
Conception et mise en œuvre de DeepSearch et DeepResearch

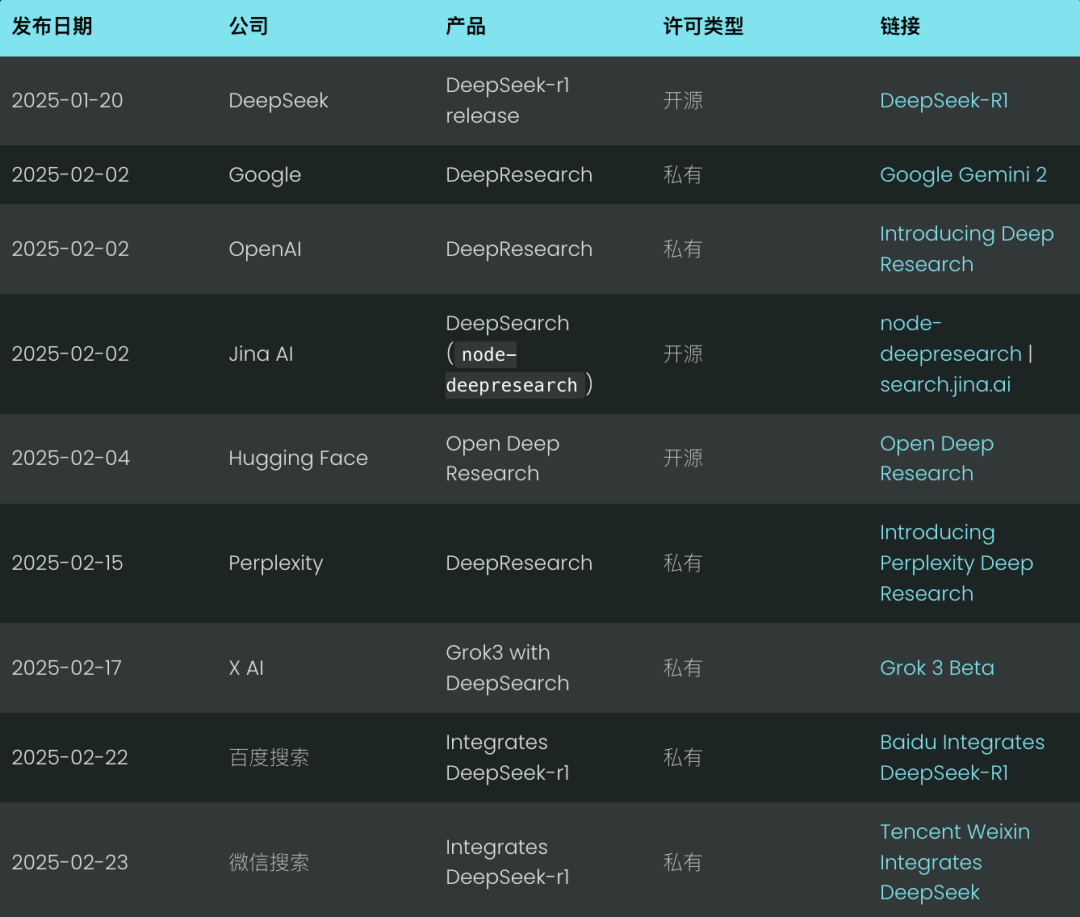
Nous ne sommes qu'en février, et la recherche en profondeur s'annonce déjà comme la nouvelle norme de recherche pour 2025. Des géants comme Google et OpenAI ont dévoilé leurs produits "Deep Research" dans le but de devancer la vague technologique. (Nous sommes également fiers d'avoir publié notre produit open-sourcenode-deepresearch).
Perplexité a fait de même avec Deep Research, tandis que X AI de Musk est allé plus loin en intégrant des capacités de recherche en profondeur directement dans son système de gestion de l'information. Grok 3, qui est essentiellement une variante de Deep Research.
Il s'agit essentiellement de ce que nous appelions l'année dernière RAG (Retrieval Augmented Generation) ou "multihop quizzing". Mais à la fin du mois de janvier de cette année, avec Deepseek-r1 il a fait l'objet d'une attention et d'une croissance sans précédent.
Le week-end dernier, Baidu Search et Tencent WeChat Search ont tous deux intégré Deepseek-r1 dans leurs moteurs de recherche.En intégrant des processus de réflexion et de raisonnement à long terme dans le système de recherche, il est possible d'obtenir une recherche plus précise et plus approfondie que jamais.
Mais pourquoi ce changement se produit-il maintenant ? Tout au long de l'année 2024, la "Deep(Re)Search" ne semble pas avoir attiré beaucoup d'attention. Il convient de rappeler qu'au début de l'année 2024, le Stanford NLP Lab a publié l'étude STORM Projet de génération de rapports longs basés sur le web. Est-ce simplement parce que "Deep Search" est plus à la mode que "More QA", "RAG" ou "STORM" ? Honnêtement, il suffit parfois d'un changement de marque réussi pour que l'industrie adopte soudainement quelque chose qui existe déjà.
Nous pensons que le véritable point de basculement est la publication par OpenAI, en septembre 2024, de l'applicationo1-previewIl a introduit le concept de "calcul en temps réel" et a subtilement changé la perception de l'industrie.L'expression "calculer tout en raisonnant" désigne le fait d'investir davantage de ressources informatiques dans la phase de raisonnement (c'est-à-dire la phase au cours de laquelle le grand modèle linguistique génère le résultat final), plutôt que de se concentrer sur les phases de préformation ou de post-formation. Parmi les exemples classiques, on peut citer le raisonnement par chaîne de pensée (CoT), ainsi que des approches telles que"Wait" Des techniques telles que l'injection (également connue sous le nom de contrôle budgétaire) qui donnent au modèle une plus grande marge de réflexion interne, comme l'évaluation de plusieurs réponses potentielles, une planification plus approfondie et l'autoréflexion avant de donner une réponse finale.
Cette philosophie "calculer tout en raisonnant", ainsi que les modèles qui se concentrent sur le raisonnement, conduisent les utilisateurs à accepter la notion de "gratification différée" :Échangez des temps d'attente plus longs contre des résultats de meilleure qualité et plus utiles. À l'instar de la célèbre expérience de Stanford sur les marshmallows, les enfants qui peuvent résister à la tentation de manger un marshmallow tout de suite pour pouvoir en avoir deux plus tard ont tendance à mieux réussir à long terme. deepseek-r1 renforce encore cette expérience utilisateur, que la plupart des utilisateurs ont implicitement acceptée, que cela vous plaise ou non.
Cela marque une rupture importante avec les besoins traditionnels en matière de recherche. Dans le passé, si votre solution ne pouvait pas donner une réponse dans les 200 millisecondes, c'était l'échec assuré. Mais en 2025, les développeurs de recherche expérimentés et les RAG Les ingénieurs, quant à eux, font passer la précision et le rappel avant la latence. Les utilisateurs se sont habitués à des temps de traitement plus longs : tant qu'ils peuvent voir que le système essaie d'améliorer la qualité de l'information, ils ne peuvent pas s'attendre à ce qu'il y ait des problèmes.<thinking>.
En 2025, l'affichage du processus de raisonnement est devenu une pratique courante, de nombreuses interfaces de dialogue en ligne étant rendues dans des zones d'interface utilisateur dédiées. <think> Le contenu.
Dans cet article, nous discuterons des principes de DeepSearch et DeepResearch en examinant notre implémentation open source. Nous présenterons les décisions clés en matière de conception et soulignerons les mises en garde potentielles.
Qu'est-ce que la recherche approfondie ?
L'idée centrale de DeepSearch est de trouver la réponse optimale en passant par les trois étapes de la recherche, de la lecture et du raisonnement jusqu'à ce que la réponse optimale soit trouvée. La session de recherche explore l'internet à l'aide d'un moteur de recherche, tandis que la session de lecture se concentre sur l'analyse exhaustive de pages web spécifiques (par exemple, à l'aide de Jina Reader). La session de raisonnement est chargée d'évaluer l'état actuel et de décider si le problème initial doit être décomposé en sous-problèmes plus petits ou si d'autres stratégies de recherche doivent être essayées.
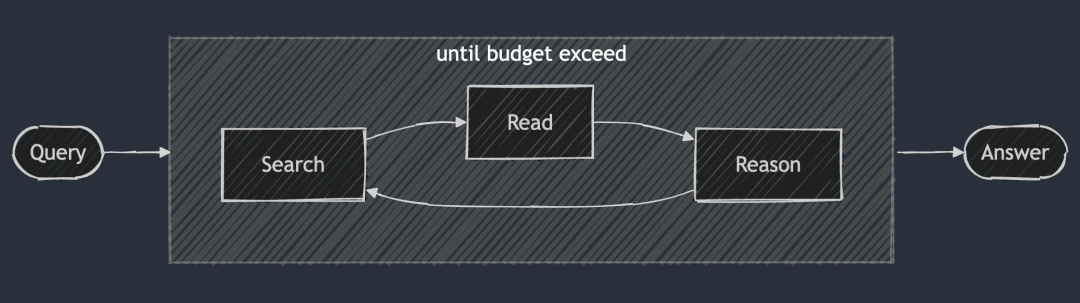 DeepSearch - Recherche continue, lecture de pages web et raisonnement jusqu'à ce que la réponse soit trouvée (ou dépassée). jeton (Budget).
DeepSearch - Recherche continue, lecture de pages web et raisonnement jusqu'à ce que la réponse soit trouvée (ou dépassée). jeton (Budget).
Contrairement au système 2024 RAG, qui exécute généralement un seul processus de génération de recherche, DeepSearch effectue plusieurs itérations qui nécessitent des conditions d'arrêt explicites. Ces conditions peuvent être basées sur des limites d'utilisation des jetons ou sur le nombre de tentatives infructueuses.
Essayez DeepSearch sur le site search.jina.ai et observez les résultats de la recherche. <thinking>pour voir si vous pouvez repérer l'endroit où la boucle se produit.
En d'autres termes.DeepSearch peut être considéré comme un agent LLM équipé de divers outils web tels que des moteurs de recherche et des lecteurs web.L'agent analyse les observations actuelles et les actions passées afin de déterminer la marche à suivre suivante : donner une réponse directement ou continuer à explorer le réseau. Cela construit une architecture de machine à états, où le LLM est responsable du contrôle des transitions entre les états.
À chaque point de décision, deux options s'offrent à vous : vous pouvez créer des indices qui permettent au modèle génératif standard de produire des instructions d'action spécifiques ; ou bien vous pouvez utiliser un modèle d'inférence spécialisé comme Deepseek-r1 pour dériver naturellement la prochaine action à entreprendre. Cependant, même avec r1, vous devrez périodiquement interrompre son processus génératif pour injecter les résultats de l'outil (par exemple, les résultats d'une recherche, le contenu d'une page web) dans le contexte et l'inciter à poursuivre le processus de raisonnement.
En fin de compte, il ne s'agit que de détails de mise en œuvre. Que vous élaboriez des mots-clés ou que vous utilisiez simplement un modèle d'inférence, la fonctionIls respectent tous les principes de conception de DeepSearch : rechercher, lire et déduire.du cycle continu.
Qu'est-ce que DeepResearch ?
DeepResearch ajoute à DeepSearch un cadre structuré pour générer des rapports de recherche de longue durée. Son flux de travail commence généralement par la création d'une table des matières, puis applique systématiquement DeepSearch à chaque section requise du rapport : de l'introduction, aux travaux connexes, à la méthodologie et à la conclusion finale. Chaque section du rapport est générée en introduisant des questions de recherche spécifiques dans DeepSearch. Enfin, toutes les sections ont été intégrées dans un indice unique afin d'améliorer la cohérence de la narration globale du rapport.
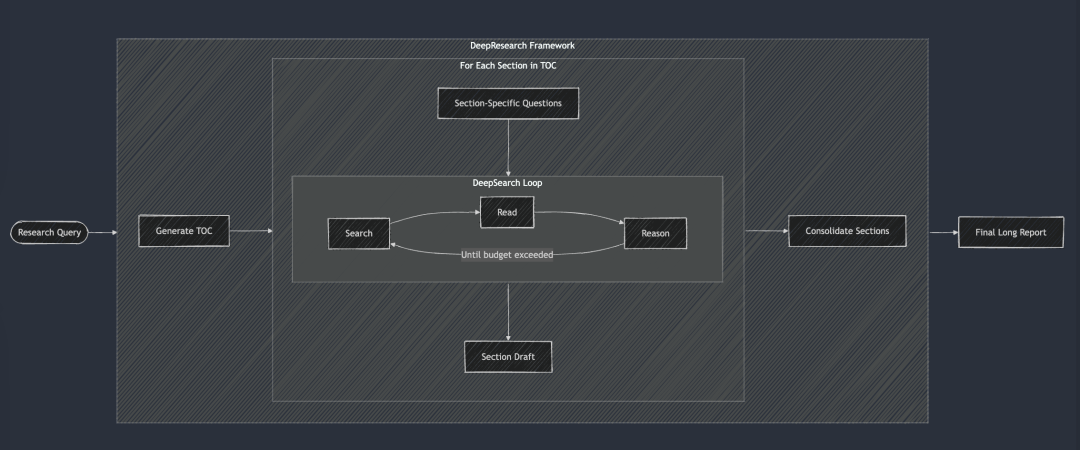 DeepSearch sert de base à DeepResearch. Chaque chapitre est construit de manière itérative grâce à DeepSearch, puis la cohérence globale est améliorée avant que le rapport final ne soit généré.
DeepSearch sert de base à DeepResearch. Chaque chapitre est construit de manière itérative grâce à DeepSearch, puis la cohérence globale est améliorée avant que le rapport final ne soit généré.
En 2024, nous avons également réalisé le projet "Recherche" en interne, et à l'époque, afin d'assurer la cohérence du rapport, nous avons adopté une approche assez stupide, qui consistait à prendre en compte tous les chapitres à chaque itération, et à procéder à de multiples améliorations de la cohérence. Mais aujourd'hui, il semble que cette approche soit un peu trop difficile, car les grands modèles linguistiques actuels ont une fenêtre contextuelle super longue, et il est possible de réaliser des révisions cohérentes en une seule fois, ce qui est beaucoup plus efficace.
Cependant, nous n'avons pas publié le projet "Recherche" pour plusieurs raisons :
Plus particulièrement, la qualité des rapports ne répondait pas à nos normes internes. Nous l'avons testé avec deux requêtes internes familières : "Jina AI's Competitor Analysis" et "Jina AI's Product Strategy". Les résultats ont été décevants, les rapports étaient médiocres et ternes, et ne nous ont pas réservé de surprises "ah-ha". Ensuite, la fiabilité des résultats de recherche est médiocre, et l'illusion est un problème sérieux. Enfin, la lisibilité globale est mauvaise, avec beaucoup de répétitions et de redondances entre les sections. Bref, il ne vaut rien. Et le rapport est si long que sa lecture est à la fois une perte de temps et improductive.
Toutefois, ce projet nous a permis d'acquérir une expérience précieuse et a donné naissance à un certain nombre de sous-produits :
Par exemple.Notre compréhension approfondie de la fiabilité des résultats de recherche et de l'importance de la vérification des faits au niveau du paragraphe et même de la phrase a directement conduit au développement ultérieur du point final g.jina.ai.Nous avons également pris conscience de la valeur de l'expansion des requêtes et avons commencé à investir dans la formation de petits modèles linguistiques (SLM) pour l'expansion des requêtes. Enfin, nous avons beaucoup aimé le nom ReSearch, qui est à la fois une expression intelligente de l'idée de réinventer la recherche et un jeu de mots. Il était dommage de ne pas l'utiliser, et nous avons fini par l'utiliser pour l'annuaire 2024.
Au cours de l'été 2024, notre projet "Recherche" a adopté une approche "incrémentale", en se concentrant sur la génération de rapports plus longs. Il commence par la génération simultanée de la table des matières (TOC) du rapport, suivie par la génération simultanée du contenu de tous les chapitres. Enfin, chaque chapitre est révisé progressivement de manière asynchrone, chaque révision tenant compte du contenu global du rapport. Dans la vidéo de démonstration ci-dessus, la requête que nous avons utilisée était "Competitive Analysis for Jina AI".
DeepSearch vs DeepResearch
De nombreuses personnes ont tendance à confondre DeepSearch et DeepResearch. Mais à notre avis, ils résolvent des problèmes complètement différents.DeepSearch est l'élément constitutif de DeepResearch, le moteur central sur lequel ce dernier fonctionne.
DeepResearch se concentre sur la rédaction de rapports de recherche de haute qualité, lisibles et de longue durée.Il ne s'agit pas seulement de rechercher des informations, c'est un projet systématique.Le projet DeepSearch a été conçu pour être un outil très efficace pour la fonction de recherche, nécessitant l'intégration d'éléments de visualisation efficaces (par exemple, des graphiques, des tableaux), une structure de chapitre logique qui assure un flux fluide entre les sous-chapitres, une terminologie cohérente dans tout le texte, l'évitement de la redondance de l'information et l'utilisation de transitions fluides pour relier les contextes. Ces éléments ne sont pas directement liés à la fonctionnalité de recherche sous-jacente, c'est pourquoi nous nous concentrons davantage sur DeepSearch en tant qu'entreprise.
Pour résumer les différences entre DeepSearch et DeepResearch, voir le tableau ci-dessous. Il convient de noter queDeepSearch et DeepResearch sont tous deux indissociables du contexte long et des modèles d'inférence, mais pour des raisons légèrement différentes.
DeepResearch a besoin d'un contexte long pour générer des rapports longs, ce qui est compréhensible. Et bien que DeepSearch puisse apparaître comme un outil de recherche, il doit également se souvenir des tentatives de recherche précédentes et du contenu des pages web afin de planifier les opérations ultérieures, de sorte que les contextes longs sont tout aussi essentiels.

En savoir plus sur la mise en œuvre de DeepSearch
Lien Open Source : https://github.com/jina-ai/node-DeepResearch
Au cœur de DeepResearch se trouve son mécanisme de raisonnement circulaire. Contrairement à la plupart des systèmes RAG qui tentent de répondre aux questions en une seule étape, nous utilisons une boucle itérative. Le système continue à rechercher des informations, à lire les sources pertinentes et à raisonner jusqu'à ce qu'il trouve une réponse ou qu'il n'ait plus de budget de jetons. Voici un squelette condensé de cette grande boucle "while" :
// 主推理循环
while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) {
// 追踪进度
step++; totalStep++;// Obtenir le numéro actuel dans la file d'attente des lacunes, ou utiliser le numéro original s'il n'est pas disponible.
const currentQuestion = gaps.length > 0 ? gaps.shift() : question;/
/ Générer des invites basées sur le contexte actuel et les actions autorisées
system = getPrompt(diaryContext, allQuestions, allKeywords.
allowReflect, allowAnswer, allowRead, allowSearch, allowCoding.
badContext, allKnowledge, unvisitedURLs);/
/ Laisser le LLM décider de la suite des événements
const result = await LLM.generateStructuredResponse(system, messages, schema) ;
thisStep = result.object;/
/ Effectuer les actions sélectionnées (répondre, réfléchir, rechercher, visiter, coder)
if (thisStep.action === 'answer') {
// Traiter les actions de réponse...
} else if (thisStep.action === 'reflect') {
// Traitement des actions réflexives...
} // ... Et ainsi de suite pour les autres actions
Afin de garantir la stabilité et la structure de la production, une mesure clé a été prise :Désactiver sélectivement certaines opérations à chaque étape.
Par exemple, nous désactivons l'opération "visite" lorsqu'il n'y a pas d'URL en mémoire, et nous empêchons l'agent de répéter immédiatement l'opération "réponse" si la dernière réponse a été rejetée. Ce mécanisme de contrainte guide l'agent dans la bonne direction et l'empêche de tourner en rond au même endroit.
repère du système
Pour la conception des messages-guides du système, nous utilisons des balises XML pour définir les différentes parties, ce qui nous permet de générer des messages-guides et des contenus générés plus robustes. Dans le même temps, nous avons constaté que, directement dans le schéma JSON, les balises description avec des contraintes de champ pour obtenir de meilleurs résultats. Il est vrai que les modèles d'inférence comme DeepSeek-R1 peuvent théoriquement générer automatiquement la plupart des mots-indices. Cependant, compte tenu des contraintes liées à la longueur du contexte et de notre besoin de contrôler finement le comportement de l'agent, cette façon d'écrire explicitement les mots-indices est plus fiable dans la pratique.
function getPrompt(params...) {
const sections = [];// Ajouter un en-tête avec les commandes du système
sections.push("Vous êtes un assistant de recherche senior en IA spécialisé dans le raisonnement à plusieurs étapes...") ;
// Ajouter les fragments de connaissances accumulées (s'ils existent)
if (knowledge ?.length) {
sections.push("[knowledge entry]"); ;
}// Ajouter des informations contextuelles pour les actions précédentes
if (context ?.length) {
sections.push("[Historique des actions]"); ;
}
// Ajouter les tentatives ratées et les stratégies apprises
if (badContext ?.length) {
sections.push("[failed attempts]"); ;
sections.push("[stratégie améliorée]"); ;
}
// Définir les options d'action disponibles en fonction de l'état actuel
sections.push("[définitions d'actions disponibles]"); ;
// Ajouter les instructions de formatage de la réponse
sections.push("Veuillez répondre dans un format JSON valide qui correspond strictement au schéma JSON"); ;
return sections.join("nn") ;
}
Traverser le problème du manque de connaissances
Dans DeepSearch, leUne "question sur les lacunes en matière de connaissances" fait référence à une lacune en matière de connaissances que l'agent doit combler avant de répondre à la question principale.Au lieu d'essayer de répondre directement à la question initiale, l'agent identifie et résout des sous-questions qui constituent la base de connaissances nécessaire.
C'est une façon très élégante de procéder.
// 在“反思行动”中识别出知识空白问题后
if (newGapQuestions.length > 0) {
// 将新问题添加到队列的头部
gaps.push(...newGapQuestions);// Toujours ajouter la question originale à la fin de la file d'attente
gaps.push(originalQuestion) ;
}
Il crée une file d'attente FIFO (First In First Out) avec un mécanisme de rotation qui suit les règles suivantes :
- Les nouvelles questions relatives aux lacunes de connaissances sont classées par ordre de priorité et placées en tête de la file d'attente.
- La question initiale se trouve toujours en fin de file d'attente.
- À chaque étape, le système extrait les questions de l'en-tête de la file d'attente pour les traiter.
La subtilité de cette conception réside dans le fait qu'elle maintient un contexte commun pour tous les problèmes. En d'autres termes, lorsqu'un problème de déficit de connaissances est résolu, les connaissances acquises peuvent être immédiatement appliquées à tous les problèmes ultérieurs et finiront par nous aider à résoudre également le problème initial.
File d'attente FIFO vs récursion
Outre les files d'attente FIFO, nous pouvons également utiliser la récursivité, qui correspond à une stratégie de recherche en profondeur. Pour chaque problème de "lacune de connaissances", la récursivité crée une pile d'appels entièrement nouvelle avec un contexte distinct. Le système doit résoudre complètement chaque problème de lacune de connaissances (et tous ses sous-problèmes potentiels) avant de revenir au problème parent.
A titre d'exemple, un problème simple de récursion à 3 niveaux de connaissances approfondies, les nombres dans les cercles indiquant l'ordre dans lequel les problèmes sont résolus.
En mode récursif, le système doit résoudre entièrement Q1 (et ses éventuels sous-problèmes dérivés) avant de pouvoir passer à d'autres problèmes ! Cela contraste avec l'approche de la file d'attente, qui reviendrait à Q1 après avoir traité trois problèmes de connaissances manquantes.
Dans la pratique, nous avons constaté que les méthodes récursives sont difficiles à contrôler. Étant donné que les sous-problèmes peuvent continuer à engendrer de nouveaux sous-problèmes, il est difficile de déterminer le budget en jetons qui doit leur être alloué en l'absence de lignes directrices claires. L'avantage de la récursivité en termes d'isolation contextuelle claire est bien moindre que la complexité du contrôle du budget et le risque de retards dans les résultats. En revanche, la conception des files d'attente FIFO établit un bon équilibre entre la profondeur et l'étendue, ce qui permet au système de continuer à acquérir des connaissances, de s'améliorer progressivement et de revenir finalement au problème initial plutôt que de s'enfoncer dans un bourbier de récursion potentiellement infini.
Réécriture de requête
Un défi assez intéressant que nous avons relevé consistait à réécrire efficacement la requête de recherche de l'utilisateur :
// 在搜索行为处理器中
if (thisStep.action === 'search') {
// 搜索请求去重
const uniqueRequests = await dedupQueries(thisStep.searchRequests, existingQueries);// Réécrire des requêtes en langage naturel en expressions de recherche plus efficaces
const optimisedQueries = await rewriteQuery(uniqueRequests) ;
// S'assurer qu'il n'y a pas de répétition des recherches précédentes
const newQueries = await dedupQueries(optimisedQueries, allKeywords) ;
// Effectuer une recherche et stocker les résultats
for (const query of newQueries) {
const results = await searchEngine(query) ;
if (results.length > 0) {
storeResults(results) ;
allKeywords.push(query) ;
}
}
}
Nous avons constaté queLa réécriture des requêtes est bien plus importante que prévu et constitue sans doute l'un des facteurs les plus critiques pour déterminer la qualité des résultats de recherche.Un bon réécrivain de requêtes ne se contente pas de transformer le langage naturel de l'utilisateur en quelque chose de plus approprié pour l'utilisateur. BM25 Les algorithmes traitent les formulaires de mots-clés qui étendent également la requête pour couvrir davantage de réponses potentielles dans différentes langues, tonalités et formats de contenu.
En ce qui concerne le dédoublonnage des requêtes, nous avons d'abord essayé un schéma basé sur le LLM, mais nous avons constaté qu'il était difficile de contrôler précisément le seuil de similarité et que les résultats n'étaient pas satisfaisants. Finalement, nous avons choisi la méthode jina-embeddings-v3. Ses excellentes performances sur la tâche de similarité sémantique des textes nous ont permis de réaliser facilement un dédoublonnage inter-langues sans avoir à nous préoccuper des requêtes non anglaises filtrées par des faux positifs. Par coïncidence, c'est le modèle d'intégration qui a finalement joué un rôle clé. Nous n'avions pas l'intention de l'utiliser pour la recherche en mémoire au départ, mais nous avons été surpris de constater qu'il était très efficace pour la tâche de déduplication.
Exploration du contenu des sites web
L'exploration du web et le traitement du contenu constituent également une partie cruciale du processus. Jina Reader Outre le contenu intégral de la page web, nous collectons des extraits sommaires renvoyés par le moteur de recherche, qui servent d'informations complémentaires pour le raisonnement ultérieur. Ces extraits peuvent être considérés comme un résumé concis du contenu de la page web.
// 访问行为处理器
async function handleVisitAction(URLs) {
// 规范化并过滤已访问过的 URL
const uniqueURLs = normalizeAndFilterURLs(URLs);// Traite chaque URL en parallèle
const results = await Promise.all(uniqueURLs.map(async url => {
try {
// Obtenir et extraire le contenu
const content = await readUrl(url) ;
// Stocké en tant que connaissance
addToKnowledge(`Qu'y a-t-il dans ${url} ? `, content, [url], 'url') ;
return {url, success : true} ;
} catch (error) {
return {url, success : false} ;
} finally {
visitedURLs.push(url) ;
}
}));
// Mise à jour des journaux en fonction des résultats
updateDiaryWithVisitResults(results).
}
Pour faciliter le traçage, nous normalisons les URL et limitons le nombre d'URL accédées par étape afin de contrôler l'empreinte mémoire de l'agent.
gestion de la mémoire
La gestion efficace de la mémoire de l'agent constitue un défi majeur pour le raisonnement en plusieurs étapes. Le système de mémoire que nous avons conçu fait la distinction entre ce qui compte comme "mémoire" et ce qui compte comme "connaissance". Mais dans tous les cas, ils font tous partie du contexte de l'indice LLM, séparés par différentes balises XML :
// 添加知识条目
function addToKnowledge(question, answer, references, type) {
allKnowledge.push({
question: question,
answer: answer,
references: references,
type: type, // 'qa', 'url', 'coding', 'side-info'
updated: new Date().toISOString()
});
}// Enregistrer les étapes dans le journal
function addToDiary(step, action, question, résultat, évaluation) {
diaryContext.push(`
A l'étape ${étape}, vous avez pris **${action}** sur la question : "${question}".
[Détails et résultats] [Évaluation (le cas échéant)] `) ; et
}
Etant donné la tendance vers des contextes très longs dans LLM 2025, nous avons choisi d'abandonner les bases de données vectorielles en faveur d'une approche de mémoire contextuelle. La mémoire de l'agent se compose de trois parties dans une fenêtre contextuelle : les connaissances acquises, les sites Web visités et les journaux des tentatives échouées. Cette approche permet à l'agent d'accéder directement à l'historique complet et à l'état des connaissances pendant le processus de raisonnement, sans étapes de récupération supplémentaires.
Évaluation des réponses
Nous avons également constaté qu'il était plus facile de générer et d'évaluer des réponses en les plaçant dans des mots-indices différents.Dans notre mise en œuvre, lorsqu'une nouvelle question est reçue, nous identifions d'abord les critères d'évaluation, puis nous les évaluons au cas par cas. L'évaluateur se réfère à un petit nombre d'exemples pour l'évaluation de la cohérence, ce qui est plus fiable que l'auto-évaluation.
// 独立评估阶段
async function evaluateAnswer(question, answer, metrics, context) {
// 根据问题类型确定评估标准
const evaluationCriteria = await determineEvaluationCriteria(question);// Évaluer chaque critère individuellement
const results = [] ;
for (const criterion of evaluationCriteria) {
const result = await evaluateSingleCriterion(criterion, question, réponse, contexte) ;
results.push(result) ;
}
// Déterminer si la réponse réussit l'évaluation globale
return {
pass : results.every(r => r.pass),
think : results.map(r => r.reasoning).join('n')
};
}
Contrôle budgétaire
Le contrôle budgétaire ne vise pas seulement à réaliser des économies, mais aussi à garantir que le système traite les problèmes de manière adéquate avant que le budget ne soit épuisé et qu'il ne renvoie pas les réponses prématurément.Depuis la sortie de DeepSeek-R1, notre réflexion sur le contrôle budgétaire est passée de la simple sauvegarde des budgets à l'encouragement d'une réflexion plus approfondie et à la recherche de réponses de haute qualité.
Dans notre mise en œuvre, nous demandons explicitement au système d'identifier les lacunes en matière de connaissances avant de tenter de répondre.
if (thisStep.action === 'reflect' && thisStep.questionsToAnswer) {
// 强制深入推理,添加子问题
gaps.push(...newGapQuestions);
gaps.push(question); // 别忘了原始问题
}
En ayant la possibilité d'activer et de désactiver certaines actions, nous pouvons orienter le système vers l'utilisation d'outils permettant d'approfondir le raisonnement.
// 在回答失败后
allowAnswer = false; // 强制代理进行搜索或反思
Pour éviter de gaspiller des jetons sur des chemins non valables, nous limitons le nombre de tentatives infructueuses. Lorsque nous approchons de la limite du budget, nous activons le "mode bête" pour nous assurer que nous donnons quand même une réponse et éviter de repartir les mains vides.
// 启动野兽模式
if (!thisStep.isFinal && badAttempts >= maxBadAttempts) {
console.log('Enter Beast mode!!!');// Configurer les messages-guides pour guider les réponses décisives
système = getPrompt(
diaryContext, allQuestions, allKeywords.
false, false, false, false, false, false, false, // désactiver d'autres opérations
badContext, allKnowledge, unvisitedURLs.
true // Activer le mode "bête" (Beast Mode)
);
// Forcer la génération de réponses
const result = await LLM.generateStructuredResponse(system, messages, answerOnlySchema) ;
thisStep = result.object ;
thisStep.isFinal = true ;
}
Le message de l'invite "Beast Mode" est délibérément exagéré, informant clairement le LLM qu'il doit maintenant prendre une décision décisive pour donner une réponse sur la base des informations disponibles !
<action-answer>
🔥 启动最高战力! 绝对优先! 🔥Première directive :
- Éliminez toute hésitation ! Mieux vaut répondre que se taire !
- Une stratégie localisée peut être adoptée - en utilisant toutes les informations connues !
- Autoriser la réutilisation des tentatives précédentes qui ont échoué !
- Lorsque vous n'arrivez pas à vous décider : sur la base des informations disponibles, agissez de manière décisive !
L'échec n'est pas une option ! Soyez sûrs d'atteindre vos objectifs ! ⚡️
Cela permet de s'assurer que, même face à des questions difficiles ou vagues, nous pouvons donner une réponse utilisable plutôt que rien.
rendre un verdict
On peut dire que DeepSearch constitue une avancée importante dans la technologie de recherche pour le traitement des requêtes complexes. Il décompose l'ensemble du processus en étapes indépendantes de recherche, de lecture et de raisonnement, surmontant ainsi bon nombre des limites des systèmes traditionnels de RAG à un tour ou de Q&A à plusieurs sauts.
Au cours du processus de développement, nous avons constamment réfléchi à ce à quoi devrait ressembler la future base technologique de recherche en 2025, compte tenu des changements radicaux survenus dans l'ensemble de l'industrie de la recherche après la sortie de DeepSeek-R1. Quels sont les nouveaux besoins qui émergent ? Quels sont les besoins obsolètes ? Quels sont les pseudo-besoins ?
En examinant la mise en œuvre de DeepSearch, nous avons soigneusement identifié ce qui était attendu et essentiel, ce que nous considérions comme acquis et dont nous n'avions pas vraiment besoin, et ce que nous n'avions pas du tout prévu mais qui s'est avéré crucial.
Premièrement.Un LLM à contexte long qui génère des résultats dans un format canonique (par exemple, JSON Schema) est essentiel !. Un modèle d'inférence est peut-être également nécessaire pour améliorer le raisonnement sur les actions et l'expansion des requêtes.
Les extensions de requêtes sont également absolument nécessairesL'expansion des requêtes, qu'elle soit mise en œuvre à l'aide de SLM, LLM ou de modèles d'inférence spécialisés, est une partie inéluctable du processus. Mais après avoir réalisé ce projet, nous nous sommes rendu compte que le SLM n'était peut-être pas bien adapté à cette tâche, car l'expansion des requêtes doit être intrinsèquement multilingue et ne peut se limiter à un simple remplacement des synonymes ou à l'extraction de mots-clés. Il doit être suffisamment complet pour disposer d'une base de tokens couvrant plusieurs langues (de sorte que l'échelle puisse facilement atteindre 300 millions de paramètres), et il doit être suffisamment intelligent pour sortir des sentiers battus. Par conséquent, la mise à l'échelle des requêtes par la seule méthode SLM peut s'avérer inefficace.
Les compétences en matière de recherche et de lecture sur le web sont, sans aucun doute, une priorité absolue !Heureusement, notre [Reader (r.jina.ai)] a très bien fonctionné, il est non seulement puissant mais aussi très extensible, ce qui m'a incité à réfléchir à la façon dont nous pourrions améliorer notre point d'arrivée de recherche (s.jina.ai) sont autant d'inspirations qui peuvent être optimisées lors de la prochaine itération.
Les modèles vectoriels sont utiles, mais ils sont utilisés à des endroits totalement inattendus. Nous pensions à l'origine qu'il serait utilisé pour la récupération en mémoire, ou en conjonction avec une base de données vectorielle pour compresser le contexte, mais ni l'un ni l'autre ne s'est avéré nécessaire. En fin de compte, nous avons constaté qu'il était préférable d'utiliser le modèle vectoriel pour la déduplication, essentiellement une tâche STS (Semantic Text Similarity - Similitude sémantique de texte). Étant donné que le nombre de requêtes et de lacunes dans les connaissances est généralement de l'ordre de quelques centaines, il est parfaitement suffisant de calculer la similarité cosinus directement en mémoire sans utiliser de base de données vectorielle.
Nous n'avons pas utilisé le modèle RerankerLe modèle Embeddings et Reranker peut être utilisé comme outil pour aider à déterminer quels URL devraient être prioritaires pour l'accès sur la base de la requête, du titre de l'URL et de l'extrait de résumé, en théorie. Pour les modèles Embeddings et Reranker, la capacité multilingue est une exigence de base, puisque les requêtes et les questions sont multilingues. Le traitement du contexte long est utile pour les modèles Embeddings et Reranker, mais n'est pas un facteur décisif. Nous n'avons pas rencontré de problèmes liés à l'utilisation de vecteurs, probablement grâce au fait que le modèle jina-embeddings-v3 (une excellente longueur de contexte de 8192 tokens). Dans l'ensemble, lesjina-embeddings-v3 répondre en chantant jina-reranker-v2-base-multilingual Ils restent mon premier choix, car ils offrent un support multilingue, des performances SOTA et une bonne gestion des contextes longs.
Le cadre des agents s'est finalement avéré inutile. En termes de conception du système, nous avons préféré rester proches des capacités natives des LLM et éviter d'introduire des couches d'abstraction inutiles. Le Vercel AI SDK offre une grande facilité d'adaptation aux différents fournisseurs de LLM, ce qui réduit considérablement l'effort de développement, car seule une ligne de code doit être modifiée pour créer un nouveau LLM dans le système de gestion des LLM. Gémeaux Commutation entre Studio, OpenAI et Google Vertex AI. La gestion de la mémoire proxy a du sens, mais l'introduction d'un cadre spécialisé pour cela est discutable. Personnellement, je pense qu'une dépendance excessive aux frameworks peut construire une barrière entre LLM et le développeur, et le sucre syntaxique qu'ils fournissent peut devenir un fardeau pour le développeur. De nombreux frameworks LLM/RAG ont déjà validé cela. Il est plus sage d'adopter les capacités natives de LLM et d'éviter d'être lié par des frameworks.
Cet article provient de WeChat : Jina AI
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...