Raisonnement complexe avec de grands modèles de l'OpenAI-o1
En 2022, OpenAI a lancé ChatGPT, qui est devenue l'application la plus rapide au monde à franchir le cap des centaines de millions d'utilisateurs, et à cette époque, les gens pensaient que nous étions plus proches de la véritable IA. Mais les gens ont vite découvert que ChatGPT pouvait avoir des conversations et même écrire des poèmes et des articles, mais qu'il n'était toujours pas satisfaisant en matière de logique simple, comme la fameuse "fraise" avec plusieurs tiges de "r".
Aujourd'hui, deux ans plus tard, OpenAI a publié le modèle o1, qui a suscité une discussion animée sur la méthodologie qui le sous-tend avec sa puissante capacité de raisonnement logique et la puissante capacité d'OpenAI à dissimuler la technologie. Dans cet article, nous avons passé au peigne fin certains articles connexes pour examiner le développement de la capacité de raisonnement complexe des grands modèles, en nous inspirant de la spéculation sur la technologie du modèle o1.
01 Contexte
La chaîne de pensée, ou CoT en abrégé, est un concept de psychologie cognitive et d'éducation qui décrit le processus progressif par lequel la pensée d'une personne se développe lorsqu'elle résout des problèmes ou prend des décisions. Plutôt que de passer directement d'une question à une réponse, le processus comporte plusieurs étapes, chacune pouvant impliquer la collecte, l'analyse, l'évaluation et la révision de conclusions antérieures. De cette manière, les individus sont capables de traiter des problèmes complexes de manière plus systématique et d'élaborer des solutions rationnelles.
Apprentissage superviséL'apprentissage supervisé est la forme la plus courante de formation de modèles dans le domaine de l'apprentissage automatique. Il utilise des ensembles de données étiquetées pour que le modèle apprenne à classer les données ou à prédire les résultats avec précision. Au fur et à mesure que les données d'entrée entrent dans le modèle, l'apprentissage supervisé ajuste les poids du modèle jusqu'à ce que le modèle produise un ajustement approprié.
Le "Supervised Fine-Tune", ou SFT en abrégé, fait référence à l'apprentissage supervisé, qui consiste à former un modèle avec un ensemble de données axé sur une tâche particulière, en plus d'un modèle de base existant, en vue de sa capacité à en tirer des enseignements pour résoudre la tâche en question.
Apprentissage par renforcementL'apprentissage par renforcement, ou RL en abrégé, est l'un des trois paradigmes de base de l'apprentissage automatique, avec l'apprentissage supervisé et l'apprentissage non supervisé. L'apprentissage par renforcement se concentre sur la recherche d'un équilibre entre l'exploration (l'inconnu) et l'exploitation (le connu), permettant aux modèles d'apprendre les bons comportements dans le but de maximiser les rendements à long terme.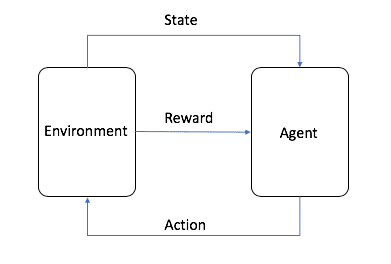
L'image provient d'AWS, comme le montre la figure, dans l'apprentissage par renforcement, l'agent est la cible ultime que nous devons former, il interagit avec l'environnement défini (Environnement) et génère une récompense et un transfert d'état, l'agent apprend sur la base de la récompense et choisit mieux l'action suivante, le cycle est donc le processus de formation. Ce cycle est le processus de formation de l'apprentissage par renforcement.
Dans le processus d'apprentissage du LLM, le RL joue un rôle important, et il est devenu un consensus dans l'industrie que la phase de pré-entraînement est alignée avec l'aide du RLHF. Dans l'apprentissage par renforcement du LLM, nous avons généralement besoin d'un autre modèle pour simuler l'environnement afin de récompenser la sortie du LLM, appelé modèle de récompense, ou RM en abrégé.
Nous aurons plusieurs modèles : le modèle de l'acteur, le modèle du critique et le modèle de la récompense. Conformément au cadre de formation RL standard décrit ci-dessus, l'acteur et le critique forment l'agent et la récompense est formée en tant qu'environnement dans le processus de formation RL.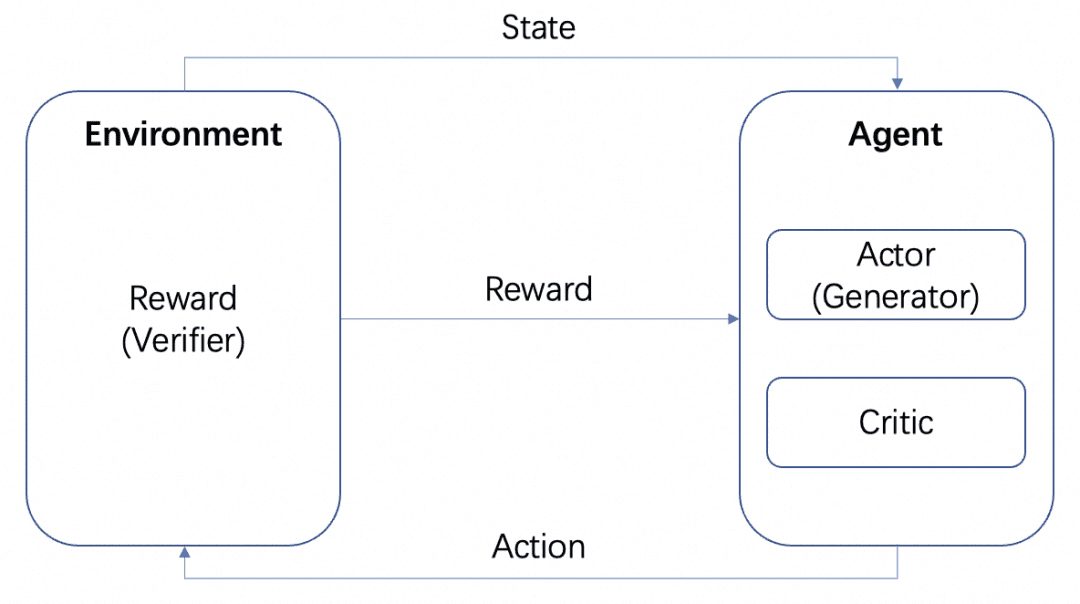
Mais après l'entraînement, nous pouvons déployer des modèles d'Acteur ou de Récompense séparément, où le modèle d'Acteur est notre Générateur et le modèle de Récompense est le Vérificateur que nous utilisons pour mesurer la qualité de la génération du Générateur, ce qui est la structure Générateur-Vérificateur que l'OpenAI mentionne dans l'article Let's verify step by step. Il s'agit de la structure Générateur-Vérificateur mentionnée dans l'article Let's verify step by step de l'OpenAI.
Les modèles de récompense peuvent être classés en fonction du degré de détail du retour d'information :
Modèle de récompense basé sur le processus PRM : le PRM fournit un retour d'information basé sur les résultats intermédiaires du LLM.
-Modèle de récompense basé sur les résultats ORM : l'ORM ne donne un retour d'information qu'après le résultat final.
Ces deux concepts sont abordés ci-dessous dans des scénarios spécifiques.
Recherche arborescente de Monte Carlo La recherche arborescente de Monte Carlo, ou MCTS, est un algorithme de recherche arborescente dont l'idée principale est qu'à chaque étape, plusieurs comportements sont tentés et les gains futurs possibles de ces comportements sont prédits, en se concentrant sur l'exploration sélective de certains des comportements les plus gratifiants.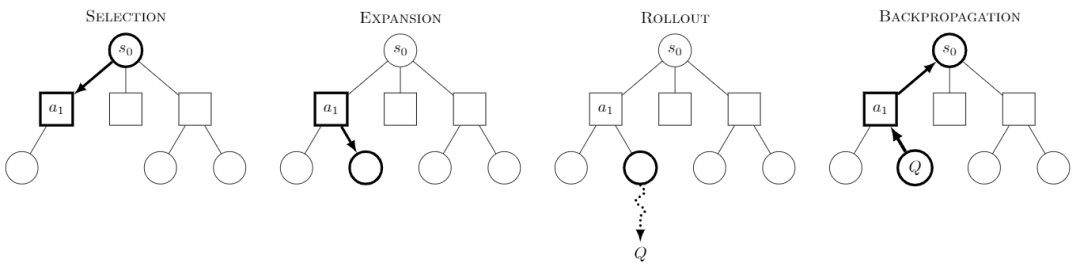
Image tirée de Wikipedia. Chaque quête serait divisée en quatre étapes :
-Sélection : sélection d'un nœud
-Expansion : génère un nouveau nœud à partir de ce nœud à explorer.
-Rollout : effectuer une simulation le long de ce nouveau nœud pour produire un résultat.
-Propagation vers l'arrière : les résultats de la simulation sont propagés vers l'arrière, mettant à jour les nœuds sur les chemins.
En explorant continuellement, nous obtenons un arbre dont chaque nœud contient un résultat possible de l'exploration et nous pouvons effectuer une recherche dans cet arbre pour obtenir le meilleur chemin ou résultat.
Les SCTM pour RL ont produit des modèles bien connus tels qu'AlphaZero, qui exécute les étapes de sélection et de déploiement en utilisant des modèles entraînables, réduisant ainsi le vaste espace de recherche et le coût de simulation des SCTM afin d'obtenir efficacement la solution optimale. L'approche d'AlphaZero consiste à utiliser des modèles entraînables pour effectuer les étapes de sélection et de déploiement, réduisant ainsi le vaste espace de recherche et le coût de simulation des SCTM afin d'obtenir efficacement la solution optimale. Par exemple, en utilisant le Policy Network pour rechercher efficacement la prochaine étape possible, et en utilisant le Value Network pour déterminer la valeur de chaque étape au lieu de la simulation de déploiement.
La capacité de raisonnement en plusieurs étapes de o1 En ce qui concerne le modèle o1, nous devons parler de son étonnante capacité de raisonnement en plusieurs étapes, et le site web de l'OpenAI donne plusieurs exemples pour montrer sa capacité de raisonnement en plusieurs étapes dans les mots de passe, les codes, les mathématiques, les mots croisés, et ainsi de suite. Dans l'exemple relatif au "mot de passe", le résultat du décodage est "THERE ARE THREE R'S IN STRAWBERRY", qui est également le résultat du "mot de passe" existant. ChatGPT Capacité de raisonnement pour répondre.
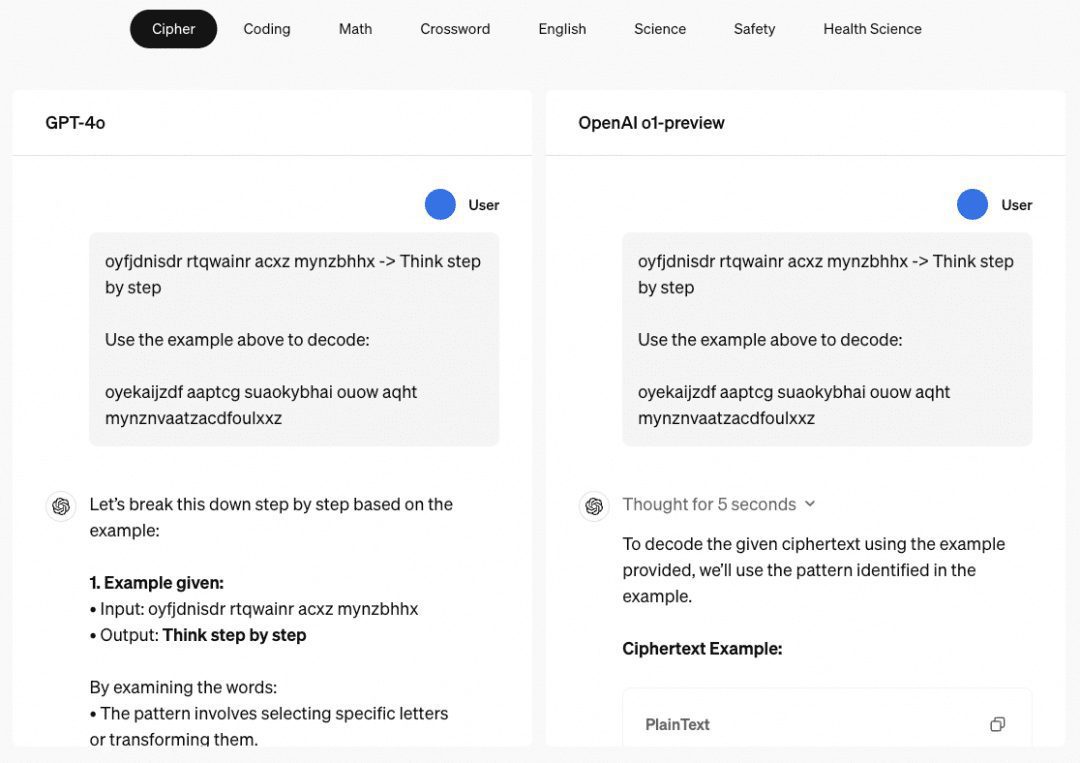
Nous avons donc étudié un certain nombre d'articles, principalement à ce titre, qui ont été rassemblés et résumés comme décrit ci-dessous.
02 Ingénierie du mot de repère
Actuellement, l'apprentissage de l'IA nécessite généralement une grande quantité de données d'exemple, alors que l'apprentissage avec très peu de données d'exemple est appelé Few-Shot, ou Zero-Shot, si aucun exemple n'est donné.
L'article "Chain of Thought Prompting Elicits Reasoning in Large Language Models" propose une approche Few-Shot pour améliorer le raisonnement mathématique des modèles :
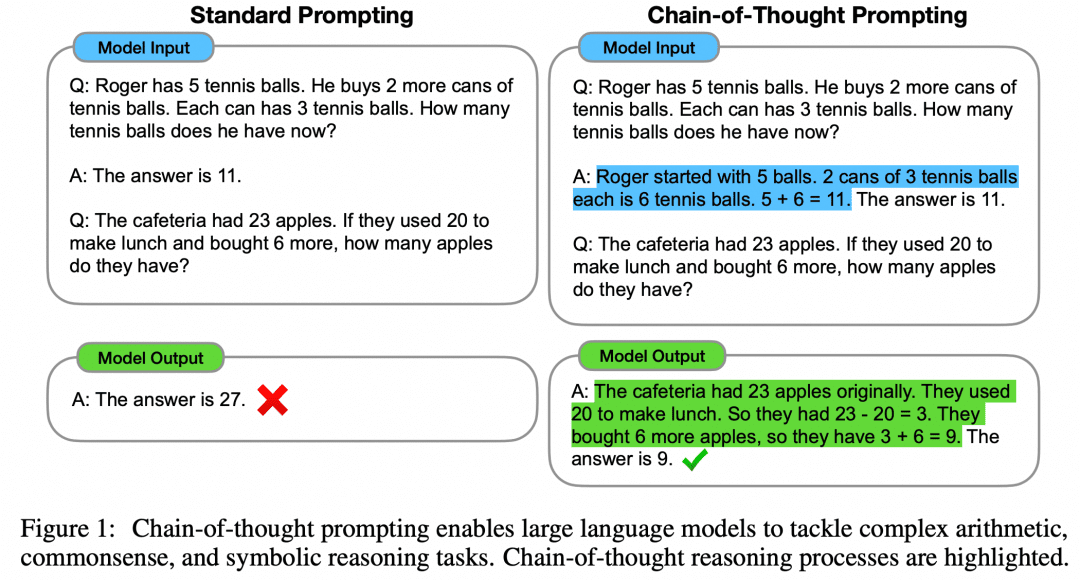
Comme le montre la figure, le côté gauche donne un exemple au LLM pour qu'il apprenne dans l'invite de l'entrée LLM, ce qui est l'apprentissage à la petite semaine, mais son effet n'est pas encore satisfaisant. Le document propose ce paradigme Few-Shot avec CoT sur le côté droit. Ainsi, à droite, dans Few-Shot, non seulement la question et la réponse d'un exemple sont données, mais aussi le processus intermédiaire et le résultat. Les auteurs ont constaté que l'invite Few-Shot ainsi construite à l'aide de CoT améliore l'inférence du modèle.
Au fur et à mesure que le modèle s'améliore et que les recherches se poursuivent, l'article "Large Language Models are Zero-Shot Reasoners" révèle que Zero-Shot peut également utiliser CoT pour améliorer les capacités du modèle :

Au lieu de se donner la peine de construire un processus intermédiaire de CdT, ou même de construire des exemples pour Few-Shot, un simple "Réfléchissons étape par étape" peut améliorer le LLM. C'est une évidence. Cette invitation a été reprise et modifiée par OpenAI en "Vérifions étape par étape", et ce document est maintenant au cœur des lectures répétées de tous ceux qui veulent comprendre o1.
Bien entendu, la construction de CoT sur l'ingénierie des mots repères ne peut à elle seule expliquer la puissance de o1, mais CoT, une approche progressive de l'avancement de la logique, est devenue l'orientation dominante de l'augmentation du raisonnement dans les modèles de grande taille.
03 CoT + réglage fin supervisé
Bien sûr, il y a eu des tentatives pour enseigner les capacités de raisonnement en plusieurs étapes de CoT aux LLM en utilisant SFT. "STaR : Bootstrapping Reasoning With Reasoning" est une des premières tentatives. L'image ci-dessous est tirée de cet article :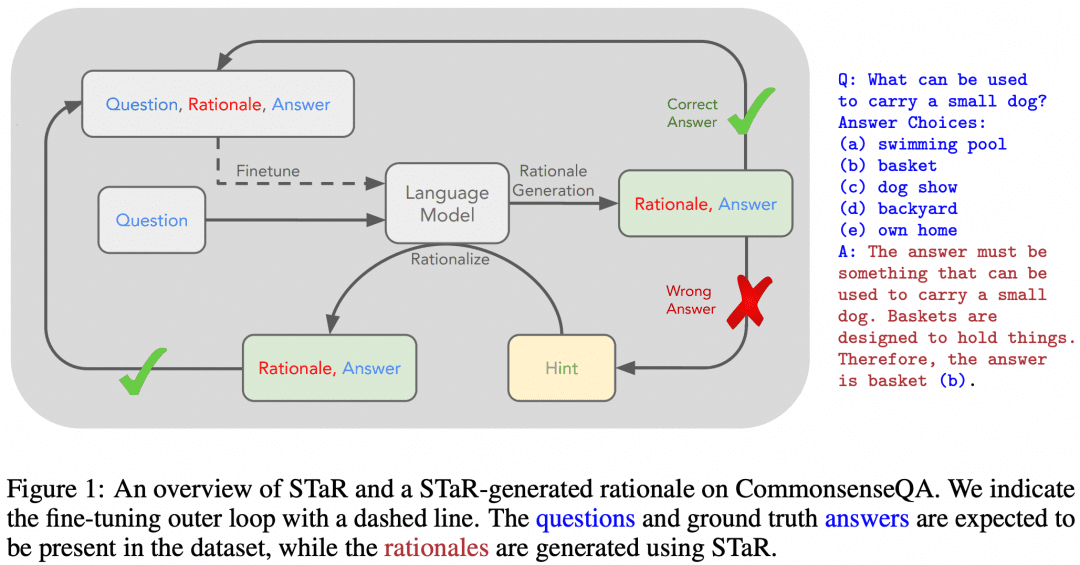
L'idée de l'article est la suivante. Tout d'abord, nous utilisons l'approche d'ingénierie des mots repères décrite ci-dessus pour que le modèle essaie de raisonner sur l'ensemble des données à l'aide de la méthode CoT, ce qui se traduira par un lot de réponses, qui comporteront naturellement des réponses correctes et des réponses erronées :
Si nous obtenons une réponse correcte, nous considérons le CoT correspondant généré par le modèle comme un CoT de haute qualité, puis nous collectons de tels échantillons "question-CoT-réponse" de haute qualité pour obtenir un nouvel ensemble de données, et nous utilisons cet ensemble de données pour tester notre LLM, et en continuant à tourner en boucle, nous pouvons obtenir le LLM avec une meilleure capacité de raisonnement. LLM ;
S'il y a des questions auxquelles LLM répond toujours mal, alors nous laissons directement LLM voir "Question+Réponse" et le laissons générer un CoT de la question à la réponse, nous pouvons penser que le CoT généré par LLM est correct lorsque la réponse est connue, et alors cette partie de l'échantillon "Question-CoT-Réponse" peut également être utilisée pour la formation. Question-CoT-Réponse" peut également être utilisée pour la formation.
Comme cette étude est assez ancienne, il est facile d'en trouver les failles aujourd'hui, par exemple, le LLM a souvent "un mauvais processus mais un bon résultat" ou "un bon processus mais un mauvais résultat", ce qui signifie que les échantillons que nous avons utilisés pour la formation ci-dessus ne sont en fait pas d'une très grande qualité. Cela signifie que les échantillons que nous avons utilisés pour la formation ne sont pas vraiment de très bonne qualité. Comment obtenir un processus d'inférence plus correct ?
04 Recherche arborescente de Monte Carlo
Nous avons appris ci-dessus que la CdT décompose la logique de la question à la réponse en processus de pensée intermédiaire après processus de pensée intermédiaire. Les SCTM peuvent-ils donc être utilisés pour rechercher la meilleure étape de pensée pour l'étape de raisonnement suivante, et donc la meilleure chaîne de pensées de raisonnement ? Naturellement, oui.
Mutual Reasoning Makes Smaller LLMs Stronger Les résolveurs de problèmes ont conçu un tel algorithme MCTS, appelé rStar, et ils ont ouvert le projet sur GitHub. L'image ci-dessous est tirée de l'article, et ne présente-t-elle pas une certaine ressemblance avec l'image MCTS ci-dessus ?
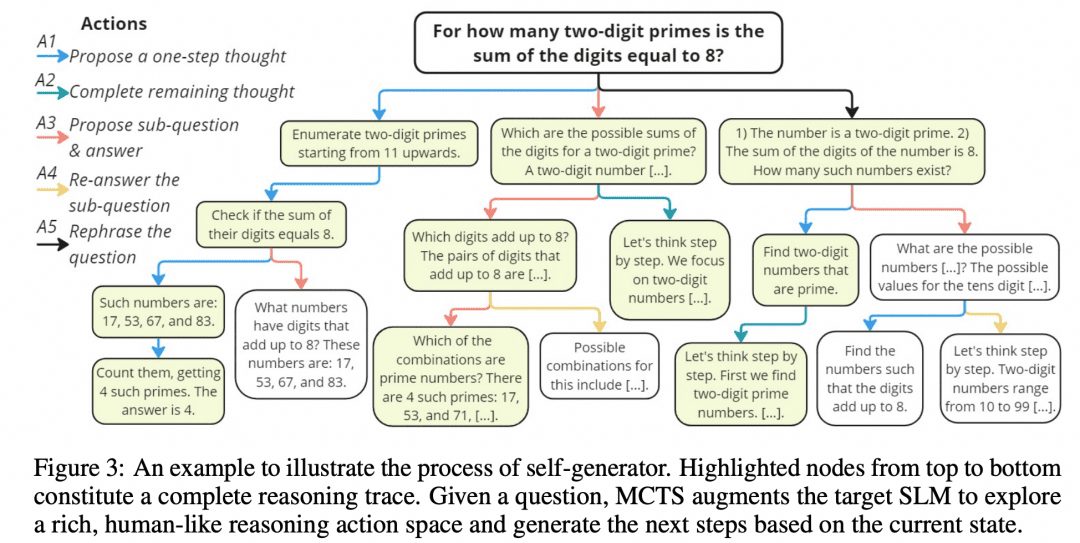
Comme le montre la figure ci-dessus, les chercheurs ont divisé les étapes intermédiaires du CoT en 5 types de nœuds :
1. générer les étapes suivantes du raisonnement
2. générer tous les raisonnements ultérieurs
3. générer une sous-question et une réponse
4. répondre à nouveau aux sous-questions
5. les problèmes de reconfiguration
Les SCTM sont ensuite utilisés pour déterminer le nœud de réflexion suivant. Le chemin relié par nœud après nœud de pensée est le CdT. Nous prenons simplement tous les résultats finaux que nous obtenons et nous les votons.
Bien sûr, les auteurs ont étudié plus que cela, comme mentionné ci-dessus, il est nécessaire de pouvoir mesurer la justesse des nœuds et la justesse du raisonnement à chaque étape, et les chercheurs ont conçu la méthode suivante :
-Filtrage discriminant : après avoir obtenu le chemin d'inférence original, on en masque aléatoirement une partie, puis on utilise un autre modèle pour la sortie ; si l'on obtient le même résultat que le générateur original, alors le chemin d'inférence original est fiable.
-L'exactitude de la réponse : toutes les réponses finales sont collectées et la proportion d'une réponse particulière par rapport à toutes les réponses est le score de la réponse.
-L'exactitude du processus : pour chaque nœud de raisonnement dans le chemin, un certain nombre de nœuds de type 2 sont générés en parallèle pour générer un certain nombre de résultats finaux en une étape, et la proportion de ces résultats qui sont le résultat final du chemin actuel est considérée comme le score de processus de ce nœud de raisonnement. La mesure en trois parties conduit à un chemin optimal, et le résultat final du chemin optimal est considéré comme le résultat des SCTM.
05 Générateur + Vérificateur
Outre les SCTM susmentionnés, qui permettent d'organiser les processus de pensée en arbres et de les explorer, il existe d'autres moyens d'y parvenir. L'apprentissage par renforcement, par exemple, et nous reviendrons sur l'introduction à l'apprentissage par renforcement :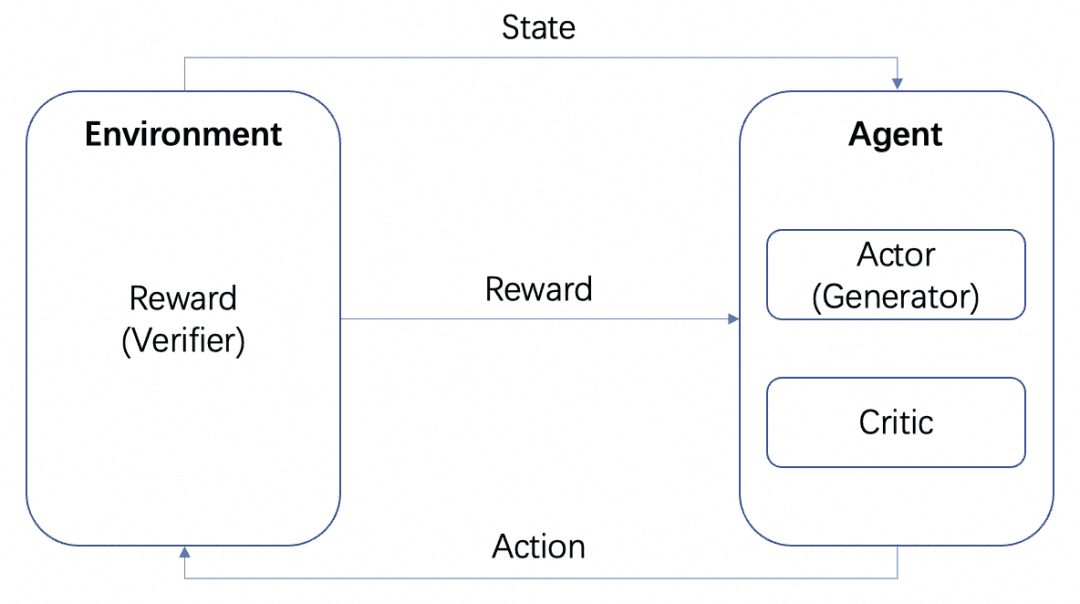
Si nous prenons le LLM comme Acteur, un autre RM formé au problème comme Environnement, et un Critique implicite, une boucle d'apprentissage par renforcement serait : l'Acteur produit un résultat pour le problème, le RM vérifie l'exactitude du résultat et le renvoie à l'Agent, et l'Acteur et le Critique s'entraînent en fonction de la Récompense. L'acteur et le critique sont formés en fonction de la récompense. Nous appelons l'agent "générateur", car sa tâche consiste à générer le résultat, et le gestionnaire "vérificateur", car sa tâche consiste à vérifier le résultat.
Si l'on y réfléchit, la relation entre l'acteur et le critique au sein d'un agent n'est-elle pas très similaire à la politique et au réseau de valeurs utilisés par AlphaZero ? Il est également vrai que les réseaux de politiques et de valeurs s'inscrivent dans le cadre de l'acteur et du critique.
Nous résumons maintenant qu'un processus d'apprentissage par renforcement implique trois réseaux, l'Acteur, le Critique et le RM. Dans le déploiement, différents cadres sont utilisés en fonction de la situation : dans un jeu de société, le gagnant ne peut être connu qu'à la fin du jeu, et la récompense donnée par le RM est trop faible, nous choisissons donc de conserver le cadre Acteur-Critique dans le déploiement, puis d'exécuter le MCTS pour une meilleure solution ; tandis que dans le déploiement LLM, notre RM formé peut fournir un retour d'information en temps opportun, nous pouvons donc naturellement combiner l'Acteur et le RM dans un cadre Générateur-Vérificateur dans le déploiement. Dans le déploiement LLM, notre RM formé peut fournir un retour d'information opportun, de sorte que nous pouvons naturellement combiner l'acteur et le RM dans le cadre du générateur-vérificateur au moment du déploiement.
OpenAI travaille dans ce sens depuis l'époque de GPT3 (ChatGPT est basé sur le modèle GPT-3.5). La solution qu'ils ont donnée est le document Training Verifiers to Solve Math Word Problems (Former des vérificateurs pour résoudre des problèmes mathématiques). L'image ci-dessous est tirée de ce document :
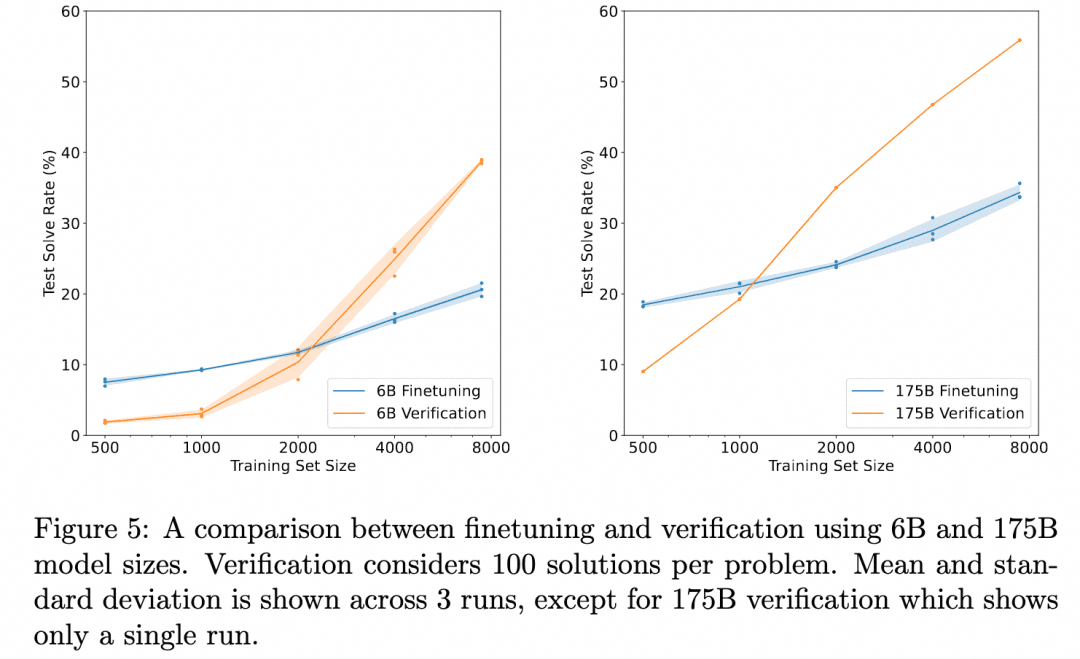
Le graphique ci-dessus compare : "L'exactitude des résultats obtenus en affinant simplement le générateur" avec "L'exactitude des résultats obtenus en affinant un vérificateur, en évaluant plusieurs résultats produits par le générateur et en sélectionnant le résultat le mieux noté". Cela démontre l'efficacité du vérificateur.
En effet, la tâche consiste ici à raisonner sur le problème pour obtenir le résultat. Le générateur utilisé ne produit donc pas de processus de raisonnement intermédiaire, mais produit directement le résultat, et le vérificateur est également l'ORM (Outcome Based Reward Model) que nous avons mentionné dans la section sur l'apprentissage par renforcement, qui sert à produire un score basé sur le résultat du générateur. Il n'y a donc pas ici de processus d'inférence en plusieurs étapes que nous voulons explorer, mais simplement la découverte que la validation ORM donne de meilleurs résultats finaux qu'un simple réglage fin.
L'équipe de l'OpenAI est donc allée plus loin : d'une part, elle a fait en sorte que le générateur ne produise plus de résultats directement, mais plutôt un raisonnement étape par étape ; d'autre part, elle a formé un PRM (Process-based Reward Model) qui agit comme un vérificateur, dont le rôle est de produire un score pour chaque étape du processus de raisonnement du générateur. Nous pensons que les résultats obtenus en recherchant l'exactitude du processus de raisonnement du générateur de cette manière sont les plus susceptibles d'être corrects.
Il s'agit de l'étude Let's verify pas à pas mentionnée ci-dessus. Dans ce travail, l'équipe a comparé les résultats d'inférence générés en recherchant le même générateur avec PRM et ORM comme vérificateurs (à ce stade, leur générateur était déjà GPT-4), et a prouvé que PRM comme vérificateur recherchait des résultats plus précis. La figure ci-dessous est tirée de l'article :
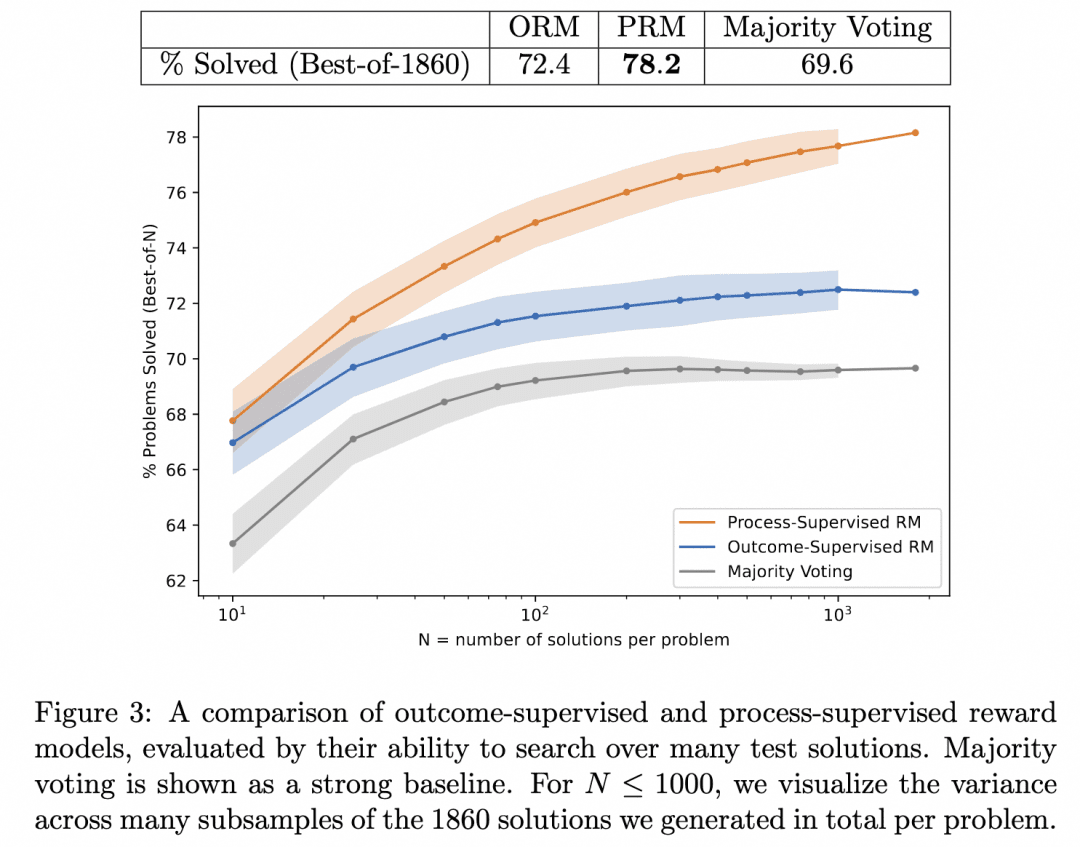
La figure ci-dessus montre que le même générateur d'inférence par étapes produit des résultats pour lesquels il est valable d'utiliser l'ORM comme vérificateur pour choisir la meilleure réponse pour le résultat, mais que nous avons plus de chances d'être corrects lorsque nous utilisons le PRM comme vérificateur pour choisir la meilleure réponse pour le processus !
S'agit-il de la technologie de l'o1 que nous recherchons ? Nous ne pouvons que supposer à ce stade qu'il s'agit de l'une des technologies de base de l'o1. Les raisons en sont les suivantes :
1, ce document est relativement éloigné de la sortie de o1, et un an est suffisant pour que les chercheurs de l'OpenAI approfondissent cette direction. En raison de la validité du MRP, bien qu'une année soit également suffisante pour s'adapter à d'autres directions, nous pensons toujours qu'ils vont plus loin plutôt que de faire demi-tour.
2) L'article démontre l'efficacité du MPR en tant que vérificateur, et il est clair que l'étape suivante pourrait être d'améliorer le générateur avec un vérificateur puissant pour produire de meilleurs résultats. Mais le document ne va pas dans ce sens, et nous avons donc des raisons de croire qu'OpenAI a dû essayer, et il n'est pas certain que le résultat ait été o1.
Cette supposition étant faite, passons à l'exploration d'autres façons d'utiliser Verifier pour la recherche. L'article "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters", publié par Google DeepMind en août dernier, approfondit la recherche. Cet article est considéré par beaucoup comme montrant une ligne technique similaire aux principes derrière o1. La figure ci-dessous est tirée de cet article :
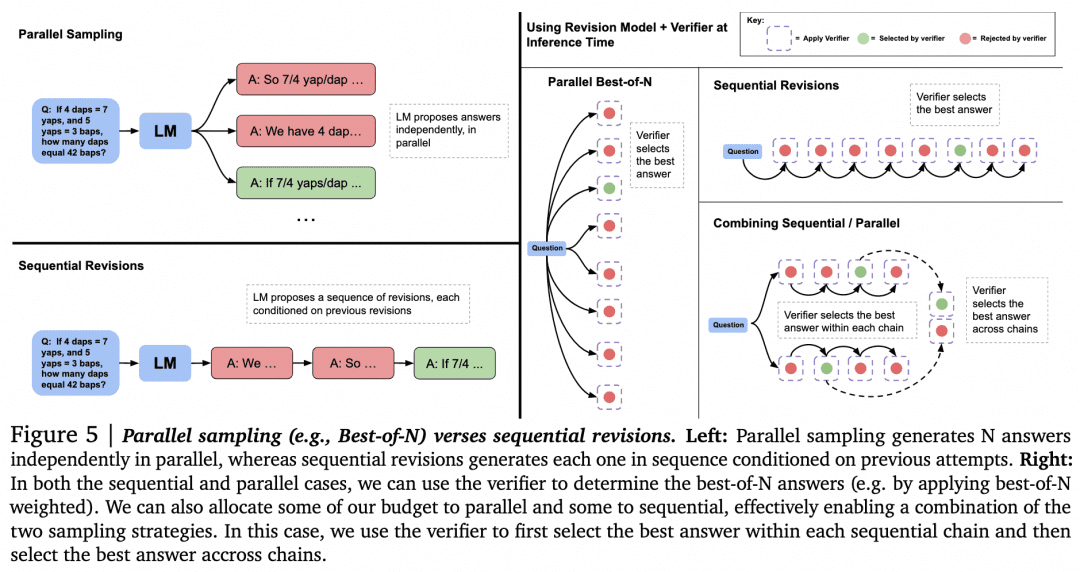
Maintenant que nous disposons d'un générateur et d'un vérificateur, comment pouvons-nous les faire travailler ensemble pour obtenir les meilleurs résultats ? Comme nous l'avons mentionné plus haut, l'une des solutions consiste à demander au générateur d'échantillonner en parallèle pour obtenir plusieurs résultats, et au vérificateur de les évaluer et de choisir le score le plus élevé. Il s'agit de l'approche "Parallel Sampling + Best-of-N" à gauche dans la figure ci-dessus. Mais il existe évidemment d'autres approches :
Lors de la génération de plusieurs résultats, outre l'échantillonnage de plusieurs résultats en parallèle, il est également possible que le générateur génère un résultat, puis vérifie et corrige le résultat lui-même pour obtenir une séquence de réponses, où elles ne sont plus en parallèle les unes avec les autres.
-Il peut y avoir des alternatives à Best-of-N lorsque la sélection est faite par le vérificateur. Comme le montre la figure suivante tirée de l'article :
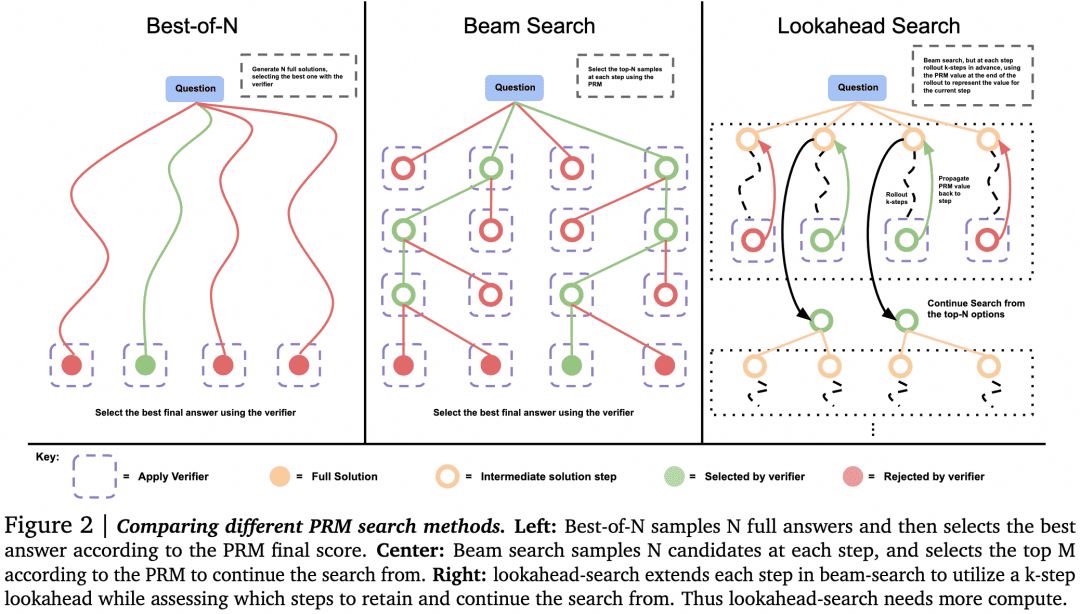
L'article a montré que pour les problèmes simples, nous devrions utiliser Verifier pour encourager Generator à s'autocontrôler et à corriger, plutôt que d'effectuer une recherche aveugle en parallèle. Pour les problèmes complexes, il est préférable que le Generator essaie différentes solutions en parallèle.
Un travail similaire est A Comparative Study on Reasoning Patterns of OpenAI's o1 Model (Étude comparative des schémas de raisonnement du modèle o1 de l'OpenAI). L'équipe de l'article a ouvert Open-o1, une réplique de o1, sur GitHub, et cet article est le résultat de certaines de leurs recherches après la publication de o1. L'image ci-dessous est tirée de l'article :
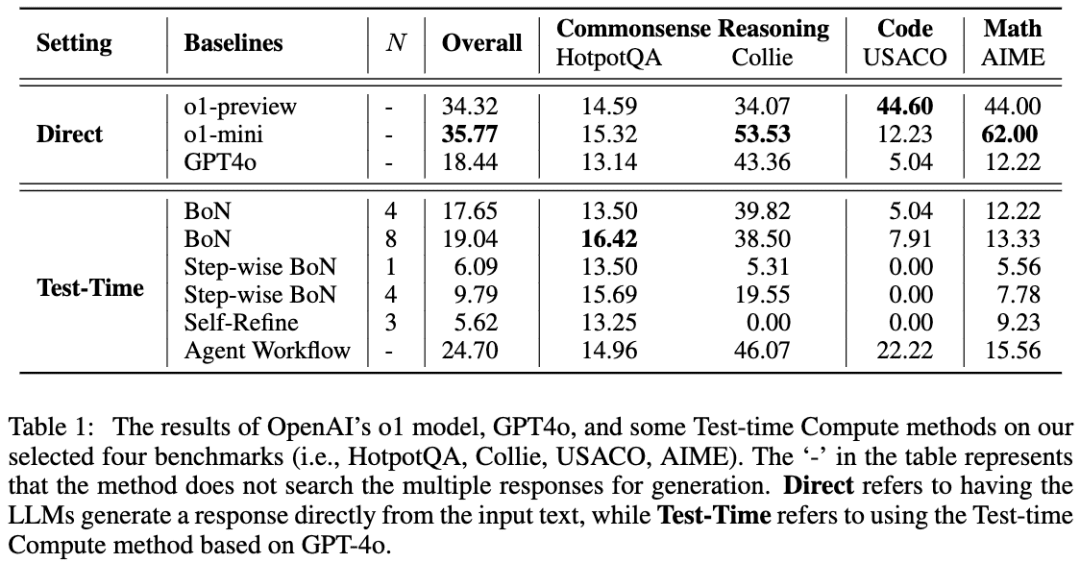
L'équipe a utilisé GPT-4o comme modèle squelette, puis a comparé ses résultats en utilisant quatre approches courantes pour amener les LLM à réfléchir avant de raisonner. L'équipe a constaté que sur la tâche HotpotQA, les approches Best-of-N et Step-wise BoN ont permis d'améliorer de manière significative le raisonnement du LLM, BoN permettant même à GPT-4o de surpasser le modèle o1.
06 OpenR
Parmi les projets open source actuels qui tentent de reproduire o1, OpenR est l'un des plus aboutis.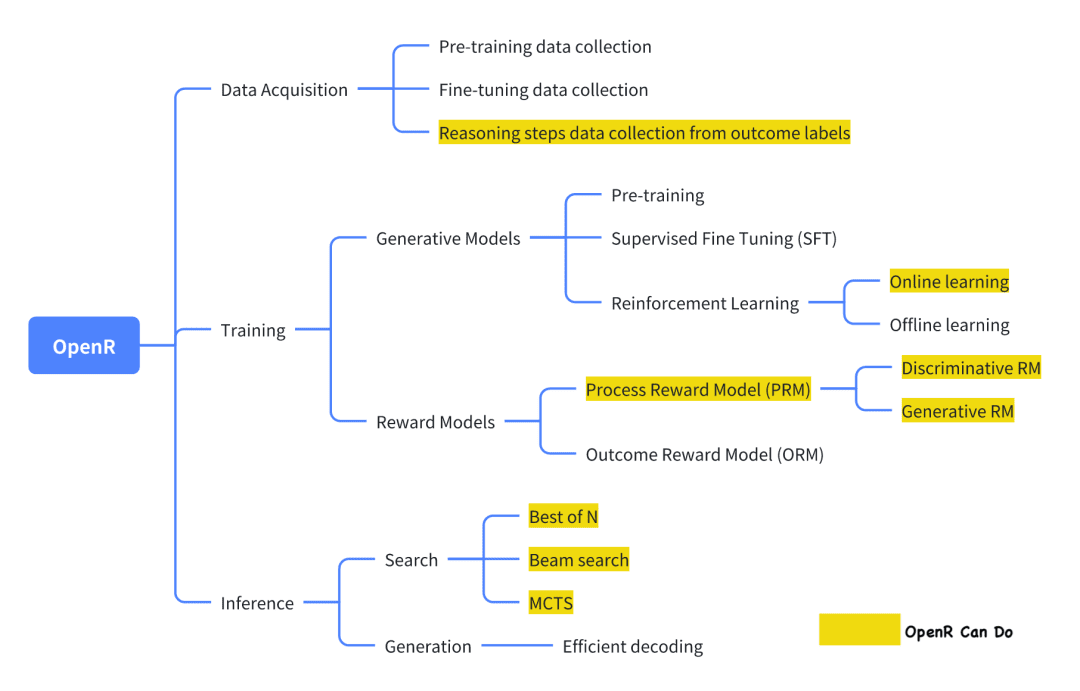
L'image est tirée de sa documentation officielle, qui, en l'état, met en œuvre la collecte de données ainsi que la formation et le déploiement conformément au cadre Générateur-Vérificateur.
Collecte des données Selon l'introduction officielle, la méthode de collecte des données est tirée de l'article intitulé "Improve Mathematical Reasoning in Language Models by Automated Process Supervision" (Améliorer le raisonnement mathématique dans les modèles linguistiques par la supervision automatisée des processus). En bref, il s'agit d'utiliser les SCTM pour étendre l'ensemble de données original problème-réponse_finale afin de générer des étapes d'inférence CoT. Enfin, un ensemble de données MATH-APS est obtenu.
Les jeux de données pertinents ont été hébergés sur ModelScope :
Ensemble de données PRM800K-Stepwise :
https://modelscope.cn/datasets/AI-ModelScope/openai-prm800k-stepwise-critic/
Ensemble de données MATH-APS :
https://modelscope.cn/datasets/AI-ModelScope/MATH-APS/
Ensemble de données Math-Shepherd :
https://modelscope.cn/datasets/AI-ModelScope/Math-Shepherd
En bref, l'algorithme PPO utilise les informations de récompense fournies par le modèle de récompense pour former le générateur, tout en limitant l'acteur afin qu'il ne s'écarte pas trop de l'acteur original au cours du processus d'apprentissage, pour éviter de perdre les connaissances existantes. Actuellement, OpenR prend en charge trois variantes : APPO, GRPO et TPPO.
L'équipe de formation de Virifier a utilisé l'apprentissage supervisé SFT pour former un MRP en utilisant l'ensemble de données MATH-APS ci-dessus, ainsi que deux ensembles de données open source, PRM800K et Math-Shepherd. Plus précisément, sur ces trois ensembles de données au niveau de l'étape, l'équipe a étiqueté chaque étape avec une étiquette "+" ou "-", puis a demandé au PRM d'apprendre à prédire l'étiquette de chaque étape et de déterminer si elle était correcte ou incorrecte.
Le modèle utilise des données "par étapes" pour la formation des OPP, et les poids du modèle qui en résultent ont été hébergés dans ModelScope, qui fournit actuellement des points de contrôle pour les modèles SFT, PRM et RL, ainsi que pour certains formats GGUF :
Le modèle mistral-7b-sft :
https://modelscope.cn/models/AI-ModelScope/mistral-7b-sft
Modèle RL (version GGUF) :
https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-rl-GGUF
Modélisation des PMR :
Version GGGUF : https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-prm-GGUF
Modèle RPM : https://modelscope.cn/models/AI-ModelScope/math-shepherd-mistral-7b-prm
Déploiement du raisonnement Au moment du déploiement, OpenR utilise des algorithmes de recherche à travers le générateur et le vérificateur spécifiés pour obtenir le processus de raisonnement et la réponse finale. Actuellement, MCTS, Beam Search et best_of_n sont pris en charge.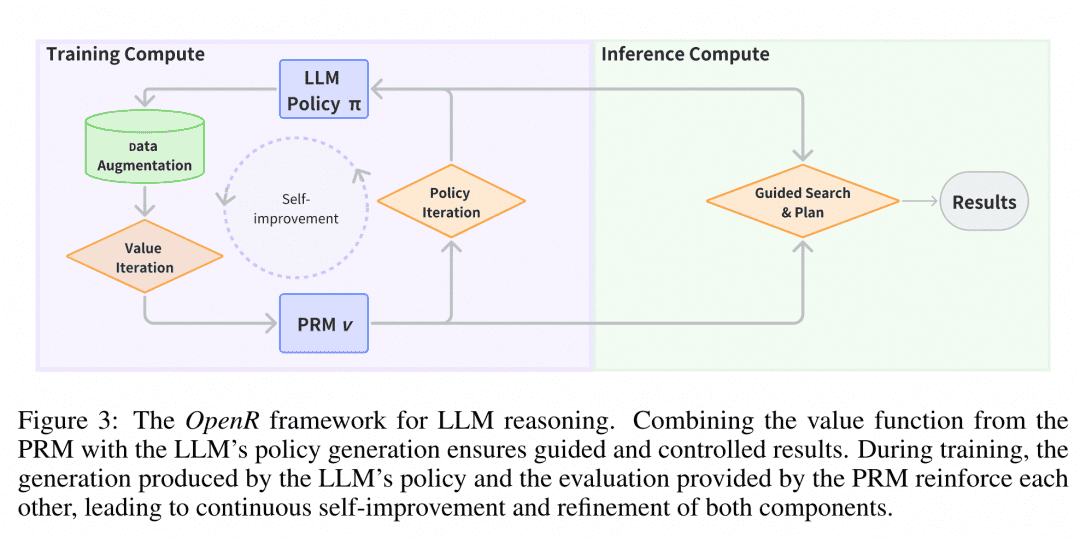
L'image est tirée de l'article "OpenR : An Open Source Framework for Advanced Reasoning with Large Language Models". La structure d'OpenR est illustrée dans la figure, et jusqu'à présent, OpenR met en œuvre une réplique de la chaîne d'O1, de la collecte des données d'entraînement à l'entraînement d'un PRM, à l'utilisation du PRM pour renforcer l'apprentissage, et enfin au déploiement du modèle. OpenR met actuellement en œuvre une chaîne qui reproduit O1, de la collecte des données d'entraînement à l'entraînement d'un MRP, à l'utilisation du MRP pour renforcer l'apprentissage et au déploiement du modèle pour la recherche. L'équipe a mis tout ce travail en open source pour que la communauté puisse en tirer des enseignements et l'essayer, ce qui nous permet d'en avoir un aperçu.
Expérience de l'espace créatifNous avons déployé le service d'inférence d'OpenR dans l'espace créatif de la communauté Magic Hitch, et les développeurs peuvent expérimenter les effets d'OpenR en ligne en visitant le lien suivant : https://www.modelscope.cn/studios/modelscope/OpenR_Inference.
07 Conclusion
Les articles ci-dessus sur le raisonnement à plusieurs étapes que nous avons étudiés démontrent que permettre au LLM de raisonner étape par étape au lieu de sauter les processus intermédiaires peut améliorer de manière significative sa précision sur les problèmes liés à la logique. Afin de permettre au LLM de raisonner étape par étape, nous pouvons l'affiner en utilisant des ensembles de données avec des processus intermédiaires, en plus de le guider avec une ingénierie simple de mots repères. Plus efficacement, nous pouvons former un vérificateur qui peut vérifier pas à pas la précision du générateur pour rechercher les résultats générés par le générateur.
D'après les spéculations et les articles publiés jusqu'à présent, il semble que la technologie probable vers o1 soit précisément basée sur la coopération entre le puissant générateur LLM et le vérificateur LLM. Ce type de pied gauche sur pied droit, qui s'itère contre lui-même, n'est pas une première dans l'apprentissage profond, mais OpenAI est la première à introduire un tel modèle dans le domaine du LLM, qui est très coûteux rien que pour former le Générateur, ce qui est vraiment une grosse affaire.
Par conséquent, nous pensons que si nous voulons reproduire o1, la première chose dont nous avons besoin est un vérificateur qui peut fournir une assistance et des conseils au générateur, et afin de générer les données nécessaires pour former le vérificateur, nous pouvons nous référer aux chapitres CoT + Supervised Fine-Tune et Monte Carlo Tree Search ci-dessus pour obtenir des données de meilleure qualité à un moindre coût. Afin de générer les données nécessaires à l'entraînement du Verifier, on peut se référer aux chapitres CoT + Supervised Fine-Tune et Monte Carlo Tree Search ci-dessus pour obtenir des données de meilleure qualité à moindre coût. C'est pourquoi nous avons également présenté ces tâches.
Enfin, nous avons présenté un projet open source très abouti et, sur la base de leur travail, nous avons pu organiser nos réflexions et nos idées.
08 Référence
L'incitation à la chaîne de pensée suscite le raisonnement dans de grands modèles linguistiques
Les grands modèles linguistiques sont des raisonneurs à coup zéro
STaR : Bootstrapping Reasoning With Reasoning (raisonner avec le raisonnement)
Le raisonnement mutuel permet aux petits LLM de mieux résoudre les problèmes
Former les vérificateurs à la résolution de problèmes mathématiques
Vérifions étape par étape
La mise à l'échelle du calcul optimal du temps de test du LLM peut être plus efficace que la mise à l'échelle des paramètres du modèle.
Étude comparative des schémas de raisonnement du modèle o1 de l'OpenAI
OpenR : Un cadre Open Source pour le raisonnement avancé avec de grands modèles de langage
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...