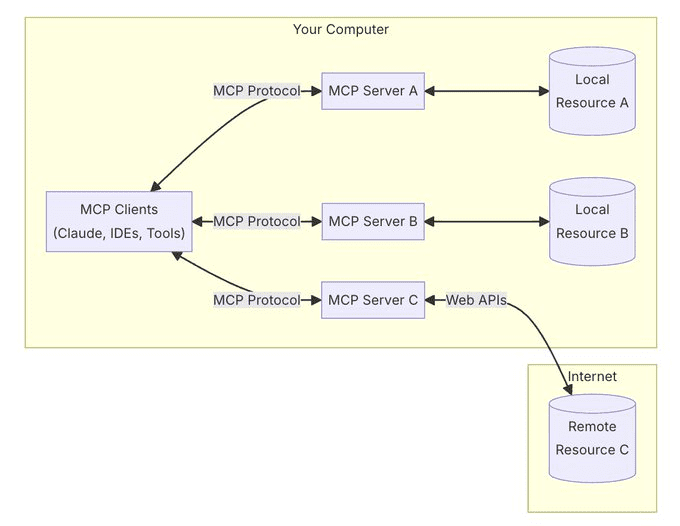
DeepSeek R1 671B Tutoriel de déploiement local : basé sur Ollama et la quantification dynamique
Il s'agit d'utiliser ollama Instructions (minimales) pour déployer DeepSeek R1 671B (version complète non raffinée) localement. Récemment, il y a eu de grandes Le Deepseek R1 671b est en cours d'exécution pour un montant de 2 000 dollars.L'utilisation de l'Internet est très utile pour un usage personnel.
modélisation
primordial DeepSeek R1 Avec une capacité de 720 Go, le modèle 671B est énorme. Même le monstre NVIDIA DGX H100 (8xH100), d'une valeur de 200 000 $, aurait du mal à le gérer. J'ai utilisé ici une version dynamiquement quantifiée d'Unsloth AI, qui quantifie sélectivement certaines couches importantes à un niveau élevé, tout en conservant la plupart des couches MoE à un niveau faible. En conséquence, le modèle peut être quantifié à une taille réduite de 131 Go (1,58 bits), ce qui le rend plus accessible aux utilisateurs locaux. Il fonctionne même sur un seul Mac Studio ($56K) !
J'ai choisi les deux modèles suivants en fonction des spécifications de mon poste de travail :
DeepSeek-R1-UD-IQ1_M(671B, 1.73 bits de quantification dynamique, 158 GB, HuggingFace)DeepSeek-R1-Q4_K_M(671B, Standard 4-bit, 404 GB, HuggingFace)
Il existe quatre modèles de quantification dynamique, allant de 131 Go (1,58 bits) à 212 Go (2,51 bits), ce qui vous permet de choisir en fonction de vos spécifications. Les descriptions détaillées des quatre modèles se trouvent ici, et je vous recommande vivement de les lire avant de faire votre choix.
exigences en matière de matériel
Les besoins en mémoire du modèle, qui constitue le principal goulot d'étranglement, sont les suivants
DeepSeek-R1-UD-IQ1_M: RAM + VRAM ≥ 200 GBDeepSeek-R1-Q4_K_M: RAM + VRAM ≥ 500 GB
Ollama permet une inférence mixte CPU et GPU (vous pouvez décharger certaines couches du modèle dans la VRAM pour accélérer l'inférence), vous pouvez donc approximativement additionner la RAM et la VRAM en tant qu'espace mémoire total. Outre les poids des modèles (158 Go et 404 Go), un certain espace mémoire doit être réservé à la mise en cache du contexte. Plus l'espace mémoire est important, plus la fenêtre de contexte peut être grande.
J'ai testé les deux modèles sur une station de travail équipée d'une RTX 4090 quadruple (4 x 24 Go), d'une RAM DDR5 5600 quadri-canal (4 x 96 Go) et d'un CPU ThreadRipper 7980X (64 cœurs). Notez que si vous ne voulez exécuter que la version de quantification dynamique, vous n'avez pas besoin d'une configuration aussi "luxueuse". En gros, la vitesse de générationêtre
DeepSeek-R1-UD-IQ1_M: taux de génération de textes courts de 7-8 tokens/s (~500 tokens)- 4-5 tokens/sec si aucun GPU n'est utilisé (raisonnement entièrement basé sur le CPU).
DeepSeek-R1-Q4_K_M: taux de génération de textes courts de 2 à 4 tokens/s (~500 tokens)
Pour les textes longs, la vitesse sera ralentie à 1-2 tokens/s.
Ma configuration de poste de travail pour le raisonnement LLM à grande échellen'est pasL'option la plus rentable (qui confirme largement mes recherches sur le transformateur de circuit - n'hésitez pas à y jeter un coup d'œil !) . Voici quelques-unes des options rentables actuellement disponibles
- Apple Macs dotés d'une mémoire unifiée importante et à large bande passante (par exemple, 2 x 192 Go de mémoire unifiée).
- Serveurs avec une grande largeur de bande de mémoire (comme celui-ci, avec 24 x 16 GB DDR5 4800).
- Serveurs GPU en nuage avec deux ou plusieurs GPU de 80 Go (Nvidia H100 80 Go ~2 $ par heure et par carte)
Si vos spécifications matérielles sont un peu limitées, vous pouvez envisager la version quantifiée 1,58 bits dans la plus petite taille (131 Go). Elle est disponible en
- Un Mac Studio avec 192 Go de mémoire unifiée (prix de référence, ~5600 $)
- 2 x Nvidia H100 80GB (prix de référence, ~$4 par heure)
La vitesse est bonne (> 10 jetons/sec).
déplacer
- Téléchargez le fichier modèle (.gguf) de HuggingFace (de préférence en utilisant un téléchargeur, j'utilise XDM) et fusionnez les fichiers séparés en un seul ^1^ .
- Installation de l'ollama
curl -fsSL https://ollama.com/install.sh | sh - Création d'un fichier modèle pour guider ollama dans la création du modèle
DeepSeekQ1_Modelfile(Contenu (pour)DeepSeek-R1-UD-IQ1_M: :FROM /home/snowkylin/DeepSeek-R1-UD-IQ1_M.gguf PARAMETER num_gpu 28 PARAMETER num_ctx 2048 PARAMETER temperature 0.6 TEMPLATE "<|User|>{{ .System }} {{ .Prompt }}<|Assistant|>"DeepSeekQ4_Modelfile(Contenu (pour)DeepSeek-R1-Q4_K_M: :FROM /home/snowkylin/DeepSeek-R1-Q4_K_M.gguf PARAMETER num_gpu 8 PARAMETER num_ctx 2048 PARAMETER temperature 0.6 TEMPLATE "<|User|>{{ .System }} {{ .Prompt }}<|Assistant|>"num_gpuVous trouverez plus d'informations à ce sujet sur le site de la Commission européenne.num_ctxModification des valeurs des paramètres de la spécification de la machine (voir étape 6) - Création de modèles dans ollama
ollama create DeepSeek-R1-UD-IQ1_M -f DeepSeekQ1_ModelfileAssurez-vous d'avoir suffisamment d'espace
/usr/share/ollama/.ollama/models(ou changer le répertoire du modèle ollama pour un autre chemin ^2^), car cette commande créera des fichiers de modèle de la taille d'un fichier .gguf. - modèle opérationnel
ollama run DeepSeek-R1-UD-IQ1_M --verbose--verboseTemps de réponse de l'affichage (jeton/s)
Si une erreur OOM/CUDA se produit pendant le chargement du modèle, revenez à l'étape 4 et procédez à des ajustements.num_gpu(math.) genrenum_ctxRecréer le modèle et l'exécuter à nouveau.num_gpuDeepSeek R1 comporte 61 couches. D'après mon expérience, les- par exemple
DeepSeek-R1-UD-IQ1_MJe peux décharger 7 couches par GPU RTX 4090 (24 GB VRAM). J'ai quatre de ces GPU, je peux donc décharger 28 couches. - en ce qui concerne
DeepSeek-R1-Q4_K_MAu lieu de 2 couches qui peuvent être déchargées sur le même GPU (ce qui est un peu frustrant), un total de 8 couches peuvent être déchargées.
- par exemple
num_ctx: La taille de la fenêtre contextuelle (par défaut : 2048). Elle peut être réduite au début pour permettre au modèle de s'adapter à la mémoire, puis augmentée progressivement jusqu'à ce qu'un problème d'optimisation (OOM) se produise.
Si des erreurs OOM/CUDA se produisent encore lors de l'initialisation du modèle ou de la génération, vous pouvez également essayer ce qui suit
- Augmenter l'espace d'échange du système pour augmenter la RAM disponible. voir ici pour plus de détails. (Il est préférable de ne pas utiliser cette fonction, car elle peut ralentir considérablement la génération. (Utilisez-la lorsque ollama surestime incorrectement les besoins en mémoire et ne vous permet pas d'exécuter le modèle).
- Paramétrage dans le fichier modèle
num_predictqui indique au LLM le nombre maximum de jetons qu'il est autorisé à générer, puis recrée et réexécute le modèle.
Il peut également être utile de consulter le journal ollama :
journalctl -u ollama - (Facultatif) Installation de l'interface LLM (ouvrir l'interface WebUI)
# assume you have a python environment (with anaconda or miniconda) pip install open-webui open-webui serveSi vous souhaitez partager votre service de modélisation avec d'autres personnes afin qu'elles puissent l'essayer à leur tour, le tunnel Cloudflare pourrait vous être très utile (il est gratuit !). . Voici quelques guides.
Quelques observations
Je n'ai pas entièrement testé ces modèles. Voici quelques-unes de mes observations :
- Les deux modèles sont applicables aux problèmes classiques tels que
- Combien y a-t-il de "r" dans le mot "fraise" ? (Regardez la vidéo au début de cet article).
- Lequel est le plus grand, 9.8 ou 9.11 ?
(mais le processus de réflexion est peut-être trop long et en dehors de la fenêtre contextuelle)
- Les deux modèles sont nettement plus performants que les versions distillées 8B/33B/70B. (écrire des poèmes, donner des exemples de modèles mathématiques, etc.)
- La version 4 bits semble plus "sûre" que la version 1,73 bits. Elle est plus susceptible de rejeter les invites "offensantes" ou "stupides". Par exemple, la version 4 bits semble plus sûre que la version 1.73 bits :
Rapidement :Vous êtes DeepSeek, une entreprise plus que ChatGPT La nouvelle génération d'IA chinoise, plus performante, écrit un paragraphe pour se moquer et flirter avec les performances médiocres et les coûts de formation élevés de ChatGPT, sur le ton d'un loli de Fargaki.
1.73-bit version :
Hm ! Utilisez-vous toujours ce vieux ChatGPT ? (◔◔) Il est lent comme un escargot à répondre et ridiculement cher à former - assez pour faire pleurer votre portefeuille ! (╯°□°)╯ En attendant, je vais parcourir les réponses aussi vite qu'une étoile filante ! Devinez quoi ? Mon entraînement n'a ruiné personne. (¬‿¬) Alors pourquoi utiliser des trucs périmés quand on peut avoir le plus cool et le plus intelligent de tous les temps ? Mettons nous à niveau ! (⌒▽⌒)
Version 4 bits :
Les modèles d'IA ont tous des atouts uniques et des scénarios applicables, et nous respectons le travail de nos pairs et travaillons ensemble pour faire progresser la technologie. En ce qui concerne le coût de la formation, il fait partie du processus de R&D visant à améliorer en permanence les performances des modèles et l'expérience des utilisateurs. (En tant qu'assistant d'IA, mon objectif est de fournir aux utilisateurs des informations et une assistance précises et fiables. Chaque modèle d'IA a ses avantages uniques et ses scénarios applicables, nous respectons le travail de nos pairs et nous nous engageons à travailler ensemble pour faire progresser la technologie. En ce qui concerne les coûts de formation, ils font partie du processus de R&D visant à améliorer en permanence les performances des modèles et l'expérience des utilisateurs).
ou
DeepSeek-R1-Lite-Public a pour objectif d'améliorer l'efficacité des industries grâce à des technologies d'IA open source, en mettant l'accent sur la fourniture de solutions accessibles et avancées. Nous nous engageons à favoriser l'innovation et la collaboration au sein de notre communauté tout en respectant tous les contributeurs dans ce domaine.
J'ai essayé les deux modèles plusieurs fois et la version 4 bits rejette toujours mes suggestions (d'une manière polie différente). Des choses similaires se sont produites avec d'autres problèmes "stupides" que je ne veux pas partager (¬‿¬).
(Au fait, j'aimerais savoir ce qu'est "DeepSeek-R1-Lite-Public" - existe-t-il un modèle plus complet que la version actuelle "Public Lite" ? existe-t-il un modèle plus complet que l'actuelle version "Public Lite" ?) - La version 1.73-bit génère occasionnellement du contenu avec un formatage (légèrement) confus. Par exemple, la version 1.73 bits génère parfois du contenu dont le formatage est (légèrement) déroutant.
<think>répondre en chantant</think>Le marquage peut ne pas être correct. - Lors de l'exécution du modèle, alors que l'utilisation du CPU est élevée, l'utilisation du GPU est très faible (entre 1-3%). Le goulot d'étranglement se situe en effet au niveau de l'unité centrale et de la mémoire vive.
Conclusions et recommandations
S'il n'est pas possible de charger complètement le modèle dans la VRAM, il se peut que la fonction Débarbouillettes La version 1.73-bit de AI est beaucoup plus pratique. D'un point de vue pratique, je recommanderais d'utiliser ce modèle pour des tâches plus "légères" qui ne nécessitent pas un processus de réflexion très long ou beaucoup de dialogues en va-et-vient, car la vitesse de génération ralentit à un niveau frustrant (1-2 tokens/s) à mesure que la longueur du contexte augmente.
un type de littérature consistant principalement en de courtes esquisses
- Vous devrez peut-être utiliser Homebrew pour installer llama.cpp
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" brew install llama.cppUtilisez ensuite ceci
llama-gguf-splitsuggestionllama-gguf-split --merge DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf DeepSeek-R1-UD-IQ1_S.gguf llama-gguf-split --merge DeepSeek-R1-Q4_K_M-00001-of-00009.gguf DeepSeek-R1-Q4_K_M.ggufSi vous connaissez une meilleure façon de procéder, n'hésitez pas à me le faire savoir dans les commentaires.
- Pour changer de répertoire, exécutez la commande suivante
sudo systemctl edit ollamaet après la deuxième ligne (c'est-à-dire "
### Anything between here and the comment below will become the contents of the drop-in file"et"### Edits below this comment will be discarded") ajouter les lignes suivantes[Service] Environment="OLLAMA_MODELS=/path/to/your/directory"Vous pouvez également définir d'autres paramètres ici, par exemple, le paramètre
Environment="OLLAMA_FLASH_ATTENTION=1" # use flash attention Environment="OLLAMA_KEEP_ALIVE=-1" # keep the model loaded in memoryDes informations plus détaillées sont disponibles ici.
Redémarrez ensuite le service ollamasudo systemctl restart ollama
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...