GLM-4.5V - Modèle de raisonnement visuel multimodal Open Source par Smart Spectrum
Qu'est-ce que le GLM-4.5V ?
GLM-4.5V est le premier modèle d'inférence visuelle open source au monde lancé par Smart Spectrum, avec 106 milliards de paramètres totaux et 12 milliards de paramètres activés. Le modèle est basé sur une nouvelle génération de modèles de base textuelleGLM-4.5-AirGLM-4.5 est entraîné à avoir de fortes capacités de compréhension et de raisonnement visuels, et peut traiter un large éventail de contenus visuels tels que des images, des vidéos, des documents, etc. Le modèle est performant dans les tâches multimodales, couvrant des scénarios tels que les questions-réponses visuelles, la génération de descriptions d'images, la compréhension de vidéos et la réplication de sites web, tout en supportant une commutation flexible entre la réponse rapide et l'inférence profonde.GLM-4.5V atteint une performance SOTA dans 41 listes multimodales visuelles publiquement disponibles, et réalise une inférence visuelle de scénario complet grâce à un entraînement hybride efficace, fournissant des solutions d'IA multimodales rentables pour les entreprises et les développeurs. multimodale pour les entreprises et les développeurs.
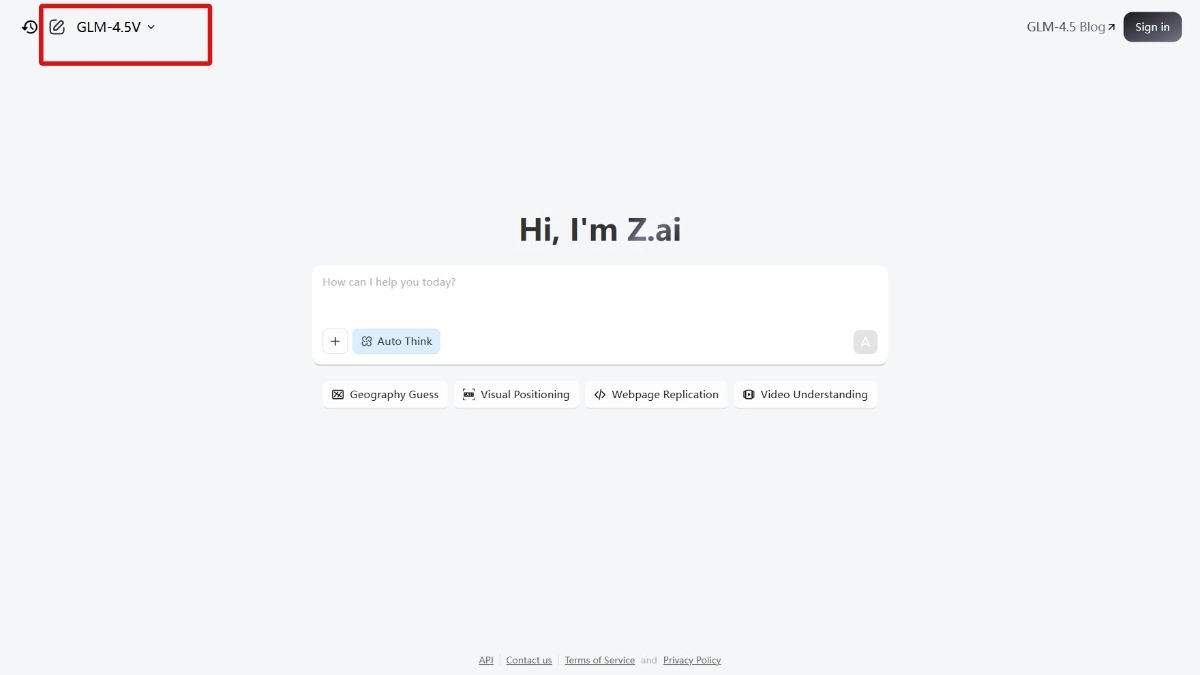
GLM-4.5V Caractéristiques fonctionnelles
- raisonnement graphiqueLes élèves sont capables de comprendre les objets, les relations entre les personnages et les informations contextuelles dans des scènes complexes.
- Compréhension vidéoLe logiciel d'analyse de contenu vidéo : Il prend en charge l'analyse de contenus vidéo longs, y compris les scènes fractionnées, la reconnaissance d'événements et l'extraction d'informations clés.
- Capacités d'interaction multimodale: :
- Intégration textuelle et visuelleLes images peuvent être générées à partir de descriptions textuelles ou à partir de descriptions textuelles à partir d'images.
- génération multimodaleLa capacité de convertir un contenu visuel en texte, ou un contenu textuel en contenu visuel.
- Réplique de l'interface WebIl permet de générer un code frontal basé sur des dessins de conception web pour un développement web rapide. Les utilisateurs n'ont qu'à télécharger des captures d'écran de pages web ou des vidéos interactives, et le modèle peut générer un code HTML, CSS et JavaScript complet.
- Jeux TouhouCaractéristiques : Prise en charge des tâches de recherche et de mise en correspondance basées sur l'image. Par exemple, la recherche rapide d'images cibles spécifiques dans des scènes complexes, adaptée à la surveillance de la sécurité, à la vente au détail intelligente et au développement de jeux de divertissement.
- Interprétation de documents complexesCapacité à travailler avec de longs documents et des diagrammes complexes, à extraire, résumer et traduire des informations. Permet d'exporter son propre "point de vue", et pas seulement d'extraire de simples informations.
Principaux avantages du GLM-4.5V
- Forte compréhension visuelle et raisonnementL'élève est capable de comprendre en profondeur un contenu visuel complexe, y compris des images, des vidéos et des documents. Il peut non seulement reconnaître des objets, des scènes et des relations humaines, mais aussi effectuer des raisonnements avancés, comme déduire des informations contextuelles à partir d'indices subtils dans une image.
- Interaction multimodale et capacités de productionLe modèle prend en charge l'intégration transparente du contenu textuel et visuel, avec la possibilité de générer des images à partir de descriptions textuelles, ou des descriptions textuelles à partir d'images. Le modèle prend en charge la mise en œuvre de la génération multimodale, par exemple la conversion d'un contenu visuel en texte, ou d'un contenu textuel en contenu visuel.
- Modèle efficace d'adaptation des tâches et de raisonnementIl est équipé de capacités de raisonnement visuel sur l'ensemble de la scène et peut traiter un large éventail de tâches telles que le raisonnement sur les images, la compréhension des vidéos, les tâches liées aux interfaces graphiques et l'analyse de diagrammes complexes et de longs documents.
- Un déploiement rapide et rentableIl s'agit d'un outil qui permet d'équilibrer la vitesse d'inférence et le coût de déploiement tout en conservant une grande précision. Son prix d'appel API est aussi bas que 2 $/M tokens pour l'entrée et 6 $/M tokens pour la sortie, avec une vitesse de réponse de 60-80 tokens/s.
- Source ouverte et large soutien de la communautéLes développeurs peuvent utiliser plusieurs canaux, tels que le dépôt GitHub, le dépôt de modèles Hugging Face et la communauté Magic Ride, pour faciliter le démarrage rapide et le développement secondaire, et fournir une application d'assistant de bureau pour prendre en charge la capture et l'enregistrement d'écran en temps réel, afin de faciliter l'expérience des développeurs en ce qui concerne la capacité du modèle.
- Large éventail de scénarios d'applicationLes applications : Pour une variété de scénarios d'application dans le monde réel, y compris la réplication de l'interface web, les quiz visuels, les jeux de recherche de graphes, la compréhension de vidéos, la génération de descriptions d'images, et l'interprétation de documents complexes.
Quel est le site web officiel de GLM-4.5V ?
- Dépôt GitHub: : https://github.com/zai-org/GLM-V/
- Bibliothèque de modèles HuggingFace: : https://huggingface.co/collections/zai-org/glm-45v-68999032ddf8ecf7dcdbc102
- Documents techniques: : https://github.com/zai-org/GLM-V/tree/main/resources/GLM-4.5V_technical_report.pdf
- Application Desktop Assistant: : https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
Personnes pour lesquelles GLM-4.5V est adapté
- développeursLe logiciel de développement multimodal : Il offre aux développeurs de puissantes capacités de développement multimodal pour les aider à créer rapidement des applications telles que les quiz visuels, la génération d'images, l'analyse vidéo, et bien plus encore.
- utilisateur professionnelLes entreprises utilisent les capacités de compréhension visuelle pour optimiser des scénarios commerciaux tels que la sécurité et la surveillance, la vente au détail intelligente et la recommandation vidéo.
- chercheurGLM-4.5V : Les chercheurs exploitent les modèles et les ensembles de données open-source de GLM-4.5V pour mener des recherches de pointe dans les domaines du raisonnement multimodal, de la fusion de langages visuels, et bien plus encore.
- utilisateur régulierLes utilisateurs ordinaires utilisent des fonctions telles que la description des images et la compréhension des vidéos pour améliorer l'efficacité de la création de contenu et l'accès à l'information.
- Éducateurs et étudiantsLes services d'éducation et de formation : les éducateurs et les étudiants pour faciliter l'enseignement et l'apprentissage et améliorer l'expérience éducative.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Postes connexes

Pas de commentaires...