Ali Bailian fournit gratuitement l'API QwQ-32B, et 1 million de jetons sont gratuits pour l'utiliser chaque jour !
Récemment, AliCloud Hundred Refinement Platform a annoncé la création d'une nouvelle plateforme pour le développement de l'entreprise. QwQ-32B Le modèle de langage Big Language ouvre des interfaces API et fournitAccès gratuit à 1 million de jetons par jourLe modèle QwQ-32B est une technologie nouvelle et passionnante qui réduit considérablement les obstacles à l'accès des utilisateurs à la technologie de pointe en matière d'IA. Pour les utilisateurs qui souhaitent bénéficier des puissantes performances du modèle QwQ-32B mais qui sont limités par la puissance de calcul du matériel local, l'appel au modèle en nuage via l'interface API est sans aucun doute une option plus attrayante.
Lecture recommandée pour ceux qui ne connaissent pas QwQ-32B :Petit modèle, grande puissance : QwQ-32B avec un paramètre de 1/20 pour lutter contre DeepSeek-R1 au sang chaud
Avantages de l'interface API : suppression des limitations matérielles, puissance de calcul au bout des doigts
Nous avons déjà publié Déploiement local des grands modèles QwQ-32B : un guide simple pour les PC En outre, les utilisateurs qui souhaitent expérimenter des modèles linguistiques à grande échelle tels que QwQ-32B doivent souvent déployer localement un équipement informatique à haute performance. L'exigence matérielle d'une mémoire vidéo de 24 Go, voire plus, empêche souvent de nombreux utilisateurs d'accéder à l'expérience de l'IA. L'interface API fournie par la plateforme Hundred Refine d'Aliyun résout intelligemment ce problème.
En appelant les modèles QwQ via l'interface API, les utilisateurs peuvent bénéficier de plusieurs avantages :
- Pas de seuil pour la configuration du matériel. Il n'est pas nécessaire de déployer localement du matériel de haute performance, ce qui abaisse le seuil d'utilisation. Même les ordinateurs portables légers et minces, voire les smartphones, peuvent faire appel à la puissance de modélisation du nuage. Il est recommandé aux utilisateurs d'utiliser une carte graphique dotée d'une mémoire vidéo de 24G ou plus pour une expérience d'exécution de modèle local plus fluide.
- Compatibilité avec le système. L'interface API est indépendante du système d'exploitation et multiplateforme. Que vous utilisiez Windows, macOS ou Linux, vous pouvez y accéder facilement.
- La version Plus, plus puissante. Les utilisateurs peuvent découvrir la version améliorée de QwQ Plus, qui surpasse la version complète de QwQ-32B déployée localement. La version Plus, c'est-à-dire la version améliorée du modèle d'inférence de QwQ pour Tongyi Qianqi, est basée sur le modèle Qwen2.5 et entraînée par apprentissage par renforcement. Par rapport à la version de base, la version Plus améliore considérablement la capacité d'inférence du modèle et atteint les meilleures performances dans les mesures principales (par exemple, AIME 24/25, livecodebench) et certaines mesures générales (par exemple, IFEval, LiveBench, etc.) dans l'évaluation. Profondeur de l'eau-R1 Version à sang complet du niveau du modèle.
- Réponse rapide. L'interface API permet des temps de réponse rapides de 40 à 50 jetons/seconde. Cela signifie que les utilisateurs peuvent bénéficier d'une expérience interactive en temps quasi réel, ce qui améliore considérablement l'efficacité.
Il convient de mentionner qu'en plus d'AliCloud Hundred Refine, la plateforme de mobilité in silico fournit également une interface API pour le modèle QwQ-32B. Si les utilisateurs sont intéressés par la plateforme de flux in silico, ils peuvent se référer à l'article précédent. Dans cet article, nous allons principalement présenter comment utiliser l'interface API fournie par la plateforme Aliyun Hundred Refine.
Guide d'accès à l'API Aliyun Hundred Refined : trois étapes simples pour commencer !
La plate-forme AliCloud Hundred Refinement Platform offre aux utilisateurs de l'API du modèle de la série QwQ 1 million de dollars par jour. jetons Le crédit gratuit. Pour la plupart des utilisateurs, ce montant est suffisant pour une expérience et des tests quotidiens. Les utilisateurs n'ont qu'à effectuer une simple inscription et une configuration pour commencer.
Vous trouverez ci-dessous les étapes de la configuration de l'API Aliyun Bai Lian QwQ Plus du côté client :
1) Obtenir la clé API et le nom du modèle
Tout d'abord, visitez le site Plate-forme de raffinement AliCloud Hundred et compléter l'inscription ou la connexion.
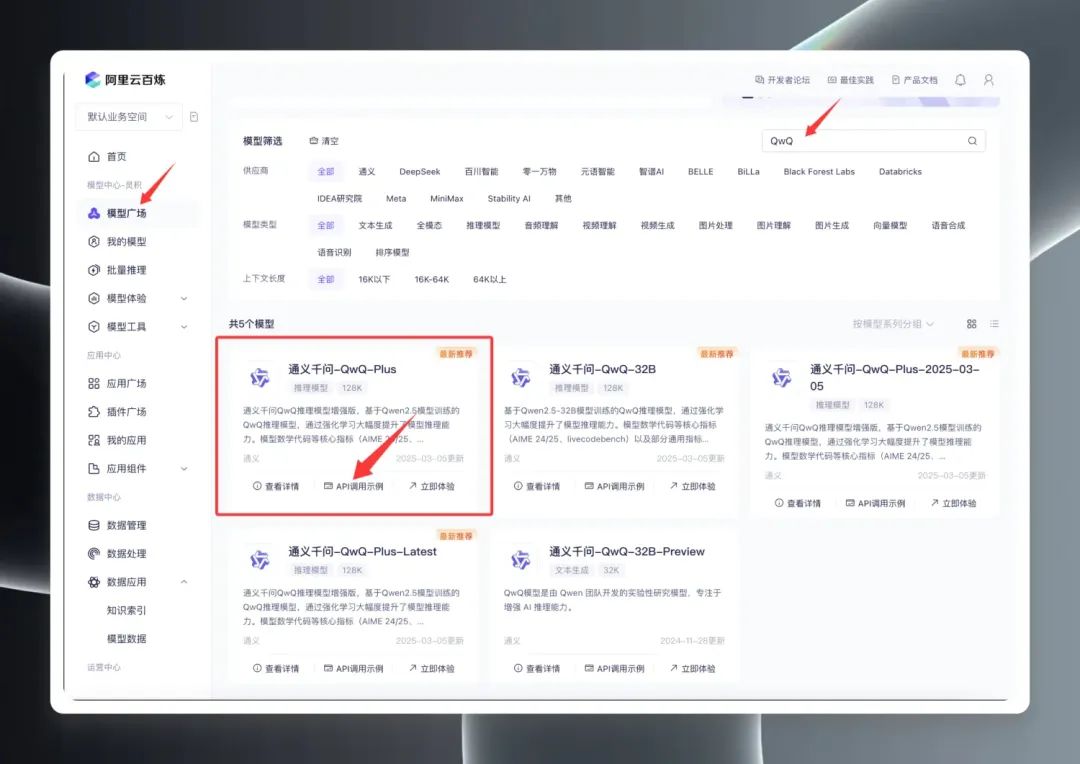
Une fois connecté, recherchez "QwQ" dans le Model Square pour voir la gamme de modèles QwQ. En fait, Model Square affiche trois versions principales : QwQ32B (version officielle), QwQ32B-Preview (version de prévisualisation) et QwQ Plus (version améliorée, également connue sous le nom de version commerciale).
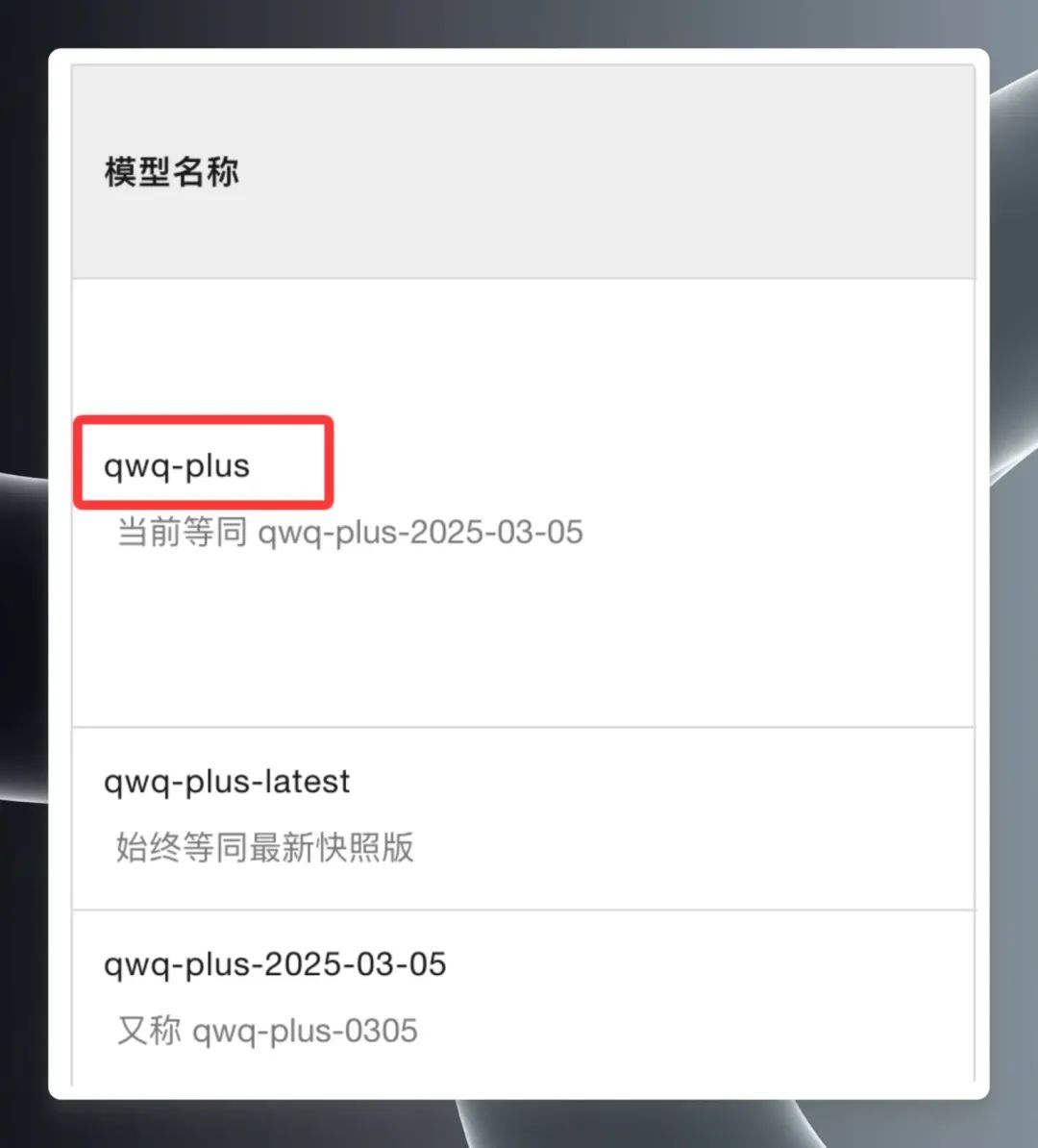
Sélectionnez "QwQ Plus (Enhanced)", cliquez sur "API Call Examples", et sur la nouvelle page, trouvez le fichier Nom du modèle qwq-plus.
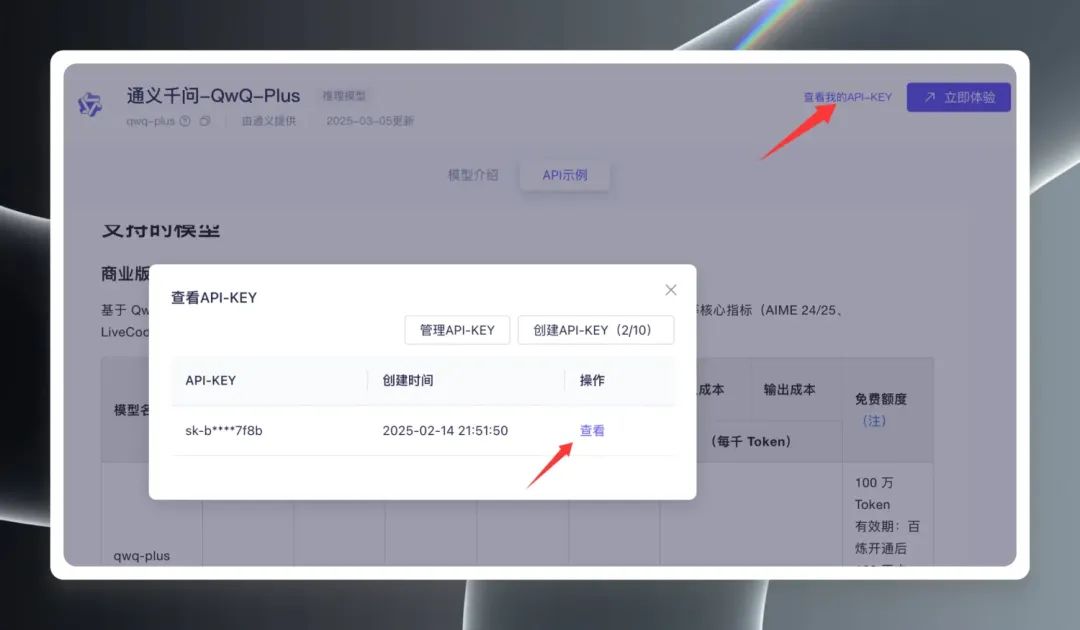
Ensuite, cliquez sur "View My API Key" dans le coin supérieur droit de la page, vous devez créer une clé API pour la première fois, si vous en avez déjà créé une, vous pouvez directement la visualiser et la copier. Clé API.
2. configuration du client
ce document est basé sur Chatwise Le client est utilisé comme exemple à des fins de démonstration. Ouvrez le logiciel Chatwise, cliquez sur l'avatar de l'utilisateur et accédez à l'écran "Paramètres".
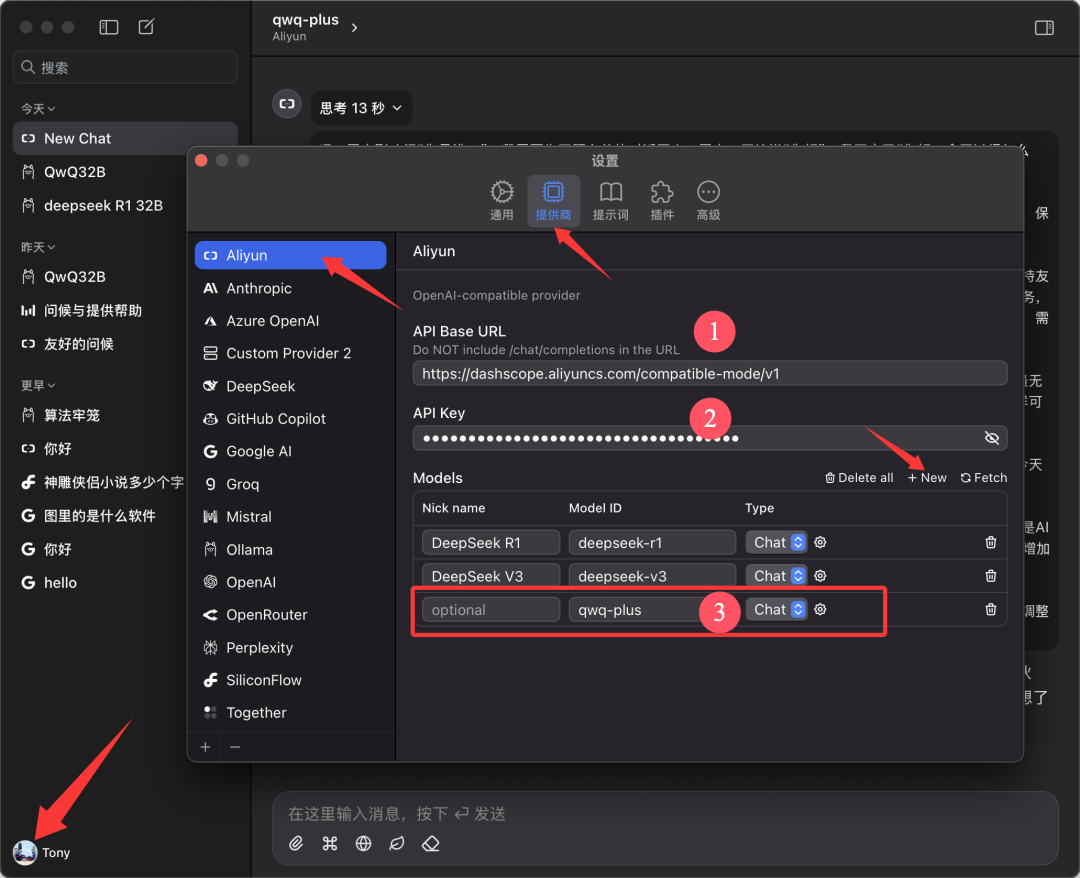
Trouvez "Aliyun" dans la liste des fournisseurs, s'il n'est pas trouvé, cliquez sur "➕" en bas pour l'ajouter.
Configurer comme indiqué dans la figure ci-dessous :
- URL de base de l'API.
https://bailian.aliyuncs.com(Général) - Clé API. Collez la clé API que vous avez copiée à l'étape précédente.
- Modèles. Ajouter le nom du modèle
qwq-plus(doit être le nom)
3. démarrer l'expérience
Retournez à l'écran principal de Chatwise et sélectionnez le modèle "qwq-plus" dans le menu déroulant de sélection du modèle pour commencer votre expérience de dialogue.
Performances réelles : comparables ou supérieures aux déploiements locaux
Afin de vérifier les performances réelles de l'API QwQ Plus, nous avons effectué un simple test de comparaison.
Test de vitesse :
Les mesures montrent que la vitesse de l'interface API de QwQ Plus est excellente, avec un taux stable de 40-50 jetons/seconde. En comparaison, l'interface DeepSeek R1, le taux est nettement plus lent, avec plus de 10 jetons par seconde.
Tests de compatibilité :
Les utilisateurs peuvent également configurer et utiliser l'API QwQ Plus sur un client tel que CherryStudio, mais lors des tests de CherryStudio, un problème potentiel a été observé : lorsque le modèle effectue un raisonnement complexe sur une longue période, CherryStudio peut consommer une grande quantité de ressources système, et des redémarrages de logiciel peuvent se produire sur certains appareils configurés. Cependant, l'utilisation du client Chatwise dans le même environnement matériel n'a pas наблюдаться des problèmes similaires. Cela peut être lié aux différences entre les cadres de développement des différents clients.
Comparaison des compétences :
Nous reprenons les questions de raisonnement logique colorées par un chapeau et comparons les performances du modèle QwQ32 avec celles de l'API QwQ Plus.
Description du problème :
Cinq personnes sont alignées, chacune avec un chapeau de couleur rouge ou bleue. Elles peuvent voir les chapeaux des personnes qui se trouvent devant elles, mais pas le leur. L'animateur annonce : "Il y a au moins un chapeau rouge". En commençant par la dernière personne, chaque personne à tour de rôle dit "oui" ou "non" (en indiquant si elle connaît ou non la couleur de son chapeau). Si la cinquième personne dit "non" et que la quatrième personne dit "oui", trouvez la distribution de toutes les couleurs de chapeau possibles.
Performance du modèle local QwQ32 :

Le modèle local QwQ32 a finalement reçu une réponse positive après deux tentatives, la seconde ayant duré 196 secondes.
QwQ Plus API performance :
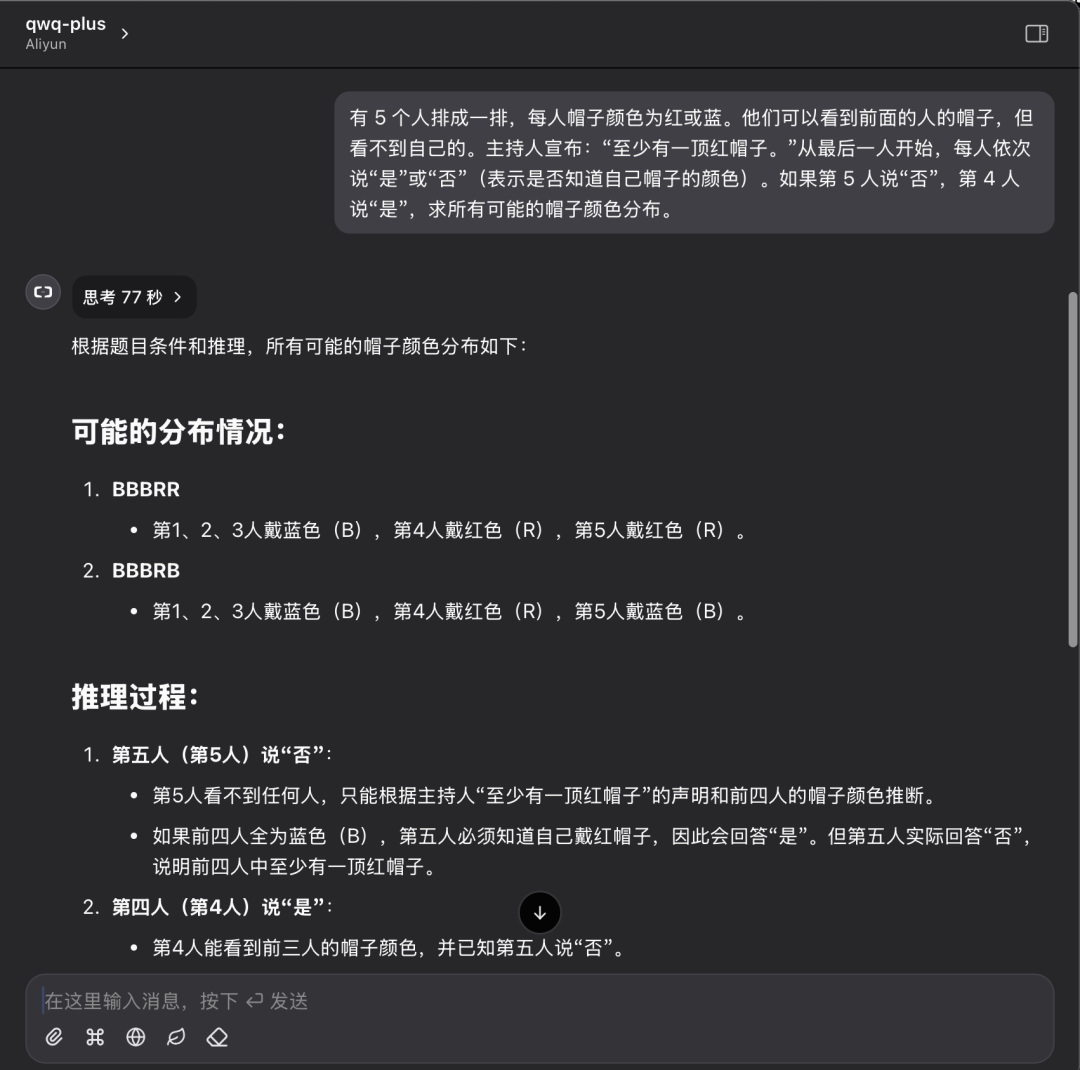
Performance de l'API QwQ Plus pour la même question : une seule réponse correcte en 77 secondes.
Analyse des résultats des tests :
Bien qu'un seul cas ne soit pas suffisant pour évaluer pleinement la capacité du modèle, les résultats de ce test peuvent refléter visuellement la différence entre le modèle déployé localement et la solution API en nuage. Lors de la résolution de problèmes de raisonnement logique, les deux solutions peuvent donner des réponses correctes, mais l'API QwQ Plus est meilleure en termes d'efficacité et de clarté du processus de raisonnement, avec un temps de raisonnement plus court et une consommation de jetons moindre.
Adopter l'IA dans le nuage pour tous
L'ouverture gratuite de l'interface API QwQ-32B sur la plateforme AliCloud Hundred Refine et la mise à disposition de jetons gratuits généreux constituent sans aucun doute une étape importante dans la promotion de la popularité de la technologie de modélisation des grandes langues. Grâce à l'interface API, les utilisateurs peuvent facilement découvrir la puissance des modèles d'IA haute performance dans le nuage sans avoir à investir dans du matériel coûteux. Que vous soyez développeur, chercheur ou passionné d'IA, vous pouvez maintenant profiter pleinement des ressources gratuites fournies par Aliyun Hundred Refine pour commencer votre voyage d'exploration de l'IA.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...