
Les modèles de la série PP de Flying Paddles sont nouveaux ! La nouvelle "abeille" de PP-DocBee pour la compréhension de l'image des documents !
La technologie de compréhension des images de documents vise à permettre aux ordinateurs de comprendre le contenu des images de documents aussi bien que les humains. Il s'agit principalement d'analyser, de traiter et de comprendre des images de documents (contrats papier, pages de livres, factures, etc.) obtenues par numérisation ou photographie, d'en extraire des informations utiles, telles que du texte, des tableaux, des graphiques, etc. et de structurer ces informations. Dans la vague actuelle de transformation numérique, la technologie de compréhension des images de documents est largement utilisée dans les entreprises, les universités et la vie quotidienne pour améliorer l'efficacité et la précision du traitement des documents.
Précédemment, FeiPaddle a publié la solution de fusion de modèles de taille PP-ChatOCRv3, qui utilise d'abord la technologie OCR pour extraire le texte de l'image, puis l'introduit dans le Wenxin Big Model pour analyser le quiz, ce qui améliore considérablement l'analyse de la disposition texte-image et l'effet d'extraction de l'information. Le système est très précis pour le texte et les tableaux, mais la capacité à comprendre les images et les graphiques dans les documents doit encore être améliorée. Par conséquent, afin de mieux satisfaire les besoins des utilisateurs pour des tâches complexes et diverses de compréhension d'images de documents, nous proposons un nouveau système, PP-DocBee, qui permet de comprendre de bout en bout les images de documents sur la base d'un macromodèle multimodal. Il peut être appliqué efficacement à toutes sortes de scénarios tels que la compréhension de documents, les questions-réponses sur les documents, etc. En particulier pour les scénarios de compréhension de documents chinois, tels que les rapports financiers, les lois et règlements, les thèses, les manuels, les contrats, les rapports de recherche, etc.
Exemple de compréhension de documents Un rapide coup d'œil sur l'effet de PP-DocBee sur la compréhension de textes imprimés, de tableaux, de graphiques et d'autres documents :


PP-DocBee a pratiquement atteint la SOTA pour les modèles du même niveau de volume de paramètres sur plusieurs listes d'examen de la compréhension de documents anglais faisant autorité dans le monde universitaire.
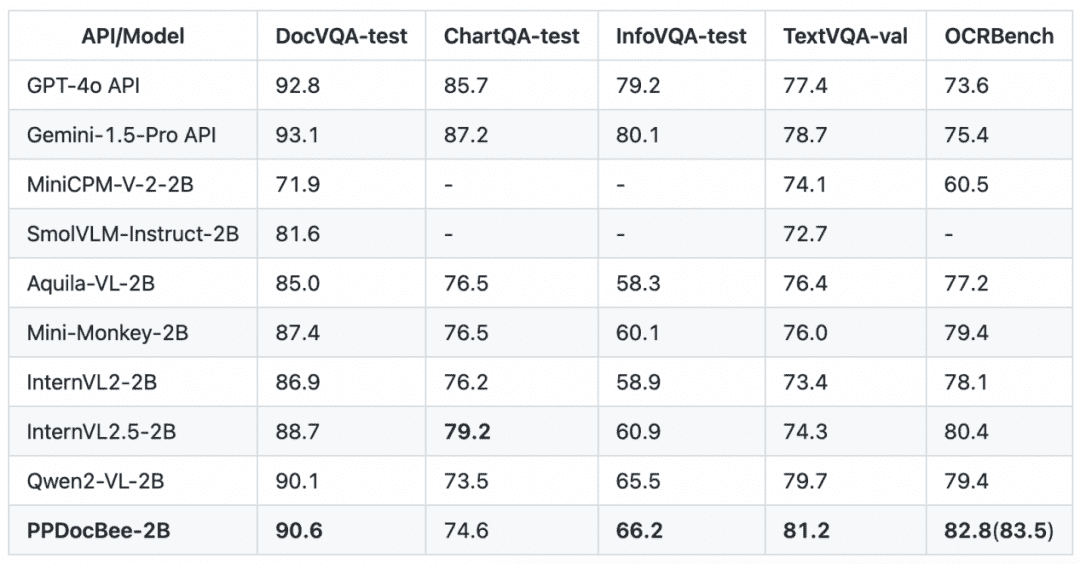
English Document Comprehension Review List Comparaison des concurrents
Note : Les mesures OCRBench sont normalisées sur une échelle de 100 points, et les mesures OCRBench de PPDocBee-2B ont un score de 82,8 pour l'évaluation de bout en bout et de 83,5 pour l'évaluation assistée par post-traitement de l'OCR. PP-DocBee est également plus performant que les modèles populaires actuels à source ouverte et fermée dans la catégorie des mesures du scénario chinois de l'entreprise interne.
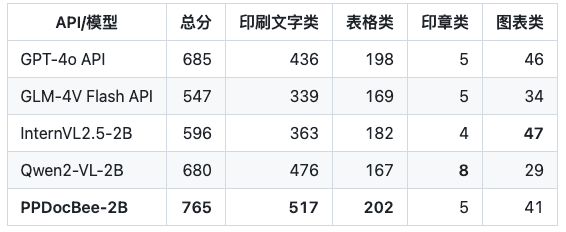
Scénario chinois des affaires Comparaison des concurrents
Note : L'ensemble des scénarios chinois d'évaluation pour les affaires internes comprend des scénarios de rapports financiers, de lois et de règlements, d'articles scientifiques et techniques, de manuels, d'articles d'arts libéraux, de contrats, de rapports de recherche, etc., qui sont divisés en quatre catégories principales : textes imprimés, formulaires, sceaux et graphiques.
Pour améliorer encore les performances de l'inférence PP-DocBee, nous obtenons une réduction du temps d'inférence de 51,51 TP3T et une réduction du temps total de bout en bout de 41,91 TP3T grâce à l'optimisation de la fusion des opérateurs, comme le montre le tableau suivant.
| PP-DocBee | Temps moyen de bout en bout (s) | Temps moyen de prétraitement (s) | Temps moyen consacré au raisonnement (s) |
| version par défaut | 1.60 | 0.29 | 1.30 |
| Édition haute performance | 0.93 | 0.29 | 0.63 |
Note : La version haute performance a pratiquement la même quantité de jetons de sortie que la version par défaut avec la même quantité de jetons d'entrée. Grâce à l'optimisation des performances de la palette volante, PP-DocBee répond plus rapidement tout en maintenant la qualité des réponses. Cette version de raisonnement haute performance, pour plus de détails, peut être consultée à l'adresse suivante : https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/ppdocbee
Nous fournissons également un environnement d'expérience en ligne pour la communauté de Flying Paddle Star River, où vous pouvez rapidement expérimenter les fonctionnalités de PP-DocBee grâce au centre d'application de la communauté de Flying Paddle Star River (https://aistudio.baidu.com/application/detail/60135).
En outre, nous fournissons également un déploiement local de gradio, un déploiement de service OpenAI, ainsi que des instructions détaillées, les utilisateurs et les enthousiastes sont invités à visiter la page d'accueil du projet : https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/ exemples/ppdocbee
Introduction au programme PP-DocBee
La structure du modèle PP-DocBee est présentée dans la figure suivante, en utilisant l'architecture ViT+MLP+LLM. Les idées d'optimisation pour les scénarios de compréhension des documents sont les suivantesStratégies de synthèse des données, prétraitement des données, méthodes de formation et assistance au post-traitement OCRAu final, le modèle est capable de comprendre des documents génériques et d'analyser des documents dans des scénarios chinois.

Structure du modèle PP-DocBee
Plus précisément, PP-DocBee comprend les améliorations majeures suivantes :
1. stratégie de synthèse des données
Pour résoudre les problèmes liés à l'insuffisance des capacités linguistiques en chinois et au manque de données de scène, nous avons conçu une solution de production intelligente pour les données de type document, des liens de génération de données différents pour chacun des trois principaux types d'ensembles de données, tels que Doc, Tableau, Graphique, etc. et adopté de nombreuses stratégies : combinaison du petit modèle OCR et du grand modèle LLM, production de données d'image basée sur le moteur de rendu, et production de données personnalisée pour chaque type de document Ces stratégies ont permis d'améliorer la qualité des questions et réponses et de contrôler les coûts de production. Les détails sont illustrés dans la figure ci-dessous :
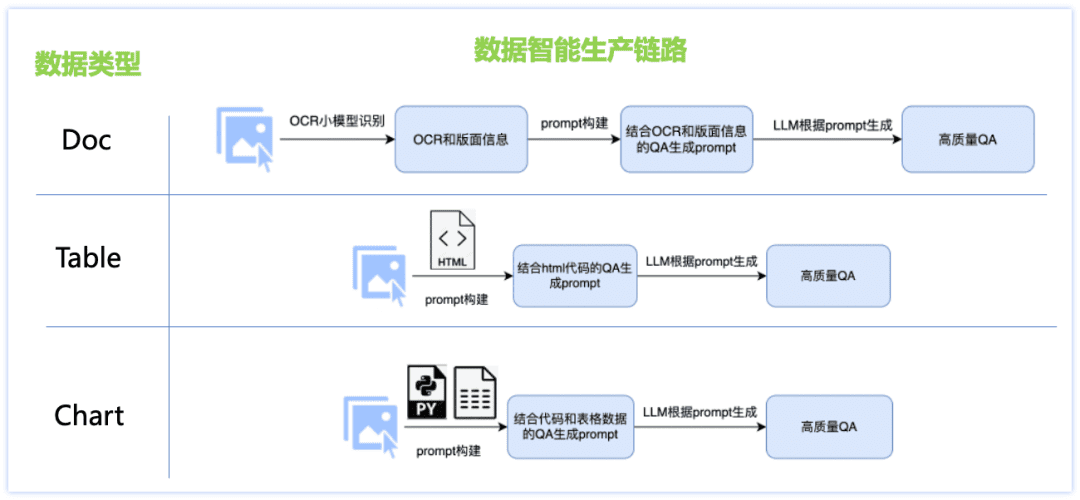
Données de la classe Doc :
Picture : collecte et organise des documents, des rapports financiers, des documents de recherche et d'autres fichiers pdf, combinés à des outils d'analyse pdf pour produire des données massives d'images de documents d'une seule page ;
Q&R : Le petit modèle de l'OCR extrait des informations détaillées sur la présentation de l'image, compensant ainsi les lacunes du grand modèle en matière de perception visuelle, et utilise en même temps la puissante capacité de compréhension du texte du grand modèle linguistique pour corriger l'imprécision de la reconnaissance des caractères individuels du petit modèle de l'OCR ; la combinaison des deux permet de produire des Q&R de meilleure qualité et contrôlables en termes de typographie.
Données de la classe de tableaux :
Image : sur la base de l'image du tableau contenant des informations textuelles html, modifier la valeur, le sujet et d'autres informations du texte à l'aide du modèle de grand langage, et obtenir l'image du tableau de haute qualité riche en contenu à l'aide de l'outil de rendu du tableau.
Q&A : le texte au format html correspondant à l'image du tableau est utilisé comme information auxiliaire GT pour garantir l'exactitude des réponses, et la conception de messages-guides finement ajustés pour produire des Q&A de haute qualité grâce à un grand modèle linguistique.
Données de la classe graphique :
Image : sur la base des données sources de graphiques de haute qualité testés par la foule (données image-code-table), modifier de manière aléatoire les valeurs, les axes, les légendes, les thèmes et d'autres informations détaillées du graphique dans le code à l'aide du modèle de langage étendu, obtenir le code source avec des contenus divers, puis le rendre à l'aide de l'outil de rendu de graphique (voir l'encadré ci-dessous).Matplotlib, Seaborn, Vega-Liteetc.) pour obtenir des données d'images cartographiques de haute qualité ;
Q&R : le code correspondant à l'image du graphique et aux données du tableau est utilisé comme information auxiliaire GT pour garantir l'exactitude de la réponse, et les types de questions correspondants sont conçus pour différents types de graphiques, et l'invite finement ajustée est conçue pour produire des Q&R de haute qualité par le biais du grand modèle de langage. Grâce au schéma de production intelligente de données de type document ci-dessus, nous obtenons une grande quantité de données synthétiques et filtrons certaines d'entre elles pour en faire des données d'entraînement PP-DocBee (la distribution des données est illustrée dans la figure ci-dessous), ce qui permet d'améliorer efficacement la capacité du modèle.
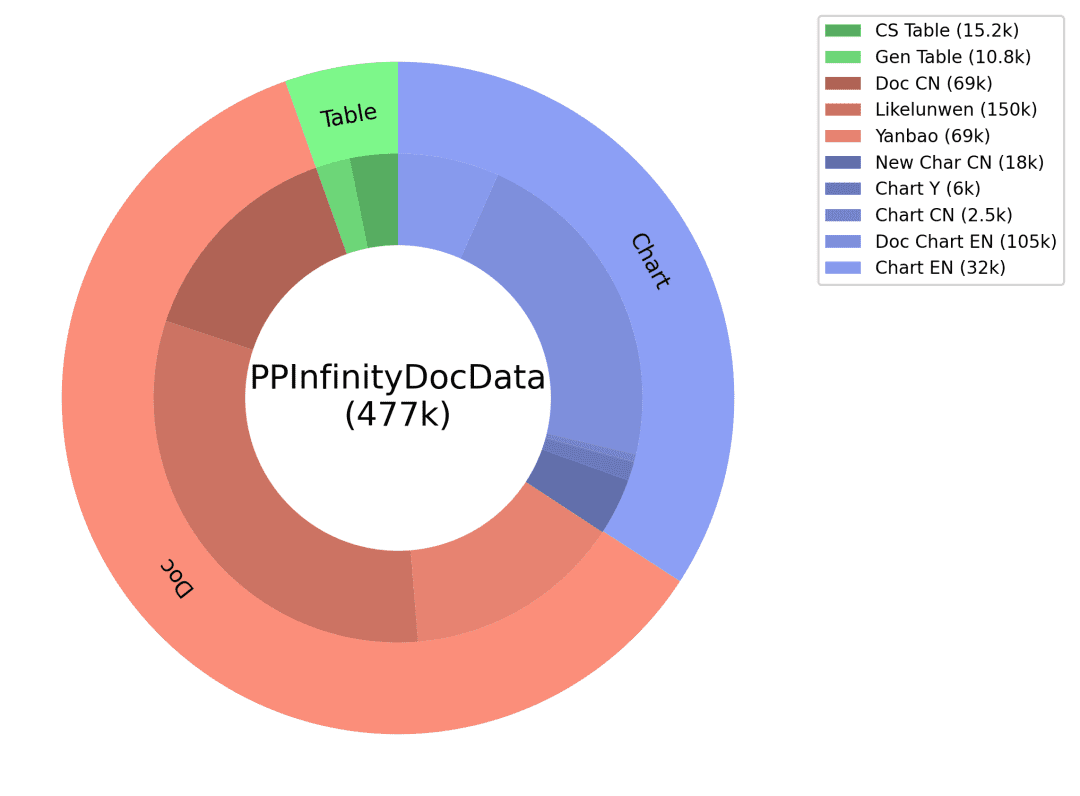
Distribution des données synthétiques
2. le prétraitement des données
Deux stratégies sont incluses, l'une consiste à fixer un seuil de redimensionnement plus important pendant l'entraînement afin d'augmenter la distribution de la résolution globale de l'ensemble de données, et l'autre consiste à fixer un agrandissement égal de 1,1 à 1,3 fois pour la plupart des images régulières pendant l'inférence, tout en conservant la stratégie de prétraitement des données d'origine inchangée pour les images de faible résolution. Ces deux stratégies ont permis d'obtenir des caractéristiques visuelles plus adéquates et plus complètes, ce qui a amélioré la compréhension finale.
3. les méthodes de formation
Il s'agit principalement d'un mélange de diverses classes de données relatives à la compréhension des documents, et un mécanisme de mise en correspondance des données est mis en place. Le mécanisme de mise en correspondance des données consiste à définir des ratios d'échantillonnage pour les données provenant de différentes sources dans différentes classes et interclasses afin d'augmenter les poids d'échantillonnage des données ayant des gains plus importants dans plusieurs classes, ainsi que d'équilibrer les différences quantitatives entre les différents types d'ensembles de données.
4. assistance au post-traitement de l'OCR
Principalement par le biais de l'outil OCR ou du modèle à l'avance pour obtenir la reconnaissance OCR des résultats du texte, puis comme une information auxiliaire a priori fournie dans les questions du quiz de l'image, et ensuite donner le raisonnement du modèle PP-DocBee, peut être dans le texte n'est pas beaucoup et l'image claire a un certain effet sur l'amélioration.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...