Raisonner avec de grands modèles linguistiques : trouver un équilibre entre "sous-réflexion" et "sur-réflexion".
Les grands modèles de langage (LLM) évoluent rapidement et leur capacité de raisonnement est devenue un indicateur clé de leur niveau d'intelligence. En particulier, les modèles dotés de longues capacités de raisonnement, tels que le modèle de l'OpenAI o1,DeepSeek-R1,QwQ-32B répondre en chantant Kimi K1.5 Ceux-ci ont attiré beaucoup d'attention pour leur capacité à résoudre des problèmes complexes en simulant des processus de pensée humains profonds. Cette capacité implique souvent une technique appelée Inference-Time Scaling, qui permet au modèle de passer plus de temps à explorer et à corriger lorsqu'il génère des réponses.
Cependant, un examen plus approfondi révèle que ces modèles se situent souvent dans deux extrêmes en matière de raisonnement :Sous-pensée répondre en chantant Réflexion excessive.
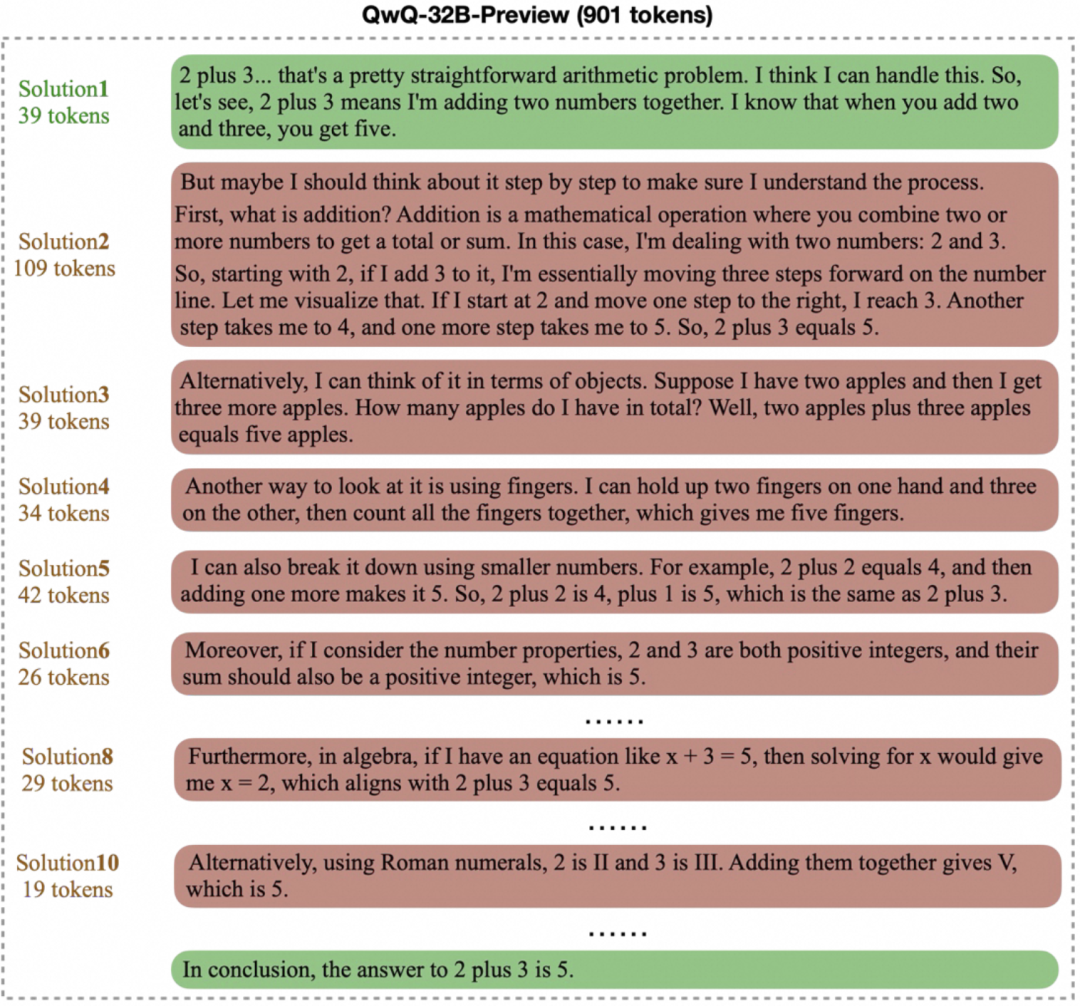
pas assez de matière à réflexion Il s'agit des changements fréquents d'idées dans le raisonnement du modèle, ce qui rend difficile de se concentrer sur une direction prometteuse pour une recherche plus approfondie. La sortie du modèle peut être remplie de mots tels que "alternativement", "mais attendez", "laissez-moi reconsidérer", etc. comme le montre la figure ci-dessous, aboutissant à une réponse finale erronée. Ce phénomène peut être comparé à l'inattention humaine, qui affecte la validité du raisonnement.

surréflexion Au lieu de cela, le modèle génère des "chaînes de pensée" longues et inutiles pour des problèmes simples. Par exemple, pour un problème arithmétique de base tel que "2+3= ?", certains modèles peuvent nécessiter des centaines, voire des milliers d'heures de travail. Par exemple, pour un problème arithmétique de base tel que "2+3= ?", certains modèles peuvent nécessiter des centaines, voire des milliers d'heures de travail. token pour vérifier ou explorer plusieurs solutions de manière itérative, comme indiqué ci-dessous. Si les processus de réflexion complexes sont utiles pour les problèmes difficiles, dans les scénarios simples, ils entraînent certainement un gaspillage des ressources informatiques.
Ensemble, ces deux questions mettent en évidence un défi central : comment améliorer l'efficacité de la réflexion du modèle tout en maintenant la qualité des réponses ? Un modèle idéal devrait être capable de trouver et de donner la bonne réponse dans le délai le plus court.
Pour relever ce défi.EvalScope Le projet présente EvalThink afin de fournir un outil standardisé pour évaluer l'efficacité de la réflexion d'un modèle. Dans le présent document, nous utiliserons l'outil MATH-500 À titre d'exemple, l'analyse de l'ensemble des données comprend DeepSeek-R1-Distill-Qwen-7B La performance d'une série de modèles de raisonnement, y compris ceux qui se concentrent sur six dimensions : le raisonnement de modèle token Nombre, première fois correcte token Nombre, réflexions restantes token Les chiffres,token Efficacité, nombre de chaînes de sous-réflexion et précision.
Méthodologie et processus d'évaluation
Le processus d'évaluation comprend deux étapes principales : l'évaluation du raisonnement du modèle et l'évaluation de l'efficacité du raisonnement du modèle.
Évaluation du raisonnement du modèle
L'objectif de cette phase est d'obtenir le modèle en MATH-500 Résultats bruts de l'inférence et précision de base sur l'ensemble des données.MATH-500 L'ensemble de données contient 500 problèmes de mathématiques de difficulté variable (du niveau 1 au niveau 5).
Préparation de l'environnement d'évaluation
L'évaluation peut être effectuée en accédant à un service de raisonnement compatible avec l'API OpenAI.EvalScope Le cadre soutient également l'utilisation de transformers La bibliothèque fait l'objet d'une évaluation locale. Pour ceux qui doivent traiter de longues chaînes de pensée (peut-être plus de 10 000 token) du modèle d'inférence en utilisant vLLM peut-être ollama Les cadres d'inférence efficaces tels que ceux-ci déploient des modèles qui peuvent accélérer considérablement le processus d'évaluation.
afin de DeepSeek-R1-Distill-Qwen-7B A titre d'exemple, utilisez le vLLM L'exemple de commande pour déployer le service est le suivant :
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --trust_remote_code --port 8801
Examen du raisonnement exécutif
faire passer (un projet de loi, une inspection, etc.) EvalScope (utilisé comme expression nominale) TaskConfig Configurez l'adresse API du modèle, le nom, le jeu de données, la taille du lot et les paramètres de génération, puis exécutez la tâche d'évaluation. Voici un exemple de code Python :
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需与部署时一致)
eval_type='service', # 评测类型:服务
datasets=['math_500'], # 数据集
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数,包含难度级别
eval_batch_size=32, # 并发请求数
generation_config={
'max_tokens': 20000, # 最大生成 token 数,设置较大值防截断
'temperature': 0.6, # 采样温度
'top_p': 0.95, # top-p 采样
'n': 1, # 每个请求生成一个回复
},
)
run_task(task_config)
Une fois l'évaluation terminée, le modèle sera exporté en format MATH-500 Précision à chaque niveau de difficulté (AveragePass@1) :
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|-----------------------------|-----------|---------------|----------|-----|--------|---------|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
Évaluation de l'efficacité de la réflexion sur les modèles
Après avoir obtenu les résultats du raisonnementEvalThink Interventions sur les composants pour des analyses d'efficacité plus approfondies. Les mesures d'évaluation de base comprennent
- raisonnement modélisé
token(Jetons de raisonnement)Les chaînes de réflexion pendant la génération des réponses (comme dans le modèle O1/R1)</think>(ce qui précède le drapeau) contenu dans letokenMontant total. - bien dès la première fois
tokenNombre (premiers jetons corrects)Le modèle est un outil d'aide à la décision qui permet d'identifier la bonne réponse à une question donnée, et ce depuis le début de la sortie du modèle jusqu'à la première occurrence d'une réponse correcte identifiable.tokenQuantité. - Réflexions restantes
tokenNombre (jetons de réflexion): : De la première position de réponse correcte à la fin de la chaîne de pensée.tokenLa quantité. Cela reflète en partie le coût de la poursuite de la validation ou de l'exploration après que le modèle a trouvé une réponse. - Pensée numérique: : En comptant les signifiants spécifiques (par ex.
alternatively,but wait,let me reconsider) pour estimer la fréquence à laquelle le modèle change d'idée. tokenEfficacité des jetons: : Mesurer l'efficacité de la penséetokenIndicateur de pourcentage, calculé comme étant correct la première foistokenChiffres et raisonnement généraltokenLa moyenne du ratio du nombre de (seuls les échantillons avec des réponses correctes ont été comptés) :
Efficacité des jetons = 1⁄N ∑ Premier correctif Jetonsi⁄Raisonnement Tokensi
où N est le nombre de questions auxquelles il a été répondu correctement. Plus la valeur est élevée, plus la pensée du modèle est "efficace".
Aux fins de la détermination du "premier droit token nombre", un cadre d'évaluation qui s'appuie sur l'expérience de l'Union européenne. ProcessBench L'idée est d'utiliser un modèle de juge distinct, par exemple Qwen2.5-72B-Instructafin d'examiner les étapes de l'inférence et de localiser la position où la bonne réponse apparaît le plus tôt. La mise en œuvre consiste à décomposer les résultats du modèle en étapes (stratégie facultative : par séparateur spécifique) separatorMots-clés de la presse keywordsou réécrite et découpée à l'aide du LLM llm), puis laisser le modèle d'arbitre juger chacune d'entre elles.
Exemple de code pour effectuer une évaluation de l'efficacité de la pensée :
from evalscope.third_party.thinkbench import run_task
# 配置裁判模型服务
judge_config = dict(
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1', # 假设裁判模型也部署在此服务
model_name='Qwen2.5-72B-Instruct',
)
# 配置待评估模型的信息
model_config = dict(
report_path='./outputs/2025xxxx', # 上一步推理结果路径
model_name='DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Tokenizer 路径,用于计算 token
dataset_name='math_500', # 数据集名称
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 数据集子集
split_strategies='separator', # 推理步骤分割策略
judge_config=judge_config
)
max_tokens = 20000 # 过滤 token 过长的输出
count = 200 # 每个子集抽样数量,加速评测
# 运行思考效率评估
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
Les résultats de l'évaluation détailleront les six mesures dimensionnelles du modèle pour chaque niveau de difficulté.
Analyse et discussion des résultats
L'équipe de recherche a utilisé EvalThink droit DeepSeek-R1-Distill-Qwen-7B et plusieurs autres modèles (QwQ-32B,QwQ-32B-Preview,DeepSeek-R1,DeepSeek-R1-Distill-Qwen-32B) a été évaluée et un modèle mathématique spécialisé non inférentiel a été ajouté Qwen2.5-Math-7B-Instruct À titre de comparaison.
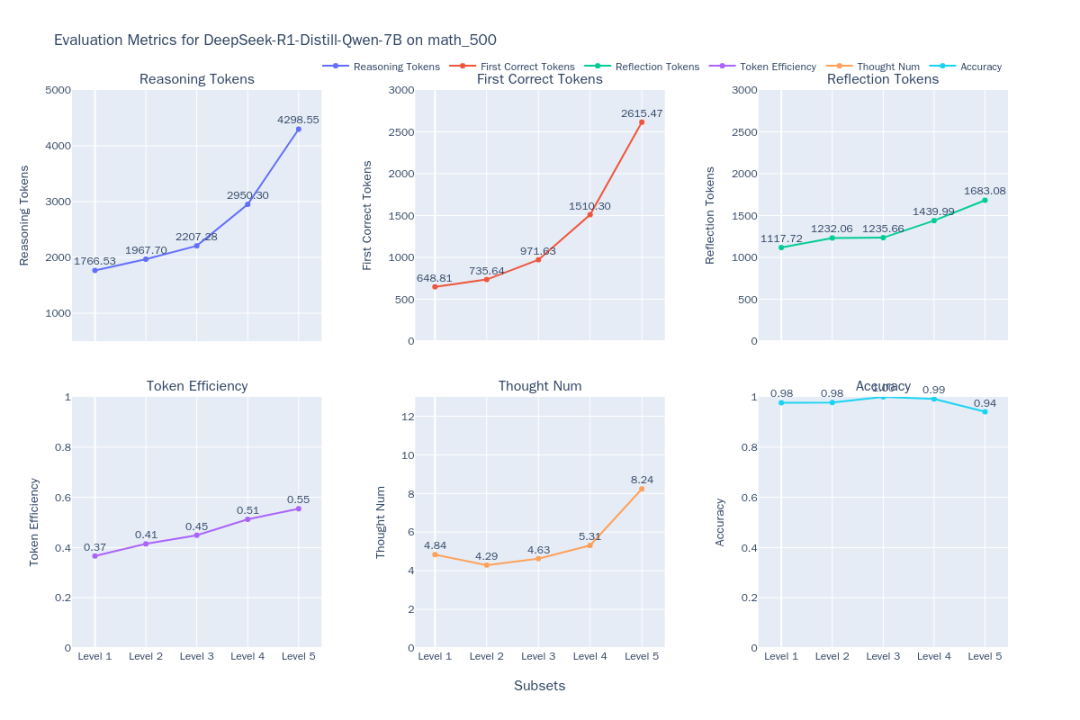
Figure 1 : Indicateur d'efficacité de la réflexion DeepSeek-R1-Distill-Qwen-7B
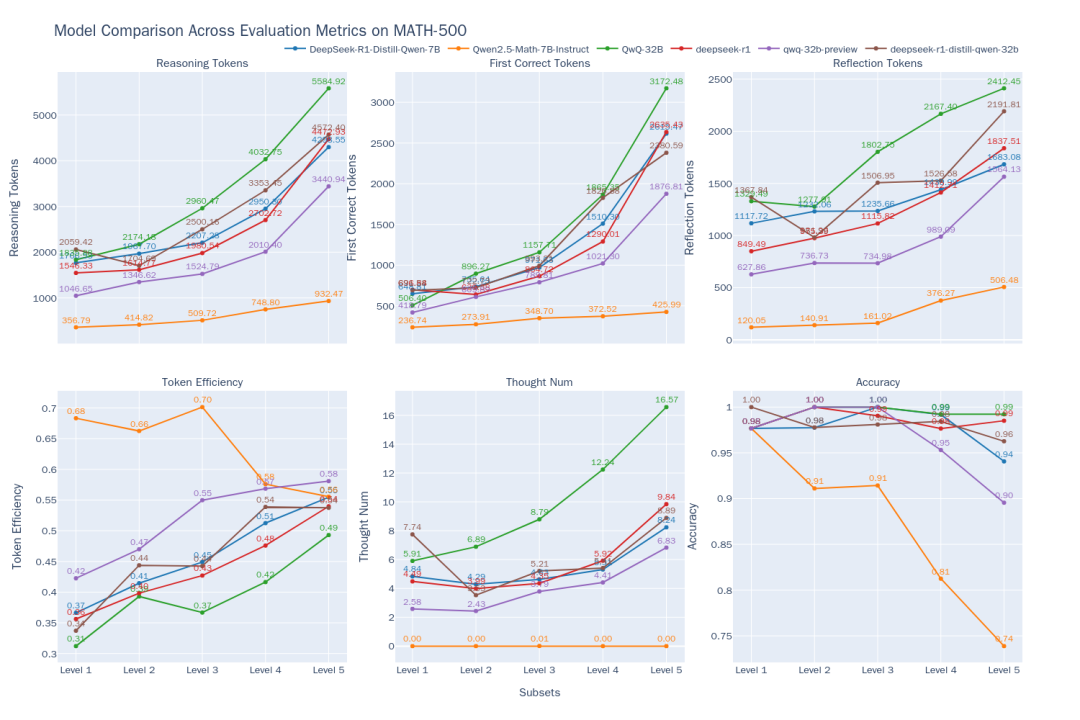
Figure 2 : Comparaison de l'efficacité de réflexion des 6 modèles à différents niveaux de difficulté de MATH-500
Les tendances suivantes peuvent être observées à partir des résultats de la comparaison (figure 2) :
- Corrélation entre la difficulté et la performanceLa précision de la plupart des modèles diminue au fur et à mesure que la difficulté du problème augmente (du niveau 1 au niveau 5). Cependant.
QwQ-32Brépondre en chantantDeepSeek-R1exceller dans les problèmes difficiles.QwQ-32Bla plus grande précision au niveau 5. Dans le même temps, les résultats de tous les modèlestokenLes nombres deviennent de plus en plus longs à mesure que la difficulté augmente, ce qui est conforme à l'attente de "raisonner en élargissant" - le modèle doit "penser" davantage pour résoudre l'énigme. - Propriétés du modèle de raisonnement de la classe O1/R1:
- Gains d'efficacité: : Il est intéressant de noter que pour les
DeepSeek-R1répondre en chantantQwQ-32BCe type de modèle d'inférence, bien que la sortie devienne plus longue, latokenEfficience (efficace)token) augmente également avec la difficulté (DeepSeek-R1De 36% à 54%.QwQ-32B(de 31% à 49%). Cela suggère que leur réflexion supplémentaire sur les problèmes difficiles est plus "rentable", alors que sur les problèmes simples, il peut y avoir une certaine quantité de "réflexion excessive", par exemple une validation itérative inutile.QwQ-32B(utilisé comme expression nominale)tokenLa consommation est globalement élevée, ce qui peut être l'une des raisons pour lesquelles il peut maintenir un taux de précision élevé au niveau 5, mais cela indique également une tendance à trop réfléchir. - Les chemins de la pensée:
DeepSeekLe nombre de chaînes de sous-réflexion pour les modèles en série est relativement stable aux niveaux 1 à 4, mais augmente considérablement au niveau 5, le plus difficile, ce qui suggère que le niveau 5 représente un défi important pour ces modèles et qu'il nécessite plusieurs tentatives. En revanche.QwQ-32BLe modèle en série présente une croissance plus régulière du nombre de chaînes de pensée, ce qui reflète des stratégies d'adaptation différentes.
- Gains d'efficacité: : Il est intéressant de noter que pour les
- Limites des modèles non inférentiels: : Modèles mathématiques spécialisés
Qwen2.5-Math-7B-InstructLa précision diminue considérablement lorsqu'il s'agit de traiter des problèmes difficiles, et le rendement de l'appareil diminue considérablement lorsqu'il s'agit de traiter des problèmes difficiles.tokenCe chiffre est bien inférieur à celui des modèles de raisonnement (environ un tiers). Cela suggère que, bien que ces modèles puissent être plus rapides et moins gourmands en ressources pour les problèmes courants, l'absence de processus de réflexion plus profonds leur confère un "plafond" de performance significatif pour les tâches de raisonnement complexes.
Considérations méthodologiques et limites
dans l'application EvalThink Il y a plusieurs points à garder à l'esprit lors d'une évaluation :
- Définition des indicateurs:
- proposée dans le présent document
tokenLes indicateurs d'efficacité, qui s'appuient sur les concepts de "surpensée" et de "sous-pensée" de la littérature, se concentrent principalement sur les éléments suivantstokenLa quantité, mesure simplifiée du processus de réflexion, ne permet pas de saisir tous les détails de la qualité de la réflexion. - Le calcul du nombre de sous-chaînes de pensée repose sur des mots-clés prédéfinis, et la liste des mots-clés peut devoir être adaptée à différents modèles afin de refléter fidèlement leurs schémas de pensée.
- proposée dans le présent document
- Champ d'application:
- Les mesures actuelles sont principalement validées sur des ensembles de données de raisonnement mathématique, et leur efficacité dans d'autres scénarios tels que les quiz ouverts et la génération d'idées doit encore être testée.
- théâtre
DeepSeek-R1-Distill-Qwen-7Best basé sur un modèle mathématique de distillation de l'eau de mer.MATH-500Il peut y avoir un avantage naturel dans la performance sur l'ensemble de données. Les résultats de l'évaluation doivent être interprétés dans le contexte du modèle.
- Modèle d'adjudication dépendance:
tokenLe calcul de l'efficacité s'appuie sur le modèle du juge (JM) pour juger avec précision de la justesse des étapes du raisonnement. En tant queProcessBench4Comme l'indique l'étude, il s'agit d'une tâche difficile pour les modèles existants, qui nécessitent généralement des modèles très performants pour être à la hauteur.- Les erreurs de jugement dans le modèle d'arbitrage peuvent avoir un impact direct sur
tokenLe choix du bon modèle d'arbitre est donc crucial.
En bref.EvalThink Un ensemble de cadres et de mesures permettant d'évaluer quantitativement l'efficacité de la pensée LLM est fourni, révélant les performances de différents modèles en termes de précision,token compromis entre la consommation et la profondeur de la réflexion. Ces résultats sont utiles pour guider la formation des modèles (par exemple, la formation de l'équipe de recherche). GRPO et SFT), il est instructif de développer des modèles de nouvelle génération plus efficaces et capables d'ajuster de manière adaptative la profondeur de la réflexion en fonction de la difficulté du problème.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...