
Un article clair Distillation des connaissances (Distillation) : le "petit modèle" peut aussi avoir une "grande sagesse".
La distillation des connaissances est une technique d'apprentissage automatique qui vise à transférer l'apprentissage d'un grand modèle pré-entraîné (c'est-à-dire un "modèle enseignant") à un "modèle étudiant" plus petit. Les techniques de distillation peuvent nous aider à développer des modèles génératifs plus légers à utiliser dans des domaines tels que le dialogue intelligent et la création de contenu.
le plus proche (des lieux) Distillation Ce mot est très fréquent.
L'équipe DeepSeek, qui a fait parler d'elle il y a deux jours, a publié le rapport de l'équipe DeepSeek. Profondeur de l'eau-R1dont le grand modèle de 670B paramètres a été transféré avec succès vers un modèle léger de 7B paramètres grâce à des techniques d'apprentissage par renforcement et de distillation.
Le modèle distillé surpasse les modèles traditionnels de même taille et se rapproche même du meilleur petit modèle d'OpenAI, OpenAI-o1-mini.
Dans le domaine de l'intelligence artificielle, les grands modèles linguistiques (par exemple, GPT-4, Profondeur de l'eau-R1 ) a démontré d'excellentes capacités de raisonnement et de génération avec des centaines de milliards de paramètres. Toutefois, ses énormes exigences en matière de calcul et ses coûts de déploiement élevés limitent considérablement son application dans des scénarios tels que les appareils mobiles et l'informatique périphérique.
Comment compresser la taille d'un modèle sans perdre en performance ?Distillation des connaissances(Distillation des connaissances) est une technique clé pour résoudre ce problème.
1) Qu'est-ce que la distillation des connaissances ?
La distillation des connaissances est une technique d'apprentissage automatique qui vise à transférer l'apprentissage d'un grand modèle pré-entraîné (c'est-à-dire un "modèle enseignant") à un "modèle étudiant" plus petit.
Dans l'apprentissage profond, il est utilisé comme une forme de compression de modèle et de transfert de connaissances, en particulier pour les réseaux neuronaux profonds à grande échelle.
L'essence de la distillation des connaissances est la suivantela migration des connaissancesqui imite la distribution de sortie du modèle de l'enseignant, de sorte que le modèle de l'élève hérite de sa capacité de généralisation et de sa logique de raisonnement.
- Modèle d'enseignant(modèle de l'enseignant) : il s'agit généralement d'un modèle complexe doté d'un grand nombre de paramètres et d'un entraînement suffisant (par exemple, DeepSeek-R1), dont la sortie contient non seulement les résultats de la prédiction, mais aussi, de manière implicite, les informations relatives à la similarité entre les catégories.
- Modèles d'étudiants(Student Model : un petit modèle compact avec moins de paramètres qui permet le transfert de compétences en correspondant aux Soft Targets du modèle de l'enseignant.
Contrairement à l'apprentissage profond traditionnel, où l'objectif est de former un réseau neuronal artificiel pour faire des prédictions qui ressemblent davantage aux sorties de l'échantillon fournies dans l'ensemble de données de formation, la distillation des connaissances exige que le modèle de l'étudiant ne corresponde pas seulement à la bonne réponse (un objectif difficile), mais qu'il apprenne également la "logique de la pensée" du modèle de l'enseignant. -En d'autres termes, la sortie du modèle de l'enseignant doit correspondre à la bonne réponse (objectif difficile à atteindre).distribution de probabilité(cible molle).
Par exemple, dans la tâche de classification d'images, le modèle de l'enseignant n'indiquera pas seulement "cette image est un chat" (confiance 90%), mais donnera également des possibilités telles que "cela ressemble à un renard" (5%), "d'autres animaux "(5%) et d'autres possibilités.
En saisissant les corrélations (par exemple, les chats et les renards ont des oreilles pointues et des caractéristiques de poils similaires), le modèle de l'étudiant finira par apprendre à être plus flexible dans sa capacité de discrimination plutôt que de mémoriser mécaniquement des réponses standard.
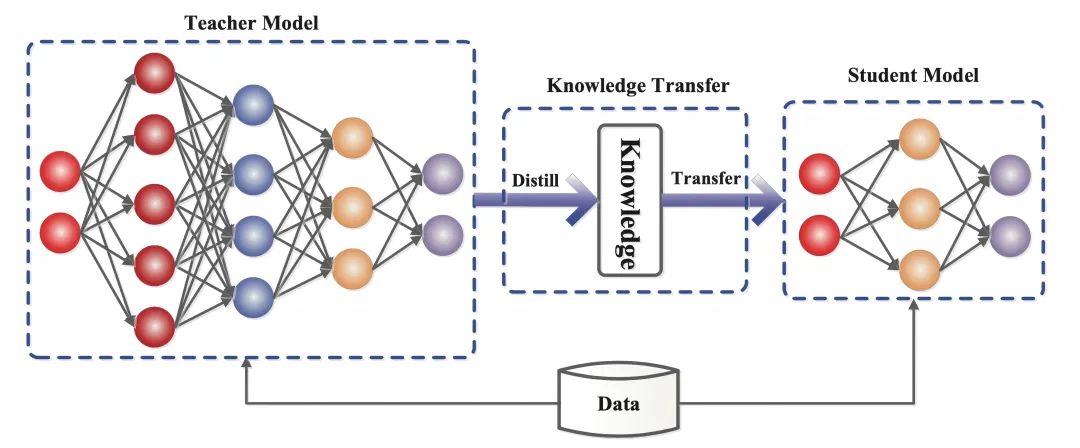
2. connaissance du fonctionnement de la distillation
Dans l'article de 2015 intitulé "Distilling the Knowledge in a Neural Network", qui propose de diviser la formation en deux étapes ayant des objectifs différents, les auteurs établissent une analogie : alors que la forme larvaire de nombreux insectes est optimisée pour extraire de l'énergie et des nutriments de l'environnement, la forme adulte est complètement différente, optimisée pour voyager et se reproduire, alors que l'apprentissage profond traditionnel utilise les mêmes modèles dans les phases de formation et de déploiement, même s'ils ont des exigences différentes.
L'interprétation du terme "connaissance" dans les documents varie également :
Avant la publication de l'article, on avait tendance à assimiler les connaissances du modèle de formation aux valeurs des paramètres appris, ce qui rendait difficile de voir comment les mêmes connaissances pouvaient être maintenues en changeant la forme du modèle.
Une vision plus abstraite de la connaissance est qu'il s'agit d'un apprentissage.Correspondance entre le vecteur d'entrée et le vecteur de sortie.
Les techniques de distillation des connaissances ne se contentent pas de reproduire les résultats des modèles des enseignants, mais imitent également leurs "processus de pensée". À l'ère des LLM, la distillation des connaissances permet de transférer des qualités abstraites telles que le style, la capacité de raisonnement et l'alignement sur les préférences et les valeurs humaines.
La réalisation de la distillation des connaissances peut être décomposée en trois étapes essentielles :
2.1 Génération de cibles souples : "fuzzifier" les réponses
Le modèle de l'enseignant est transmisSoftmax haute températureLa technologie transforme les réponses "noires et blanches" en "indices flous" contenant des informations détaillées.
Lorsque la température (Température) augmente (par exemple T=20), la distribution de probabilité de la sortie du modèle est plus lisse.
Par exemple, le jugement original "Chat (90%), Renard (5%)"
Peut devenir "Chat (60%), Renard (20%), Autre (20%)".
Cet ajustement oblige les modèles des élèves à se concentrer sur les corrélations entre les catégories (par exemple, les chats et les renards ont des oreilles de forme similaire) plutôt que sur la mémorisation mécanique des étiquettes.
2.2 Conception de la fonction objective : équilibrer les objectifs doux et durs
Les objectifs d'apprentissage du modèle de l'étudiant sont doubles :
- Imiter la logique de la pensée de l'enseignant(Cible molle) : apprendre les relations entre les classes en faisant correspondre les distributions de probabilités à haute température des enseignants.
- Souvenez-vous de la bonne réponse.(Objectif difficile) : veiller à ce qu'il n'y ait pas de baisse de la précision de base.
La fonction de perte du modèle de l'élève est une combinaison pondérée de cibles douces et dures, et les poids des deux doivent être ajustés de manière dynamique.
Par exemple, en attribuant des pondérations de 70% aux cibles souples et de 30% aux cibles difficiles, cela revient à ce que les élèves passent 70% à étudier les solutions de l'enseignant et 30% à consolider les réponses standard, pour finalement parvenir à un équilibre entre flexibilité et précision.
2.3 Régulation dynamique des paramètres de température, contrôle de la "granularité de transfert" des connaissances.
Le paramètre de la température est le "bouton de difficulté" de la distillation intellectuelle :
- Mode haute température(par exemple T=20) : les réponses sont très ambiguës et conviennent à la transmission d'associations complexes (par exemple la distinction entre différentes races de chats).
- mode basse température(par exemple T=1) : les réponses sont proches de la distribution originale et conviennent à des tâches simples (par exemple, la reconnaissance de chiffres).
- stratégie dynamiqueL'assimilation des connaissances : absorption extensive des connaissances avec des températures élevées dans les premiers stades et un refroidissement pour se concentrer sur les caractéristiques clés dans les stades ultérieurs.
Par exemple, les tâches de reconnaissance vocale nécessitent des températures plus basses pour maintenir la précision. Ce processus est similaire à celui d'un enseignant qui adapte la profondeur de l'enseignement au niveau de l'élève, de l'heuristique à la passation de tests.
3. l'importance de la distillation des connaissances
Les modèles les plus performants pour une tâche donnée sont généralement trop volumineux, trop lents ou trop coûteux pour la plupart des cas d'utilisation réels, mais leurs excellentes performances sont dues à leur taille et à leur capacité à effectuer un pré-entraînement sur de grandes quantités de données d'entraînement.
En revanche, les petits modèles, bien que plus rapides et moins exigeants en termes de calcul, sont moins précis, moins affinés et moins bien informés que les grands modèles comportant davantage de paramètres.
C'est là que la valeur de l'application de la distillation des connaissances entre en jeu, par exemple :
Le grand modèle de 670B-paramètres de DeepSeek-R1 migre ses capacités vers un modèle léger de 7B-paramètres grâce à une technique de distillation des connaissances : DeepSeek-R1-7B, qui surpasse les modèles de non-inférence tels que GPT-4o-0513 à tous les égards.DeepSeek-R1-14B surpasse le QwQ-32BPreview dans toutes les mesures d'évaluation, tandis que les modèles DeepSeek-R1-32B et DeepSeek-R1-70B surpassent considérablement o1-mini dans la plupart des repères. DeepSeek-R1-32B et DeepSeek-R1-70B sont nettement plus performants que o1-mini dans la plupart des repères.
Ces résultats démontrent le fort potentiel de la distillation. La distillation des connaissances est devenue un outil technique important.
Dans le domaine du traitement du langage naturel, de nombreux instituts de recherche et entreprises utilisent des techniques de distillation pour compresser de grands modèles de langage en versions plus petites pour des tâches telles que la traduction, les systèmes de dialogue et la classification de textes.
Par exemple, les grands modèles, une fois distillés, peuvent être exécutés sur des appareils mobiles pour fournir des services de traduction en temps réel sans dépendre de puissantes ressources informatiques en nuage.
La valeur de la distillation des connaissances est encore plus importante dans l'IdO et l'informatique périphérique. Alors que les grands modèles traditionnels nécessitent souvent le soutien de puissants clusters GPU, les petits modèles sont distillés pour pouvoir être exécutés sur des microprocesseurs ou des dispositifs embarqués avec une consommation d'énergie beaucoup plus faible.
Cette technologie permet non seulement de réduire considérablement les coûts de déploiement, mais aussi de généraliser l'utilisation des systèmes intelligents dans des domaines tels que les soins de santé, la conduite autonome et les maisons intelligentes.
À l'avenir, le potentiel d'application de la distillation des connaissances sera encore plus large. Avec le développement de l'IA générative, la technologie de distillation peut nous aider à développer des modèles génératifs plus légers pour le dialogue intelligent, la création de contenu et d'autres domaines.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...