
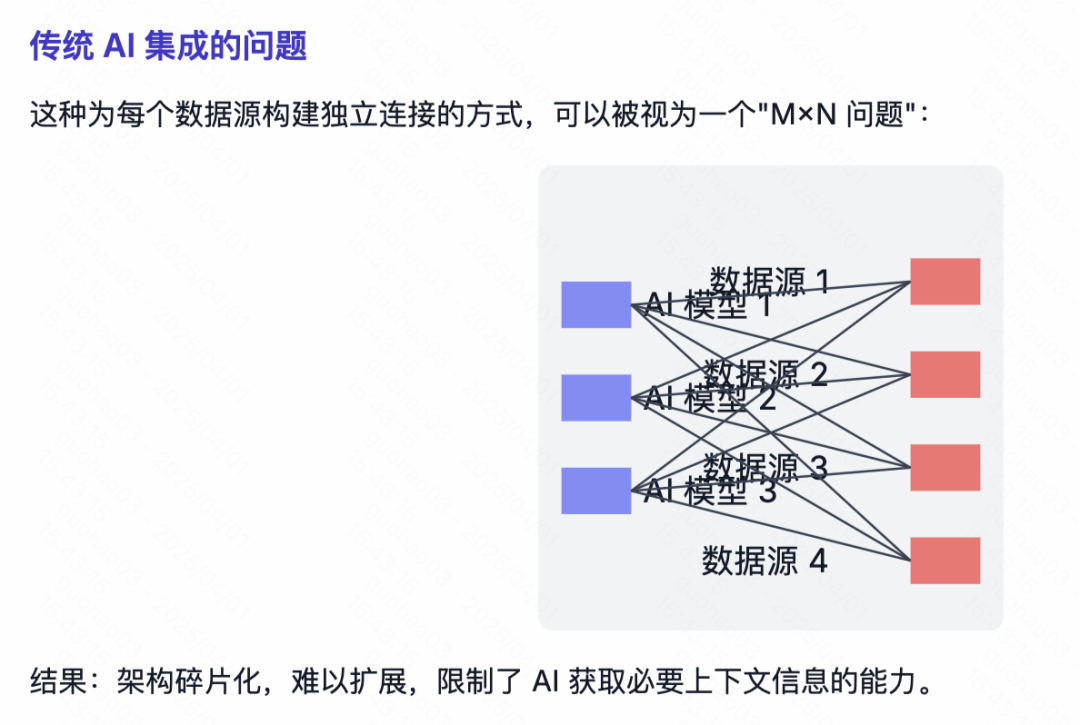
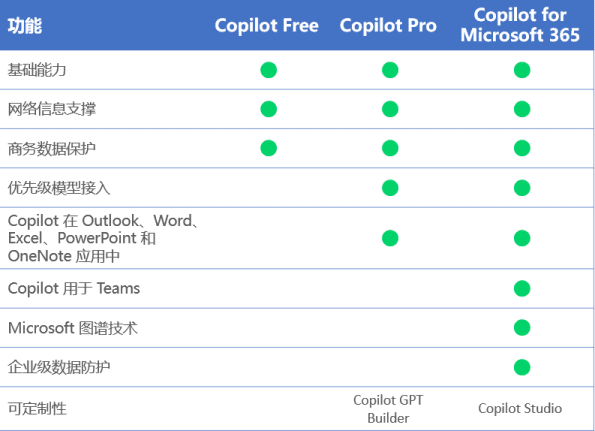
Dify développe la visualisation de données privées et l'intelligence analytique
La technologie de l'intelligence artificielle continue d'évoluer et les applications de chat deviennent de plus en plus riches en fonctionnalités. Récemment, la plateforme Dify a lancé une mise à jour importante : sa nouvelle application de chat peut directement mettre en œuvre l'analyse visuelle des données dans le dialogue, offrant ainsi aux utilisateurs une expérience de communication plus intuitive et plus efficace. Bien que le titre de l'article mentionne que la fonction est "aussi efficace que ChatGPT", il y a encore une lacune dans l'application réelle, qui est plus axée sur la démonstration de la technologie et l'exploration de la fonction. L'article manque d'explications sur le principe, lecture recommandée Les flux de travail Dify et les assistants intelligents IA réinventent le modèle d'adoption des données d'entreprise .
La solution de visualisation de données de ChatGPT
En ce qui concerne la visualisation des données, certains produits d'IA de premier plan, tels que ChatGPT, ont été activement étudiés. La solution de visualisation de données de ChatGPT convertit également les commandes de l'utilisateur en code Python, qui est exécuté en arrière-plan et affiché au premier plan. Toutefois, le diagramme circulaire généré par ChatGPT présente des problèmes de compatibilité avec l'affichage en chinois.

Solution de visualisation des données de Dify pour les plates-formes Low-Code
Dify La plateforme adopte une approche différente en tirant parti de sa nature "low-code", qui permet aux utilisateurs de créer rapidement des applications de chat avec des capacités de visualisation de données sans écrire de code complexe.
sur la base de ChatGPT La plateforme Dify propose une solution simple : ajuster la commande de code Pandas précédemment utilisée pour générer directement le code Pyecharts, l'exécuter en arrière-plan dans un environnement sandbox, et obtenir les images ou les fichiers HTML générés. Il s'agit d'une méthode relativement simple à mettre en œuvre.
Cependant, cet article se concentre sur Dify, une plateforme de conception de corps intelligents à code bas, pour montrer à quel point il est facile de visualiser les données, et nous continuerons donc à optimiser nos conceptions de flux de travail précédentes pour tirer pleinement parti des outils intégrés de Dify.

La plateforme Dify dispose d'outils intégrés de génération de graphiques qui prennent en charge les diagrammes circulaires, les diagrammes à barres, les graphiques linéaires et d'autres types de graphiques. Les utilisateurs peuvent comprendre intuitivement les paramètres requis pour ces trois outils de création de graphiques, qui sont tous sous forme de chaînes et dans le même format.

Optimisation du flux de travail : conversion des formats de données
Afin de faire correspondre le résultat du flux de travail aux paramètres requis par l'outil graphique Dify, le flux de travail doit être optimisé.
Les données JSON suivantes sont un exemple de la sortie du flux de travail du tutoriel précédent, et sont dans un format qui ne peut pas être utilisé directement dans l'outil graphique de Dify.
{"status": "success", "data_result": {"学校": 2, "互联网": 1, "物流": 1, "硬件": 1, "教育机构": 1, "传统零售": 1, "传统媒体": 1, "制造业": 1}}
Ici, vous avez choisi d'utiliser du code Python pour la conversion du format des données et, pour ce faire, vous devez ajouter un nœud d'exécution de code au flux de travail et le remplir avec le code Python approprié.

Ce code Python peut être généré à l'aide du Big Language Model, le générateur de code intégré à la plateforme Dify, qui ne nécessite qu'une description claire des besoins. Voici un exemple des invites utilisées pour générer le code.
{"status": "success", "data_result": {"学校": 2, "互联网": 1, "物流": 1, "硬件": 1, "教育机构": 1, "传统零售": 1, "传统媒体": 1, "制造业": 1}} 边写一段Pytho函数代码,,接受json输入,将data_result的所有key值拼接为一个字符串,每个key之间用 ";" 分隔,赋值到变量exl_ key,将data_result的所有value值拼接为一个字符串,每个value之间用 ";" 分隔,赋值到变量exl_value,将exl_key exl_value返回

Le code généré directement par le générateur de code Dify présente quelques problèmes mineurs. Par exemple, le résultat obtenu ne contient qu'une seule variable, alors que l'outil de diagramme circulaire de Dify en requiert deux. Par conséquent, le code généré doit être modifié pour s'assurer que la variable return renvoie un résultat de type dictionnaire (dict).
import json
def main(data: dict) -> dict:
data = json.loads(data)
exl_key = ";".join(data["data_result"].keys())
exl_value = ";".join(map(str, data["data_result"].values()))
return {'exl_key': exl_key, 'exl_value': exl_value}
Il existe un problème potentiel avec le code ci-dessus, si le format des données générées par le grand modèle ne correspond pas au format attendu. {key: value, key: value} l'exécution du code signalera une erreur. Cette question sera examinée dans un article ultérieur, cet article se concentre d'abord sur la mise en œuvre de la fonctionnalité.
En outre, le format des variables d'entrée reçues par le nœud d'exécution du code est également sujet à des erreurs. L'entrée par défaut est une chaîne de caractères, ce qui nécessite l'utilisation de l'attribut json pour effectuer une conversion de type forcée. Dans le cas contraire, l'erreur suivante se produira.

Fonctionnement du flux de travail et présentation des résultats
Le flux de travail peut maintenant être exécuté dans son intégralité pour voir les résultats finaux.

À ce stade, le flux de travail a été configuré avec succès pour générer des résultats sous forme de diagrammes à secteurs en fonction des besoins d'analyse de données de l'utilisateur.
Extensions du flux de travail : prise en charge de plusieurs types de graphiques
Cependant, si l'utilisateur a besoin de générer des diagrammes à barres ou des graphiques linéaires, le flux de travail actuel doit être étendu.
L'idée d'optimisation est la suivante : premièrement, un nœud "Extraction de paramètres" doit être ajouté pour que le grand modèle puisse identifier le besoin de visualisation des graphiques, tels que les graphiques à secteurs ou à barres, à partir des commandes de l'utilisateur. Deuxièmement, un nœud de "branchement conditionnel" doit être ajouté entre les nœuds de traitement des données et de visualisation des diagrammes circulaires, afin que différents chemins de branchement puissent être sélectionnés en fonction des résultats de l'extraction des paramètres. La conception finale du flux de travail est illustrée dans la figure ci-dessous.

Nous décrivons ci-dessous en détail comment configurer l'extracteur de paramètres. Comme vous pouvez le voir dans l'interface de configuration, celle-ci contient les trois aspects principaux suivants :
- variable d'entrée: Spécifie que le grand modèle extrait les paramètres du texte de la commande de l'utilisateur.
- paramètre d'extraction: Définit les paramètres à extraire, c'est-à-dire si l'instruction de l'utilisateur contient des informations de type graphique. Si des informations pertinentes sont extraites, elles sont affectées à une nouvelle variable
exl_type. - directives: mots repères envoyés par l'extracteur de paramètres au grand modèle. La tâche d'extraction des paramètres est relativement simple pour les grands modèles.

De cette manière, les nœuds de "branchement conditionnel" suivants seront modélisés par le modèle plus large sur la base des paramètres extraits. exl_type Le nœud "Branchement conditionnel" semble complexe, mais le principe est simple. Le nœud "Branchement conditionnel" semble complexe, mais le principe est simple : en fonction du type de graphique produit par le grand modèle, sélectionnez la branche correspondante pour générer le graphique correspondant.

Ensuite, nous démontrons le fonctionnement de l'ensemble du flux de travail. Les résultats obtenus sont satisfaisants, ce qui indique que le flux de travail peut être appliqué à l'application Big Model Chat.

Publication des flux de travail en tant qu'outils Dify et intégration dans les applications des agents
Afin d'intégrer ce flux de travail dans Dify, vous devez d'abord le publier en tant qu'outil intégré à Dify. Dans l'interface du flux de travail, cliquez sur le bouton Publier dans le coin supérieur droit et sélectionnez Publier en tant qu'outil.

Remarque : il s'agit d'une étape cruciale. En règle générale, le format des paramètres des flux de travail publiés en tant qu'outils doit être défini comme suit text-input type. Ce n'est qu'à ce moment-là, dans une application Dify Agent, que le grand modèle appellera correctement l'outil via un appel de fonction. Dans le cas contraire, le grand modèle ignorera l'outil. Il est donc important d'ajuster les variables d'entrée du flux de travail comme indiqué dans la figure suivante text-input avant de le publier en tant qu'outil.

Une fois que vous avez terminé les étapes ci-dessus, vous pouvez intégrer le flux de travail d'analyse des données dans Dify en tant qu'appel de fonction. Ensuite, créez une application Agent dans Dify. Si vous n'êtes pas familier avec l'application Agent, vous pouvez d'abord suivre les étapes, puis nous comprendrons son principe et son application étape par étape. Ensuite, j'écrirai un article pour comparer les différences entre les différents types d'applications dans Dify.

Ensuite, il suffit d'ajouter l'outil publié à l'application Agent. À ce stade, la configuration est terminée. Prévisualisez et déboguez directement pour voir le résultat final.

Grâce à ces étapes, la plateforme Dify intègre avec succès des applications de chat avec des fonctions de visualisation de données, offrant ainsi aux utilisateurs une toute nouvelle expérience interactive. Grâce aux fonctions à code bas de Dify, les utilisateurs peuvent rapidement créer des applications puissantes et intelligentes et profiter de la commodité de la technologie de l'IA sans avoir besoin d'un codage approfondi.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...