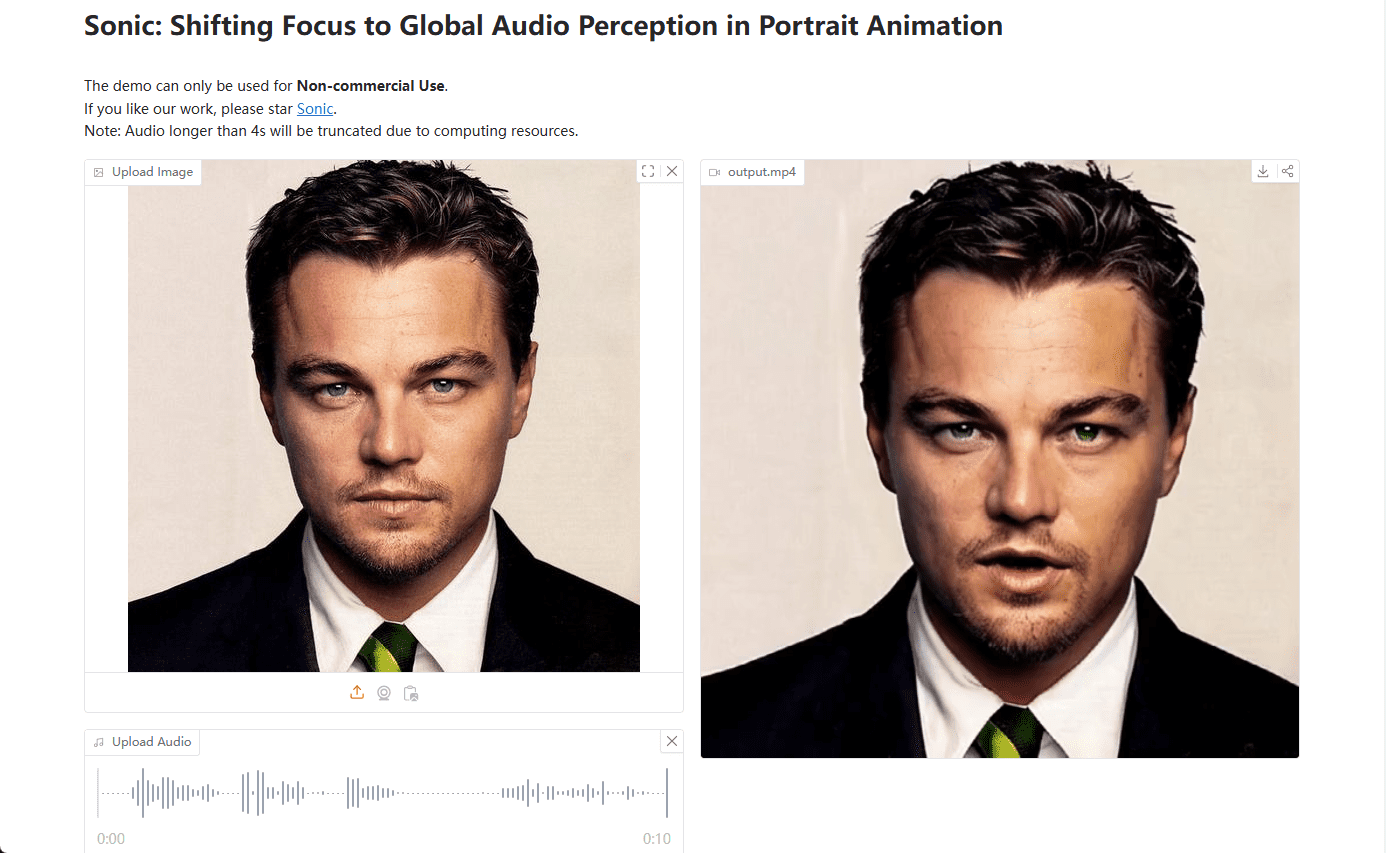
Deepdive Llama3 From Scratch : Apprendre à implémenter des modèles Llama3 à partir de zéro
Introduction générale
Deepdive Llama3 From Scratch est un projet open source hébergé sur GitHub qui se concentre sur l'analyse pas à pas et la mise en œuvre du processus d'inférence des modèles Llama3. Il est optimisé sur la base du projet naklecha/lllama3-from-scratch, et est conçu pour aider les développeurs et les apprenants à acquérir une compréhension plus profonde des concepts de base et des détails de raisonnement de Llama3. Le projet fournit des commentaires de code détaillés, des parcours d'apprentissage structurés et des instructions de traçage des dimensions de la matrice, ce qui permet aux débutants de commencer facilement. Grâce à un code clair de désassemblage et d'implémentation étape par étape, les utilisateurs peuvent maîtriser le processus complet, de l'inférence du modèle au calcul complexe, ce qui constitue une ressource de grande qualité pour l'apprentissage de grands modèles de langage.

Liste des fonctions
- Raisonnement étape par étape pour atteindreLlama3 : Fournit une analyse de chaque étape de l'inférence du modèle Llama3, y compris la dérivation mathématique et l'implémentation du code.
- Commentaires détaillés sur le codeLes annotations : ajouter des annotations détaillées à chaque morceau de code pour expliquer sa fonction et son rôle et aider à comprendre la logique sous-jacente.
- Suivi dimensionnelLes données de l'analyse de la matrice : annotent le changement des dimensions de la matrice dans le calcul et montrent clairement le processus de flux de données.
- Optimiser les structures d'apprentissageRéorganiser l'ordre du contenu et la table des matières pour faciliter l'apprentissage étape par étape.
- Explication du mécanisme d'attention de groupeLlama3 : une explication en profondeur du mécanisme d'attention aux requêtes de groupe de Llama3 et de sa mise en œuvre.
- Description du réseau SwiGLU Feedforward: Disséquer la structure du réseau SwiGLU et son rôle dans le modèle.
- Prise en charge de la génération de plusieurs motsLe programme KV-Cache : Démontre comment générer une sortie multi-mots via des appels récursifs, y compris le principe d'optimisation du KV-Cache.
Utiliser l'aide
Comment l'installer et l'utiliser
Deepdive Llama3 From Scratch est un projet open source GitHub qui peut être utilisé sans processus d'installation compliqué. Vous trouverez ci-dessous les étapes détaillées qui vous permettront de démarrer et d'explorer les fonctionnalités du projet.
Obtenir le projet
- Visiter la page GitHub
Ouvrez votre navigateur et entrez l'URLhttps://github.com/therealoliver/Deepdive-llama3-from-scratchpour accéder à la page d'accueil du projet. - Télécharger le code
- Cliquez sur le bouton vert Code Bouton.
- option Télécharger ZIP Téléchargez le fichier zip ou clonez le projet à l'aide de la commande Git :
git clone https://github.com/therealoliver/Deepdive-llama3-from-scratch.git - Extrayez le fichier ZIP ou accédez au dossier du projet cloné.
- Préparation de l'environnement
Le projet s'appuie sur l'environnement Python et sur des bibliothèques d'apprentissage profond courantes telles que PyTorch. Les étapes suivantes sont recommandées pour la configuration :- Assurez-vous que Python 3.8 ou supérieur est installé.
- Exécutez la commande suivante dans le terminal pour installer la dépendance :
pip install torch numpy - Si vous avez besoin d'effectuer une inférence complète du modèle, vous pouvez avoir besoin d'installer en plus le programme
transformersou d'autres bibliothèques, en fonction des exigences spécifiques du code.
Principales fonctions
1) Réalisation par raisonnement par étapes
- Description fonctionnelleLlama3 : Il s'agit du cœur du projet, qui fournit un démontage de chaque étape de l'inférence Llama3, de l'intégration des données d'entrée à la prédiction des données de sortie.
- procédure: :
- Ouvrez le fichier principal dans le dossier du projet (par ex.
llama3_inference.py(ou des documents portant un nom similaire, en fonction de la dénomination au sein du projet). - Lisez les instructions au début du document pour comprendre le processus global de raisonnement.
- Exécutez les extraits de code étape par étape, avec des commentaires expliquant chaque segment. Exemple :
# Embedding 输入层,将 token 转换为向量 token_embeddings = embedding_layer(tokens) - Comprendre les principes mathématiques et la logique de mise en œuvre de chaque étape grâce à des commentaires et des comparaisons de code.
- Ouvrez le fichier principal dans le dossier du projet (par ex.
- Conseils et astucesIl est recommandé de l'exécuter avec Jupyter Notebook afin d'exécuter le code bloc par bloc et de voir les résultats intermédiaires.
2) Commentaires détaillés sur le code
- Description fonctionnelleChaque morceau de code est accompagné d'annotations détaillées, permettant aux débutants de comprendre des concepts complexes.
- procédure: :
- Ouvrez le fichier du projet dans un éditeur de code tel que VS Code.
- Lorsque vous parcourez le code, notez que le code commençant par
#Les notes qui commencent par, par exemple :# RMS 归一化,避免数值不稳定,eps 防止除零 normalized = rms_norm(embeddings, eps=1e-6) - Après avoir lu les commentaires, essayez de modifier vous-même les paramètres et exécutez le programme, en observant l'évolution des résultats.
- Conseils et astucesLes notes : Traduisez les notes dans votre propre langue afin de les enregistrer et d'approfondir votre compréhension.
3. le suivi dimensionnel
- Description fonctionnelleLes données de la matrice sont étiquetées afin d'aider les utilisateurs à comprendre les transformations de la forme des données.
- procédure: :
- Trouvez des endroits où étiqueter les dimensions, par exemple :
# 输入 [17x4096] -> 输出 [17x128],每 token 一个查询向量 q_per_token = torch.matmul(token_embeddings, q_layer0_head0.T) - Vérifiez la forme du tenseur produit par le code et vérifiez qu'elle est conforme aux commentaires :
print(q_per_token.shape) # 输出 torch.Size([17, 128]) - Comprendre le processus de calcul des mécanismes d'attention ou des réseaux feedforward par le biais de changements dimensionnels.
- Trouvez des endroits où étiqueter les dimensions, par exemple :
- Conseils et astucesLes diagrammes de transformation des dimensions (par exemple, 4096 -> 128) sont tracés manuellement pour obtenir une vue d'ensemble du flux de données.
4) Explication du mécanisme de l'attention de groupe
- Description fonctionnelle: Explication approfondie de l'attention groupée aux requêtes (GQA) pour Llama3, où chaque groupe de 4 requêtes partage un ensemble de vecteurs clé-valeur.
- procédure: :
- Localisez le segment de code du mécanisme d'attention, qui se trouve généralement dans la section
attention.pyou dans un document similaire. - Lisez les notes correspondantes, par exemple :
# GQA:将查询头分为组,共享 KV,维度降至 [1024, 4096] kv_weights = model["attention.wk.weight"] - Exécutez le code et observez comment le regroupement réduit la quantité de calculs.
- Localisez le segment de code du mécanisme d'attention, qui se trouve généralement dans la section
- Conseils et astucesLes résultats de l'étude sont les suivants : Calculer les économies de mémoire de l'AQG par rapport à l'attention traditionnelle à plusieurs têtes.
5) Description du réseau SwiGLU de type feed-forward
- Description fonctionnelleLes réseaux SwiGLU : Expliquer comment les réseaux SwiGLU augmentent la non-linéarité et améliorent la représentation du modèle.
- procédure: :
- Trouvez le code d'implémentation du réseau feedforward, par exemple :
# SwiGLU:w1 和 w3 计算非线性组合,w2 输出 output = torch.matmul(F.silu(w1(x)) * w3(x), w2.T) - Lisez les formules annotées et comprenez leurs principes mathématiques.
- Modifiez les données d'entrée, exécutez le code et observez les changements au niveau de la sortie.
- Trouvez le code d'implémentation du réseau feedforward, par exemple :
- Conseils et astucesIl n'est pas possible de le remplacer par ReLU et de comparer la différence de performance.
6. la prise en charge de la génération de mots multiples
- Description fonctionnelleLe projet KV-Cache : Générer des séquences de plusieurs mots via des appels récurrents et introduire l'optimisation de KV-Cache.
- procédure: :
- Trouvez le code logique de la génération, par exemple :
# 循环预测下一个词,直到遇到结束标记 while token != "<|end_of_text|>": next_token = model.predict(current_seq) current_seq.append(next_token) - Lisez les notes relatives à KV-Cache pour comprendre comment la mise en cache accélère l'inférence.
- Saisissez une phrase courte (par exemple "Bonjour") et exécutez-la pour générer une phrase complète.
- Trouvez le code logique de la génération, par exemple :
- Conseils et astuces: Ajustements
max_seq_lenpour tester différentes longueurs de sorties.
mise en garde
- exigences en matière de matérielLa prise en charge par le GPU peut être nécessaire pour exécuter une inférence complète, mais des tests plus petits peuvent être effectués sur le CPU.
- Conseils en matière d'apprentissage: A lire en parallèle avec le papier officiel Llama3 pour de meilleurs résultats.
- Méthode de mise en serviceSi vous rencontrez une erreur, vérifiez la version de la dépendance ou consultez la page GitHub Issues pour obtenir de l'aide.
Grâce à ces étapes, vous pouvez maîtriser Deepdive Llama3 From Scratch, du raisonnement de base aux techniques d'optimisation !
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...