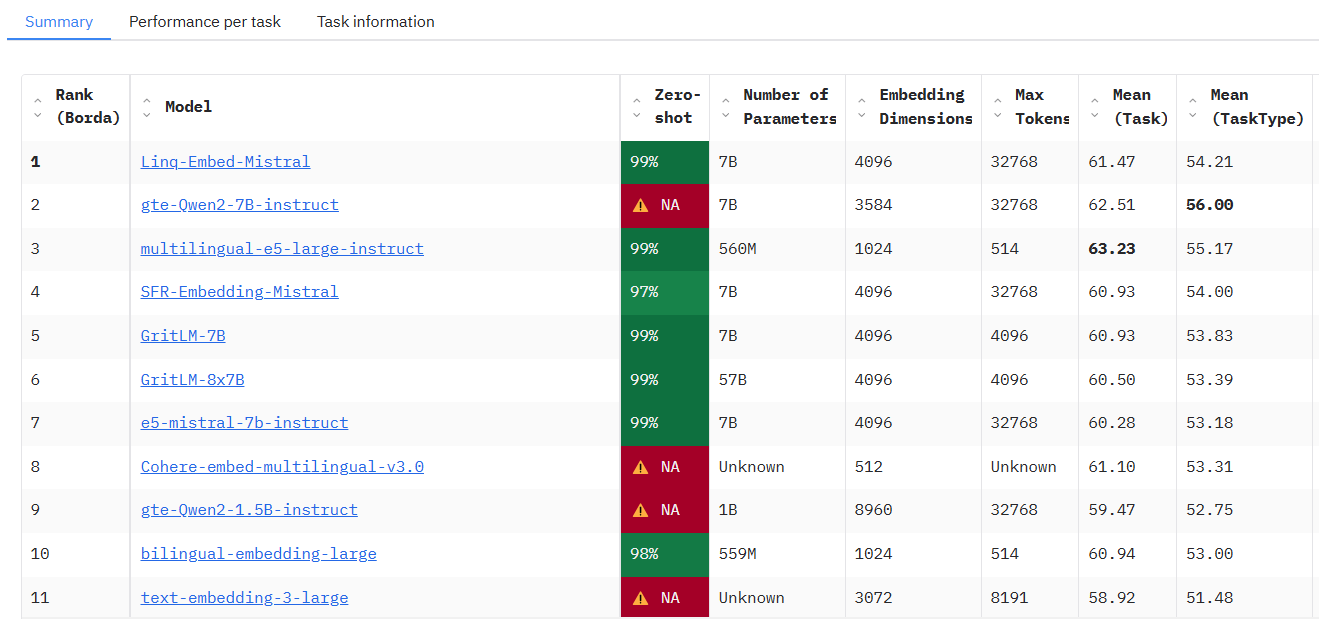
II-Researcher : Recherche approfondie et raisonnement par étapes pour répondre à des questions complexes
Introduction générale
II-Researcher est un outil de recherche en IA open source développé par l'équipe Intelligent-Internet et hébergé sur GitHub. Il est conçu pour la recherche en profondeur et le raisonnement complexe, et est capable de répondre à des questions complexes par le biais de recherches intelligentes sur le web et d'analyses en plusieurs étapes. Publié le 27 mars 2025, le projet prend en charge de nombreux outils de recherche et d'exploration (par exemple Tavily, SerpAPI, Firecrawl) et intègre LiteLLM pour appeler différents modèles d'IA. Les utilisateurs peuvent obtenir le code gratuitement et le déployer ou le modifier eux-mêmes, ce qui convient aux chercheurs, aux développeurs et aux autres personnes qui ont besoin d'un traitement efficace de l'information. Son cœur réside dans l'open source, le fonctionnement configurable et asynchrone, fournissant un soutien transparent à la recherche.

Liste des fonctions
- Recherche intelligente sur le web : via Tavily et SerpAPI pour des informations précises.
- Exploration et extraction de pages web : prise en charge de Firecrawl, Browser, BS4 et d'autres outils d'extraction de contenu.
- Raisonnement en plusieurs étapes : capacité à décomposer un problème et à raisonner étape par étape jusqu'à la réponse.
- Modèles configurables : prise en charge de l'adaptation des LLM à différentes tâches (par exemple, GPT-4o, DeepSeek).
- Opérations asynchrones : améliorer l'efficacité de la recherche et du traitement.
- Générer des réponses détaillées : fournir des rapports complets avec des références.
- Pipelines personnalisés : les utilisateurs peuvent adapter le processus de recherche et de raisonnement.
Utiliser l'aide
Processus d'installation
Pour utiliser II-Researcher, vous devez installer et configurer l'environnement. Voici les étapes spécifiques :
- Clonage de la base de code
Entrez la commande suivante dans le terminal pour télécharger le code :
git clone https://github.com/Intelligent-Internet/ii-researcher.git
cd ii-researcher
- Installation des dépendances
Le projet nécessite Python 3.7+. Exécutez la commande suivante pour installer les dépendances :
pip install -e .
- Définition des variables d'environnement
Configurez les clés et paramètres API nécessaires. Exemple :
export OPENAI_API_KEY="your-openai-api-key"
export TAVILY_API_KEY="your-tavily-api-key"
export SEARCH_PROVIDER="tavily"
export SCRAPER_PROVIDER="firecrawl"
Configuration optionnelle (pour la compression ou l'inférence) :
export USE_LLM_COMPRESSOR="TRUE"
export FAST_LLM="gemini-lite"
export STRATEGIC_LLM="gpt-4o"
export R_TEMPERATURE="0.2"
- Exécuter le serveur de modèle local LiteLLM
Installer LiteLLM :
pip install litellm
Création de fichiers de configuration litellm_config.yaml: :
model_list:
- model_name: gpt-4o
litellm_params:
model: gpt-4o
api_key: ${OPENAI_API_KEY}
- model_name: r1
litellm_params:
model: deepseek-reasoner
api_key: ${OPENAI_API_KEY}
litellm_settings:
drop_params: true
Démarrer le serveur :
litellm --config litellm_config.yaml
Par défaut, le programme s'exécute dans l'environnement http://localhost:4000.
- Déploiement Docker (optionnel)
Après avoir configuré les variables d'environnement, exécutez le programme :
docker compose up --build -d
Adresse de service :
- Côté avant :
http://localhost:3000 - API dorsale :
http://localhost:8000 - LiteLLM :
http://localhost:4000
Principales fonctions
Recherche intelligente en profondeur
- procédure: :
- Exécutez-le à partir de la ligne de commande :
python cli.py --question "AI如何改善教育质量?"
- Le système appelle Tavily ou SerpAPI pour effectuer une recherche et renvoyer les résultats.
- Description fonctionnelleLe système d'information sur la santé : Il permet des recherches à partir de plusieurs sources, ce qui convient aux problèmes complexes.
raisonnement en plusieurs étapes
- procédure: :
- Utiliser le modèle d'inférence :
python cli.py --question "AI在教育中的优缺点" --use-reasoning --stream
- Le système analyse et émet des conclusions étape par étape.
- Description fonctionnelleCapacité à effectuer des tâches nécessitant des déductions logiques.
robot d'exploration
- procédure: :
- configurer
SCRAPER_PROVIDER="firecrawl"et la clé API. - Exécutez une tâche de recherche pour explorer automatiquement le contenu web.
- Description fonctionnelleLe site Web de la Commission européenne est un outil d'exploration multiple qui permet de garantir un contenu complet.
Utilisation de l'interface web
- procédure: :
- Lancer l'API backend :
python api.py
- entrer dans
frontendinstallez et exécutez le front-end :
npm install
npm run dev
- entretiens
http://localhost:3000, des problèmes de saisie.
- Description fonctionnelleLe système de gestion de l'information : Il offre une interface graphique pour un fonctionnement plus intuitif.
mise en garde
- Une connexion réseau stable est nécessaire pour accéder à l'API.
- Configuration matérielle requise : 8 Go de RAM pour les fonctionnalités de base, 16 Go ou plus et un GPU sont recommandés pour l'inférence de grands modèles.
- Vérification des journaux : vérifiez les journaux à l'aide de la fonction
docker compose logs -fVérifier l'état de fonctionnement. - Configuration du délai : délai de recherche par défaut de 300 secondes, réglable
SEARCH_PROCESS_TIMEOUT.
Avec ces étapes, les utilisateurs peuvent facilement déployer et utiliser II-Researcher pour le processus complet, de la recherche à l'inférence.
scénario d'application
- recherche universitaire
Les chercheurs peuvent l'utiliser pour effectuer des recherches dans la littérature, analyser des données et produire des rapports. - développement technologique
Les développeurs peuvent mettre au point des outils de recherche personnalisés basés sur le cadre. - Aides pédagogiques
Les élèves peuvent l'utiliser pour organiser des informations et répondre à des questions. - analyse du marché
Les entreprises peuvent l'utiliser pour recueillir des informations sur le secteur et analyser les tendances.
QA
- II-Researcher est-il gratuit ?
Oui, il s'agit d'un projet open source et le code est gratuit pour les utilisateurs. - Besoin d'une base en programmation ?
Nécessite une connaissance de base des opérations Python, mais la documentation est suffisamment détaillée pour que les débutants puissent commencer. - Prend-il en charge le chinois ?
Soutien, configuration du modèle et de l'outil de recherche adéquats pour traiter la tâche chinoise. - Quelle est la configuration matérielle minimale requise ?
8 Go de RAM pour exécuter les fonctions de base, 16 Go ou plus et un GPU sont recommandés pour les tâches plus importantes.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...