






























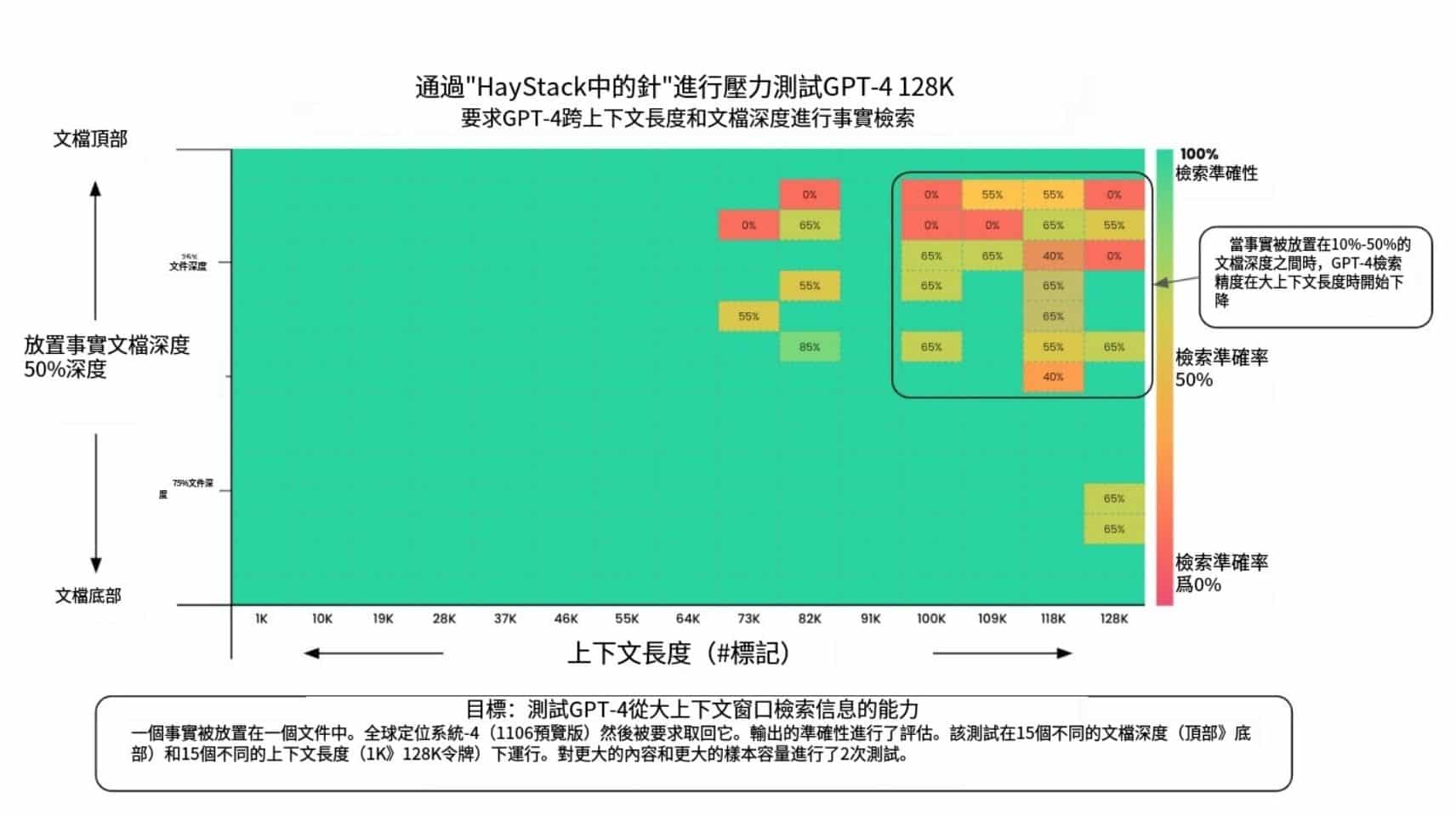
Claude 3.7 Sonnet Full Experience : Chaînes gratuites, détails de l'API, activation du raisonnement
Récemment, Anthropic Inc. a lancé Claude Une mise à jour du modèle 3.5 Sonnet - Claude 3.7 Sonnet. Bien qu'elle n'ajoute que 0.2 au numéro de version, cette mise à jour apporte un certain nombre de changements à la fois en termes de performances et de fonctionnalités. La dernière mise à jour du modèle Claude remonte à plus de quatre mois, ce qui est long dans le domaine de l'intelligence artificielle qui évolue rapidement.

Il est généralement admis dans l'industrie que les modèles ne sont pas mis à niveau directement à la version 4.0 sans une avancée architecturale.
Accès gratuit
| Nom du site | Adresses (certaines nécessitent un accès à l'internet scientifique) | version du modèle | mode d'inférence | Fenêtre contextuelle (jetons) | Production maximale (jetons) | fonction de mise en réseau | Limites journalières/coûts | spécificités |
|---|---|---|---|---|---|---|---|---|
| Site officiel de Claude | https://claude.ai/ | 3.7 Sonnet | déduction | Environ 32K | Environ 8K | sans soutien | Les utilisateurs gratuits sont limités, les utilisateurs payants sont limités par jeton (normal/étendu). | La plateforme officielle, avec un petit montant pour les utilisateurs gratuits et une limite pour les utilisateurs payants. |
| lmarena | https://lmarena.ai/ | 3.7 Sonnet/32k Réflexion | Non-raisonnement/raisonnement | 8K / 32K | 2K (max. 4K) | sans soutien | Semble être illimité | Fournit des modes de non-inférence et d'inférence 32k avec un nombre maximum de jetons de sortie réglable. |
| Genspark | https://www.genspark.ai/ | 3.7 Sonnet | déduction | non concluant | non concluant | adjuvant | 5 séances gratuites par jour | Prise en charge des recherches en réseau pour les scénarios dans lesquels vous devez obtenir les informations les plus récentes. |
| Poe | https://poe.com/ | 3.7 Sonnet/Pensée | Non-raisonnement/raisonnement | 16K / 32K (max. 64K) | accordable | sans soutien | Points bonus quotidiens, 3.7 Sonnet 333 points par session, Pensée 2367 points par session | Ajustement flexible de la fenêtre de contexte et de la longueur de sortie grâce à l'utilisation d'un système de contrôle intégral. |
| Curseur (à titre d'essai) | https://www.cursor.com/cn | 3.7 Sonnet | non concluant | non concluant | non concluant | sans soutien | non concluant | Intégré dans l'éditeur de code pour le confort du développeur. |
| OpenRouter | https://openrouter.ai/ | 3.7 Sonnet/pensée/en ligne | Non raisonnement / Raisonnement / En ligne | 200K | Réglable (jusqu'à 128K) | Soutien/Frais | presse jeton Facturation, même prix pour différents fournisseurs de services, frais supplémentaires pour les modèles en ligne | Plusieurs modèles et modes de raisonnement sont pris en charge, avec une sortie maximale paramétrée de 128 Ko. Les modèles de réflexion permettent un "raisonnement complet". Les modèles en ligne permettent la mise en réseau moyennant un coût supplémentaire. |
| OAIPro | (Clé API requise) | 3.7 Sonnet/Pensée | Non-raisonnement/raisonnement | 64K / 200K | 4K (réglable) | sans soutien | Facturation par jeton | Le modèle de pensée active automatiquement l'inférence, et le jeton d'inférence est forcé d'être 80% de max_tokens. |
| Cherry Studio | (Clé API requise) | 3.7 Sonnet | Non-raisonnement/raisonnement | 200K | Réglable (jusqu'à 128K) | Support (nécessite la clé Tavily) | Facturation par jeton + Tavily Nombre de demandes (1000 demandes gratuites par mois) | Associé à l'API Tavily, il permet d'effectuer des recherches en réseau. |
| NextChat | (Clé API requise) | 3.7 Sonnet | non concluant | non concluant | non concluant | Support (plugin WebPilot) | logiciel gratuit | combinant WebPilot Le plugin permet la recherche en réseau. |
Pour essayer Claude 3.7 Sonnet gratuitement, il y a plusieurs façons de le faire :
- Site officiel de Claude: :
- adresse d'accès(accès scientifique requis) https://claude.ai/
- FonctionnalitéLes membres gratuits peuvent utiliser la version sans inférence du modèle et ne prennent pas en charge la fonction de mise en réseau.

- lmarena: :
- adresse d'accès: : https://lmarena.ai/
- FonctionnalitéDans l'option "chat direct", vous pouvez sélectionner soit la version sans inférence, soit la version avec inférence de 32k du modèle, les deux ne prenant pas en charge la mise en réseau. La limite d'entrée est de 8k tokens, la sortie par défaut est de 2k tokens, et la sortie maximale peut être de 4k tokens en ajustant les paramètres.
- Introduction à lmarenaLe projet est une plateforme qui offre de multiples espaces de modélisation des langues (LLM) et des capacités de chat directes où les utilisateurs peuvent comparer et tester différents modèles.
- Version sans inférence
- 32k Édition raisonnement
- Paramètre maximal des jetons de sortie (jusqu'à 4k)
- Nombre maximal de jetons de sortie ExplicationCe paramètre est utilisé pour définir le nombre maximum de jetons qui peuvent être générés par le modèle en une seule passe.
- Genspark: :
- adresse d'accès(accès scientifique requis) https://www.genspark.ai/
- FonctionnalitéLa version "Reasoning" du modèle est fournie, le travail en réseau est pris en charge (cocher "Search Web") et il y a 5 conversations gratuites par jour.
- Introduction à Genspark: Une plateforme fournissant des services d'IA où les utilisateurs peuvent travailler avec une variété de modèles linguistiques à grande échelle et prendre en charge des capacités de recherche connectées.
- Version de raisonnement, avec accès à l'internet, 5 fois par jour
- Poe: :
- adresse d'accès(accès scientifique requis) https://poe.com/
- Fonctionnalité: 3000 points de bonus par jour.
- Introduction à Poe: Une plateforme lancée par Quora qui permet aux utilisateurs d'interagir avec plusieurs modèles de langage à grande échelle et de créer des bots personnalisés.
- Modèle Claude 3.7Le système d'information de la Commission européenne est le suivant : il consomme 333 points, il est réglable par curseur, il prend en charge jusqu'à 16 000 contextes, il n'y a pas de mise en réseau.
- Claude 3.7 Modèles de penséeLa consommation d'énergie est de 2367 points, réglable par le curseur, contexte par défaut de 32k, max 64k.
- Défaut 32k: :
- Maximum 64k: :
Il convient de noter que l'œuvre de Poe
Global per-message budgetLe cadre.Ce paramètre indique le montant maximum de crédits à consommer par conversation, qui est fixé par défaut à 700 ; Poe vous alertera si un message dépasse ce coût. Ce paramètre s'applique à toutes les conversations, ou vous pouvez modifier le budget d'une conversation spécifique dans les paramètres de la conversation. Si le budget est trop bas, les conversations de l'IA risquent d'échouer, car certains modèles nécessitent une consommation de points plus élevée pour fonctionner correctement.
- Curseur (période de stage): :
- adresse d'accès: : https://www.cursor.com/cn
- FonctionnalitéLe réseau n'est pas pris en charge.
- Introduction au curseur: Un éditeur de code avec intelligence artificielle intégrée conçu pour aider les développeurs à écrire et à déboguer le code plus efficacement.

Utilisation de l'API
Pour les développeurs, l'utilisation de Claude 3.7 Sonnet à travers l'API offre une plus grande flexibilité et un meilleur contrôle.
- prixLe processus d'inférence compte également les jetons de sortie, de sorte que le nombre réel de jetons et le prix total sont plus élevés qu'ils ne le seraient sans l'inférence. Le nombre de jetons et le prix total sont plus élevés qu'en l'absence de raisonnement.
- fenêtre contextuelleClaude 3.5 Sonnet : Comme pour Claude 3.5 Sonnet, la fenêtre de contexte totale pour l'API Claude 3.7 Sonnet est de 200k tokens.
- explication de la fenêtre contextuelle: fait référence à la longueur du texte que le modèle peut prendre en compte lors du traitement de l'entrée.
- Explication du jetonLe texte est l'unité de base du texte, qui peut être un mot, un caractère ou un sous-mot.
- production maximaleL'API Claude 3.5 Sonnet a une sortie maximale de 8k tokens, tandis que Claude 3.7 Sonnet a une sortie maximale de 128k tokens en définissant un paramètre.
La version API du Big Model dispose généralement d'une fenêtre contextuelle plus large et d'une sortie maximale que la version Chat, car les utilisateurs de l'API paient pour l'utilisation réelle, et plus il y a d'entrées et de sorties, plus les revenus du fournisseur de services sont élevés. La version Chat a généralement un prix mensuel fixe, de sorte que plus la production est importante, plus elle coûte cher au fournisseur de services.
modèle de raisonnement hybride
Il n'y a plus que 3.7 êtremodèle de raisonnement hybrideSam a dit GPT4.5 est la dernière génération de modèles non inférentiels quiGPT5.0 avec o Les séries ont ensuite fusionné, probablement avec un modèle d'inférence hybride.
Le modèle hybride est un modèle d'inférence et de non-inférence, utilisant le même modèle, l'API utilisant des paramètres, et la version Chat contrôlant la consommation de jetons d'inférence et l'effort avec des curseurs ou des menus déroulants, etc.
Correspondance, la performance du raisonnement est directement proportionnelle à la performance du modèle sous-jacent X temps de raisonnement, la performance du modèle sous-jacent est différente d'abord pas comparée, le temps de raisonnement peut être étalonné par rapport au GPT pour tester le GPT pour réduire la sagesse des poèmes japonais couramment utilisés et d'autres sujets, par exemple, la mesure personnelle.
Il s'agit d'une estimation personnelle, qui ne tient compte que de la relation d'alignement temporel, et non de l'intelligence. À titre de référence uniquement
Il y a moins de tokens à prendre en compte pour R1 car R1 est gratuit et la performance doit être prise en compte tout en gardant les coûts sous contrôle.
présent . DeepSeek tenir R1-faible collaboration avec o3mini-med En fait, attendre un combat devrait être une performance plus forte si un jeton d'inférence plus important est ouvert.
Une autre raison d'utiliser la carte DeepSeek, qui n'est manifestement pas suffisante, est que la précédente carte de l'Union européenne a été utilisée pour la première fois dans le cadre d'un programme de recherche. "Système occupé". Après un mois, il est peu probable que nous puissions augmenter les performances dans un futur proche comme o3mini et Claude en allongeant le temps de manière significative et en augmentant le nombre de Tokens, afin que la force soit assez grande pour voler, et en augmentant violemment la puissance arithmétique.
Tongli, ville de la province de Jiangsu, Chine Gémeaux Comme la R1, il s'agit également d'une stratégie gratuite et le contrôle des coûts est prioritaire, c'est pourquoi le jeton Gemini 2.0 Flash Thinking Token est également le premier jeton Gemini 2.0 Flash Thinking Token. o3mini-low Ce matériel.
Comment régler la sortie maximale de 128K
Méthode d'installation de Cherry Studio + OpenRouter (non référentiel)
Cette méthode permet d'utiliser l'API Claude 3.7 Sonnet via OpenRouter.
- Introduction à OpenRouterLe modèle linguistique : une plateforme qui fournit des services d'agrégation d'API de modèles linguistiques à grande échelle.
- À propos de Cherry Studio: Un outil côté client qui prend en charge un large éventail d'API pour les modèles de langage de grande taille.
- Ouvrez Cherry Studio et ajoutez ou modifiez un assistant.
- Dans "Paramètres du modèle", ajoutez
betassélectionnez JSON pour le type de données du paramètre :
["output-128k-2025-02-19"] - augmenter
max_tokenssélectionnez Numérique pour le type de paramètre et fixez la valeur à 128000 :betascompte pourParamètres utilisés pour activer des fonctions expérimentales spécifiques.max_tokenscompte pour: Permet de définir le nombre maximum de jetons que le modèle peut générer en une seule passe.
Des tests empiriques ont montré que des sorties supérieures à 64K peuvent être obtenues avec OpenRouter, mais avec une certaine probabilité de troncature. Cela peut être dû à l'instabilité du réseau ou aux limites du modèle lui-même.
Méthode d'installation d'OpenRouter (120K raisonnement complet)
Cette méthode ne s'applique qu'au modèle Claude-3.7-Sonnet:Thinking de l'OpenRouter.
- Ouvrez Cherry Studio et ajoutez ou modifiez un assistant.
- Dans "Paramètres du modèle", ajoutez
betassélectionnez JSON pour le type de données du paramètre :["output-128k-2025-02-19"] - augmenter
thinkingsélectionnez JSON pour le type de paramètre et définissez la valeur à :{"type": "enabled", "budget_tokens": 1200000}thinkingcompte pourParamètres utilisés pour activer le mode d'inférence et définir le budget d'inférence.
- Réglez la température du modèle sur 1. D'autres valeurs de température peuvent entraîner une inférence non valide.
- augmenter
max_tokensavec une valeur de 128000 (la valeur minimale est de 1024, ce qui doit être supérieur de quelques K au budget d'inférence laissé pour la sortie finale) :
WebUI ouverte + API officielle ou méthode d'installation oaipro (120K+ raisonnement complet)
- Introduction à l'Open WebUI: Une interface web open source et auto-hébergée pour la modélisation du langage à grande échelle.
- Introduction à l'oaipro: Une plateforme qui fournit des services de proxy Claude API.
faire passer (un projet de loi, une inspection, etc.) Ouvrir l'interface WebUI (utilisé comme expression nominale) pipe Modifications fonctionnelles headerLa sortie Claude 3.7 128K peut être réalisée à partir de n'importe quel site API.
pipecompte pourLe système de gestion de l'information de l'Open WebUI permet aux utilisateurs de modifier les en-têtes des demandes d'information.headercompte pourEn-tête de requête : En-tête de requête HTTP contenant des métadonnées sur la requête.
L'inférence peut être réglée sur un maximum de 127999, pour la raison suivante :
Contexte total 200K (fixe) - Sortie maximale 128K (réglable) = Entrée maximale restante 72K
Sortie maximale 128K (configurable) - Chaîne de réflexion 120K (configurable) = Sortie finale restante 8K
Comment vérifier si le mode raisonnement est activé
Il est possible d'essayer de poser des questions plus complexes. Si le mode de raisonnement est activé, Cherry Studio réfléchira pendant des dizaines de secondes, voire des minutes, sans produire aucun résultat. Actuellement, Cherry Studio n'a pas été adapté pour afficher le processus de raisonnement.
Par exemple, essayez les questions suivantes (qui ne mènent généralement pas à la bonne réponse sans raisonnement, prennent quelques minutes avec raisonnement et aboutissent à la bonne réponse dans la plupart des cas) :

réponse correcte:
Avantages et inconvénients des grandes productions
avantage: :
- Il est possible de remplacer une partie du travail des intelligences. Par exemple, alors que la traduction d'un livre nécessitait auparavant qu'un corps intelligent découpe les chapitres, il peut désormais traiter directement l'ensemble du livre.
- Économies possibles. Si vous ne divisez pas les chapitres et que vous saisissez directement le texte entier, vous pouvez produire 8K à chaque fois et répéter l'opération 16 fois pour obtenir une production de 128K. Bien que le coût de sortie soit le même, le texte original ne doit être saisi qu'une seule fois, ce qui permet d'économiser le coût de 15 saisies.
- Une stratégie de saisie judicieuse permet de réduire considérablement les coûts, d'améliorer l'efficacité et même d'augmenter la vitesse de traitement.
- Environ 100 000 mots +, peut être la traduction d'un livre entier, écrire un livre pour écrire un article sur le web, avant et après la cohérence est bonne, n'écrira pas à l'arrière pour oublier l'avant, théoriquement peut être une sortie unique de 3,5 16 fois la quantité de code, ce qui améliore grandement la puissance de traitement et l'efficacité.
inconvénients: :
- Les performances de tous les grands modèles diminuent avec l'augmentation du contexte, l'ampleur exacte de cette diminution devant être évaluée.
- Les sorties uniques de 128K sont coûteuses, il faut donc veiller à tester soigneusement le mot de repère avant de procéder à une sortie importante afin d'éviter les erreurs qui pourraient entraîner un gaspillage.
Mise en réseau de l'API
L'API officielle de Claude ne prend pas en charge la mise en réseau :
- CherryStudio + Clé API Tavily: 1000 connexions gratuites par mois.
- À propos de Tavily: Une plateforme qui fournit des services d'API de recherche.
Méthode : mettez à jour la version 1.0 de CherryStudio, enregistrez-vous sur tavily.com et demandez une clé API gratuite :
Renseignez la clé API dans les paramètres de Cheery et allumez le bouton Networking dans la boîte à questions :
- NextChat + Plugin WebPilot: Mise en réseau gratuite.
- À propos de NextChat: Une plateforme de chat qui prend en charge plusieurs modèles linguistiques et plugins de grande envergure.
- Introduction à WebPilot: Un plugin qui fournit des fonctionnalités d'extraction et de résumé de contenu web.
- Forum de discussion OpenRouterIl est livré avec son propre bouton de mise en réseau. Comment faire : Connectez-vous à Chatroom | OpenRouter, sélectionnez le modèle 3.7 Sonnet, et mettez en évidence le bouton de mise en réseau dans la boîte de questions :
- L'OpenRouter est doté de capacités de mise en réseauMéthode : remplir manuellement le nom du modèle lors de l'ajout d'un modèle.
anthropic/claude-3.7-sonnet:onlineLe coût du programme est de 4 dollars pour 1 000 demandes.
Autres informations relatives à l'API
- API officielle: :
- entrées: : https://www.anthropic.com/api
- Recharge minimale de 5 $.
- Le réglage via les paramètres Cherry n'est pas pris en charge
betasActive la sortie 128K. - Le niveau 1 a une limite d'entrée de 20k tpm et une limite de sortie de 8k tpm.
- entrées: : https://www.anthropic.com/api
- API OpenRouter: :
- entrées: : https://openrouter.ai/anthropic/claude-3.7-sonnet
- Fournit les modèles Claude-3.7-Sonnet, Claude-3.7-Sonnet Thinking et Claude-3.7-Sonnet Beta.
- Le support pour Claude-3.7-Sonnet Online ou Claude-3.7-Sonnet Thinking Online, avec mise en réseau, est disponible pour un supplément de 4 $ par millier de requêtes.
- Il y a trois fournisseurs Anthropic, Amazon et Google avec le même prix.
- La sortie maximale pour les fournisseurs Google n'est que de 64K, Anthropic et Amazon peuvent être paramétrés à 128K.
- entrées: : https://openrouter.ai/anthropic/claude-3.7-sonnet
- OAIPro API: :
- Introduction à l'oaipro: Une plateforme qui fournit des services de proxy Claude API.
- Entrée par défaut 64K, chaîne de réflexion + sortie finale 4K.
- Le réglage via les paramètres Cherry n'est pas pris en charge
betasActive la sortie 128K. Si vous n'ajoutez pasmax_tokensla sortie par défaut est 4K. - Claude-3-7-Sonnet-20250219-Modèle de pensée : l'inférence est activée directement, aucun paramètre supplémentaire n'est nécessaire et le jeton d'inférence est forcé d'être
max_tokens80%, il ne semble pas qu'il soit possible de spécifier unethinkingParamètres. - Claude-3-7-Sonnet-20250219 Modèle : peut être spécifié manuellement
thinkingParamètres.
- centre de transit à faible coût: :
- aicnnLe rendement ordinaire est d'environ 72 $/million de jetons.
- aicnn Introduction: Une plateforme pour fournir des services d'intelligence artificielle, y compris un relais API.
- Remarque : certaines stations de transit bon marché peuvent ne prendre en charge que la sortie 64K, et non 128K.
- aicnnLe rendement ordinaire est d'environ 72 $/million de jetons.
Version chat
Adhésion gratuite
Il est possible d'utiliser Claude 3.7 Sonnet, mais son utilisation est limitée. Selon le Anthropique Dans le passé, le nombre d'utilisateurs gratuits n'était pas forcément élevé.
En outre, le modèle Claude 3.5 Haiku est désormais indisponible pour les membres gratuits.
- fenêtre contextuelleLa valeur de l'information est de l'ordre de 32K.
- production maximaleLa valeur de l'échantillon est d'environ 8 000 euros.
- sans référence
membre cotisant
La fenêtre contextuelle et le rendement maximal de la version Chat payante ne sont pas encore sûrs d'être les mêmes que ceux de la version gratuite.
La version payante offre les modes de raisonnement Normal et Étendu. Il convient toutefois de noter que les comptes payants risquent d'être interdits. Il est conseillé de recharger votre abonnement avant de vous assurer que vous disposez d'une adresse IP intacte. Comparativement, il est plus sûr d'utiliser l'API.
La limite d'utilisation pour les membres de Claude n'est pas basée sur le nombre de fois, comme GPT ou Grok, mais plutôt sur le nombre total de tokens. Par conséquent, l'utilisation du mode raisonnement, et plus particulièrement du mode étendu, réduit considérablement le nombre de questions qui peuvent être posées par jour. Certains utilisateurs ont révélé qu'Anthropic pourrait introduire une réinitialisation payante de la limite d'utilisation, permettant aux utilisateurs de sauter la période de réflexion moyennant un paiement unique.

Fonctionnalité
- Téléchargement de fichiersLa fonction d'enregistrement de fichiers : prend en charge jusqu'à 20 fichiers d'une taille maximale de 30 Mo par fichier.
- multimodalReconnaissance d'images : prend en charge la reconnaissance d'images, mais pas la reconnaissance vocale ou vidéo.
- GitHubLe téléchargement de fichiers : Nouvelle fonctionnalité qui se connecte au dépôt GitHub d'un utilisateur comme moyen de télécharger des fichiers.
- Code ClaudeLe logiciel est un outil de ligne de commande officiel pour les développeurs, actuellement disponible en avant-première de recherche limitée. L'outil prend en charge la recherche de code, la lecture, l'édition, l'exécution de tests, les commits GitHub et les opérations en ligne de commande. Il est conçu pour réduire le temps de développement et améliorer l'efficacité du développement piloté par les tests et du débogage de problèmes complexes.
- Réseautage, recherche en profondeur, recherche en profondeur, modélisation de la parole, graphes de Vincennes: Identique à la version 3.5 de Claude, non prise en charge.
Examen du modèle
compétences en codage
La compétence en matière de code a toujours été un point fort du modèle Claude et une préoccupation majeure pour son principal groupe d'utilisateurs, les programmeurs. Si la compétence en matière de code diminue, Claude pourrait être confronté à un sérieux défi.
- Lmarena: webdev Rating Leader. Référence : https://lmarena.ai/?leaderboard
- Bancs d'essaiLa version non raisonnée de Claude 3.7 présente des améliorations moindres par rapport à la version 3.5, et la version raisonnée présente des améliorations plus importantes, mais avec une augmentation correspondante du coût (même prix unitaire, augmentation du jeton de sortie). Référence : https://livebench.ai/
- Introduction à Livebench: une plateforme pour l'évaluation continue de la performance des modèles de langage de grande taille.
- AiderLe modèle d'inférence de Claude 3.7 coûte environ 2,5 fois plus cher que celui de la version 3.5.
- Introduction à l'Aider: Un assistant de programmation IA qui aide les développeurs à générer du code et à le déboguer.
Référence : https://aider.chat/docs/leaderboards/
- CodeParrot AIClaude 3.7 obtient de bons résultats dans le test de codage HumanEval avec un score de 92,1, une amélioration par rapport à Claude 3.5 (89,4).
- Introduction à CodeParrot AILe logiciel de gestion de projet est une plate-forme qui fournit une gamme d'outils de codage pour rationaliser le processus de développement.
Utilisation de l'outil "corps intelligent
Anthropic prétend officiellement que Claude 3.7 excelle dans l'utilisation d'outils corporels intelligents.

capacité mathématique
Claude 3.7 Normal est dans la moyenne en maths, Reasoning a de meilleurs résultats.

capacité de raisonnement

performance du marché
Chaleur de la recherche Google: :
Google Play: Claude App est classé 107ème dans les charts américains.
App Store: N'a pas réussi à se hisser dans le top 200.
Résumé et perspectives
La sortie de Claude 3.7 Sonnet marque une nouvelle itération d'Anthropic dans l'espace des grands modèles. Malgré le petit changement de numéro de version, il offre des améliorations dans la génération de code, les capacités d'inférence, et de grandes sorties contextuelles. Cependant, Claude doit encore faire face à des défis en termes d'accès limité pour les utilisateurs gratuits, de manque de capacités de mise en réseau et de performance du marché.
Le taux de croissance global de Claude, en particulier dans la suite C (côté consommateur), est clairement à la traîne par rapport à ses concurrents. Sa valorisation a été dépassée par xAI.
Selon la tendance actuelle, Claude pourrait être évincé du premier niveau des grands modèles mondiaux par GPT, DeepSeek et Gemini. À l'avenir, Claude pourrait entrer en concurrence avec des modèles tels que Grok et Beanbag pour la deuxième place, ou choisir d'abandonner complètement le marché C-end et de se concentrer sur des secteurs verticaux tels que la programmation, les intelligences et l'écriture.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...