
L'institut de recherche en IA d'Alibaba lance CosyVoice 2 : un modèle amélioré de synthèse vocale en continu


1. vue d'ensemble
La technologie de la synthèse vocale a fait des progrès considérables ces dernières années, notamment en ce qui concerne la génération de discours en temps réel, naturels et fluides. Toutefois, des problèmes tels que la latence, la précision de la prononciation et la cohérence du locuteur continuent de se poser dans les applications réelles, en particulier dans les applications de diffusion en continu qui exigent une grande réactivité. Ces défis techniques sont particulièrement aigus lorsqu'il s'agit d'entrées linguistiques complexes, telles que les virelangues ou les mots polyphoniques, qui dépassent les capacités de traitement des modèles existants. Pour relever ces défis, les chercheurs d'Alibaba ont introduit CosyVoice 2, un modèle amélioré pour les défis techniques de la synthèse vocale, qui vise à résoudre efficacement ces problèmes.
2) CosyVoice 2 Debut : des bases aux percées
 CosyVoice 2 s'appuie sur les fondements du CosyVoice original et apporte une amélioration significative de la technologie de synthèse vocale. Ce modèle amélioré n'est pas seulement optimisé pour les applications de diffusion en continu, mais fait également des progrès significatifs dans les applications hors ligne. Son adaptabilité, sa flexibilité et sa précision dans un large éventail de scénarios d'application ont été améliorées, en particulier dans les systèmes de synthèse vocale et les systèmes vocaux interactifs.
CosyVoice 2 s'appuie sur les fondements du CosyVoice original et apporte une amélioration significative de la technologie de synthèse vocale. Ce modèle amélioré n'est pas seulement optimisé pour les applications de diffusion en continu, mais fait également des progrès significatifs dans les applications hors ligne. Son adaptabilité, sa flexibilité et sa précision dans un large éventail de scénarios d'application ont été améliorées, en particulier dans les systèmes de synthèse vocale et les systèmes vocaux interactifs.
Principales caractéristiques de CosyVoice 2 :
- Modes unifiés de diffusion en continu et de non-diffusion en continuCosyVoice 2 s'adapte de manière transparente à une variété de scénarios d'application, qu'ils soient générés en temps réel ou traités hors ligne, sans compromettre les performances.
- Plus grande précision de la prononciationDans les environnements linguistiques complexes, CosyVoice 2 réduit les erreurs de prononciation de 30%-50% et améliore considérablement l'intelligibilité de la parole, en particulier lorsqu'il s'agit de mots polysyllabiques ou de virelangues.
- amélioration de la congruence de l'orateurQu'il s'agisse de synthèse zéro ou de synthèse inter-langues, CosyVoice 2 garantit la cohérence de la sortie, de sorte que chaque synthèse est naturelle et fluide.
- Un contrôle de commande plus précisLes utilisateurs peuvent contrôler avec précision le ton, le style et l'accent de leur voix par le biais de commandes en langage naturel, et même adapter la performance vocale aux besoins émotionnels.
3. la technologie et les atouts qui sous-tendent l'innovation
CosyVoice 2 a permis de relever un certain nombre de défis dans le domaine de la synthèse vocale grâce à un certain nombre d'innovations technologiques.
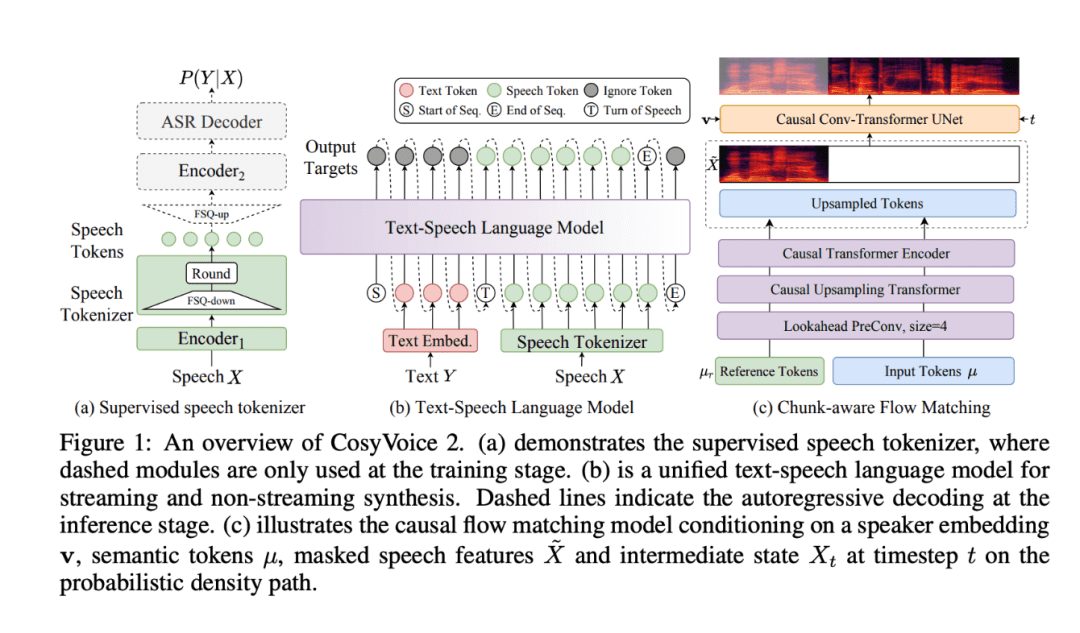
- Technique de quantification scalaire finie (FSQ) : la FSQ remplace la méthode traditionnelle de quantification vectorielle, optimise l'utilisation des vocabulaires étiquetés et améliore la capacité de représentation sémantique et la qualité de la synthèse. Cette innovation technologique permet non seulement d'améliorer le pouvoir d'expression du modèle, mais aussi de réduire efficacement la complexité du traitement des données.
- Architecture simplifiée de la synthèse vocale : CosyVoice 2 est basé sur de grands modèles de langue (LLM) pré-entraînés, ce qui élimine le besoin d'encodeurs de texte supplémentaires et simplifie l'architecture du modèle pour améliorer les performances inter-langues. Cette conception architecturale rend CosyVoice 2 beaucoup plus efficace et précis lors du traitement de plusieurs langues.
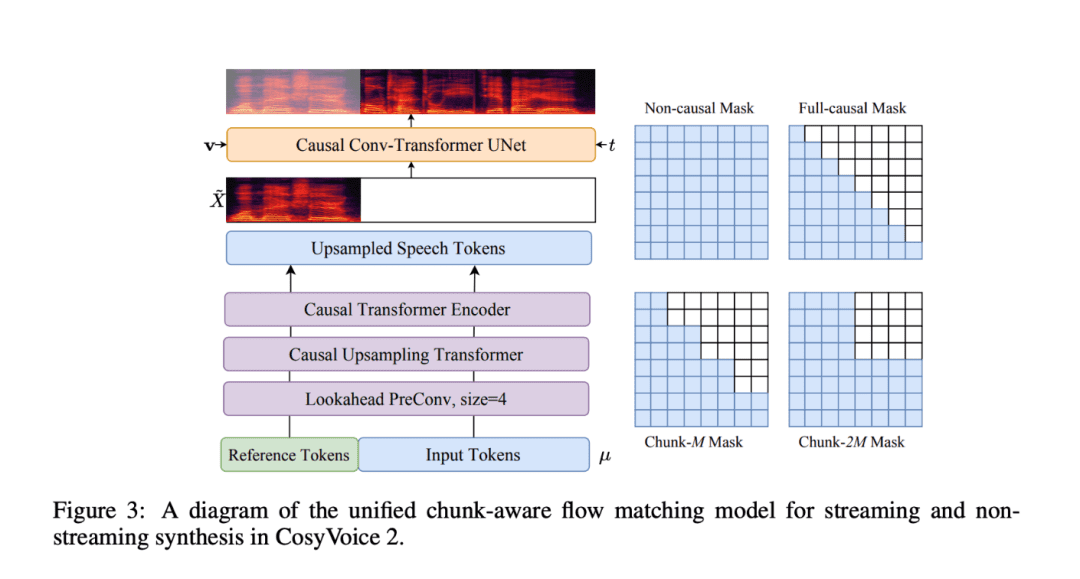
- Correspondance de flux causal consciente des blocs : cette technologie innovante permet d'aligner les caractéristiques sémantiques et acoustiques avec un temps de latence minimal, ce qui permet à CosyVoice 2 d'exceller dans la génération vocale en temps réel, en particulier pour l'interaction vocale en temps réel et les applications de diffusion en continu.
- Ensemble de données de commande étendu : avec plus de 1500 heures de données de formation, CosyVoice 2 ajoute un contrôle granulaire sur les différents accents, émotions et styles de voix, rendant la synthèse vocale plus flexible et plus expressive. Qu'il s'agisse d'un ton de voix chaleureux ou d'une émotion tendue, CosyVoice 2 est capable de la capturer et de l'exprimer avec précision.
4. les performances de CosyVoice 2 : comment il résout les problèmes du monde réel
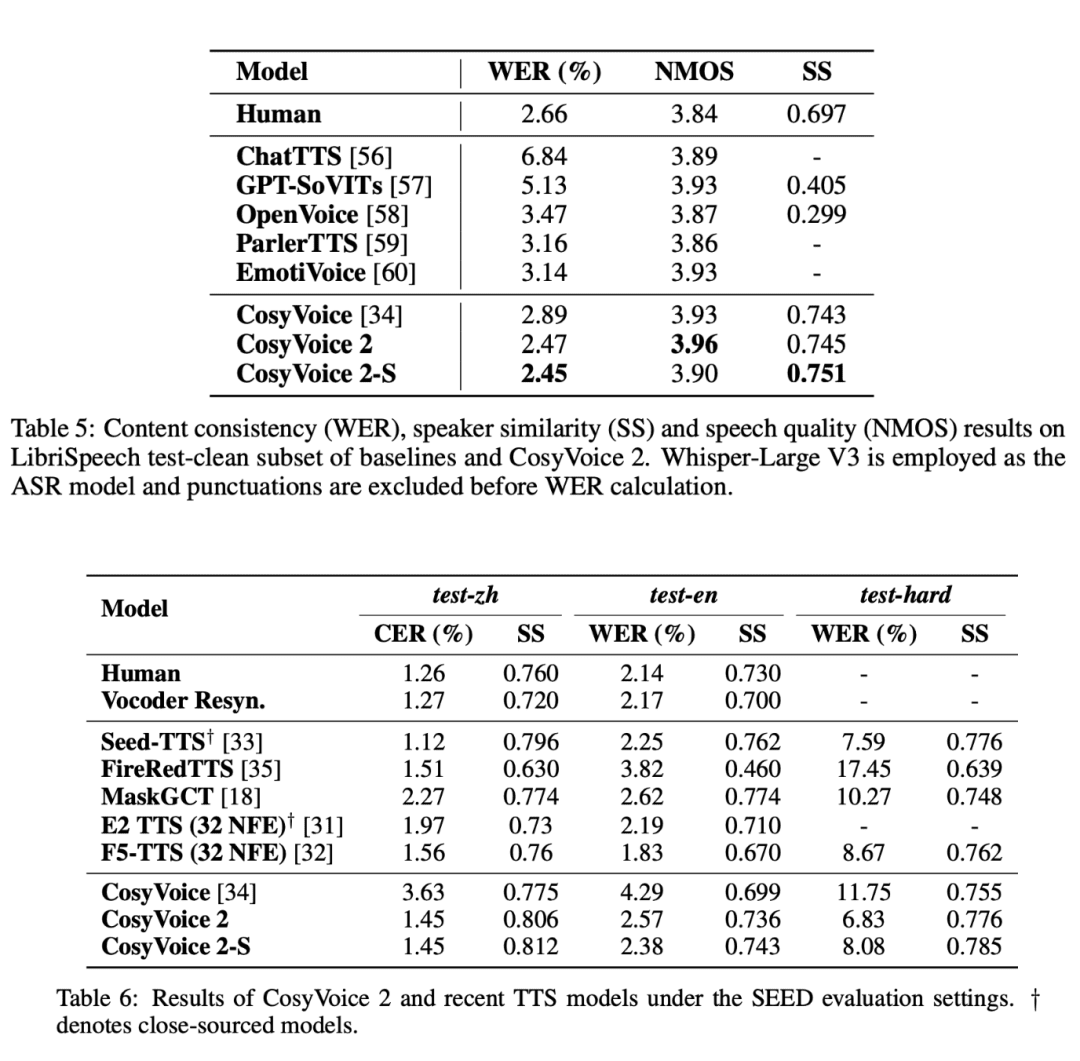
Lors d'une série de tests d'évaluation rigoureux, CosyVoice 2 a démontré des avantages indéniables, notamment en termes de faible latence, de précision élevée et de cohérence vocale.
- Faible temps de latence et grande efficacitéCosyVoice 2 a des temps de réponse aussi courts que 150 millisecondes lors de la génération de la parole, ce qui signifie qu'il est parfaitement adapté aux applications vocales en temps réel, telles que le chat vocal et les interactions en continu.
- Amélioration de la précision de la prononciationCosyVoice 2 apporte des améliorations significatives aux structures linguistiques complexes (polysyllabes, virelangues, etc.), améliorant considérablement la précision de la prononciation et réduisant les erreurs dans la synthèse vocale de tous les jours.
- Performances constantes du haut-parleurCosyVoice 2 est capable de maintenir un haut degré de cohérence entre les différentes tâches de synthèse, qu'il s'agisse de la synthèse interlinguistique ou de la synthèse zéro, et le naturel et la stabilité de la parole sont largement garantis.
- multilinguismeCosyVoice 2 a également obtenu de bons résultats dans les tests de référence pour des langues telles que le japonais et le coréen et, malgré les difficultés rencontrées avec certains jeux de caractères qui se chevauchent, il a démontré la puissance de la synthèse interlinguistique.
- Résilience dans des scénarios difficilesCosyVoice 2 a fait preuve d'une clarté et d'une précision supérieures à celles des modèles précédents dans certains scénarios vocaux difficiles (par exemple, les virelangues), dépassant ainsi les limites techniques antérieures.
5. conclusion
Le lancement de CosyVoice 2 représente une avancée importante dans la technologie de la synthèse vocale. Des technologies innovantes telles que le FSQ et la correspondance des flux causaux en bloc soutiennent fortement les performances et la facilité d'utilisation du modèle, tandis que le vaste ensemble de données d'apprentissage et le contrôle précis des styles vocaux lui permettent de faire face à un large éventail de scénarios d'applications vocales complexes.
Bien que CosyVoice 2 doive encore être amélioré en termes de prise en charge multilingue et de traitement de scénarios linguistiques complexes, il jette des bases solides pour la future technologie de synthèse vocale, en particulier dans l'application des médias en continu et de la génération vocale en temps réel, qui offre de vastes perspectives de développement. Que ce soit dans le domaine de l'assistant vocal IA, du service client intelligent ou de la traduction en temps réel, CosyVoice 2 démontre son fort potentiel et ouvre la voie à de nouvelles percées dans la technologie de la synthèse vocale.
Référence :
- https://arxiv.org/abs/2412.10117
- https://huggingface.co/spaces/FunAudioLLM/CosyVoice2-0.5B
- https://www.modelscope.cn/models/iic/CosyVoice2-0.5B
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...