开源大模型,免费使用GPU资源和API服务(测试期)-1")
glhf.chat : exécution de presque (tous) les grands modèles open source, accès gratuit aux ressources GPU et aux services API (période bêta).
Introduction générale
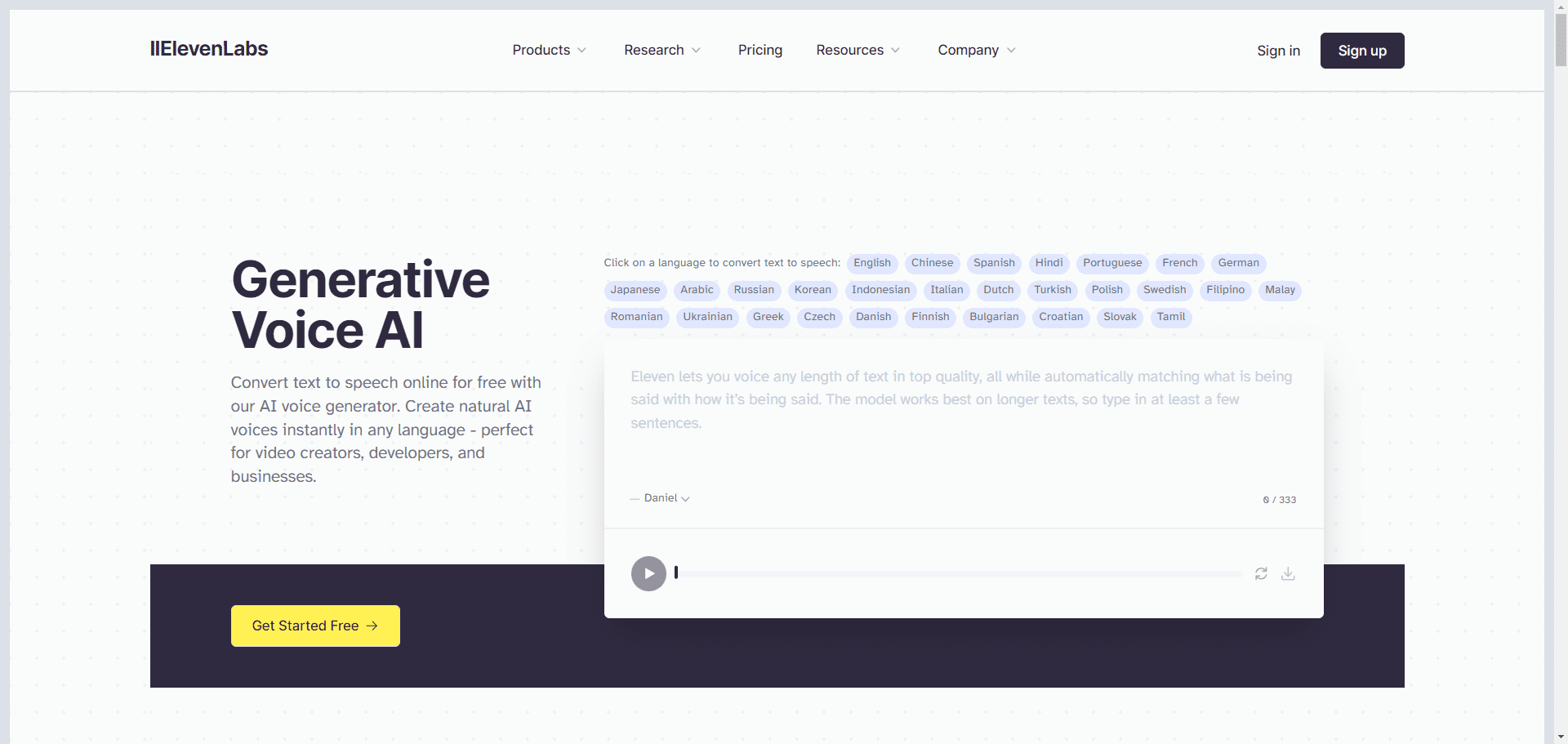
good luck have fun (glhf.chat) est un site web qui propose un service de chat sur les grands modèles. La plateforme permet aux utilisateurs d'exécuter presque n'importe quel grand modèle open source en utilisant vLLM et un planificateur GPU personnalisé à mise à l'échelle automatique. Les utilisateurs peuvent simplement coller un lien vers le référentiel Hugging Face et interagir en utilisant l'interface de chat ou des API compatibles avec OpenAI. La plateforme est proposée gratuitement pendant la période bêta et sera disponible à l'avenir à un prix inférieur à celui des principaux fournisseurs de GPU en nuage.
开源大模型,免费使用GPU资源和API服务(测试期)-1")
Liste des fonctions
- Supporte une variété de macromodèles open source, y compris Meta Llama, Qwen, Mixtral, etc.
- Permet d'accéder à un maximum de huit GPU Nvidia A100 80Gb
- Services de raisonnement pour les modèles de population d'agents automatisés
- Démarrage et arrêt des grappes à la demande pour optimiser l'utilisation des ressources
- Fournit des API compatibles avec l'OpenAI pour une intégration facile
Utiliser l'aide
Installation et utilisation
- S'inscrire et se connecter: Accèsglhf.chatet créez un compte, puis connectez-vous lorsque vous avez terminé.
- Sélectionner le modèlePour ce faire, vous devez sélectionner le macromodèle souhaité sur la page d'accueil de la plateforme. Les modèles pris en charge sont Meta Llama, Qwen, Mixtral et bien d'autres encore.
- Coller le lienPour cela, il suffit de coller le lien du référentiel Hugging Face à l'endroit indiqué et la plateforme chargera automatiquement le modèle.
- Utilisation de l'interface de dialogue en ligneInteraction avec le modèle : interagir avec le modèle par l'intermédiaire de l'interface de discussion fournie sur le site web, en tapant des questions ou des commandes, et le modèle générera des réponses en temps réel.
- Intégration de l'APILes fonctionnalités de la plate-forme peuvent être intégrées dans vos propres applications à l'aide d'API compatibles avec l'OpenAI, comme indiqué dans la documentation de l'API dans le centre d'aide du site web.
Fonction détaillée du déroulement des opérations
- Sélection et chargement du modèle: :
- Après avoir ouvert une session, vous accéderez à la page de sélection du modèle.
- Parcourez la liste des modèles pris en charge et cliquez sur le modèle souhaité.
- Collez le lien vers le référentiel Hugging Face dans la boîte de dialogue contextuelle et cliquez sur le bouton "Charger le modèle".
- Attendez que le modèle ait fini de se charger. Le temps de chargement dépend de la taille du modèle et des conditions du réseau.
- Utilisation de l'interface de chat: :
- Une fois le modèle chargé, entrez dans l'écran de discussion.
- Saisissez une question ou une instruction dans le champ de saisie et cliquez sur Envoyer.
- Le modèle génère une réponse sur la base de l'entrée et la réponse est affichée dans la fenêtre de discussion.
- Plusieurs questions ou commandes peuvent être saisies successivement, et le modèle les traitera et y répondra une par une.
- Utilisation de l'API: :
- Consultez la page de documentation de l'API pour obtenir les clés et instructions de l'API.
- Intégrez l'API dans votre application et suivez l'exemple de code fourni dans la documentation pour effectuer les appels.
- Envoyer une requête via l'API pour obtenir une réponse générée par le modèle.
- L'API prend en charge une variété de langages de programmation, voir la documentation pour des exemples de code spécifiques.
Gestion et optimisation des ressources
- Expansion automatiqueLa plateforme utilise un planificateur GPU personnalisé qui augmente et réduit automatiquement les ressources GPU en fonction de la demande de l'utilisateur afin d'assurer une utilisation efficace.
- activation à la demandePour les modèles qui ne sont pas couramment utilisés, la plateforme démarre les clusters à la demande et les arrête automatiquement lorsqu'ils sont utilisés, ce qui permet d'économiser des ressources.
- Test gratuitPendant la période de test bêta, les utilisateurs auront un accès gratuit à toutes les fonctionnalités offertes par la plateforme, et un plan de tarification réduit sera disponible à la fin du test.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...