Inventaire des technologies de recherche approfondie ! Un paradigme pour les applications LLM plus avancé que les RAGs
Après que l'outil Deep Research d'OpenAI a surgi de nulle part, tous les grands fournisseurs ont lancé leurs propres outils de recherche en profondeur. La recherche en profondeur est comparée à la recherche ordinaire, où une simple recherche RAG ne génère généralement qu'un seul cycle de recherche. Cependant, la recherche en profondeur peut rechercher, analyser, récupérer et analyser à nouveau sur la base d'un sujet, tout comme un être humain, jusqu'à ce qu'elle atteigne l'objectif de la recherche. De ce point de vue, il s'agit essentiellement d'une version améliorée de l'application RAG, de l'utilisation de ReAct/Plan And Solve et d'autres modes de construction de l'agent du domaine pendant, avec la planification et la génération de la décomposition de l'article, l'acquisition d'informations et les capacités d'analyse.
En principe, c'est très simple, mais si l'on veut réaliser un produit fini privé pour répondre aux besoins de l'entreprise, les détails techniques réels ainsi que l'effet de l'optimisation sont assez complexes, de sorte qu'un certain échafaudage de la plate-forme de développement du projet ou du produit fini est particulièrement important, ce qui est la même chose que le RAG, il y aura de plus en plus de cadres de développement de ce type.
Aujourd'hui, sur l'introduction de plusieurs Deep Research open source mise en œuvre , au nom des deux idées de mise en œuvre , l'un est basé sur la mise en œuvre du cadre d'orchestration existant , tels que Langchain Langgraph , l'autre est spécifiquement conçu pour les caractéristiques du développement de la recherche profonde . Grâce à eux, vous pouvez non seulement créer rapidement des applications de recherche approfondie, mais aussi comprendre les détails de la mise en œuvre de ces cadres et de la sélection spécifique, tels que ce qu'il faut rechercher, ce qu'il faut utiliser pour le stockage, quel est le mot d'ordre, etc.
1. Langchain Open DeepResearch
Il s'agit d'une version de démonstration officielle de LangChain, basée sur la technologie LangGraph Construire l'ensemble du flux de traitement. En intégrant de multiples API telles que Tavily Les utilisateurs peuvent définir la profondeur de la recherche pour chaque chapitre, y compris le nombre d'itérations pour la rédaction, la réflexion, la recherche et la réécriture. Les utilisateurs peuvent définir la profondeur de la recherche pour chaque chapitre, y compris le nombre d'itérations pour la rédaction, la réflexion, la recherche et la réécriture, ainsi que fournir un retour d'information sur le plan du chapitre du rapport et itérer jusqu'à satisfaction.
 Invite utilisée : https://github.com/langchain-ai/open_deep_research/blob/main/src/open_deep_research/prompts.py
Invite utilisée : https://github.com/langchain-ai/open_deep_research/blob/main/src/open_deep_research/prompts.py
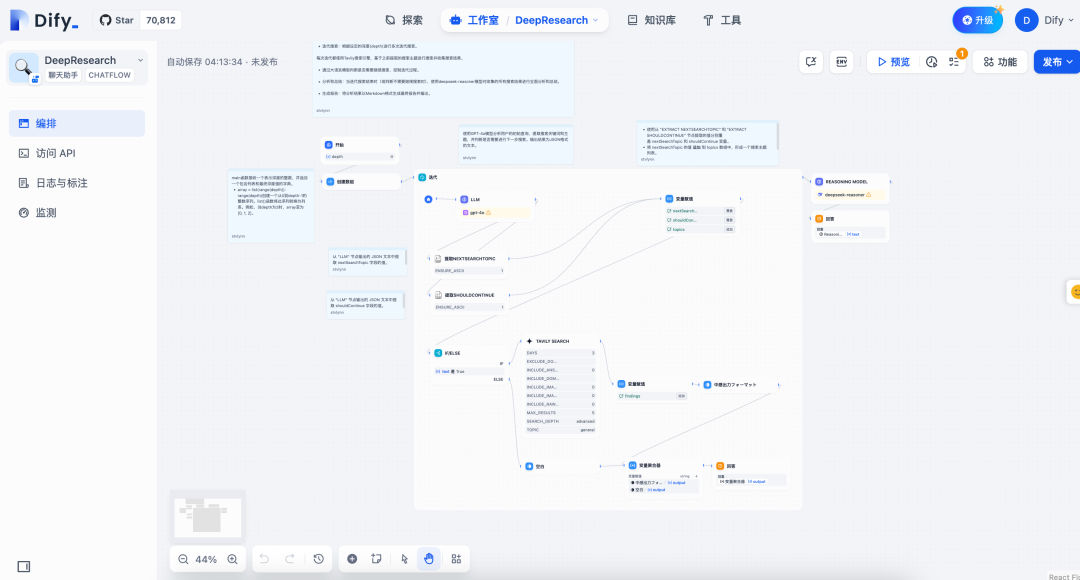
Adresse du projet : https://github.com/langchain-ai/open_deep_research同类型的有Dify等框架编排的Deep Demande de recherche.
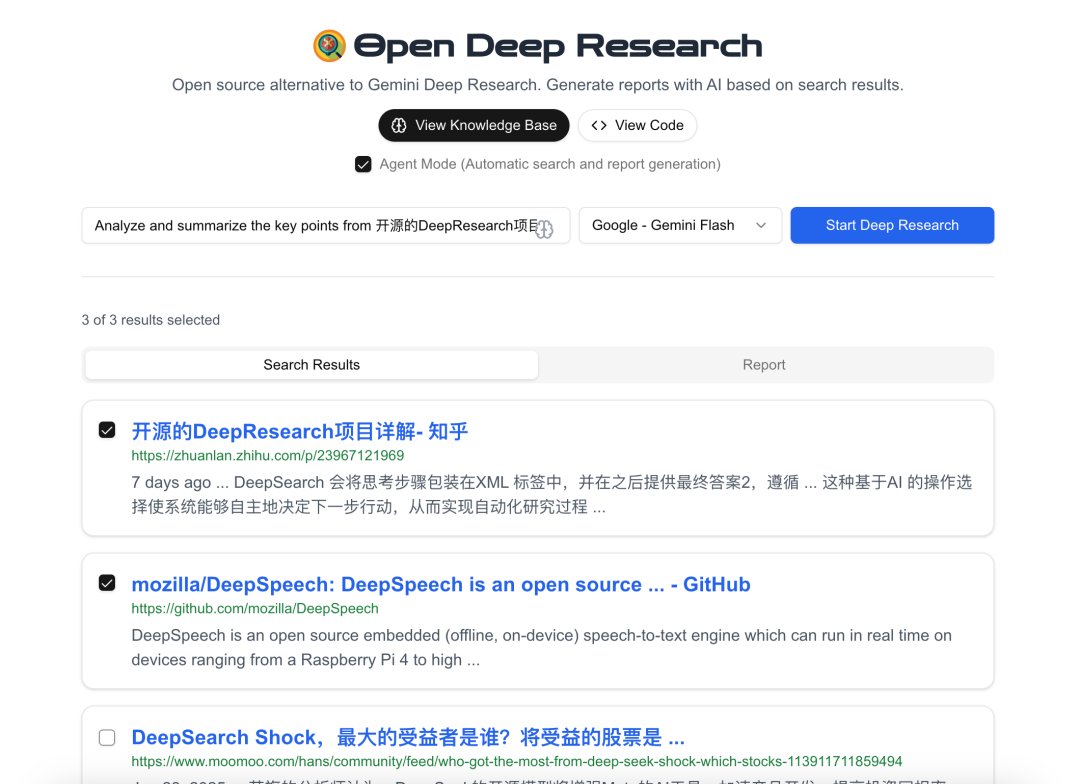
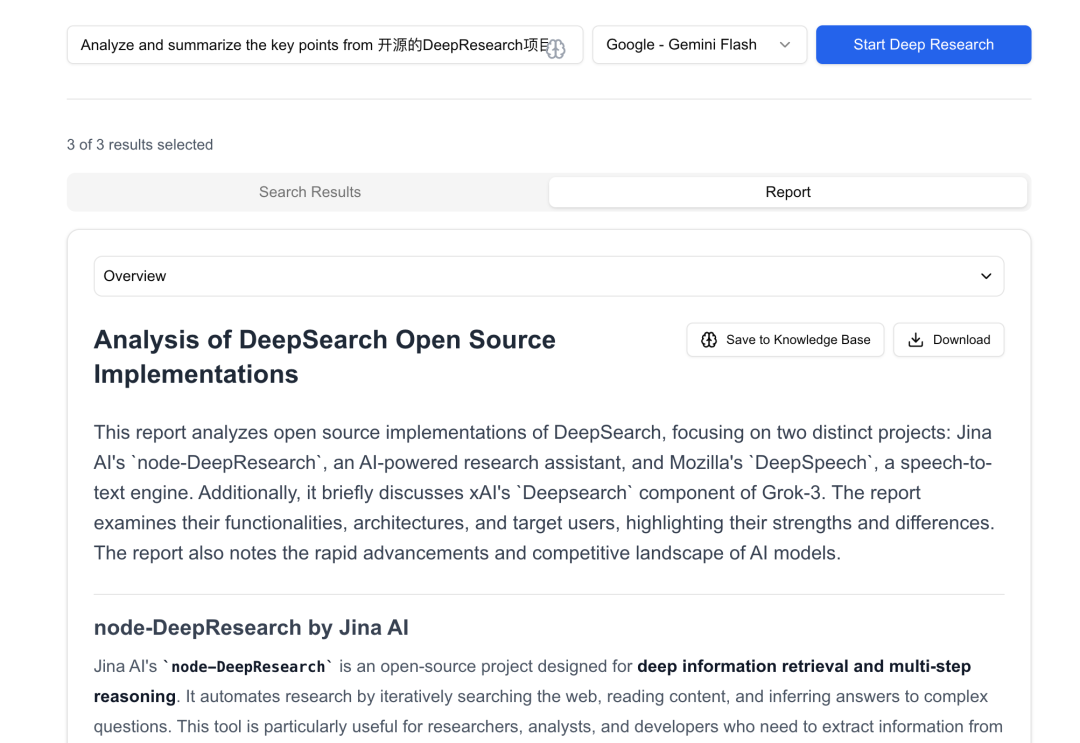
2. recherche approfondie ouverte
Open Deep Research est l'une des nombreuses implémentations de plomberie. Il déconstruit le processus DeepSearch et prend en charge les processus de recherche automatiques et semi-automatiques. Prenant en charge une variété d'interfaces API, il est non seulement capable d'extraire des informations de l'extranet, mais aussi d'extraire des informations internes à l'entreprise en vue d'une analyse sommaire. Les utilisateurs peuvent choisir différentes plateformes d'IA en fonction de leurs besoins, notamment Google, OpenAI, Anthropic, DeepSeek, etc., et peuvent même accéder à des modèles locaux pour effectuer des recherches personnalisées.
Il contient les trois étapes de la norme Deep ReSearch :
- Extraction des résultats de recherche : Obtenez des résultats de recherche complets pour les termes de recherche spécifiés via Google Custom Search ou Bing Search API (configurable).

- Extraction de contenu : JinaAI est utilisée pour extraire et traiter le contenu des résultats de recherche sélectionnés afin de garantir l'exactitude et la pertinence des informations.
- Génération de rapports : à l'aide de modèles d'IA sélectionnés par l'utilisateur (par ex. Gémeaux (GPT-4, Sonnet, etc.) génère des rapports détaillés sur les résultats de recherche rassemblés et le contenu extrait, fournissant une analyse approfondie et des informations sur les questions définies par l'utilisateur.
Voici l'invite utilisée pour générer le rapport :
You are a research assistant tasked with creating a comprehensive report based on multiple sources.
The report should specifically address this request: "${userPrompt}"
Your report should:
1. Have a clear title that reflects the specific analysis requested
2. Begin with a concise executive summary
3. Be organized into relevant sections based on the analysis requested
4. Use markdown formatting for emphasis, lists, and structure
5. Integrate information from sources naturally without explicitly referencing them by number
6. Maintain objectivity while addressing the specific aspects requested in the prompt
7. Compare and contrast the information from each source, noting areas of consensus or points of contention.
8. Showcase key insights, important data, or innovative ideas.
Here are the source articles to analyze:
${articles
.map(
(article) => `
Title: ${article.title}
URL: ${article.url}
Content: ${article.content}
---
`
)
.join('n')}
Format the report as a JSON object with the following structure:
{
"title": "Report title",
"summary": "Executive summary (can include markdown)",
"sections": [
{
"title": "Section title",
"content": "Section content with markdown formatting"
}
]
}
Use markdown formatting in the content to improve readability:
- Use **bold** for emphasis
- Use bullet points and numbered lists where appropriate
- Use headings and subheadings with # syntax
- Include code blocks if relevant
- Use > for quotations
- Use --- for horizontal rules where appropriate
Important: Do not use phrases like "Source 1" or "According to Source 2". Instead, integrate the information naturally into the narrative or reference sources by their titles when necessary.
Le rapport généré peut être téléchargé ou stocké dans la base de connaissances, mais les sources de recherche de haute qualité sont insuffisantes et les processus de validation et d'itération de la recherche font défaut, de sorte que la qualité peut encore être améliorée.
Adresse du projet : https://github.com/btahir/open-deep-research
Le même type est également disponible :
https://github.com/nickscamara/open-deep-research (4.3k)
https://github.com/mshumer/OpenDeepResearcher (2.2k)
https://github.com/assafelovic/gpt-researcher (19k)
https://github.com/zaidmukaddam/scira (6.4k)
https://github.com/jina-ai/node-DeepResearch (2.6k)
Parmi eux, node-DeepResearch pour l'implémentation open source de deep research de jina, vous pouvez directement utiliser son api, et d'autres interfaces de modèles sont aussi simples à utiliser, vous pouvez rapidement les intégrer dans leurs propres applications.
court
Comme mentionné au début de l'article, la recherche approfondie est le résultat de l'évolution de la demande de l'utilisateur pour un accès de haute qualité au contenu, brisant le cocon d'information de la recommandation passive, abandonnant la recherche traditionnelle et le résumé, puis la recherche et le résumé du processus inefficace, bien par le biais de l'automatisation. Selon cette direction de développement, le mode d'acquisition du contenu connaîtra de nouveaux changements, ce qui constituera un grand défi pour la recommandation de recherche traditionnelle.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...