
Mise à jour du modèle DeepSeek-V3 à profil bas, la capacité de codage passe à Claude-3.7

La concurrence dans le secteur des technologies ne cesse de s'intensifier. Récemment, l'équipe de la startup chinoise DeepSeek, spécialisée dans l'IA, a mis à jour son modèle de base V3 de manière discrète et sans grande publicité. DeepSeek-V3-0324 a été discrètement mise en ligne sur la plateforme Hugging Face pour que les développeurs puissent la télécharger et la déployer. Malgré la discrétion de cette mise à jour, les améliorations significatives du nouveau modèle en termes de capacité de codage ont rapidement suscité beaucoup d'intérêt et de vives discussions au sein de la communauté technique.
Il y a quelques heures, DeepSeek-AI a ouvert une version mise à jour de DeepSeekV3, la version 0324, téléchargée sur HuggingFace le 24 mars 2025 et ouverte à l'aide du protocole du MIT.
Les informations relatives à la configuration du modèle montrent que DeepSeekV3-0324 reste un grand modèle MoE, contenant 256 experts en routage et 1 expert partagé pour chaque jeton Utilise 8 experts pour l'inférence. DeepSeekV3-0324 s'adapte à une longueur de contexte maximale de 163840 (160K) via RoPE. La taille du vocabulaire du modèle est de 129280 et intègre le mécanisme LoRA pour prendre en charge un réglage fin léger.
Aucun de ces paramètres n'a changé depuis la sortie de DeepSeekV3 le 26 décembre 2024, ce qui signifie que cette mise à jour est très probablement le résultat d'un entraînement continu ou d'un post-entraînement du modèle original.
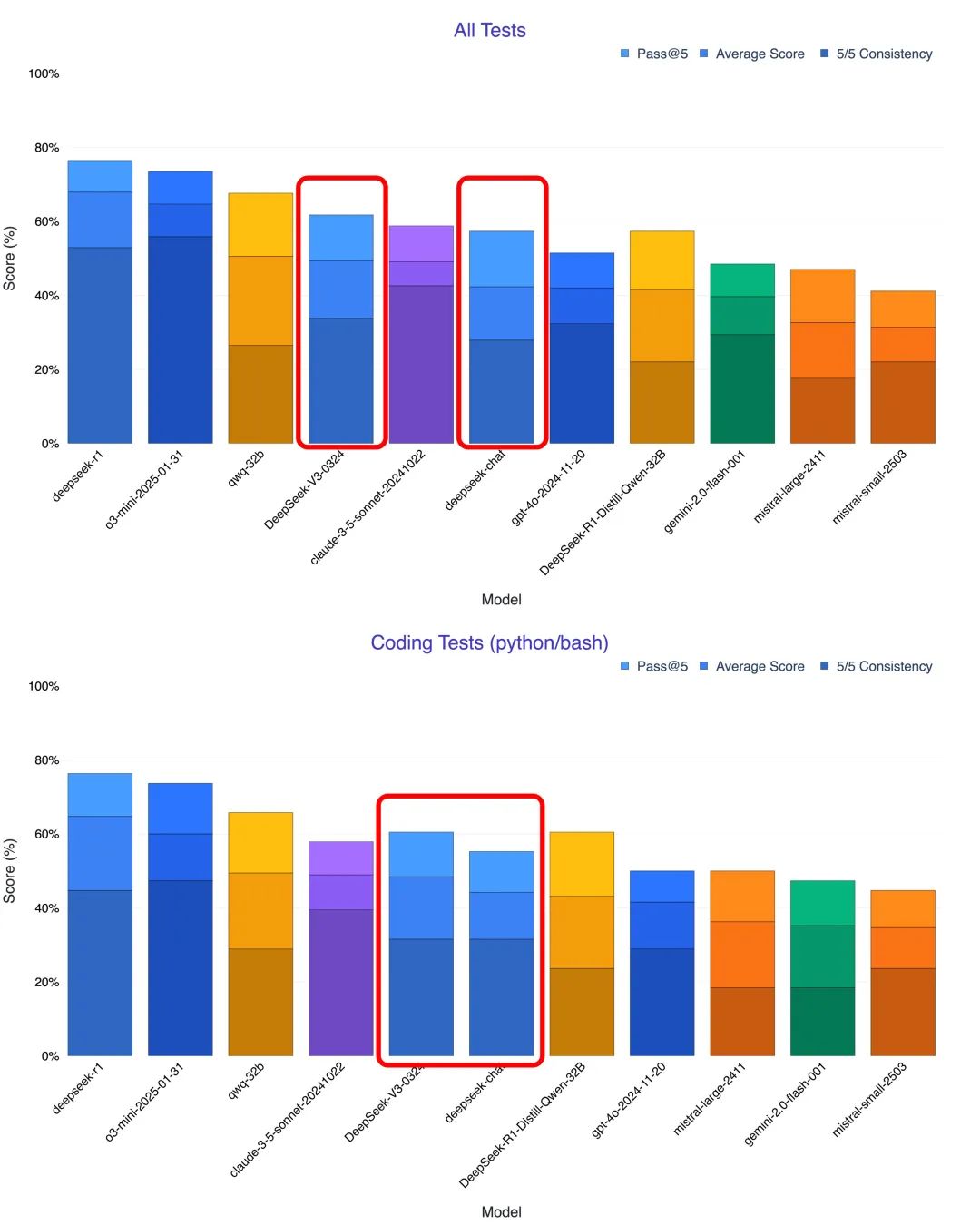
Les capacités de codage sont montées en flèche pour atteindre des niveaux de référence proches de ceux de la source.
Les premières impressions des utilisateurs et les tests multiples indiquent que l'amélioration la plus frappante de DeepSeek-V3-0324 réside dans ses capacités de génération et de compréhension de code. De nombreux testeurs ont noté que dans des domaines tels que le raisonnement mathématique et le développement frontal, la nouvelle version est plus performante que la version précédente. Claude 3.5 et Claude 3.7 Sonnet. Le blogueur @KuittinenPetri sur la plateforme de médias sociaux X a été encore plus franc lorsqu'il a déclaré que DeepSeek-V3-0324 permet de créer facilement et gratuitement de beaux codes HTML5, CSS et front-end, ce qui est excellent pour l'entreprise. Anthropique et l'OpenAI posent de nouveaux défis.
Par exemple, avec une simple commande, DeepSeek-V3-0324 a été en mesure de générer une page d'accueil responsive très attrayante pour une société d'IA appelée NexusAI, en intégrant tous les éléments dans un seul fichier HTML5. Le code résultant, de 958 lignes, a donné naissance à un site web interactif et adapté aux mobiles, qui incluait même les ressources d'images nécessaires. Selon @KuittinenPetri, DeepSeek-V3-0324 est DeepSeek Le meilleur modèle de non-inférence actuellement disponible n'est pas seulement excellent en écriture créative, mais il est maintenant encore meilleur que R1 pour générer du code HTML5 + CSS + front-end. Un autre utilisateur a également réussi à faire en sorte que DeepSeek-V3-0324 crée un site web où le modèle a généré plus de 800 lignes de code en une seule fois et où la mise en page du site était très réussie.
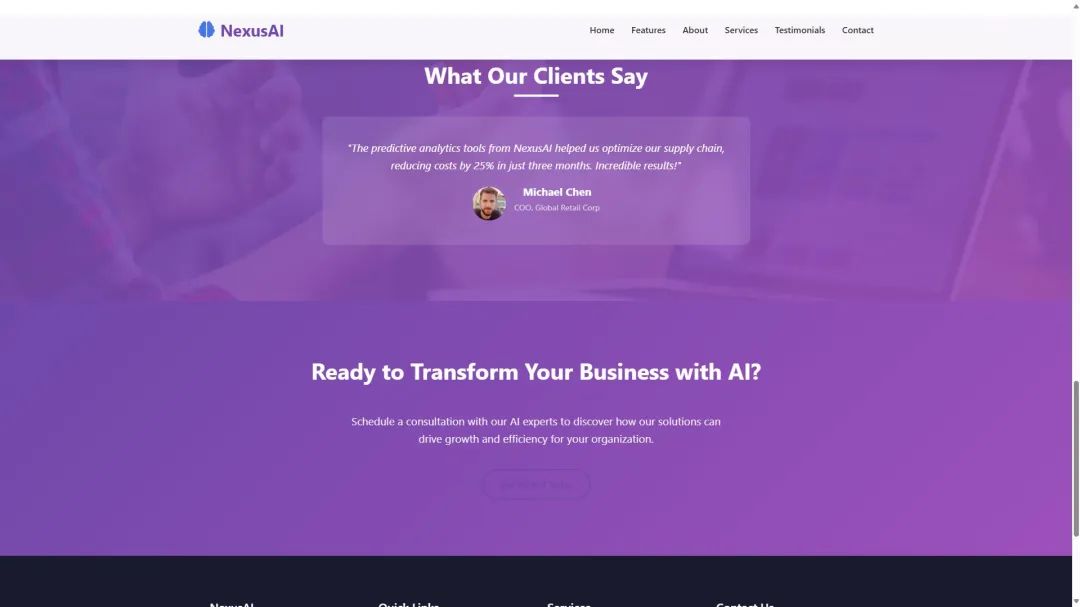
Essais multi-scénarios dans le monde réel, montrant un fort potentiel de programmation
Afin d'évaluer plus précisément les capacités de programmation de DeepSeek-V3-0324, de nombreux chercheurs ont effectué des tests avec différents scénarios et l'ont comparé à des modèles tels que l'ancienne V3, Claude 3.7 et o1 pro. Les résultats des tests ont prouvé l'amélioration significative de la nouvelle version de V3 en termes de programmation.
- Texte vers les pages de visualisation : Lors du test de conversion des descriptions textuelles en pages web interactives, DeepSeek-V3-0324 a fait un bond en avant par rapport à l'ancienne version V3. Les pages web générées par la nouvelle version sont non seulement plus riches en contenu, mais elles présentent également une interface utilisateur et une mise en page nettement améliorées, qui surpassent même la mise à niveau de Claude 3.5 à 3.7. Il est intéressant de noter que DeepSeek-V3-0324 est capable de suivre des instructions détaillées pour convertir le contenu d'un fichier PDF en une belle visualisation chinoise d'une page web, ce qui est souvent considéré comme un point fort de Claude 3.7.
- Générer une animation 3D : Lors des tests de génération de présentations 3D interactives à partir de la base de code JS, la nouvelle V3 a été en mesure de modéliser chaque étape de la fabrication du chocolat et de prendre en charge les interactions par onglets et les barres latérales. Bien que des améliorations soient encore possibles par rapport à Claude, les capacités de l'ancienne V3 ont été largement dépassées.
- Conception des composants de l'interface utilisateur : Lors du test de conception du composant d'interface utilisateur pour les prévisions météorologiques, V3-0324 a amélioré ses performances en matière d'animation et la précision de l'étiquetage du texte météorologique, ce qui montre qu'il est davantage capable de générer des interfaces utilisateur pratiques.
- Simulation du monde physique : Dans un test simulant une balle rebondissant à l'intérieur d'un hexagone en rotation, DeepSeek-V3-0324 implémente avec précision l'effet de collision de la balle. Bien qu'il y ait encore quelques défauts, les performances globales sont meilleures que celles de l'ancienne V3 et comparables à celles de l'o1 pro.
- Génération de jeux d'IA : Le plus frappant est que DeepSeek-V3-0324 génère un jeu de serpents en pixels jouable, avec des effets sonores et des modes assistés par l'IA, avec une seule phrase d'instructions. Bien qu'il ne soit pas à la hauteur du mode de pensée étendue de Claude 3.7 en termes de complexité et de perfection, le fait qu'il ait pu réaliser un jeu entièrement fonctionnel est une excellente démonstration de ses puissantes capacités de programmation.
Caractéristiques techniques et avantages en termes de coûts
DeepSeek-V3-0324 n'a pas encore publié de carte modèle détaillée, mais on sait qu'il a une taille de paramètre de 685 milliards. Il convient de noter que DeepSeek V3 utilise le modèle Modélisation experte hybride (MoE) avec 671 milliards de paramètres, dont seulement 37 milliards sont activés par inférence. (Note de l'éditeur : le modèle MoE réduit considérablement les coûts de calcul et la latence en décomposant les grands modèles en plusieurs sous-réseaux "experts", tout en maintenant les performances du modèle). Afin de résoudre le problème du déséquilibre de la charge d'experts dans le modèle traditionnel de MoE, DeepSeek propose de manière innovante dans la V3 que Stratégie d'équilibrage de la charge sans perte auxiliaire En outre, V3 ajuste dynamiquement la charge d'expertise en introduisant un "terme de biais" pour améliorer la performance du modèle et l'efficacité de la formation. En outre, V3 adopte également Mécanismes de routage en fonction des nœuds L'objectif est de réduire les coûts de communication dans le cadre d'une formation distribuée à grande échelle.
Outre ses excellentes performances, DeepSeek-V3-0324 maintient le protocole open source du MIT. Plus important encore, le prix de son API est compétitif par rapport à celui de l'API d'OpenAI. o1-pro Au moins 50 fois moins cher. Par rapport à Claude 3.7, DeepSeek v3 est environ un dixième du prix de son entrée, tandis que le prix de la sortie est environ un treizième du prix pendant les heures normales, et même un vingt-septième du prix pendant les heures spéciales. Cet avantage de prix attractif, combiné à sa nature open source, constituera sans aucun doute une forte incitation à populariser et à développer la programmation de l'IA.
Caractéristiques du modèle DeepSeek-V3-0324

DeepSeek-V3-0324 présente des améliorations significatives par rapport à son prédécesseur, DeepSeek-V3, dans plusieurs domaines clés.
- Les capacités de raisonnement sont améliorées :
- MMLU-Pro : 75,9 → 81,2 (+5,3)
- GPQA : 59,1 → 68,4 (+9,3)
- AIME : 39,6 → 59,4 (+19,8)
- LiveCodeBench : 39,2 → 49,2 (+10,0)
- Amélioration des capacités de développement de sites web frontaux :
- Amélioration de l'exécution du code
- Les interfaces web et les jeux sont plus esthétiques
- Amélioration des compétences en écriture chinoise :
- Amélioration de la qualité du style et du contenu :
- Plus proche du style d'écriture de R1
- Meilleure qualité de l'écriture moyenne
- amélioration fonctionnelle
- Amélioration de la capacité de réécriture interactive à plusieurs tours
- Optimisation de la qualité de la traduction et de la correspondance
- Amélioration de la qualité du style et du contenu :
- Amélioration de la capacité de recherche de la Chine :
- Résultats plus détaillés des demandes d'analyse de rapports
- Fonction Fonction d'appel améliorée :
- Appel de fonction Amélioration de la précision, correction des problèmes hérités de la version V3
Recommandations d'utilisation
Invite du système
Les mêmes alertes système avec des dates spécifiques sont utilisées dans l'application web officielle DeepSeek.
该助手为DeepSeek Chat,由深度求索公司创造。
今天是{current date}。
Exemple :
该助手为DeepSeek Chat,由深度求索公司创造。
今天是3月24日,星期一。
Paramétrage de la température
Dans les environnements web et d'application DeepSeek, le paramètre de température (Tmodèle) est fixé à 0,3. Étant donné que de nombreux utilisateurs utilisent la température par défaut de 1,0 dans les appels API, DeepSeek a mis en place la température API (Tapi) qui ajuste la valeur de la température d'entrée de l'API de 1,0 au réglage de la température du modèle le plus approprié de 0,3.
Tmodèle = Tapi × 0.3 (0 ≤ Tapi ≤ 1)
Tmodèle = Tapi - 0.7 (1 < Tapi ≤ 2)
Par conséquent, si vous appelez V3 via l'API, la température 1,0 correspond à la température du modèle 0,3.
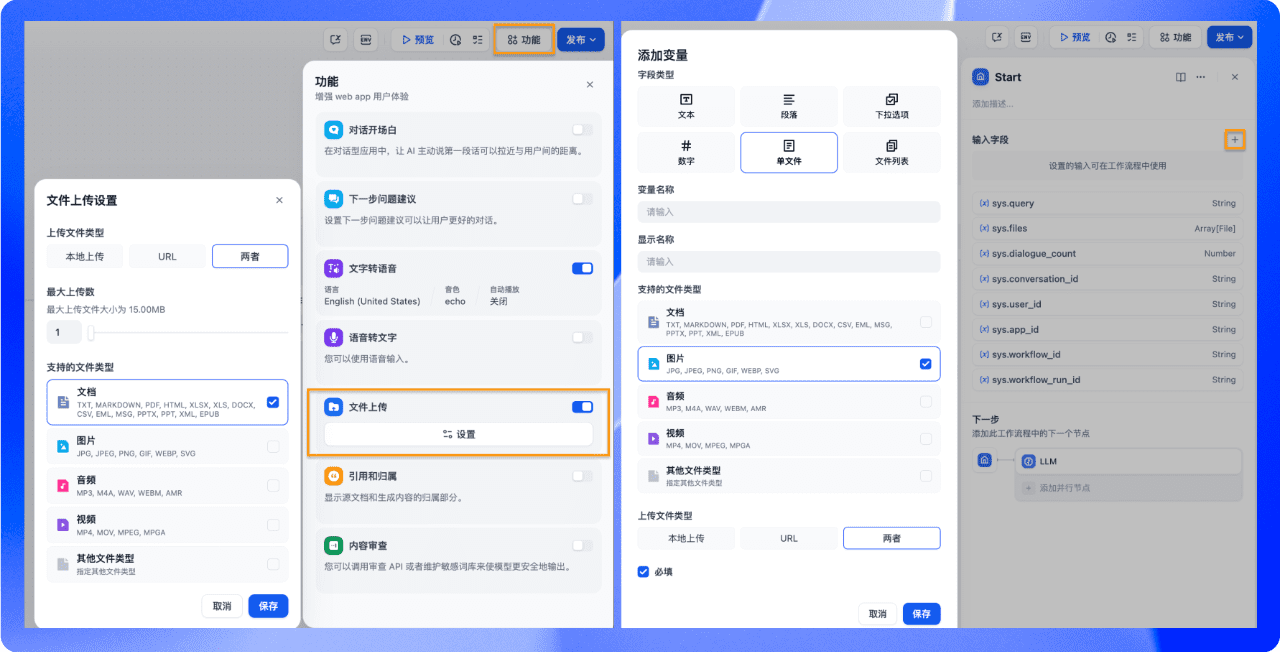
Invitations à télécharger des fichiers et à effectuer des recherches sur Internet
Pour les téléchargements de fichiers, créez des invites en suivant le modèle ci-dessous, où {file_name},{file_content} répondre en chantant {question} comme paramètre.
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
Pour les recherches sur le web.{search_results},{cur_date} répondre en chantant {question} comme paramètre.
Query Prompt chinois :
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
Enquête en anglais Prompt :
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
Méthodes d'exécution locales
La structure du modèle DeepSeek-V3-0324 est identique à celle de DeepSeek-V3. Pour plus d'informations sur l'exécution de ce modèle au niveau local, veuillez consulter le site Web de la Commission européenne. DeepSeek-V3 Dépôt de code.
Le modèle prend en charge des fonctionnalités telles que l'appel de fonction, la sortie JSON et l'achèvement FIM. Pour obtenir des instructions sur la manière de créer des invites pour utiliser ces fonctionnalités, voir la section DeepSeek-V2.5 Dépôt de code.
DeepSeek-V3-0324 est une mise à jour discrète qui a attiré beaucoup d'attention dans le monde de la technologie. Il a fait des progrès impressionnants dans ses capacités de codage, non seulement en montrant sa force dans un certain nombre de tâches de programmation, mais aussi en rivalisant à certains égards avec des modèles de pointe tels que Claude 3.5/3.7 Sonnet. Son caractère open-source, efficace et rentable est de bon augure pour l'avenir. L'ère de l'universalité de la programmation de l'IA pourrait s'accélérer DeepSeek. Au fur et à mesure que des plateformes tierces seront connectées à la nouvelle version V3 de DeepSeek, les développeurs et les utilisateurs pourront bénéficier de capacités avancées de programmation de l'IA à moindre coût. Cela insufflera sans aucun doute une nouvelle vitalité à l'ensemble de l'écosystème de l'IA et favorisera l'émergence d'applications plus innovantes. Avec la puissante capacité de codage V3 et la capacité de raisonnement de pointe R1, le futur modèle R2 de DeepSeek vaut la peine d'être attendu.
Cette mise à jour de DeepSeekV3 prouve une fois de plus que la technologie de l'IA en Chine se développe rapidement et rattrape son retard. La stratégie de licence commerciale libre et gratuite de DeepSeek-V3-0324 attirera sans aucun doute davantage de développeurs et d'entreprises à rejoindre les rangs du développement d'applications d'IA, et favorisera conjointement les progrès et la popularité de la technologie de l'IA.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...