
Lancement de Doubao-1.5-pro : un nouveau modèle de base multimodal pour l'équilibre ultime
Doubao-1.5-pro
🌟 Profil du modèle
Doubao-1.5-pro est un modèle très clairsemé de Architecture du ministère de l'environnementDans les quatre quadrants de pré-remplissage/décodage et d'attention/FFN, les caractéristiques de calcul et d'accès sont très différentes. Pour les quatre quadrants différents, nous adoptons du matériel hétérogène combiné à différentes stratégies d'optimisation de faible précision afin d'augmenter considérablement le débit tout en garantissant une faible latence, et de réduire le coût total tout en tenant compte des objectifs d'optimisation de TTFT et TPOT, atteignant ainsi l'équilibre ultime entre la performance et l'efficacité de l'inférence.
- paramètre d'activation mineurdépasse les performances du très grand modèle dense.
- Adaptation multi-scèneLes performances sont supérieures à de nombreux critères d'évaluation.
📊 Évaluation des performances
Résultats de Doubao-1.5-pro sur de nombreux benchmarks
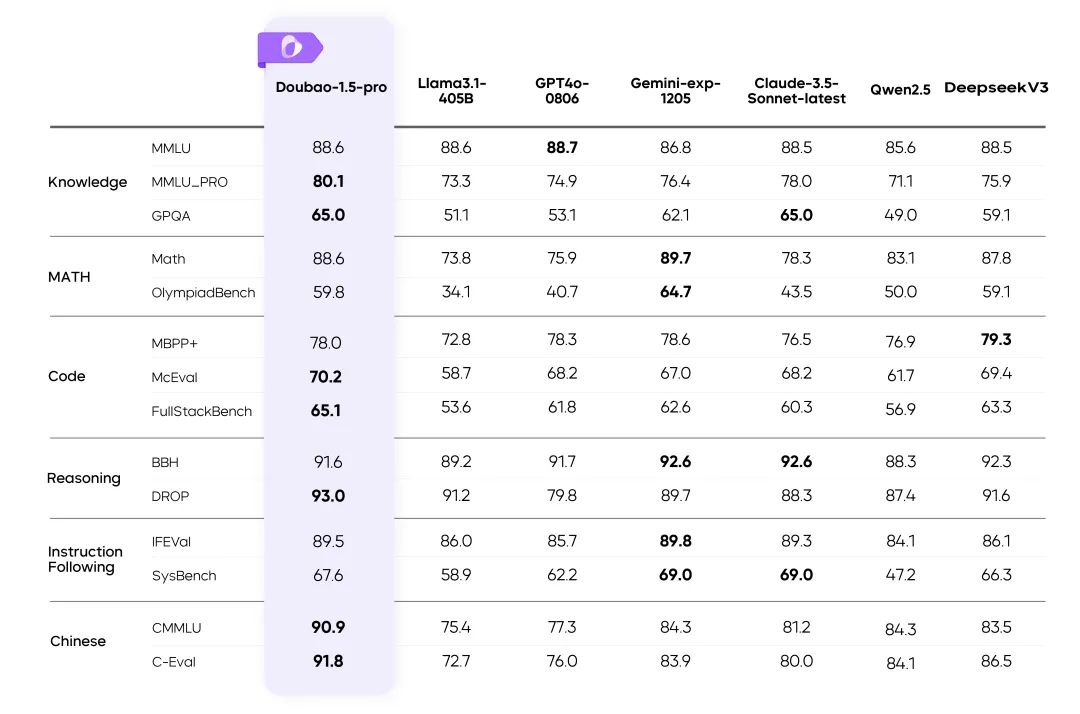
instructions: :
- Les mesures pour les autres modèles du tableau sont tirées des résultats officiels, et les parties non publiées sont réalisées par des plates-formes d'évaluation internes.
- GPT4o-0806 Excellente performance dans les évaluations publiques des modèles de langage, voir : simple-evals.
⚙️ Équilibrer la performance et le raisonnement
Architecture efficace des ministères de l'environnement
- utiliser Architecture MoE clairsemée Optimisation double de l'efficacité de la formation et du raisonnement.
- Points forts de la rechercheLes résultats de l'analyse de la performance et de l'efficacité sont déterminés à l'aide de la loi de mise à l'échelle de la sparsité (sparsity Scaling Law).
Perte d'entraînement vs.

Comparaison des performances des modèles
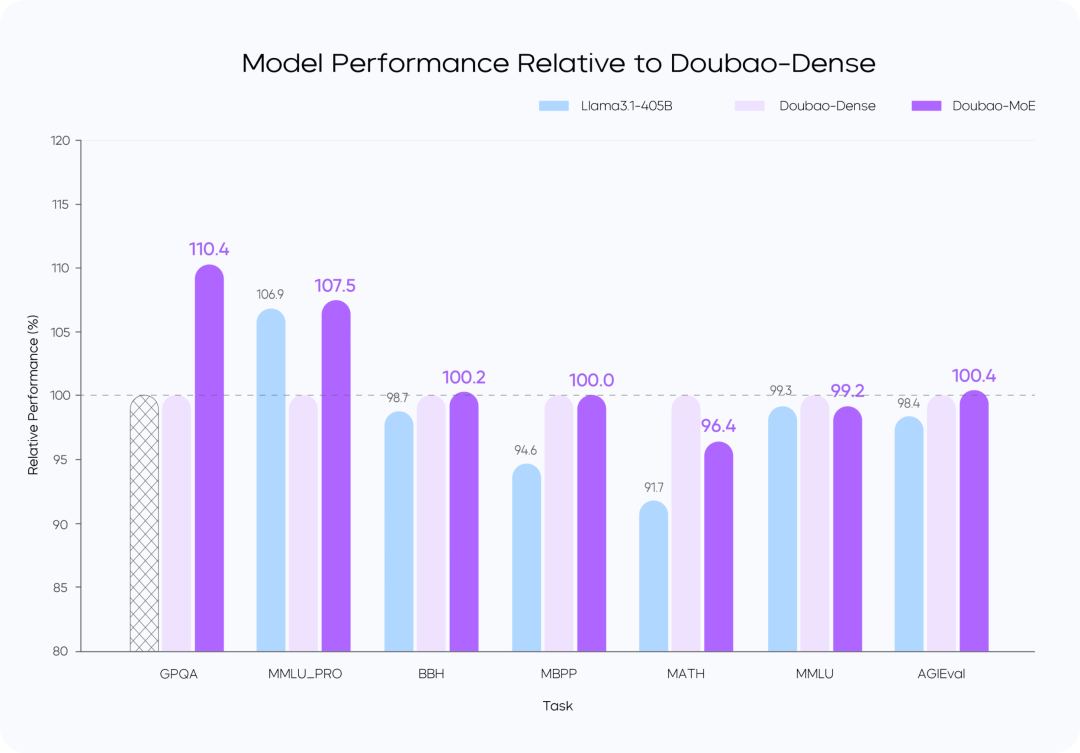
instructions: :
- Le modèle Doubao-MoE est plus performant qu'un modèle dense comportant 7 fois plus de paramètres activés (Doubao-Dense).
- Doubao La formation de modèles denses est plus efficace que la formation de modèles denses. Llama 3.1-405BLa qualité des données et l'optimisation des hyperréférences sont essentielles.
🚀 Raisonnement de haute performance
Optimisation des calculs et des caractéristiques d'accès
Doubao-1.5-pro obtient de bons résultats dans quatre quadrants de calcul : Pré-remplissage, Décodage, Attention et FFN.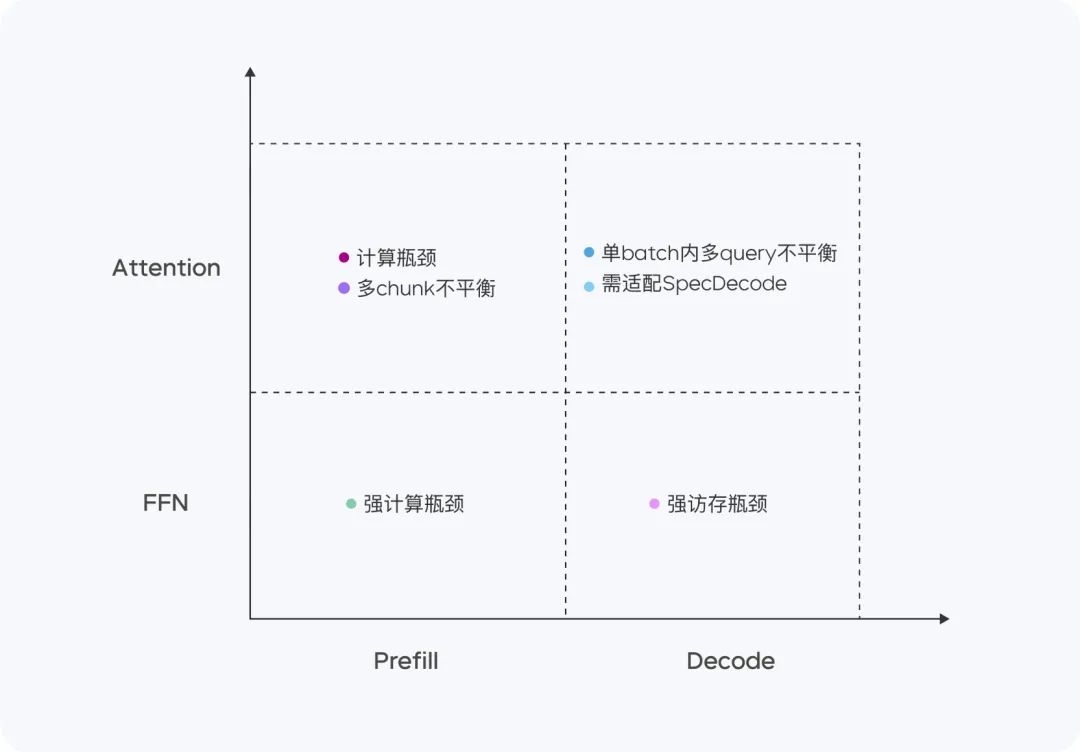
Dans la phase de préremplissage, le goulot d'étranglement de la communication et de l'accès n'est pas évident, mais le goulot d'étranglement du calcul est facilement atteint. Compte tenu des caractéristiques de l'attention unidirectionnelle LLM, nous effectuons le pré-remplissage Chunk-PP sur plusieurs dispositifs avec des ratios d'accès au calcul élevés, de sorte que le taux d'utilisation du Tensor Core dans le système en ligne est proche de 60%.
- Prefill Attention : Extension de l'implémentation open source FlashAttention 8-bit avec des instructions telles que MMA/WGMMA, combinées avec Per N jetons La stratégie de quantification par séquence garantit que cette phase peut être exécutée sans perte sur des GPU d'architectures différentes. Par ailleurs, en modélisant la consommation d'attention des tranches de différentes longueurs et en la combinant avec la stratégie dynamique de mise en lots des requêtes croisées, il est possible d'équilibrer les cartes entre elles pendant le service Chunk-PP, ce qui permet d'éliminer efficacement le fonctionnement à vide causé par le déséquilibre de la charge ;
- Prefill FFN : la quantification W4A8 réduit efficacement la surcharge d'accès des experts MoE peu nombreux et fournit davantage d'entrées à l'étape FFN grâce à la stratégie de mise en lots des requêtes croisées, ce qui améliore l'UFM à 0,8.
Dans la phase de décodage, le goulot d'étranglement informatique n'est pas évident, mais les exigences en matière de communication et de mémoire sont relativement élevées. Nous utilisons Serving, un dispositif à faible capacité de calcul et de mémoire, pour obtenir un retour sur investissement plus élevé, et en même temps, nous utilisons un échantillonnage à très faible coût et une stratégie de décodage spéculatif pour réduire la métrique TPOT.
- Décoder l'attention : TP est déployé pour optimiser le scénario courant de grandes différences dans les longueurs de KV de différentes requêtes au sein d'un même lot au moyen d'une recherche heuristique et d'une stratégie agressive de fractionnement des phrases longues ; en termes de précision, la quantification Per N tokens Per Sequence est toujours adoptée ; en outre, le calcul de l'attention pendant l'échantillonnage aléatoire est optimisé pour garantir que le cache de KV n'est consulté qu'une seule fois. En outre, nous optimisons le calcul de l'attention pendant le processus d'échantillonnage aléatoire afin de garantir que le cache KV n'est consulté qu'une seule fois.
- Décoder FFN : maintenir W4A8 quantifié et déployé à l'aide d'EP.
Dans l'ensemble, nous avons mis en œuvre les optimisations suivantes sur le système de desserte séparé de la DP :
- Backend RPC personnalisé pour le transfert Tensor, et optimisation de l'efficacité du transfert Tensor sur le réseau TCP/RDMA au moyen de la copie zéro, du parallélisme multi-flux, etc., qui à son tour améliore l'efficacité du transfert KV Cache dans le cadre de la séparation PD.
- Il prend en charge l'allocation flexible et l'expansion et la contraction dynamiques des clusters Prefill et Decode, et effectue une expansion élastique HPA pour chaque rôle indépendamment afin de garantir que Prefill et Decode n'ont pas d'arithmétique redondante, et que l'allocation arithmétique des deux côtés est conforme à la structure réelle du trafic en ligne.
- Dans le cadre du calcul GPU et du pré et post-traitement CPU asynchrone, de sorte que le GPU raisonne à l'étape N lorsque le CPU lance le noyau à l'étape N + 1, pour que le GPU soit toujours plein, l'action de traitement du cadre entier du GPU raisonne sans surcharge. En outre, grâce à notre solution de grappe de serveurs auto-développée et à la prise en charge flexible des puces à faible coût, le coût du matériel est nettement inférieur à celui de la solution de l'industrie. Nous avons également optimisé de manière significative l'efficacité de la communication par paquets grâce à des cartes d'interface réseau personnalisées et à des protocoles de réseau développés par nos soins. Au niveau arithmétique, nous réalisons un chevauchement efficace (Overlap) entre le calcul et la communication, garantissant ainsi la stabilité et l'efficacité du raisonnement distribué sur plusieurs ordinateurs.
🎯 Étiquetage des données : pas de raccourcis
- Construire un système de production de données efficace qui combine Équipe d'étiquetage répondre en chantant Modélisation des techniques d'auto-levageLa qualité des données a été considérablement améliorée.
🖼️ Capacités multimodales
Multimodalité visuelle : des scènes complexes rendues faciles
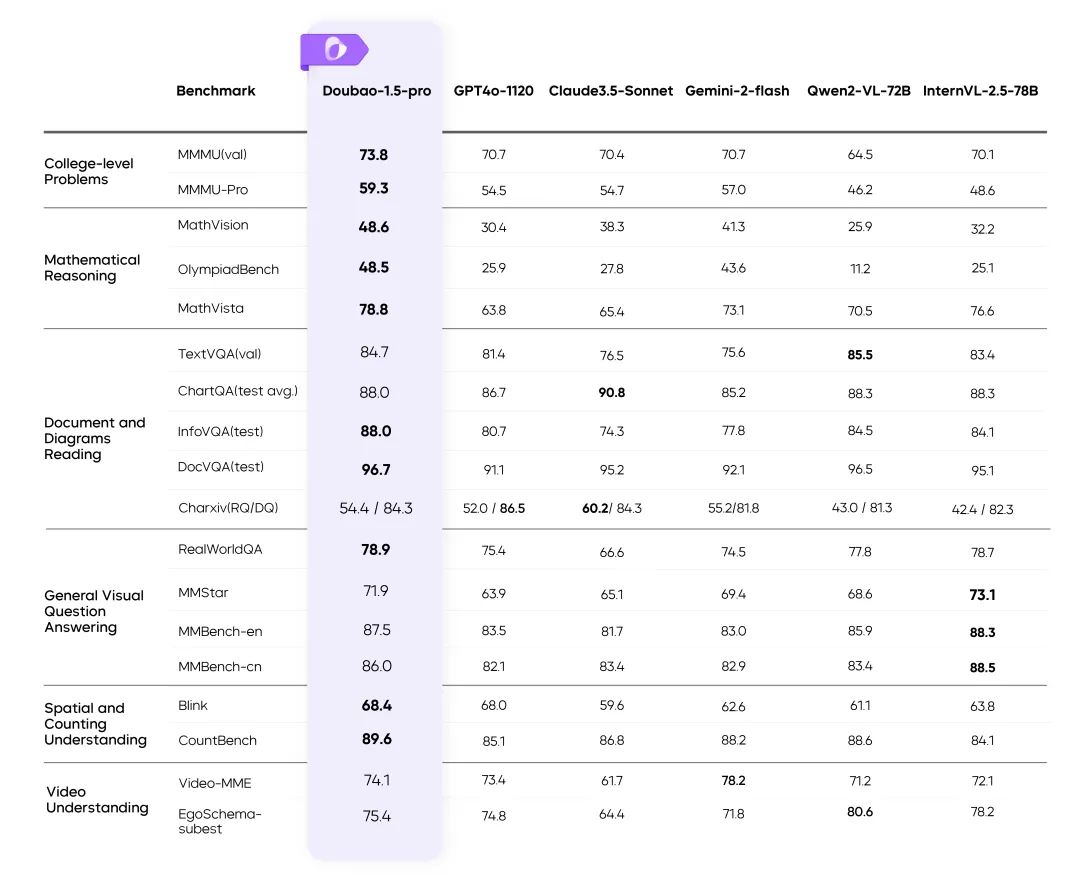
Formation à la résolution dynamique : amélioration du débit 60%
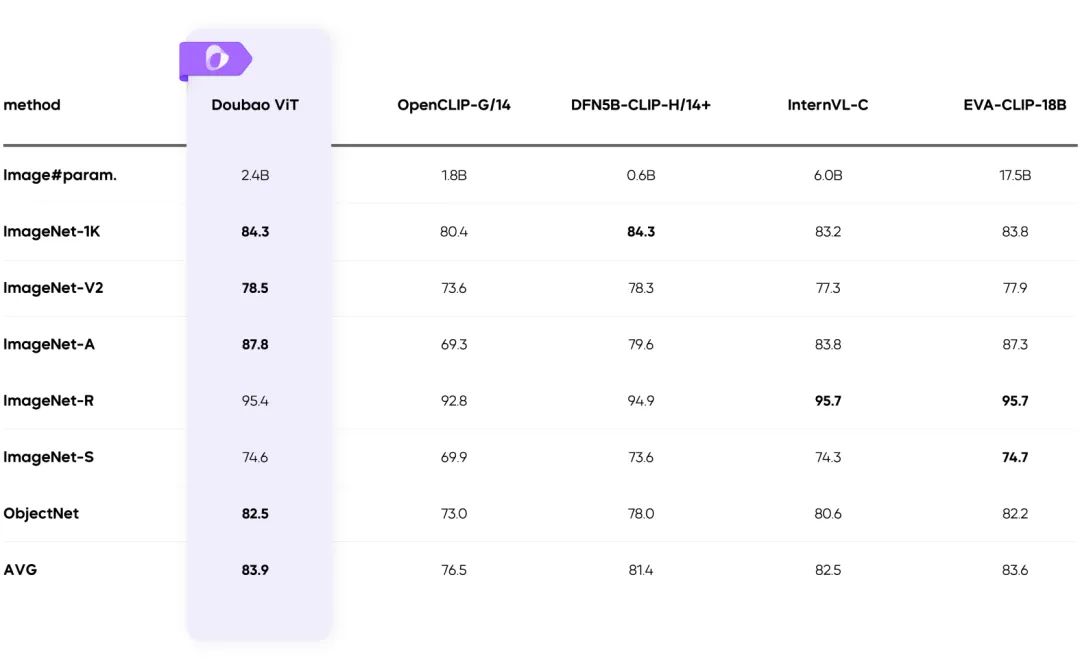
- Résoudre le problème de la charge inégale de l'encodeur visuel et améliorer l'efficacité de manière significative.
✅ Résumé
Doubao-1.5-pro trouve l'équilibre optimal entre des performances élevées et un faible coût d'inférence, et réalise des percées dans les scénarios multimodaux :
- Conception innovante d'une architecture éparse.
- Des données de formation et des systèmes d'optimisation de haute qualité.
- Une nouvelle référence en matière de technologie multimodale.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...