
Guide pour éviter les pièges : Taobao DeepSeek R1 installation package paid upsell ? Apprenez le déploiement local gratuitement (avec l'installateur en un clic)
Récemment, sur la plateforme Taobao DeepSeek Le phénomène de la vente de paquets d'installation a suscité de nombreuses inquiétudes. Il est surprenant que certaines entreprises profitent de ce modèle d'IA gratuit et open source. C'est aussi le reflet du boom du déploiement local que les modèles DeepSeek sont en train de générer.

En recherchant "DeepSeek" sur des plateformes de commerce électronique telles que Taobao et Jinduoduo, vous pouvez trouver de nombreux marchands qui vendent des ressources qui auraient pu être obtenues gratuitement, y compris des paquets d'installation, des paquets de mots clés, des tutoriels, etc. Certains vendeurs vendent même des tutoriels liés à DeepSeek à un prix majoré. En réalité, les utilisateurs peuvent facilement trouver un grand nombre de liens de téléchargement gratuits en utilisant simplement un moteur de recherche.
Quel est le prix de vente de ces ressources ? Il a été observé que le prix de l'ensemble "installateur + tutoriels + conseils" varie généralement entre 10 et 30 dollars, et que la plupart des marchands fournissent également un certain niveau de service à la clientèle. Parmi eux, de nombreux produits ont été vendus à des centaines d'exemplaires, quelques produits populaires et même достигают mille personnes pour payer l'échelle. Plus surprenant, un prix de 100 $ progiciels et tutoriels, il y a aussi 22 personnes choisissent d'acheter.

Les opportunités commerciales offertes par le déficit d'information sont donc évidentes.
Dans cet article, nous allons expliquer au lecteur comment déployer les modèles DeepSeek localement sans aucun coût. Avant cela, nous analyserons brièvement la nécessité d'un déploiement local.
Pourquoi choisir de déployer DeepSeek-R1 localement ?
Profondeur de l'eau-R1 bien qu'ils ne soient pas les modèles d'inférence les plus performants disponibles aujourd'hui, sont certainement une option très recherchée sur le marché. Cependant, lorsqu'ils utilisent directement les services des plateformes d'hébergement officielles ou tierces, les utilisateurs sont souvent confrontés à la congestion des serveurs.
Un modèle de déploiement local permet de contourner efficacement ce problème. En bref, le déploiement local consiste à installer des modèles d'IA sur les appareils des utilisateurs, plutôt que de s'appuyer sur des API dans le nuage ou des services en ligne. Les méthodes de déploiement local les plus courantes sont les suivantes :
- Raisonnement local légerLlama.cpp : fonctionne sur un PC ou un appareil mobile, par exemple Llama.cpp, Whisper, modèles au format GGUF.
- Déploiement de serveurs/postes de travailLes modèles de grande taille peuvent être exécutés avec des GPU ou TPU performants, tels que les NVIDIA RTX 4090, A100, etc.
- Serveurs cloud/intranet privésDéploiement sur des serveurs sur site, par exemple à l'aide d'outils tels que TensorRT, ONNX Runtime, vLLM.
- Déploiement d'appareils en périphérieLes modèles d'IA peuvent être exécutés sur des systèmes embarqués ou des appareils IoT tels que Jetson Nano, Raspberry Pi, etc.
Différentes méthodes de déploiement conviennent à différents scénarios d'application. Les technologies de déploiement local ont démontré leur valeur unique dans plusieurs domaines, par exemple :
- Applications d'IA sur siteLes services d'aide à la décision : Construire des chatbots privés, des systèmes d'analyse de documents, etc.
- calculs de recherche scientifiqueApplications dans l'analyse de données et la formation de modèles en biomédecine, en simulation physique et dans d'autres domaines.
- Fonctionnalités de l'IA hors ligneLe logiciel de reconnaissance vocale : Il offre des capacités de reconnaissance vocale, d'OCR et de traitement d'images dans un environnement sans réseau.
- Audit et surveillance de la sécuritéLes services d'analyse de la conformité dans les secteurs juridique et financier, entre autres, peuvent être utiles.
Dans cet article, nous nous concentrerons sur l'inférence locale légère, qui est l'option de déploiement la plus pertinente pour un large éventail d'utilisateurs individuels.
Avantages du déploiement local
En plus de résoudre la cause première du problème du "serveur occupé", le déploiement local offre un certain nombre d'avantages :
- Confidentialité et sécurité des donnéesLes modèles d'IA peuvent être déployés localement sans qu'il soit nécessaire de télécharger des données sensibles dans le nuage, ce qui prévient efficacement le risque de fuite de données. Cet aspect est essentiel pour des secteurs tels que la finance, la santé et le juridique, qui exigent des niveaux élevés de sécurité des données. En outre, le déploiement local aide également les entreprises ou les organisations à respecter les exigences en matière de conformité des données, telles que la loi chinoise sur la sécurité des données et le GDPR de l'UE.
- Faible latence et performance en temps réelLa vitesse d'inférence dépend entièrement des performances de calcul de l'appareil local, puisque tous les calculs sont effectués localement sans requêtes réseau. Par conséquent, tant que les performances de l'appareil sont suffisantes, les utilisateurs peuvent obtenir une excellente réponse en temps réel, ce qui rend le déploiement local idéal pour les scénarios d'application exigeants en temps réel, tels que la reconnaissance vocale, la conduite automatisée et l'inspection industrielle.
- Coût-efficacité à long termeDéploiement natif : le déploiement natif élimine les frais d'abonnement à l'API, ce qui permet un déploiement unique et une utilisation à long terme. Pour les applications peu exigeantes en termes de performances, il est également possible de réduire les coûts matériels en déployant des modèles légers tels que les modèles quantifiés INT 8 ou 4 bits.
- Disponibilité hors ligneLes modèles d'IA peuvent être utilisés même en l'absence de connexion réseau, ce qui convient à l'informatique en périphérie, aux bureaux hors ligne, aux environnements distants et à d'autres scénarios. La capacité de fonctionner hors ligne garantit également la continuité des services critiques et évite les interruptions d'activité dues à une déconnexion du réseau.
- Hautement personnalisable et contrôlableLe déploiement local permet aux utilisateurs d'affiner et d'optimiser le modèle afin de mieux répondre aux besoins spécifiques de l'entreprise. Par exemple, le modèle DeepSeek-R1 a donné lieu à de nombreuses versions affinées et distillées, y compris la version sans restriction deepseek-r1-abliterated. En outre, les déploiements locaux ne sont pas soumis aux changements de politique des tiers, ce qui permet de mieux contrôler et d'éviter les risques potentiels tels que les ajustements de prix de l'API ou les restrictions d'accès.
Limites du déploiement local
Les avantages d'un déploiement local sont importants, mais les limites ne sont pas négligeables, notamment en ce qui concerne la puissance de calcul requise pour les modèles à grande échelle.
- Coûts du matérielLes utilisateurs individuels ont souvent des difficultés à faire fonctionner des modèles avec des paramètres de grande taille sur leur équipement local, alors que les modèles avec des paramètres plus petits peuvent avoir des performances compromises. Par conséquent, les utilisateurs doivent trouver un compromis entre le coût du matériel et la performance du modèle. La recherche de modèles très performants nécessitera inévitablement un investissement matériel supplémentaire.
- Capacité de traitement des tâches à grande échelleLe matériel de niveau serveur est souvent nécessaire pour mener à bien les tâches qui requièrent un traitement de données à grande échelle. Les appareils personnels présentent un goulot d'étranglement naturel en termes de puissance de traitement.
- seuil technologiqueLe déploiement local se heurte à un obstacle technique par rapport à la commodité des services en nuage, qui peuvent être utilisés en visitant simplement une page web ou en configurant une interface de programmation (API). Si les utilisateurs doivent affiner leurs modèles, le déploiement sera encore plus difficile. Heureusement, les obstacles techniques au déploiement local sont progressivement abaissés.
- coût de maintenanceLes mises à jour et les itérations du modèle et des outils associés peuvent entraîner des problèmes de configuration de l'environnement, obligeant l'utilisateur à consacrer du temps et des efforts à la maintenance et à la résolution des problèmes.
Par conséquent, le choix du déploiement local ou du modèle en ligne doit être envisagé en fonction de la situation réelle de l'utilisateur. Voici un bref résumé des scénarios dans lesquels le déploiement local est ou n'est pas applicable :
- Scénarios adaptés au déploiement localLes applications de l'intelligence artificielle peuvent être très diverses : exigences élevées en matière de respect de la vie privée, exigences de faible latence, utilisation à long terme (par exemple, assistants d'intelligence artificielle d'entreprise, systèmes d'analyse juridique, etc.)
- Scénarios ne convenant pas à un déploiement localLes problèmes de validation des tests à court terme, les exigences arithmétiques élevées, la dépendance à l'égard de très grands modèles (par exemple, 70B+ niveau des paramètres).
Le déploiement privé à l'aide de serveurs gratuits dans le nuage est également une bonne solution, qui a été recommandée il y a longtemps, mais qui nécessite une certaine base technique :Déploiement en ligne du modèle open-source DeepSeek-R1 avec une puissance GPU gratuite
Déploiement local de DeepSeek-R1 en action
Il existe de nombreuses façons de déployer DeepSeek-R1 localement, mais dans cet article, nous présenterons deux options simples : basée sur l'option Ollama les méthodes de déploiement et les scénarios de déploiement sans code à l'aide de LM Studio.
Option 1 : déploiement de DeepSeek-R1 basé sur Ollama
Ollama est le cadre dominant pour le déploiement et l'exécution de modèles de langage natif. Il est léger et très évolutif, et a pris de l'importance depuis la sortie de la famille de modèles Llama de Meta. Malgré son nom, le projet Ollama est dirigé par la communauté et n'est pas directement lié au développement de Meta et de la famille de modèles Llama.

Le projet Ollama se développe rapidement et la variété des modèles et des écosystèmes qu'il prend en charge s'accroît rapidement.
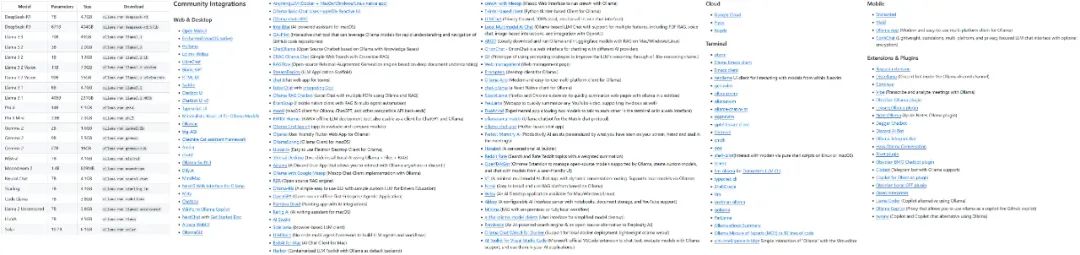
Quelques-uns des modèles et des écologies soutenus par Ollama
La première étape pour utiliser Ollama est de télécharger et d'installer le logiciel Ollama. Visitez la page officielle de téléchargement d'Ollama et sélectionnez la version qui correspond à votre système d'exploitation.
Télécharger : https://ollama.com/download
Après avoir installé Ollama, vous devez configurer le modèle d'IA pour l'appareil. Prenons DeepSeek-R1 comme exemple. Visitez la bibliothèque de modèles sur le site web d'Ollama pour parcourir les modèles et les versions pris en charge :
https://ollama.com/search
DeepSeek-R1 est disponible dans 29 versions différentes de la bibliothèque de modèles Ollama à des échelles allant de 1,5 à 67 milliards, y compris des versions affinées, distillées ou quantifiées basées sur les modèles open-source Llama et Qwen.
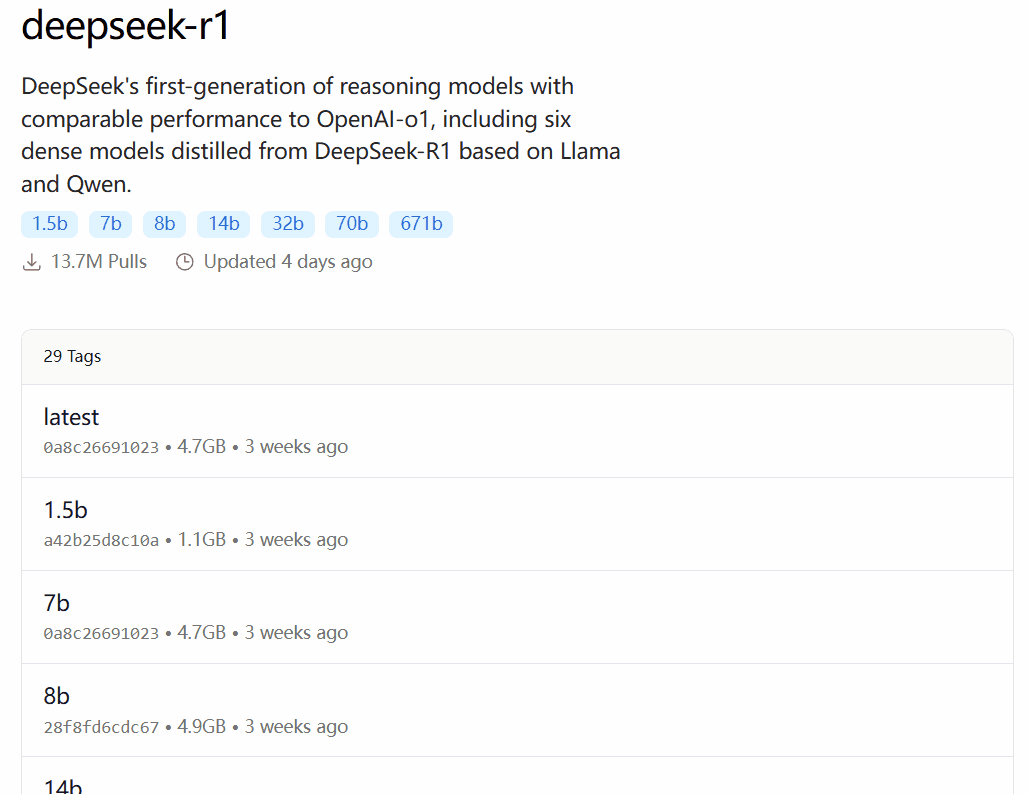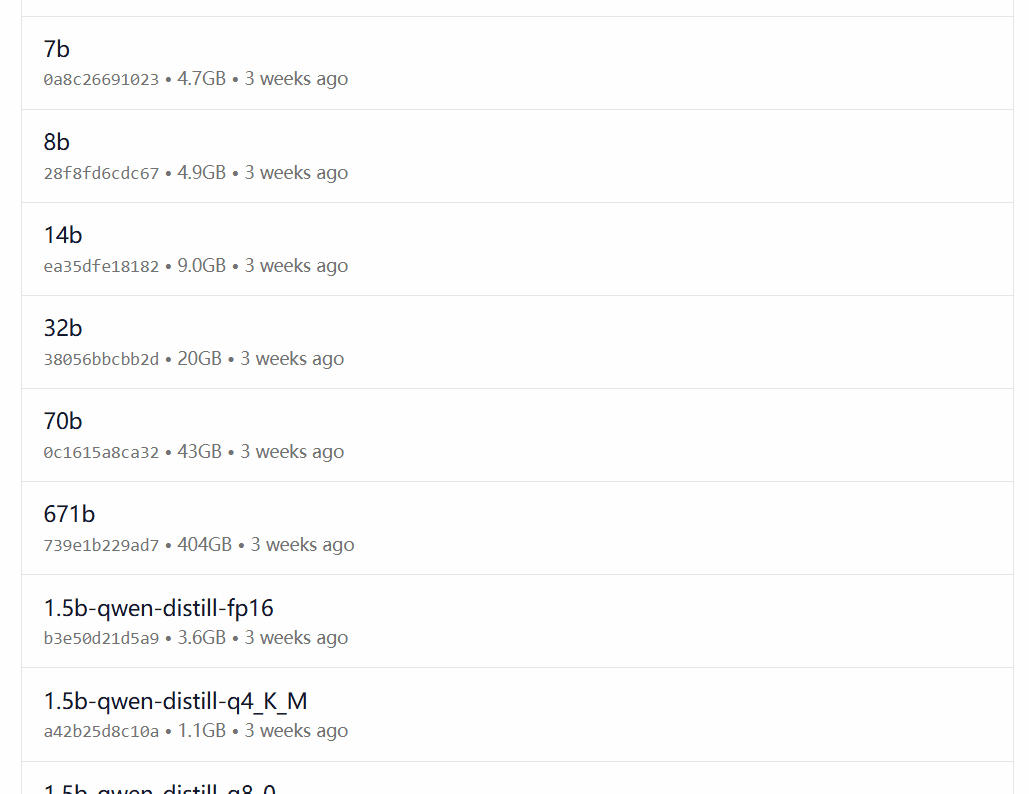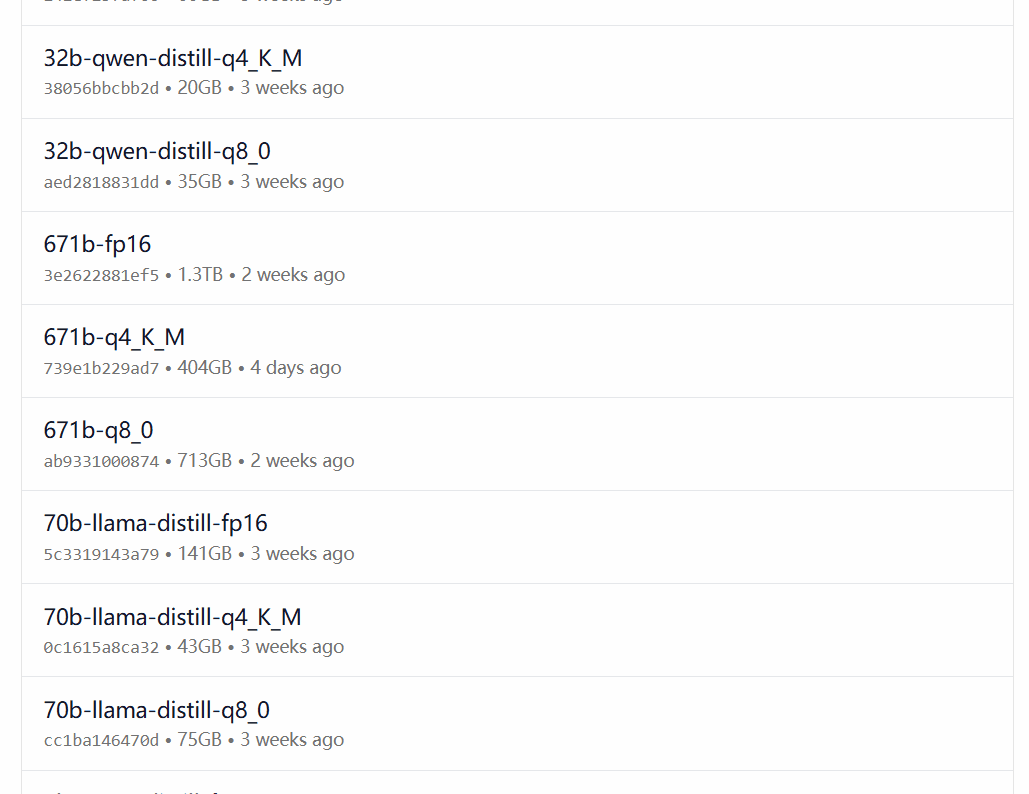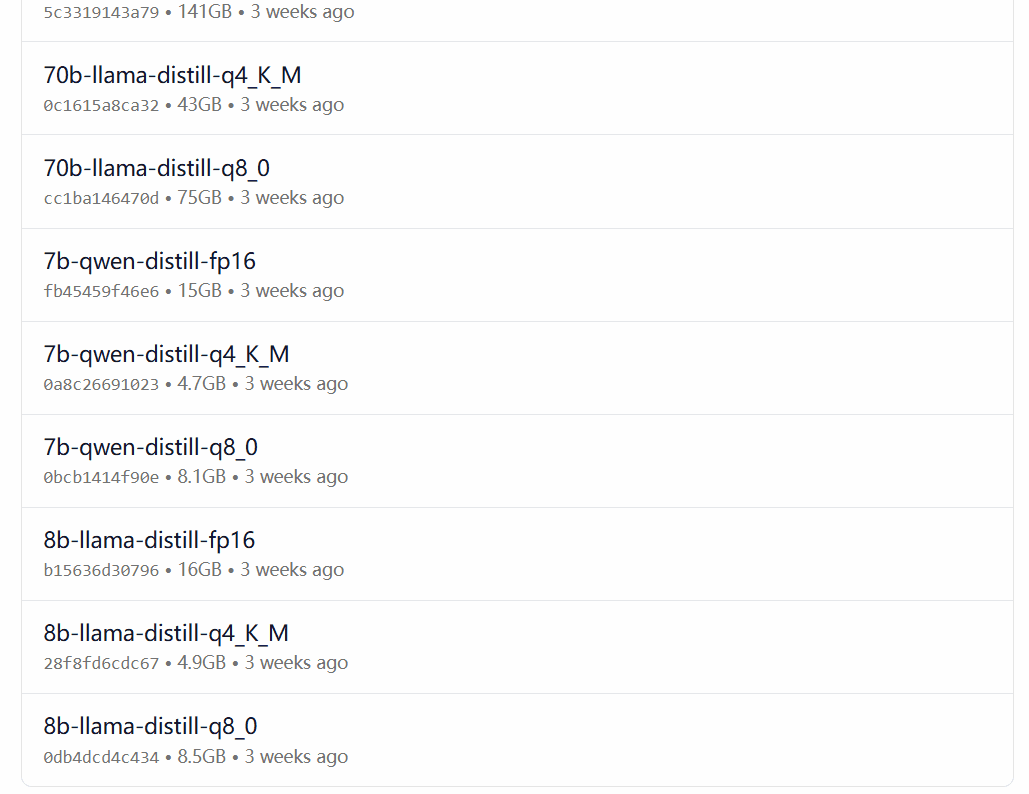
La version à choisir dépend de la configuration matérielle de l'utilisateur. Avnish de la communauté de développeurs dev.to a écrit un article résumant les exigences matérielles pour les différentes versions de DeepSeek-R1 :
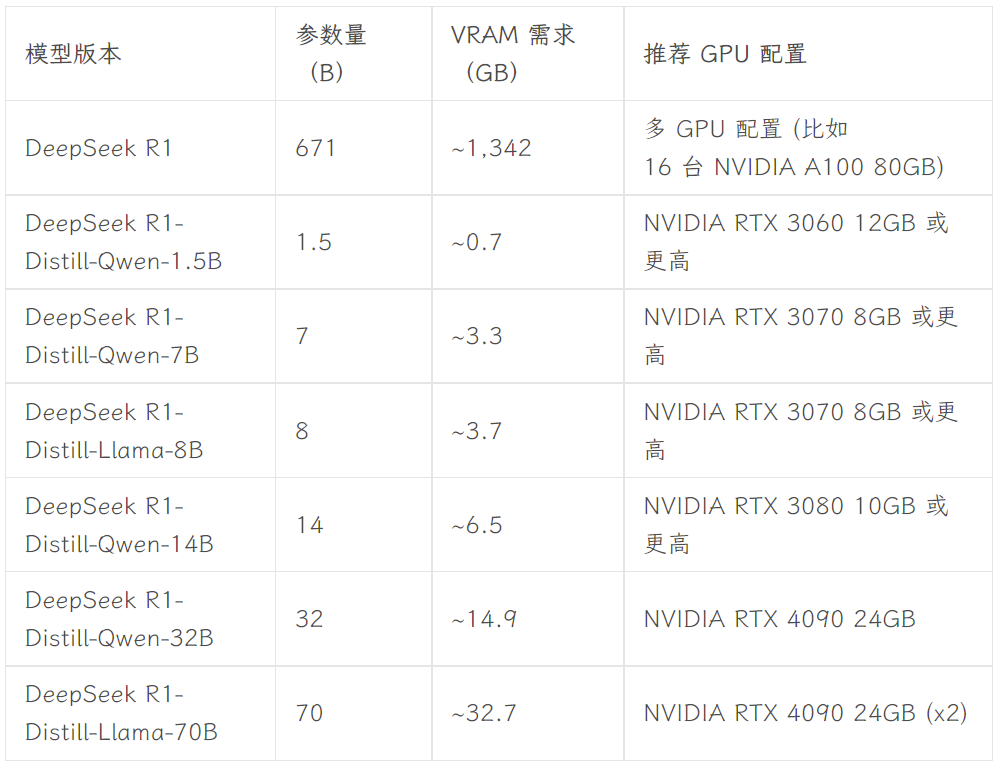
Source de l'image : https://dev.to/askyt/deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-3mf8
Cet article prend la version 8B comme exemple de démonstration. Ouvrez le terminal de l'appareil et exécutez la commande suivante :
ollama run deepseek-r1:8b
Ensuite, il suffit d'attendre que le modèle ait fini d'être téléchargé. (Ollama permet également de télécharger des modèles directement depuis Hugging Face, avec la commande ollama run hf.co/{username}/{library}:{quantified version}, par exemple ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0).

Une fois le modèle téléchargé, vous pouvez dialoguer avec la version 8B de DeepSeek-R1 dans le terminal.

Cependant, ce type de dialogue terminal n'est pas intuitif et pratique pour l'utilisateur moyen. C'est pourquoi une interface graphique frontale conviviale est nécessaire. Il existe une large gamme d'interfaces frontales parmi lesquelles on peut choisir, par exemple, l'interface Ouvrir l'interface WebUI On obtient quelque chose comme ChatGPT Vous pouvez également choisir Chatbox et d'autres applications de bureau. D'autres options frontales sont disponibles dans la documentation officielle d'Ollama :
https://github.com/ollama/ollama
- Ouvrir l'interface WebUI
Si vous choisissez Open WebUI, exécutez les deux lignes de code suivantes dans le terminal :
Installer Open WebUI :
pip install open-webui
Exécutez le service Open WebUI :
open-webui serve
Ensuite, visitez http://localhost:8080 dans votre navigateur pour découvrir l'interface web de type ChatGPT. Dans la liste des modèles de l'Open WebUI, vous pouvez voir plusieurs modèles qui ont été configurés par Ollama local, y compris les versions 7B et 8B de DeepSeek-R1, et d'autres modèles tels que Llama 3.1 8B, Llama 3.2 3B, Phi 4, Qwen 2.5 Coder, et ainsi de suite. Le modèle DeepSeek-R1 8B est choisi pour les tests :

- Chatbox
Si vous préférez utiliser une application de bureau autonome, vous pouvez envisager des outils tels que Chatbox. Les étapes de configuration sont tout aussi simples et commencent par le téléchargement et l'installation de l'application Chatbox :
https://chatboxai.app/zh
Après avoir lancé Chatbox, entrez dans l'interface "Paramètres", sélectionnez l'API OLLAMA dans "Fournisseur du modèle", puis sélectionnez le modèle que vous voulez utiliser dans la colonne "Modèle". Sélectionnez ensuite le modèle que vous souhaitez utiliser dans le champ "Modèle", et définissez les paramètres tels que le nombre maximum de messages contextuels et la température en fonction de vos besoins (vous pouvez également conserver les paramètres par défaut).

Une fois configuré, vous pouvez avoir une conversation fluide avec le modèle DeepSeek-R1 déployé localement dans Chatbox. Cependant, les résultats du test montrent que le modèle DeepSeek-R1 7B est légèrement moins performant lorsqu'il traite des commandes complexes. Cela confirme le point précédent, à savoir que les utilisateurs individuels ne peuvent généralement exécuter que des modèles aux performances relativement limitées sur des appareils locaux. Toutefois, il est prévisible qu'à mesure que la technologie matérielle continue d'évoluer, les obstacles à l'utilisation locale de modèles à grands paramètres par des utilisateurs individuels seront encore abaissés à l'avenir - et ce jour n'est peut-être pas si lointain.

**Open WebUI et Chatbox permettent d'accéder aux modèles de DeepSeek, à ChatGPT et à Claude via des API, Gémeaux et d'autres modèles commerciaux. Les utilisateurs peuvent s'en servir comme d'une interface frontale pour l'utilisation quotidienne des outils d'IA. En outre, les modèles configurés dans Ollama peuvent être intégrés dans d'autres outils, tels que des applications de prise de notes comme Obsidian et Civic Notes.
Option 2 : Déployer DeepSeek-R1 avec zéro code en utilisant LM Studio
Pour les utilisateurs qui ne sont pas familiers avec les opérations en ligne de commande ou le code, vous pouvez utiliser LM Studio pour déployer DeepSeek-R1 sans code. Tout d'abord, visitez la page officielle de téléchargement de LM Studio pour télécharger le programme qui correspond à votre système d'exploitation :
https://lmstudio.ai
Démarrez LM Studio une fois l'installation terminée. Dans l'onglet "Mes Modèles", définissez le dossier de stockage local pour les modèles :

Ensuite, téléchargez les fichiers de modèle de langue requis à partir de Hugging Face et placez-les dans le dossier ci-dessus selon la structure de répertoire spécifiée (LM Studio dispose d'une fonction de recherche de modèle intégrée, mais elle ne fonctionne pas bien dans la pratique). Notez que vous devez télécharger les fichiers de modèle au format .gguf. Par exemple Débarbouillettes Une collection de modèles DeepSeek-R1 fournis par l'organisation :
https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5
Compte tenu de la configuration matérielle, nous choisissons dans ce document la version DeepSeek-R1 Distillate (numéro de paramètre 14B) basée sur le réglage fin du modèle Qwen, et la version quantifiée à 4 bits : DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf.
Une fois le téléchargement terminé, placez les fichiers du modèle dans le dossier défini précédemment selon la structure de répertoire suivante :
Dossier modèle /unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
Enfin, ouvrez LM Studio et sélectionnez le modèle que vous souhaitez charger en haut de l'interface de l'application pour communiquer avec le modèle local.

Le plus grand avantage de LM Studio est qu'il est complètement zéro-code, il n'y a pas besoin d'utiliser un terminal ou d'écrire du code - il suffit d'installer le logiciel et de configurer les dossiers, ce qui le rend très convivial.
résumés
Les tutoriels présentés dans cet article ne fournissent qu'un niveau de base pour le déploiement local de DeepSeek-R1. Une configuration plus détaillée, telle que la mise en place d'invites système et un réglage plus avancé du modèle, est nécessaire pour intégrer ce modèle populaire plus profondément dans les flux de travail locaux, RAG Intégration, fonction de recherche, capacités multimodales et capacités d'invocation d'outils. Parallèlement, comme le matériel spécifique à l'IA et les technologies de petits modèles continuent d'évoluer, je pense que les obstacles au déploiement local de grands modèles continueront de s'abaisser à l'avenir. Après avoir lu cet article, êtes-vous prêt à essayer de déployer le modèle DeepSeek-R1 par vous-même ?
Kit d'installation en un clic DeepSeek R1+OpenwebUI ci-joint
Le paquet d'installation en un clic fourni par Sword27 intègre spécifiquement pour DeepSeek la fonction Ouvrir l'interface WebUI
DeepSeek déploiement local de l'exécution en un clic, décompressé à utiliser Support 1.5b 7b 8b 14b 32b, support minimum pour carte graphique 2G
Processus d'installation
1.AI environment download : https://pan.quark.cn/s/1b1ad88c7244
2) Téléchargement du paquet d'installation : https://pan.quark.cn/s/7ec8d85b2f95
Obtenez de l'aide dans l'article original : https://www.jian27.com/html/1396.html
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...