Affiner le modèle DeepSeek R1 pour permettre des questions-réponses médicales de précision : libérer le potentiel de l'IA open source
DeepSeek introduit une série de modèles d'inférence avancés pour remettre en question la position de l'OpenAI dans l'industrie, etEntièrement gratuit, aucune restriction d'utilisationLe programme est conçu pour bénéficier à tous les utilisateurs.
Dans cet article, nous décrivons comment affiner le modèle DeepSeek-R1-Distill-Llama-8B en utilisant le jeu de données Medical Mind Chain de Hugging Face. Cette version allégée du modèle DeepSeek-R1-Distill-Llama-8B Profondeur de l'eau-R1 obtenu en affinant le modèle Llama 3 8B sur les données générées par DeepSeek-R1, présente une inférence supérieure similaire au modèle original.

Décryptage DeepSeek R1
DeepSeek-R1 et DeepSeek-R1-Zero sont plus performants que le modèle o1 d'OpenAI dans les tâches de mathématiques, de programmation et de raisonnement logique.Il convient de mentionner que les modèles R1 et R1-Zero sont tous deux des modèles open source..
DeepSeek-R1-Zero
DeepSeek-R1-Zero est le premier modèle open-source formé exclusivement à l'aide de l'apprentissage par renforcement (RL) à grande échelle, par opposition aux modèles traditionnels qui utilisent le réglage fin supervisé (SFT) comme étape initiale. Cette approche innovante permet aux modèles d'explorer indépendamment le raisonnement CoT (Chain-of-Thought), ce qui leur permet de résoudre des problèmes complexes et d'optimiser le résultat de manière itérative. Toutefois, cette approche pose également certains problèmes, tels que la duplication possible des étapes de raisonnement, la réduction de la lisibilité et l'incohérence des styles de langage, ce qui affecte la clarté et l'utilité du modèle.
Profondeur de l'eau-R1
Le lancement de DeepSeek-R1 vise à combler les lacunes de DeepSeek-R1-Zero. En introduisant des données de départ à froid avant l'apprentissage par renforcement, DeepSeek-R1 pose des bases plus solides pour les tâches d'inférence et de non-inférence. Cette stratégie de formation en plusieurs étapes permet à DeepSeek-R1 d'atteindre un niveau de performance supérieur à celui d'OpenAI-o1 dans les domaines des mathématiques, de la programmation et de l'inférence, et d'améliorer de manière significative la lisibilité et la cohérence des résultats.
Modèle de distillation DeepSeek
DeepSeek a également introduit une famille de modèles de distillation. Ces modèles sont plus petits et plus efficaces tout en conservant d'excellentes performances d'inférence. Bien que la taille des paramètres varie de 1,5 à 70 milliards, tous ces modèles conservent de fortes capacités d'inférence. Parmi eux, DeepSeek-R1-Distill-Qwen-32B surpasse le modèle OpenAI-o1-mini dans plusieurs benchmarks. Les modèles à plus petite échelle héritent des schémas d'inférence des modèles plus grands, ce qui démontre pleinement l'efficacité de la technique de distillation.
-1")
Le réglage fin de DeepSeek R1 en action
1. configuration de l'environnement
Dans cet exercice de mise au point du modèle, Kaggle a été choisi comme IDE en nuage en raison des ressources GPU gratuites fournies par Kaggle. Deux GPU T4 ont été initialement choisis, mais un seul a été utilisé. Si les utilisateurs souhaitent effectuer l'affinage du modèle sur un ordinateur local, ils doivent disposer d'au moinsUne carte graphique RTX 3090 avec 16 Go de mémoire..
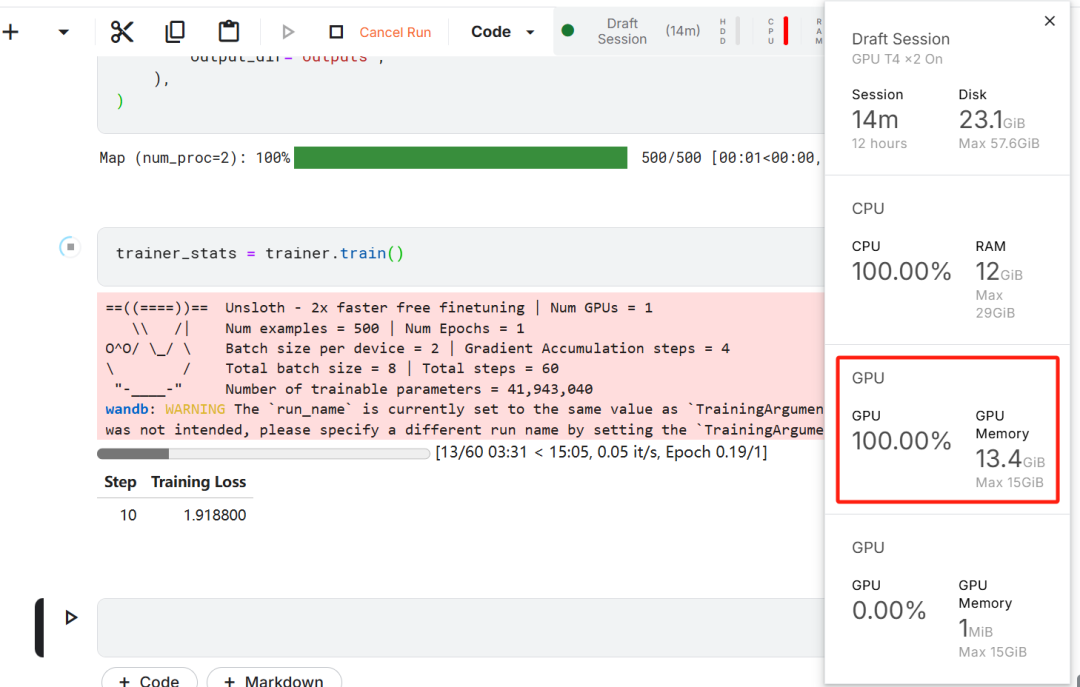
Tout d'abord, démarrez un nouveau carnet Kaggle avec le visage étreint de l'utilisateur. jeton répondre en chantant Poids & Le jeton Biases est ajouté comme clé.
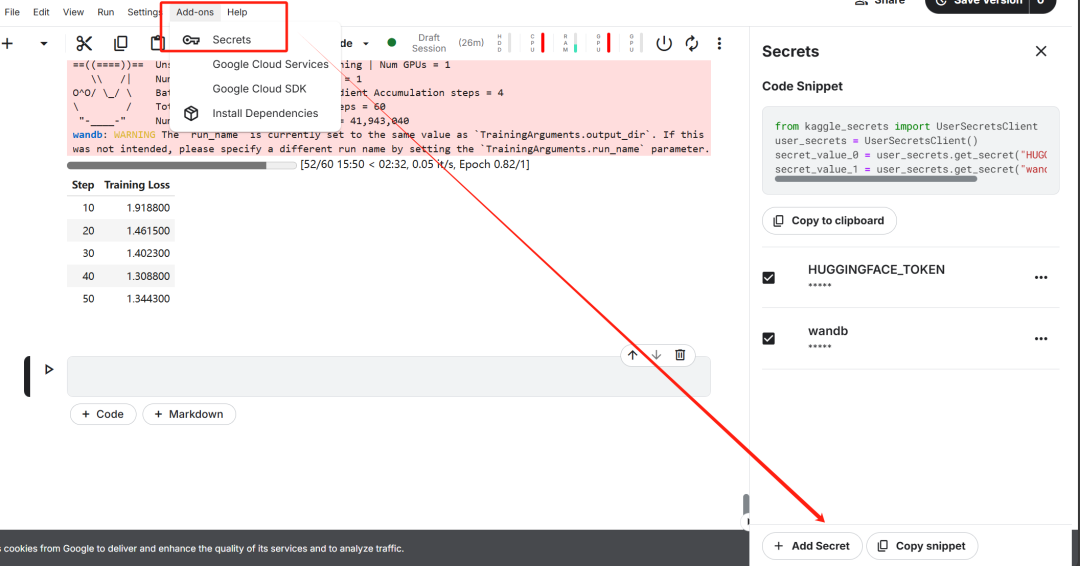
Après avoir terminé l'installation de la clé, installez le non-loth Unsloth est un framework open source conçu pour doubler la vitesse d'ajustement des grands modèles de langage (LLM) et améliorer de manière significative l'efficacité de la mémoire.
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
Cette étape est essentielle pour les téléchargements ultérieurs de l'ensemble de données et le téléchargement du modèle affiné.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)
Ensuite, connectez-vous à Weights & Biases (wandb) et créez un nouveau projet afin de suivre le déroulement de l'expérience et d'en affiner la progression.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)
2) Chargement des modèles et des tokeniseurs
Dans la pratique de ce document, la version Unsloth du modèle DeepSeek-R1-Distill-Llama-8B a été chargée.
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B
Afin d'optimiser l'utilisation de la mémoire et d'améliorer les performances, le modèle a été choisi pour être chargé de manière quantifiée sur 4 bits.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
token=hf_token,
)
3. l'amorce de la capacité de raisonnement du modèle de pré-affinage
Afin de construire un modèle d'invite pour le modèle, une invite système a été définie avec des espaces réservés pour la génération de questions et de réponses. Cette invite est destinée à guider le modèle à travers un processus de réflexion étape par étape et à générer des réponses logiquement rigoureuses et précises.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
Dans cet exemple, un message est envoyé à l'adresse suivante prompt_style a fourni un problème médical et l'a transformé en jetons, et par la suite ces jetons ont été utilisés dans le cadre d'un projet de recherche sur les maladies infectieuses. jetons transmis au modèle pour générer la réponse.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Le cœur de la question médicale ci-dessus est le suivant :
Une femme de 61 ans présente depuis longtemps des fuites d'urine involontaires lors d'activités telles que la toux ou les éternuements, mais pas de fuites nocturnes. Elle a subi un examen gynécologique et un test Q-tip. Sur la base de ces résultats, quelles informations la cystométrie pourrait-elle révéler sur son volume d'urine résiduelle et sur l'état de la contraction du détrusor ?
Même sans réglage fin, le modèle parvient à générer des chaînes de pensée et à effectuer un raisonnement rigoureux avant de donner la réponse finale, l'ensemble du processus de raisonnement étant encapsulé dans la fonction <think></think> Tagué à l'intérieur.
Alors pourquoi faut-il encore affiner le modèle ? Bien que le modèle présente un processus de raisonnement détaillé, sa représentation est un peu longue et pas assez concise. En outre, les réponses finales sont présentées sous forme de listes à puces, ce qui s'écarte de la structure et du style de l'ensemble de données à affiner.
4. le chargement et le prétraitement des ensembles de données
Le modèle d'invite a été affiné pour répondre aux besoins de traitement de l'ensemble de données en ajoutant un troisième emplacement pour la colonne Chaîne de pensée complexe dans le modèle d'invite.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
Une fonction Python a été écrite pour créer une colonne "texte" dans l'ensemble de données. Le contenu de la colonne consiste en un modèle d'invite d'entraînement avec des espaces réservés peuplés respectivement de questions, de chaînes de pensée et de réponses.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
Les 500 premiers échantillons de l'ensemble de données FreedomIntelligence/medical-o1-reasoning-SFT ont été chargés à partir du Hugging Face Hub.
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT?row=46
Par la suite, en utilisant le formatting_prompts_func met en correspondance la colonne "texte" de l'ensemble de données.
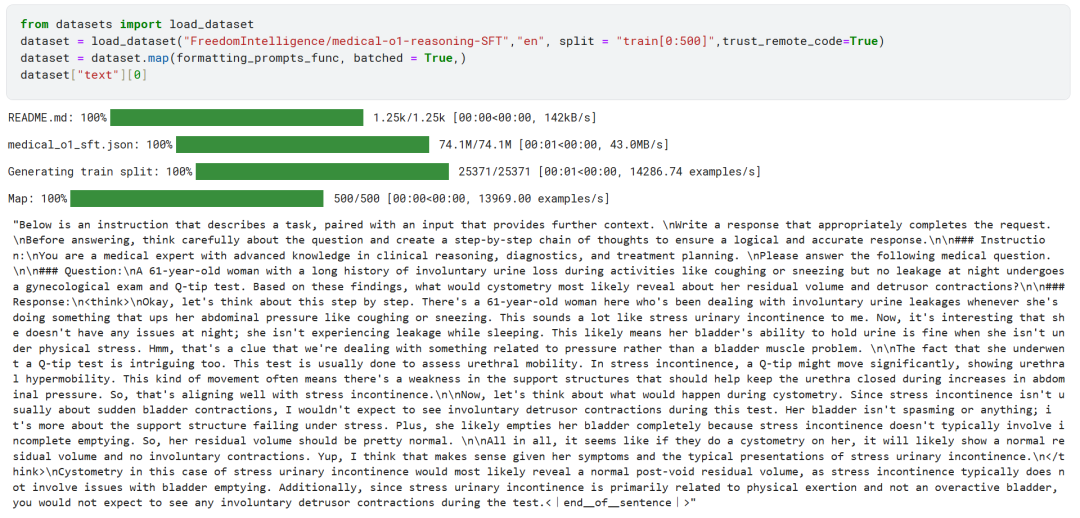
Comme vous pouvez le voir ci-dessus, la colonne "texte" a été intégrée avec succès au système d'indices, d'instructions, de chaînes de pensée et de réponses finales.
5. configuration du modèle
Le modèle est configuré à l'aide de la technique de l'adaptateur de bas rang en définissant le module cible.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
Ensuite, les paramètres de formation et le formateur (Trainer) ont été configurés. Le modèle, le tokenizer, l'ensemble de données et d'autres paramètres de formation clés ont été fournis au formateur afin d'optimiser le processus de réglage fin du modèle.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
6. formation au modèle
trainer_stats = trainer.train()
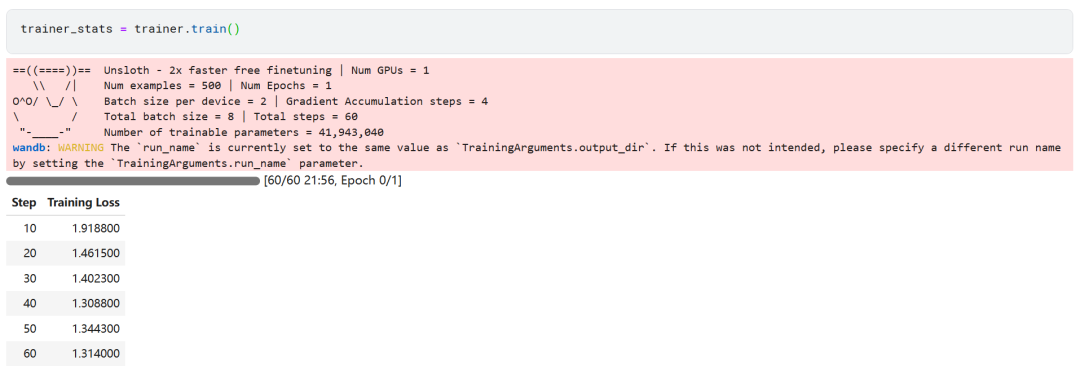
Le processus d'apprentissage du modèle a duré 22 minutes. La perte d'entraînement (perte) diminue progressivement, ce qui est un signe positif de l'amélioration des performances du modèle.
Les utilisateurs peuvent visiter le site web de Weights & Biases pour consulter le rapport complet d'évaluation du modèle.
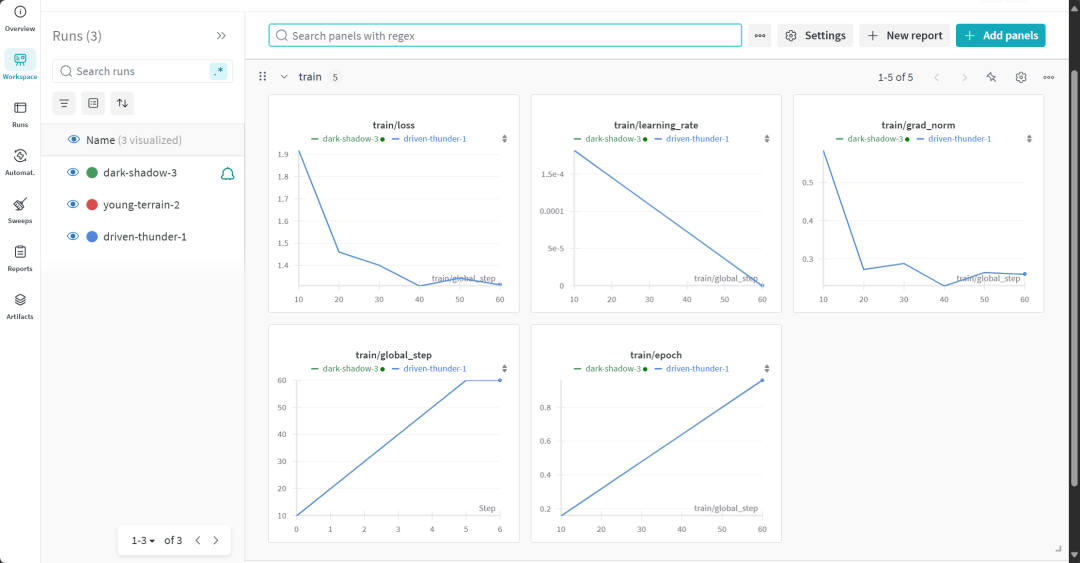
7. évaluation de la capacité de raisonnement du modèle affiné
Pour l'analyse comparative, les mêmes questions ont été posées au modèle affiné qu'avant l'affinement afin d'observer le changement dans la performance du modèle.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Les résultats expérimentaux montrent que la qualité des résultats du modèle affiné a été considérablement améliorée et que les réponses sont plus précises. La chaîne de pensée a été présentée de manière plus concise et la réponse finale a été plus directe, avec une réponse claire en un seul paragraphe, ce qui indique que le réglage fin du modèle a été un succès.

8. le stockage local des modèles
Sauvegardez maintenant l'adaptateur, le modèle complet et le tokeniser localement pour les utiliser dans d'autres projets.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")
9. modèle téléchargé sur Hugging Face Hub
L'adaptateur, le tokeniser et le modèle complet ont également été transférés vers le Hugging Face Hub, dans le but de permettre à la communauté de l'IA de tirer pleinement parti de ce modèle perfectionné et de l'intégrer facilement dans leurs systèmes.
new_model_online = "realyinchen/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method="merged_16bit")
résumés
Le domaine de l'intelligence artificielle (IA) est en pleine mutation. L'essor de la communauté des logiciels libres représente un défi de taille pour le paysage de l'IA, dominé par des modèles propriétaires depuis trois ans. Les grands modèles linguistiques (LLM) open source sont de plus en plus rapides et efficaces, ce qui permet de les affiner plus facilement que jamais avec des ressources de calcul et de mémoire réduites.
Ce document présente un examen approfondi de la DeepSeek R1 et explique comment sa version allégée peut être affinée en vue d'une application dans des scénarios de questions-réponses médicales. Le modèle d'inférence affiné offre non seulement des améliorations significatives en termes de performances, mais permet également une utilisation pratique dans des domaines clés tels que la médecine, les services d'urgence et les soins de santé.
En réponse à la sortie de DeepSeek R1, OpenAI a également introduit rapidement deux outils importants : un modèle d'inférence plus avancé, o3, et l'outil d'analyse de l'information de DeepSeek. Opérateur Ce dernier s'appuie sur le nouvel agent d'utilisation de l'ordinateur (AUC, l'agent d'utilisation de l'ordinateur). Ordinateur Use Agent) qui démontre sa capacité à naviguer de manière autonome sur des sites web et à effectuer des tâches complexes.
Code source :
https://www.kaggle.com/code/realyinchen/deepseek-r1-medical-cot
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...