
GOT-OCR2.0 : basé sur le modèle d'OCR multimodal de bout en bout QWen2 0.5B
Introduction générale
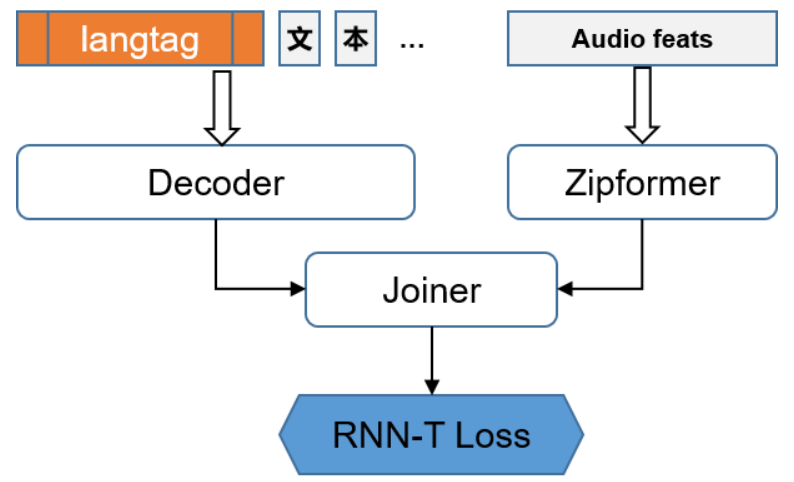
GOT-OCR2.0 est un modèle de reconnaissance optique de caractères (OCR) Open Source co-proposé par StepStar, qui vise à faire évoluer la technologie OCR vers OCR-2.0 grâce à un modèle unifié de bout en bout. Le modèle prend en charge un large éventail de tâches d'OCR, y compris la reconnaissance de texte simple, la reconnaissance de texte formaté, l'OCR à grain fin, l'OCR multi-cultures et l'OCR multi-pages.GOT-OCR2.0 est conçu dans le but de fournir une solution polyvalente et efficace pour un large éventail de scénarios d'application d'OCR complexes.
Basé sur le modèle QWen2 0.5 B. Appelé OCR 2.0, le modèle OCR de bout en bout avec 580 millions de paramètres a obtenu un score BLEU de 0,972. Adresse de l'expérience en ligne : https://huggingface.co/spaces/ucaslcl/GOT_online


Liste des fonctions
- Reconnaissance de texte en clair : reconnaître le contenu de texte en clair dans les images.
- Reconnaissance du texte formaté : reconnaît et conserve les informations de formatage du texte, telles que les tableaux, les paragraphes, etc.
- OCR fine : reconnaissance de textes fins dans des images et de textes sur des arrière-plans complexes.
- OCR multicadres : permet de recadrer plusieurs fois une image et de reconnaître le texte dans chaque zone recadrée.
- OCR multi-pages : prend en charge l'OCR de documents multi-pages.
Utiliser l'aide
Processus d'installation
- Cloner le code du projet :
git clone https://github.com/Ucas-HaoranWei/GOT-OCR2.0.git cd GOT-OCR2.0 - Créer et activer un environnement virtuel :
conda create -n got python=3.10 -y conda activate got - Installer les dépendances du projet :
pip install -e . - Installer Flash-Attention :
pip install ninja pip install flash-attn --no-build-isolation
Obtention des poids du modèle GOT
- Visage étreint
- Google Drive
- Nuage de Baidu(Code d'extraction : OCR2)
Processus d'utilisation
- Préparer les données d'entrée : placer l'image ou le document à ocr dans le répertoire d'entrée spécifié.
- Exécuter le modèle OCR :
python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type ocr - Afficher la sortie : le texte traité par l'OCR sera enregistré dans le répertoire de sortie spécifié, et les utilisateurs pourront le traiter ultérieurement si nécessaire.
Fonctions
- Reconnaissance de texte brutReconnaît et restitue le contenu textuel ordinaire des images sous forme de fichiers de texte brut, adaptés à des tâches simples d'extraction de texte.
- Reconnaissance du texte formatéPréserver les informations de mise en forme, telles que les tableaux, les paragraphes, etc., tout en reconnaissant le texte, pour les scénarios dans lesquels la mise en forme originale du document doit être préservée.
- ROC à grain finReconnaissance de textes fins dans des arrière-plans complexes, adaptée aux scènes nécessitant une extraction de texte de haute précision.
- OCR multi-culturesLa reconnaissance de texte : recadre l'image plusieurs fois et reconnaît le texte dans chaque région recadrée, ce qui convient aux scénarios qui nécessitent la reconnaissance de plusieurs régions d'une image.
- OCR multi-pagesL'OCR des documents multi-pages est possible, ce qui convient aux scénarios dans lesquels de longs documents ou des fichiers PDF multi-pages sont traités.
Grâce aux étapes ci-dessus, les utilisateurs peuvent facilement installer et utiliser le modèle GOT-OCR2.0 pour diverses tâches d'OCR. Le modèle fournit des modules fonctionnels riches pour répondre aux besoins d'OCR dans différents scénarios.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...