Baichuan-Audio : un modèle audio de bout en bout pour l'interaction vocale en temps réel
Introduction générale
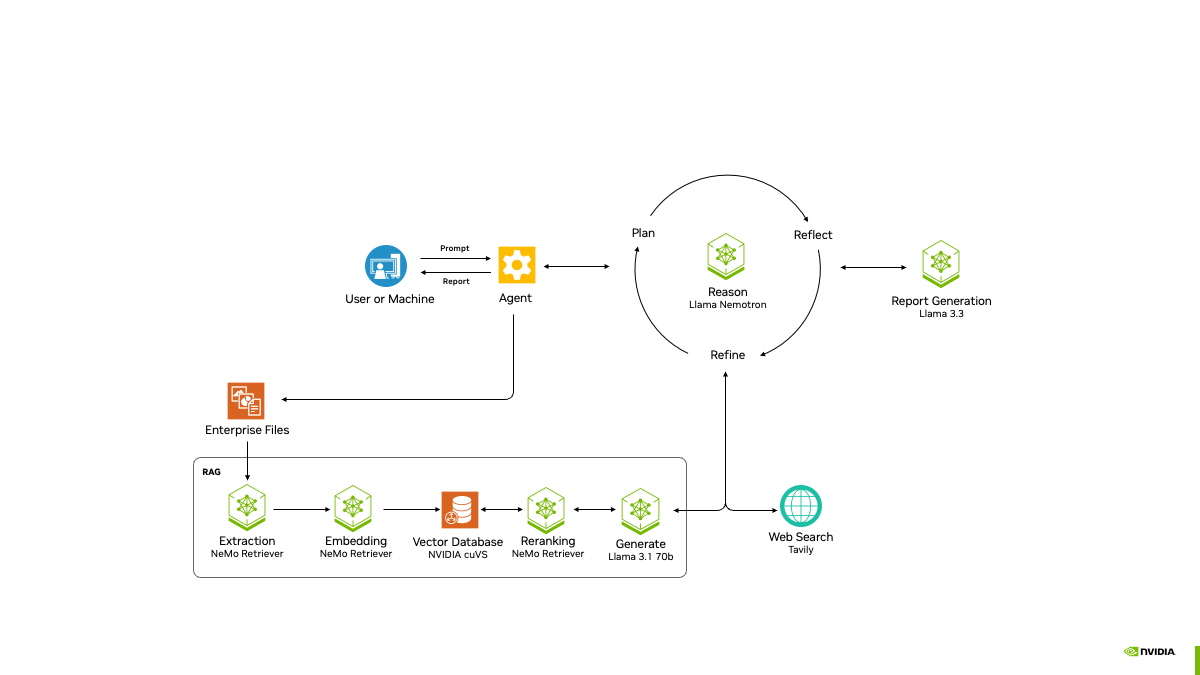
Baichuan-Audio est un projet open source développé par Baichuan Intelligence (baichuan-inc), hébergé sur GitHub, qui se concentre sur la technologie d'interaction vocale de bout en bout. Le projet fournit un cadre complet de traitement audio qui peut convertir la parole en jetons audio discrets, puis générer le texte et la sortie audio correspondants à travers un grand modèle pour obtenir un dialogue en temps réel de haute qualité. La prise en charge du chinois et de l'anglais bilingue, applicable au besoin de compréhension de la parole et de la génération de la scène, tels que les assistants intelligents, les robots de chat vocal et ainsi de suite. En outre, le projet met en open source Baichuan-Audio-Base, un modèle de base, et OpenAudio-Bench, un benchmark, afin de fournir aux développeurs un puissant support de recherche et de développement. Le projet suit la licence Apache 2.0, qui convient à la recherche universitaire et aux applications commerciales dans des conditions spécifiques.

Liste des fonctions
- étiquetage de la parole à l'audioLa parole est convertie en jetons audio discrets par le Baichuan-Audio Tokenizer, qui prend en charge une fréquence d'images de 12,5 Hz afin de garantir la rétention des informations.
- interaction vocale en temps réelLe logiciel Audio LLM permet des conversations bilingues en anglais et en chinois, et génère des réponses vocales et textuelles de haute qualité.
- Génération audioLes fonctions suivantes sont disponibles : générer des spectrogrammes et des formes d'onde Mel haute fidélité à partir de marqueurs audio à l'aide du décodeur audio Flow-matching.
- modèle de source ouverte (informatique)Le modèle de base Baichuan-Audio-Base est fourni sans ajustement des instructions, et les développeurs peuvent personnaliser la formation en fonction de leurs besoins.
- Critères de référenceLe site comprend OpenAudio-Bench, un outil d'évaluation de la compréhension et de la production audio avec 2701 points de données.
- soutien multimodalLa prise en charge de l'entrée mixte texte et audio pour une commutation intermodale transparente.
Utiliser l'aide
Processus d'installation
Pour utiliser Baichuan-Audio localement, vous devez configurer l'environnement de développement et télécharger les fichiers modèles correspondants. Voici les étapes détaillées de l'installation :
- Préparation de l'environnement
- Assurez-vous que Python 3.12 et Conda sont installés sur votre système.
- Créer et activer un environnement virtuel :
conda create -n baichuan_audio python=3.12 conda activate baichuan_audio - Installer les bibliothèques de dépendances nécessaires :
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124 pip install -r requirements.txt pip install accelerate flash_attn==2.6.3 speechbrain==1.0.0 deepspeed==0.14.4 - Installation des outils du système :
apt install llvm ffmpeg
- Télécharger les modèles
- Clonez le code à partir du dépôt GitHub (https://github.com/baichuan-inc/Baichuan-Audio) :
git clone https://github.com/baichuan-inc/Baichuan-Audio.git cd Baichuan-Audio - modifications
web_demo/constants.pya fait moucheMODEL_PATHIl s'agit du chemin d'accès au modèle local (vous devez le télécharger manuellement ou utiliser Hugging Face pour obtenir les poids du modèle, par exemple).baichuan-inc/Baichuan-Audio).
- Clonez le code à partir du dépôt GitHub (https://github.com/baichuan-inc/Baichuan-Audio) :
- Exécuter la démo
- Démarrer la démo de reconnaissance vocale :
cd web_demo python base_asr_demo.py - Démarrer la démonstration de la synthèse vocale :
python base_tts_demo.py - Lancer un dialogue à plusieurs tours Démo :
python s2s_gradio_demo_cosy_multiturn.py
- Démarrer la démo de reconnaissance vocale :
Fonction Opération Déroulement
1. la tokenisation de la parole à l'audio (Baichuan-Audio Tokenizer)
- Description fonctionnelleLe logiciel d'analyse de la parole : convertit les fichiers vocaux entrants ou les entrées microphoniques en jetons audio discrets en vue d'un traitement ultérieur.
- procédure: :
- Préparez un fichier audio (format WAV pris en charge) ou connectez un microphone.
- en cours d'exécution
base_asr_demo.pyEnsuite, l'interface vous demandera de télécharger l'audio ou d'activer le microphone. - Le système appelle automatiquement Chuchotement Large Encoder extrait les caractéristiques et génère des jetons audio à travers 8 couches de RVQ (residual vector quantisation).
- La sortie peut être visualisée sur la console sous la forme d'une séquence de marqueurs discrets.
- mise en gardeLes données audio doivent être claires et les bruits de fond faibles afin d'améliorer la précision de la reconnaissance.
2) Interaction vocale en temps réel (Audio LLM)
- Description fonctionnelleLe modèle est un outil d'aide à la décision : il permet aux utilisateurs de dialoguer en temps réel avec le modèle, en anglais et en chinois, par le biais d'une saisie vocale ou textuelle.
- procédure: :
- être en mouvement
s2s_gradio_demo_cosy_multiturn.pyPour ce faire, ouvrez l'interface Gradio. - Cliquez sur le bouton "Enregistrer" pour commencer la saisie vocale (par exemple, "Veuillez me dire le temps qu'il fait aujourd'hui en chinois").
- Le système convertit la parole en balises et l'Audio LLM génère des réponses textuelles et vocales.
- La réponse est simultanément affichée en texte et diffusée par les haut-parleurs.
- être en mouvement
- Utilisation en vedette: :
- Saisie d'un contenu mixte, par exemple en tapant le texte "Hi" puis en disant "Please continue in English" avec votre voix.
- Le système permet de passer d'un mode à l'autre grâce à des marqueurs spéciaux afin de préserver la cohérence du dialogue.
3. génération audio (décodeur audio à correspondance de flux)
- Description fonctionnelleLes logiciels d'aide à la décision : Générer une sortie vocale de haute qualité à partir d'un texte ou d'une entrée audio.
- procédure: :
- être en mouvement
base_tts_demo.py, entrer dans l'interface de synthèse vocale. - Saisissez quelque chose dans la zone de texte (par exemple, "Bonjour, nous sommes vendredi").
- En cliquant sur le bouton "Generate", le système convertit le texte en jetons audio, puis génère le spectrogramme Mel grâce au décodeur de correspondance de flux.
- Le vocodeur intégré permet de convertir le spectrogramme en fichier WAV pour la lecture automatique ou le téléchargement.
- être en mouvement
- Fonctionnalités avancéesLa fonction de réglage de la vitesse et de la hauteur de la parole est prise en charge, les paramètres spécifiques pouvant être modifiés dans le code.
4. l'utilisation de bancs d'essai (OpenAudio-Bench)
- Description fonctionnelle: Évaluer les capacités de compréhension et de génération audio des modèles.
- procédure: :
- Téléchargez le jeu de données OpenAudio-Bench (situé dans le dépôt GitHub).
- Exécutez le script d'évaluation localement (vous devez l'écrire vous-même ou vous référer à la documentation du référentiel).
- Saisissez le texte ou l'audio du test pour obtenir les scores de performance du modèle sur les 5 sous-ensembles d'évaluation.
- scénario d'applicationLes développeurs peuvent l'utiliser pour comparer les performances de différents modèles et optimiser les stratégies de formation.
mise en garde
- exigences en matière de matérielLes GPU compatibles avec CUDA (par exemple, les cartes NVIDIA) sont recommandés, car le CPU risque de fonctionner plus lentement.
- dépendance à l'égard du réseauPour la première exécution, un accès à Internet est nécessaire pour télécharger les poids du modèle, et une utilisation ultérieure hors ligne est possible.
- usage commercialIl est tenu de respecter le protocole Apache 2.0 et de confirmer que le nombre d'utilisateurs actifs quotidiens (DAU) est inférieur à 1 million.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...