Comment calculer le nombre de paramètres d'un grand modèle, et que signifient 7B, 13B et 65B ?
Récemment, de nombreuses personnes impliquées dans la formation et l'inférence de grands modèles ont discuté de la relation entre le nombre de paramètres du modèle et la taille du modèle. Par exemple, la célèbre série alpaga de grands modèles LLaMA contient quatre versions avec différentes tailles de paramètres, LLaMA-7B, LLaMA-13B, LLaMA-33B et LLaMA-65B.
Le "B" est l'abréviation de "Billion", qui signifie milliard. Ainsi, le plus petit modèle LLaMA-7B contient environ 7 milliards de paramètres, tandis que le plus grand modèle LLaMA-65B contient environ 65 milliards de paramètres.
Comment sont donc calculés ces nombres de paramètres ? Par ailleurs, quel est le niveau approximatif du nombre de paramètres d'un grand modèle correspondant à un fichier de modèle de 100 Go ? Des milliards, des dizaines de milliards, des centaines de milliards ou des billions ? Ce document répondra à ces questions de manière approfondie.
I. Méthodes de calcul de la quantité de paramètres importants du modèle
Nous prendrons le Transformateur, l'infrastructure du grand modèle, comme exemple pour analyser en détail le processus de comptage des paramètres.
Une norme Transformateur Le modèle se compose de L couches identiques empilées les unes sur les autres, et chaque couche contient deux parties principales : la couche d'auto-attention (SAL) et la couche de réseau neuronal à progression lente (MLP).
1. l'attention à soi
Le mécanisme d'auto-attention est le cœur du transformateur. Qu'il s'agisse d'une auto-attention ou d'une auto-attention à têtes multiples (MHA), le calcul de la quantité de paramètres du noyau est le même.
Dans la couche d'auto-attention, la séquence d'entrée est d'abord mappée en trois vecteurs : un vecteur de requête (Query, Q), un vecteur de clé (Key, K) et un vecteur de valeur (Value, V). Dans MHA, ces trois vecteurs sont ensuite divisés en plusieurs têtes, chacune d'entre elles étant chargée de se concentrer sur une partie différente de la séquence d'entrée.

- Auto-attention à une seule tête. Q, K, V sont chacun transformés linéairement par une matrice de poids de forme [h, h], où h est la dimension de la couche cachée. Ainsi, le nombre total de paramètres de Q, K, V est de 3h². En outre, il existe une couche de transformation linéaire pour la sortie avec la même matrice de poids de forme [h, h]. Par conséquent, le nombre total de paramètres pour l'auto-attention à une tête est de 4h² (ne pas tenir compte du terme "biais").
- Attention multiple (MHA). Supposons qu'il y ait n_têtes, chacune de dimension h_tête = h / n_tête. Chaque tête possède une matrice de poids Q, K, V distincte de la forme [h, h_tête]. Par conséquent, la quantité paramétrique de la matrice de poids Q, K, V pour chaque tête est 3 * h * h_head = 3h²/n_head. Le nombre total de quantités paramétriques pour les n_heads est n_head * (3h²/n_head) = 3h². Enfin, la forme de la matrice de poids de la transformation linéaire pour la couche de sortie est [h, h]. Le nombre total de paramètres dans la MHA est donc également de 4h² (ne pas tenir compte du terme "biais").
Par conséquent, le nombre de paramètres dans la couche d'auto-attention peut être estimé à 4h², tant pour les têtes simples que pour les têtes multiples.
2. couche du réseau neuronal à progression directe (MLP)
La couche MLP se compose de deux couches linéaires. La première couche linéaire étend la dimension h de la couche cachée à 4h, et la deuxième couche linéaire ramène la dimension de 4h à h.

- La matrice de poids de la première couche linéaire a la forme [h, 4h] et le nombre de paramètres est de 4h².
- La deuxième couche linéaire a une matrice de poids de la forme [4h, h] avec la même quantité paramétrique de 4h².
Le nombre total de paramètres dans la couche MLP est donc de 8h² (en ignorant le terme de biais).
3. normalisation des couches
Après chaque couche d'auto-attention et de MLP, et après la dernière couche de sortie du transformateur, il y a généralement une opération de normalisation des couches. Chaque couche de normalisation contient deux paramètres entraînables :
- Paramètre d'échelle (gamma) : La forme est [h].
- Paramètre de translation (bêta) : la forme est [h].
Étant donné que chaque couche du transformateur comporte deux normalisations de couche (après l'auto-attention et le MLP respectivement) plus une après la couche de sortie, le nombre total de paramètres de normalisation de couche pour le transformateur à couche L est de (2L + 1) * 2h.
4. l'encastrement
Le texte d'entrée doit d'abord être converti en vecteurs de mots par la couche d'intégration des mots. En supposant que la taille de la liste de mots est V et que la dimension du vecteur de mots est h, le nombre de paramètres de la couche d'intégration des mots est Vh.
5. couche de sortie
La matrice de poids de la couche de sortie est généralement partagée avec la couche d'intégration des mots (Weight Tying) afin de réduire le nombre de paramètres et d'améliorer potentiellement les performances. Par conséquent, si le partage des poids est utilisé, la couche de sortie n'introduit généralement pas de nombre supplémentaire de paramètres. Si elle n'est pas partagée, le nombre de paramètres est Vh.
6. codage positionnel
Le codage de la position est utilisé pour fournir au modèle des informations sur la position des mots dans la séquence d'entrée.
- Codes des postes pouvant faire l'objet d'une formation. Si le codage positionnel entraînable est utilisé, le nombre de paramètres est N * h, où N est la longueur maximale de la séquence. Par exemple, la longueur maximale de la séquence de ChatGPT est de 4k.
- Code de position relative (par exemple RoPE ou ALiBi). Ces méthodes n'introduisent pas de paramètres entraînables.
En raison du nombre relativement faible de paramètres codés en position, ils sont généralement négligeables dans le calcul du nombre total de paramètres.
7. calcul du nombre total de participants
En résumé, le nombre total de paramètres pour un modèle de transformateur à couche L est le suivant :
Nombre total de paramètres = L * (paramètre d'auto-attention + paramètre MLP + paramètre LayerNorm * 2) + paramètre d'intégration + paramètre de la couche de sortie + paramètre LayerNorm (après la couche de sortie)
Nombre total de paramètres ≈ L * (4h² + 8h² + 4h) + Vh + (Vh optionnel) + 2h
Nombre total de paramètres ≈ L * (12h² + 4h) + Vh + 2h (en supposant que la couche de sortie partage les poids avec la couche d'intégration des mots).
Lorsque la dimension cachée h est importante, les termes primaires 4h et 2h sont négligeables et le nombre de paramètres du modèle peut être approximé comme suit :
Nombre total de paramètres ≈ 12Lh² + Vh
8. estimation du nombre de participants au programme LLaMA
Le tableau suivant montre certains des paramètres clés des différentes versions de LLaMA et l'estimation de leur nombre de paramètres :
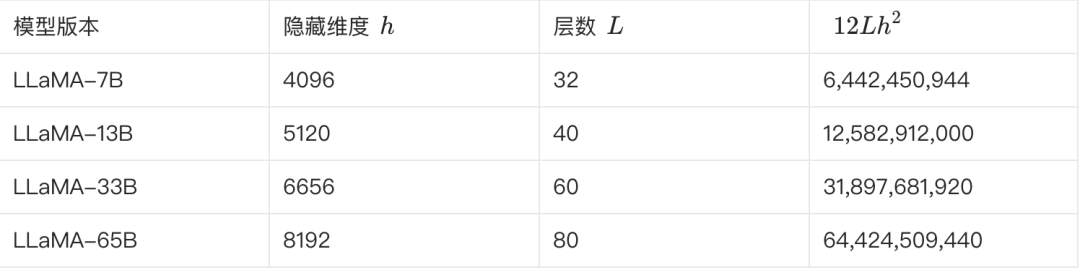
**Nous pouvons le vérifier à l'aide de la formule ci-dessus. Prenons l'exemple de LLaMA-7B, selon le tableau, L=32, h=4096, V=32000.**
Nombre estimé de paramètres ≈ 12 * 32 * 4096² + 32000 * 4096 ≈ 6.55B
Cette estimation est plus proche de 6,7 milliards. Plusieurs autres versions peuvent être estimées et validées de cette manière.
II. conversion des quantités paramétriques des grands modèles en tailles de modèles
Après avoir compris comment le nombre de paramètres est calculé, nous allons voir comment le nombre de paramètres et la taille du modèle sont convertis.
Nous utilisons toujours l'exemple de LLaMA-7B, qui compte environ 7 milliards de participants.
- Calculs théoriques. Si chaque paramètre est stocké au format FP32 (nombre à virgule flottante de 32 bits occupant 4 octets), la taille théorique de LLaMA-7B est de : 7B * 4 octets = 28GB.
- Stockage physique. Afin d'économiser de l'espace de stockage et d'améliorer l'efficacité des calculs, les poids des modèles sont généralement stockés dans un format de précision inférieure, tel que FP16 (nombre à virgule flottante de 16 bits occupant 2 octets) ou BF16. En utilisant le stockage FP16, la taille de LLaMA-7B est théoriquement : 7B * 2 octets = 14GB.
- Autres facteurs. Outre les paramètres de poids, le fichier de modèle peut également contenir des informations sur l'état de l'optimiseur (par exemple, l'élan et la variance de l'optimiseur Adam), la liste de mots, la configuration du modèle, etc. En outre, certains paramètres (par exemple, gamma et bêta pour la normalisation des couches) peuvent être stockés au format FP32.
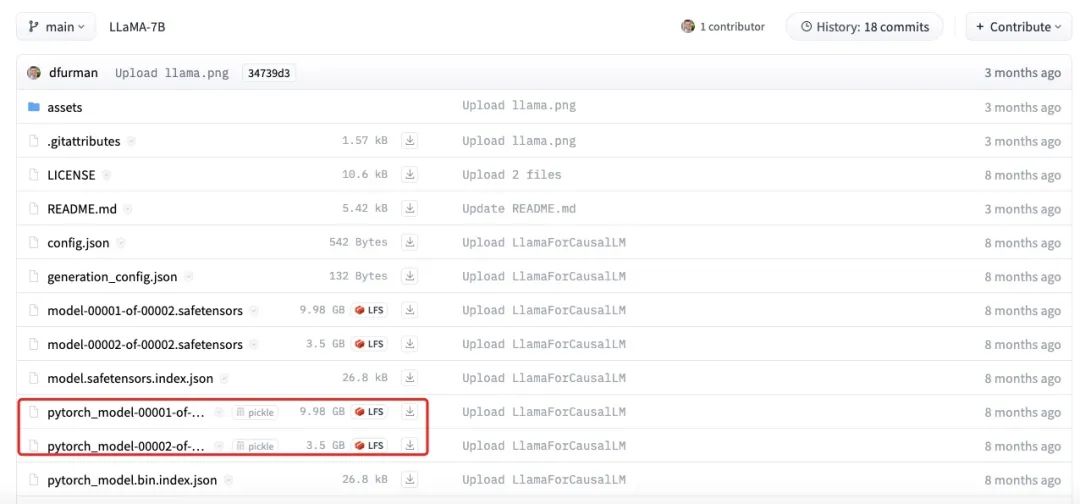
La figure ci-dessus montre la taille réelle du fichier du modèle LLaMA-7B. On peut voir que la taille totale de chaque partie est d'environ 13,5 Go, ce qui est plus proche de notre estimation de 14 Go. Les petites différences peuvent être dues à des erreurs d'arrondi, à des paramètres biaisés ou au fait que certains paramètres sont encore stockés en utilisant FP32.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...