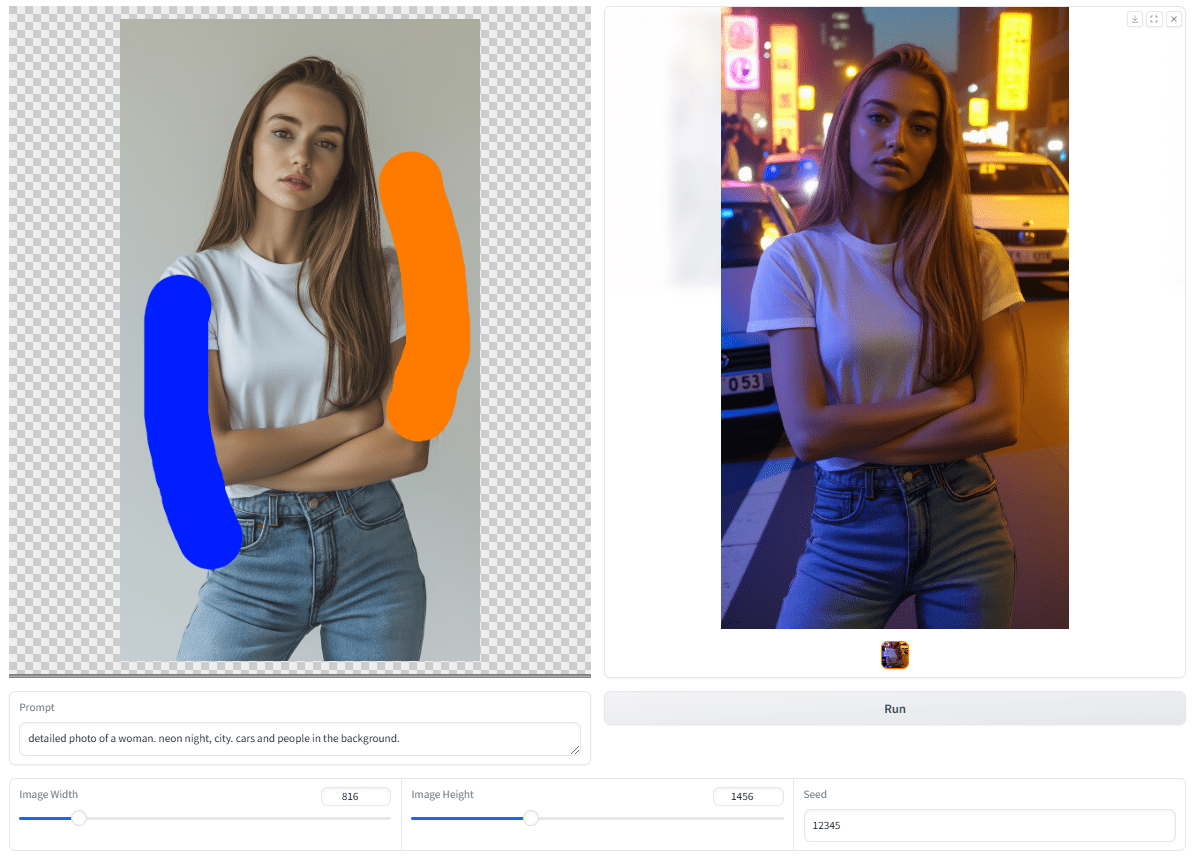
DINOv3 - Modèle de base de vision auto-supervisée de nouvelle génération de Meta AI
Qu'est-ce que DINOv3 ?
DINOv3 Oui Meta AI DINOv3 est une nouvelle génération de modèle de base de vision auto-supervisée, qui adopte le paradigme de l'apprentissage auto-supervisé pour apprendre les caractéristiques des images sans données d'étiquetage. En améliorant la préparation des données et en introduisant l'ancrage Gram, le problème de la dégradation des caractéristiques est résolu et la capacité de généralisation est améliorée. DINOv3 fournit deux architectures de réseau de base, ViT et ConvNeXt, dont ViT-7B est la version la plus importante à l'heure actuelle, contenant 6,7 milliards de paramètres. Le modèle peut générer des représentations denses de haute qualité qui capturent avec précision les relations locales et les informations spatiales des images. Il donne de bons résultats dans un large éventail de tâches visuelles telles que la classification d'images, la détection de cibles, la segmentation sémantique, etc., et peut surpasser de nombreux modèles professionnels sans réglage fin spécifique à la tâche.DINOv3 prend en charge l'extraction de caractéristiques à haute résolution, ce qui convient à l'analyse d'images médicales, à la surveillance de l'environnement et à d'autres scénarios qui nécessitent des caractéristiques de haute précision.
Caractéristiques de DINOv3
- Capacité d'apprentissage auto-superviséLe modèle peut apprendre des caractéristiques d'image sans données étiquetées et il résout le problème de la dégradation des caractéristiques lors de l'apprentissage à long terme en améliorant la préparation des données et en introduisant l'ancrage de Gram, ce qui améliore la capacité de généralisation du modèle.
- Architectures de réseaux dorsaux multiplesLe ViT-7B est la version la plus importante à ce jour, avec 6,7 milliards de paramètres.
- Représentation de haute qualité des caractéristiquesIl peut générer des représentations denses de haute qualité qui capturent avec précision les relations locales et les informations spatiales des images pour un large éventail de tâches visuelles.
- Polyvalence multitâcheLa méthode : donne de bons résultats dans des tâches telles que la classification d'images, la détection de cibles, la segmentation sémantique, etc., surpassant de nombreux modèles professionnels sans ajustement spécifique à la tâche et réduisant de manière significative les coûts d'inférence.
- Extraction de caractéristiques à haute résolutionLa technologie de l'extraction de caractéristiques à haute résolution permet d'extraire des caractéristiques de haute précision dans des scénarios tels que l'analyse d'images médicales et la surveillance de l'environnement.
Principaux avantages de DINOv3
- Apprentissage autosupervisé performantIl ne nécessite pas une grande quantité de données étiquetées et permet un apprentissage efficace grâce à un mécanisme innovant d'auto-supervision, qui résout le problème de la dégradation des caractéristiques et améliore la capacité de généralisation du modèle.
- Options d'architecture flexiblesLes architectures de réseaux dorsaux ViT et ConvNeXt sont disponibles pour répondre aux différentes exigences en matière de ressources informatiques et de tâches, en équilibrant les performances et l'efficacité.
- Représentation de haute qualité des caractéristiquesLes caractéristiques générées capturent avec précision les relations locales et les informations spatiales de l'image, et conviennent à un large éventail de tâches visuelles avec d'excellentes performances.
- Polyvalence multitâcheLes modèles professionnels sont plus performants que les modèles professionnels sans ajustement spécifique dans des tâches telles que la classification d'images, la détection de cibles, la segmentation sémantique, etc.
- Extraction de caractéristiques à haute résolutionIl permet l'extraction de caractéristiques à haute résolution et convient à l'analyse d'images médicales, à la surveillance de l'environnement et à d'autres scénarios exigeant une grande précision.
- Source ouverte et facilité d'utilisationLes avantages : code et modèles open source, prise en charge des bibliothèques Hugging Face Hub et Transformers, facilité de prise en main et de développement d'applications.
Quel est le site web officiel de DINOv3 ?
- Site web du projet: : https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
- Bibliothèque de modèles HuggingFace: : https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- Documents techniques: : https://ai.meta.com/research/publications/dinov3/
À qui s'adresse DINOv3
- Chercheurs en vision artificielleDINOv3 offre de puissantes capacités d'apprentissage auto-supervisé et des représentations de caractéristiques de haute qualité adaptées aux professionnels engagés dans la recherche sur des tâches visuelles telles que la classification d'images, la détection de cibles et la segmentation sémantique.
- Développeur Deep LearningDINOv3 : Le code source ouvert et les modèles pré-entraînés font de DINOv3 la solution idéale pour les développeurs d'apprentissage profond afin de créer et de déployer rapidement des applications de vision pour des scénarios qui nécessitent un développement et une optimisation efficaces.
- Spécialiste en imagerie médicale: La capacité d'extraction de caractéristiques à haute résolution présente un grand potentiel dans le domaine de l'analyse d'images médicales pour les tâches de diagnostic médical qui nécessitent des caractéristiques de haute précision, telles que l'analyse des rayons X, de la tomodensitométrie et de l'IRM.
- Praticiens de la surveillance de l'environnement et des systèmes d'information géographique (SIG)DINOv3 peut être utilisé pour des tâches de surveillance de l'environnement telles que l'analyse d'images satellites et la surveillance de la déforestation, fournissant ainsi un soutien technique pour les travaux liés aux SIG.
- Ingénieur en vision robotiqueLes caractéristiques de vision de haute précision et la polyvalence multi-tâches du DINOv3 en font un outil idéal pour les systèmes de vision robotique destinés à des tâches de perception visuelle dans des environnements complexes, tels que les robots d'exploration de la planète Mars.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...