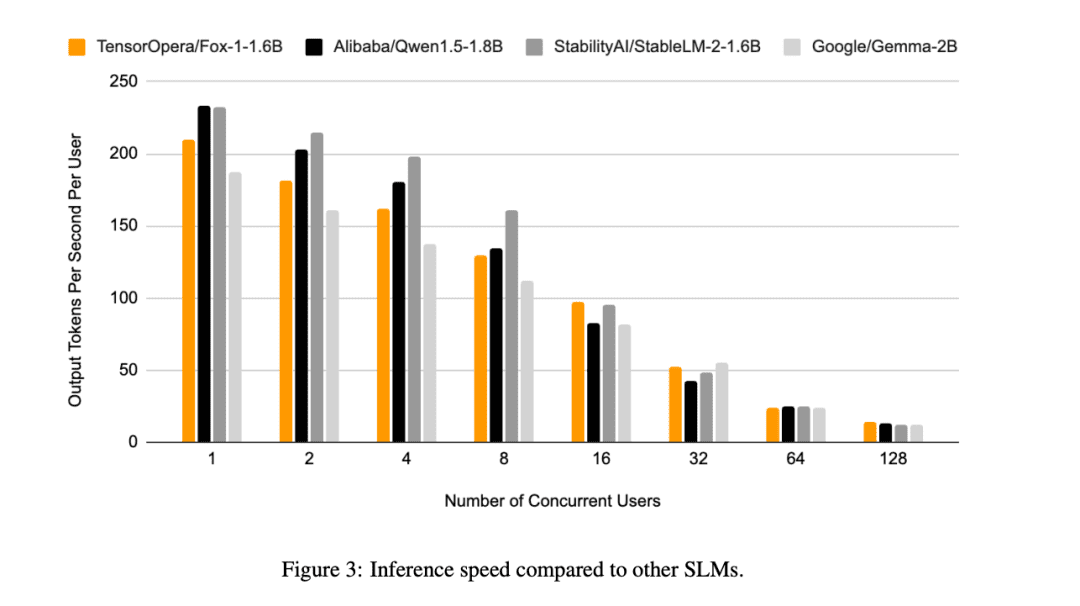
En outre, TensorOpera a évalué Fox-1, Qwen1.5-1.8B et Gemma-2B à l'aide de l'outil vLLM Efficacité de l'inférence de bout en bout avec la plateforme de services TensorOpera sur un seul NVIDIA H100.
Fox-1 atteint un débit de plus de 200 jetons par seconde, surpassant Gemma-2B et égalant Qwen1.5-1.8B dans le même environnement de déploiement. Avec la précision BF16, Fox-1 ne nécessite que 3703 Mo de mémoire GPU, alors que Qwen1.5-1.8B, StableLM-2-1.6B et Gemma-2B requièrent respectivement 4739 Mo, 3852 Mo et 5379 Mo.
De petits paramètres, mais toujours compétitifs
Alors que toutes les entreprises d'IA sont aujourd'hui en concurrence dans le domaine des grands modèles de langage, TensorOpera a adopté une approche différente en perçant dans le domaine du SLM, obtenant des résultats similaires à ceux de LLM avec seulement 1,6 milliard d'euros, et obtenant de bons résultats dans divers tests de référence.
Même avec des ressources de données limitées, TensorOpera peut pré-entraîner des modèles de langage avec des performances compétitives, offrant ainsi une nouvelle façon de penser que d'autres entreprises d'IA pourront développer.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...