AI Engineering Academy : 2.4 Techniques de regroupement de données pour les systèmes de génération augmentée de recherche (RAG)
bref
Le découpage des données est une étape clé dans les systèmes de génération améliorée de recherche (RAG). Il permet de diviser les documents volumineux en éléments plus petits et plus faciles à gérer pour une indexation, une recherche et un traitement efficaces. Ce README fournit RAG Vue d'ensemble des différentes méthodes de découpage disponibles dans le pipeline.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Data_Ingestion
Importance du regroupement dans le RAG
Un découpage efficace est essentiel au système RAG car il permet de
- Améliorer la précision de la recherche en créant des unités d'information cohérentes et autonomes.
- Amélioration de l'efficacité de la génération de l'intégration et de la recherche de similitudes.
- Permet une sélection plus précise du contexte lors de la génération des réponses.
- Contribuer à la gestion des modèles linguistiques et des systèmes intégrés de Jeton Limites.
Méthode de regroupement
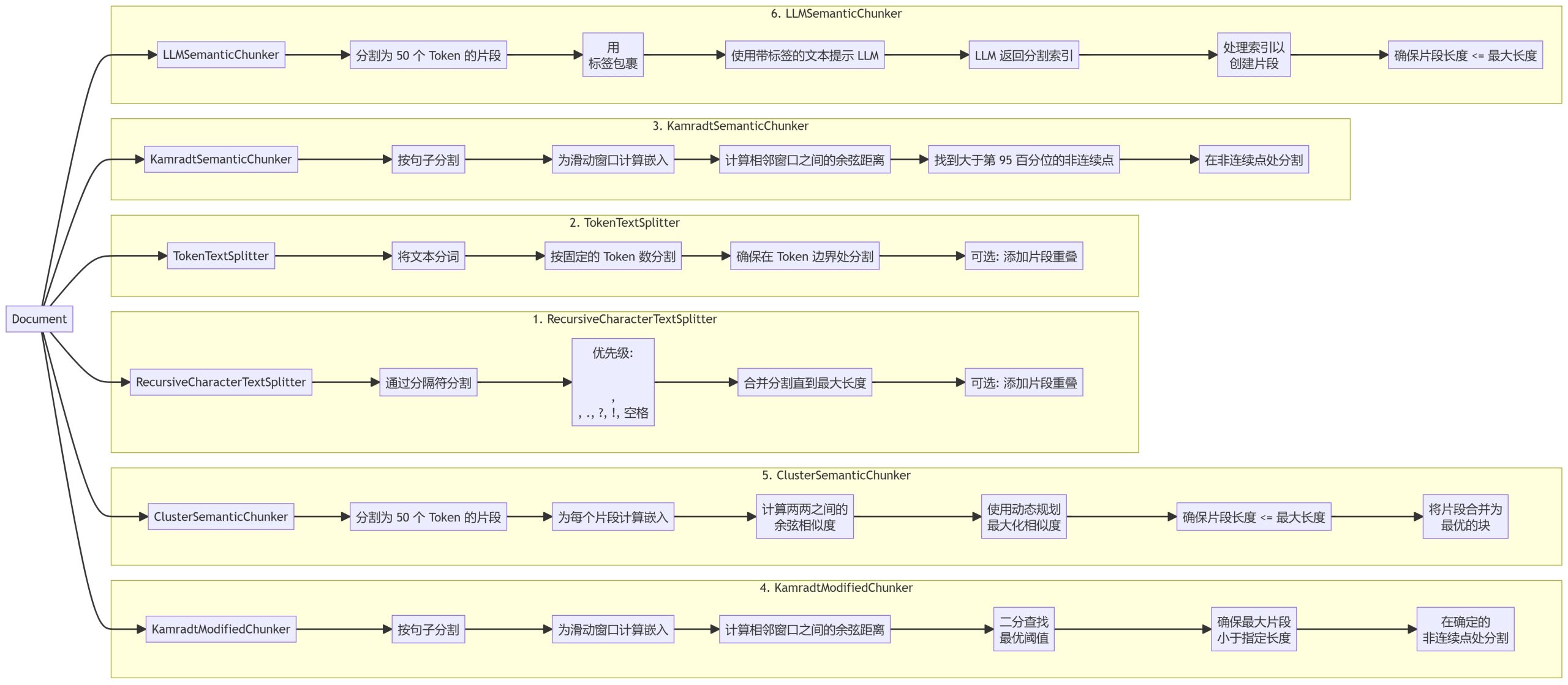
Nous avons mis en œuvre six méthodes de regroupement différentes, chacune présentant des avantages et des scénarios d'utilisation différents :
- RecursiveCharacterTextSplitter (Séparateur de texte)
- Séparateur de texte token
- KamradtSemanticChunker
- KamradtModifiedChunker
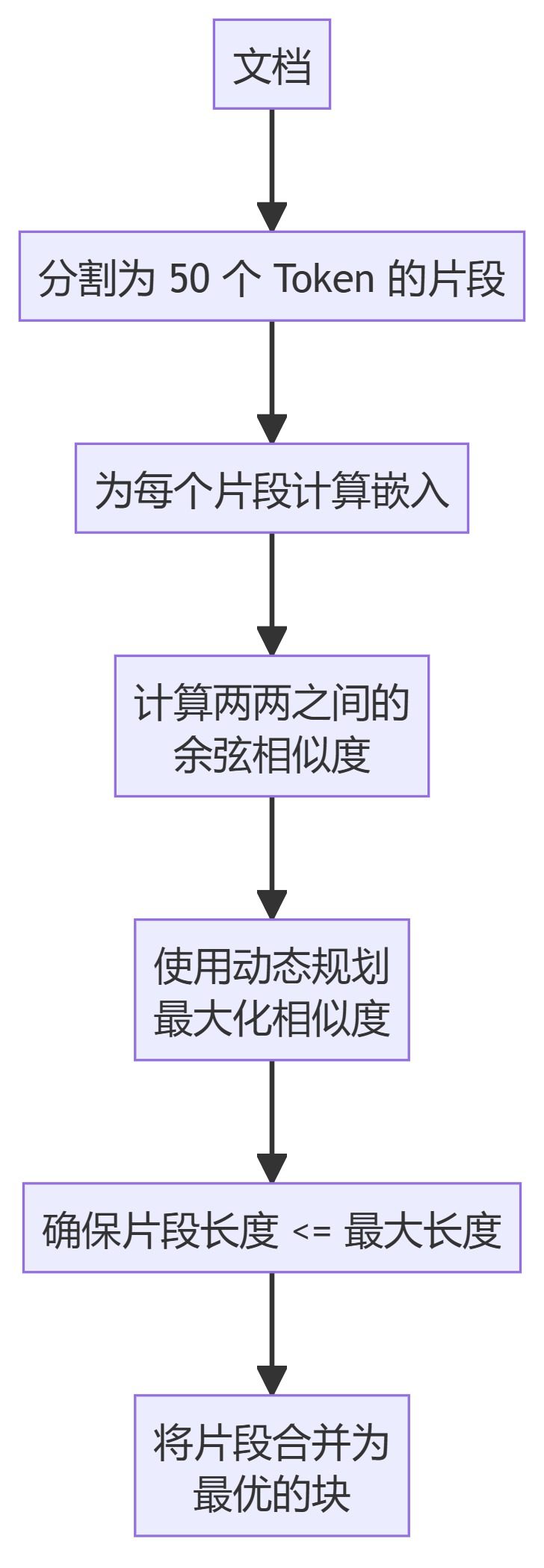
- ClusterSemanticChunker (grappe sémantique)
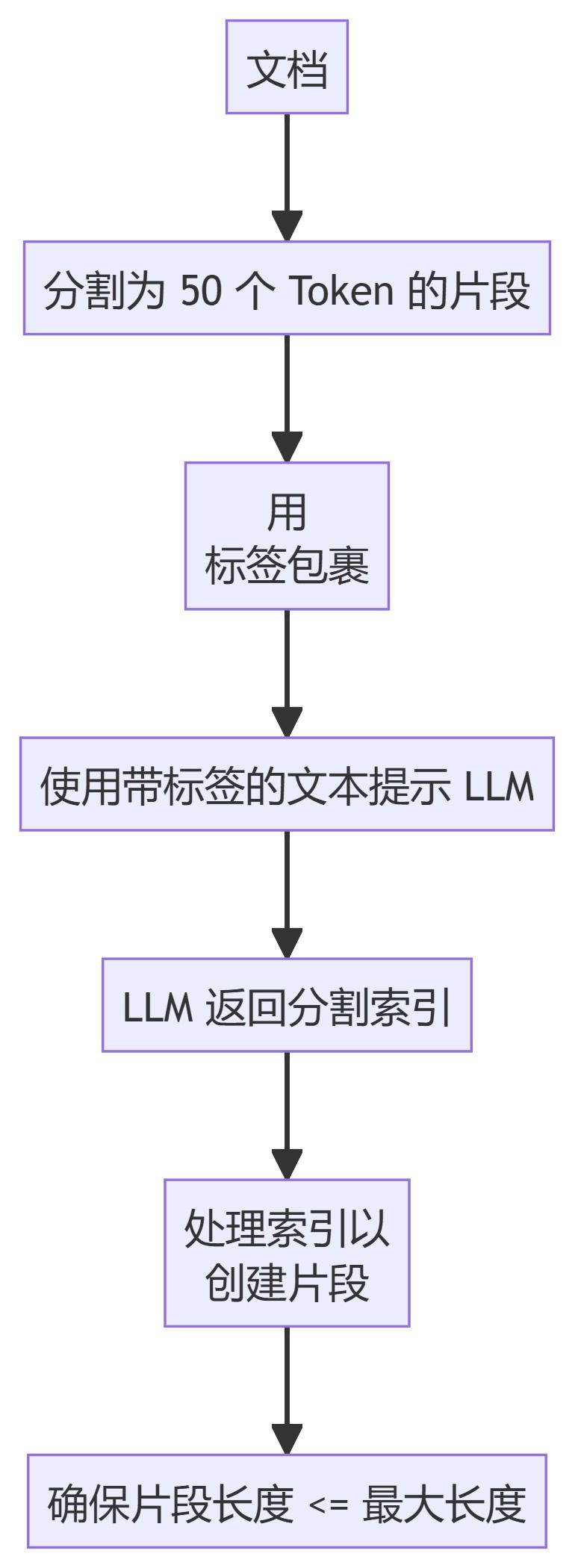
- LLMSemanticChunker
découpage
1. séparateur de caractères récursif
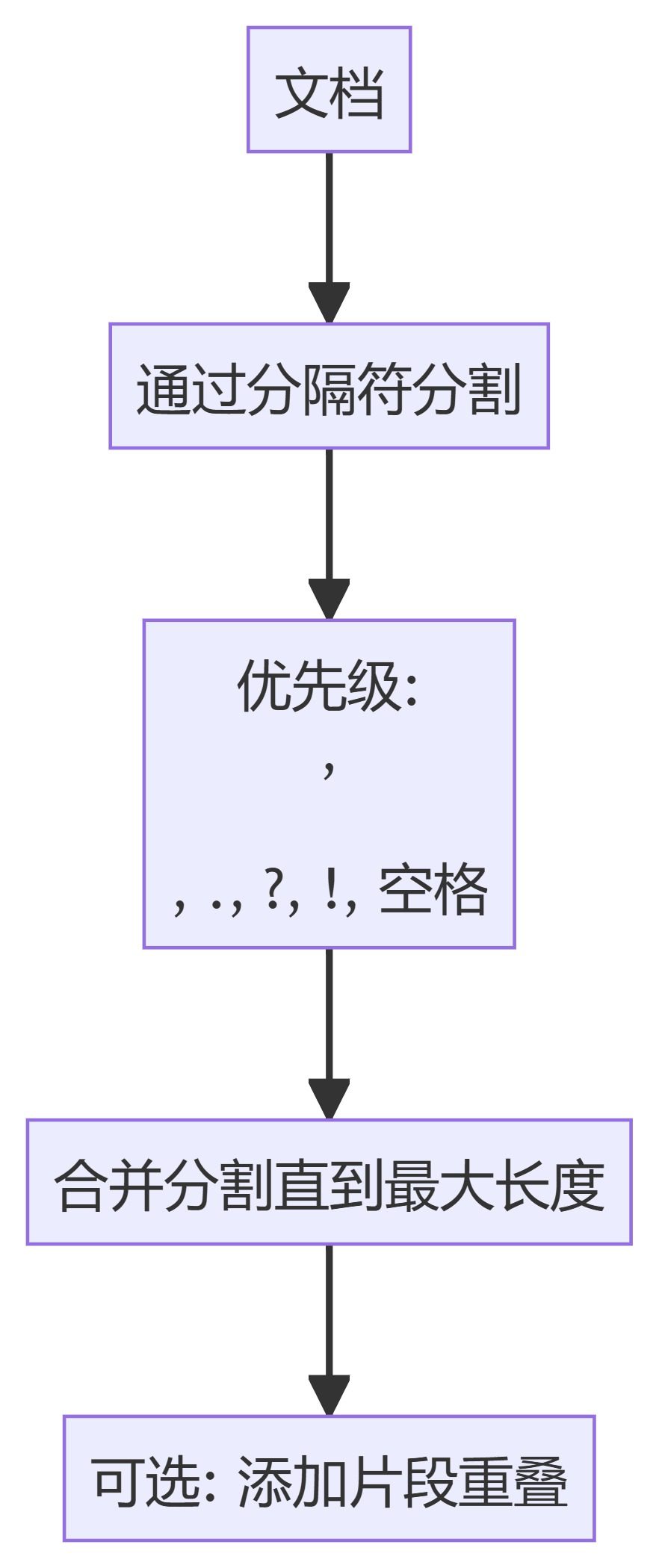
2. séparateur de texte de jeton (TokenTextSplitter)

3) KamradtSemanticChunker
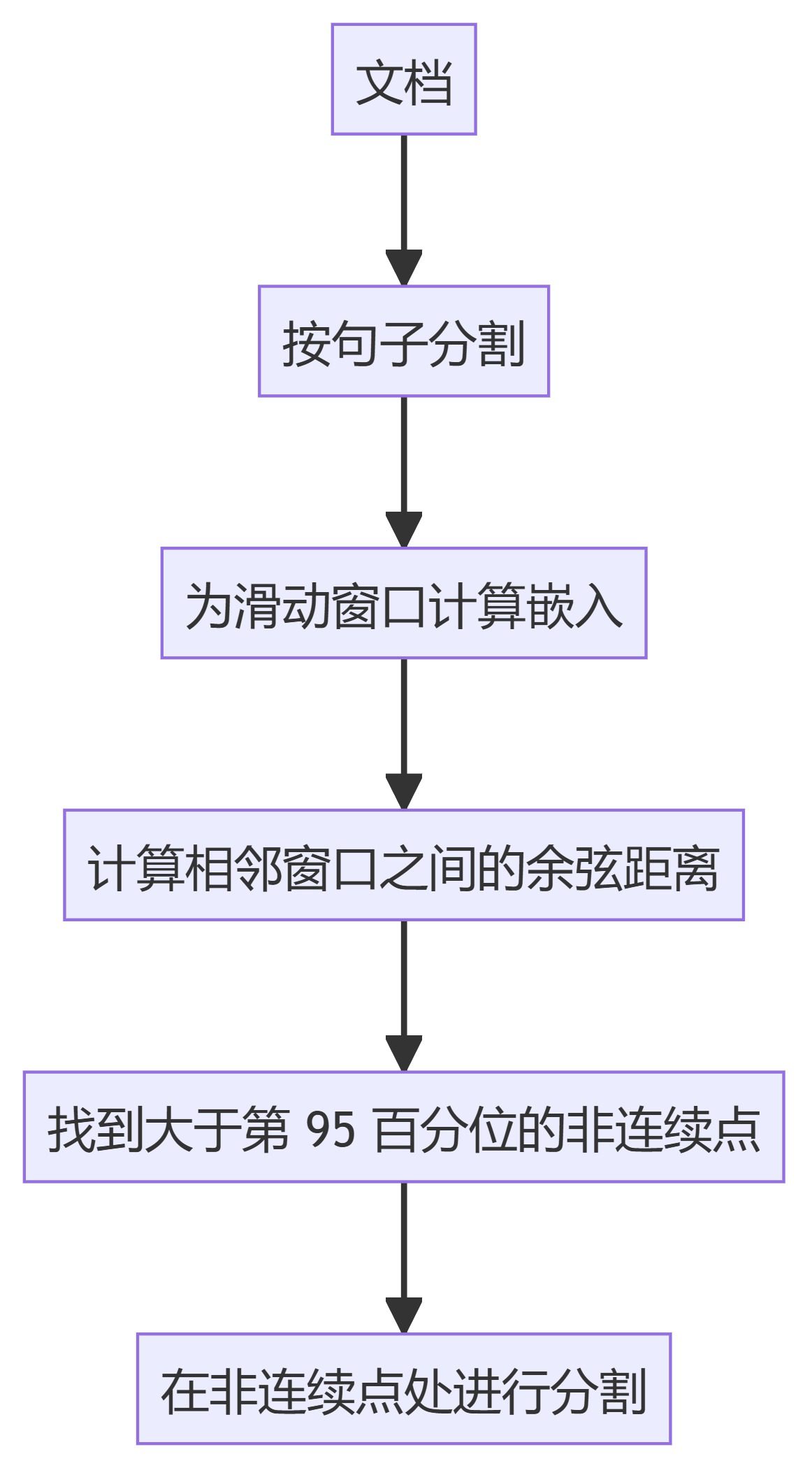
4) KamradtModifiedChunker
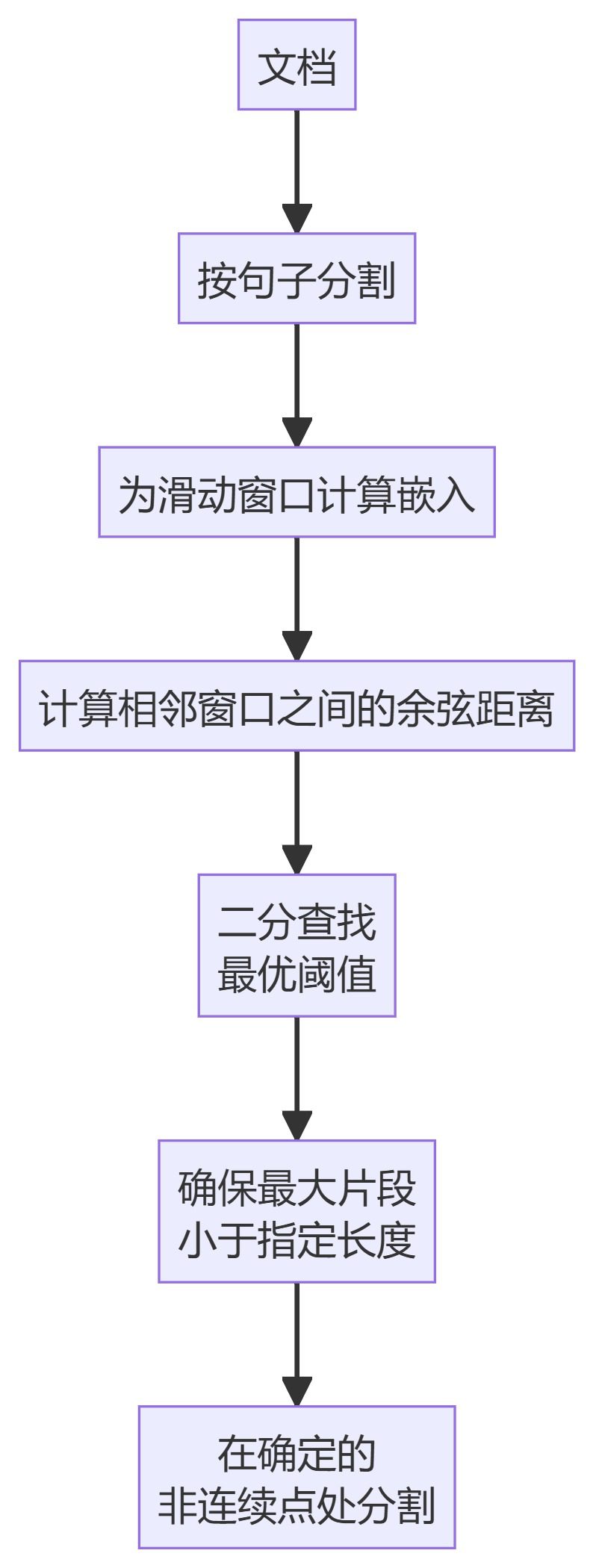
5. le ClusterSemanticChunker
6) LLMSemanticChunker
Description de la méthode
- RecursiveCharacterTextSplitter (Séparateur de texte)Le texte est divisé en fonction d'une hiérarchie de délimiteurs, en donnant la priorité aux points de rupture naturels dans le document.
- Séparateur de texte token: divise le texte en blocs d'un nombre fixe de tokens, en veillant à ce que la division se fasse à la limite des tokens.
- KamradtSemanticChunkerLes textes sont segmentés en fonction des discontinuités sémantiques, à l'aide de l'intégration de fenêtres coulissantes.
- KamradtModifiedChunkerKamradtSemanticChunker : version améliorée de KamradtSemanticChunker qui utilise la recherche par bissection pour trouver le seuil optimal de segmentation.
- ClusterSemanticChunker (grappe sémantique)La programmation dynamique permet de créer des morceaux optimaux sur la base de la similarité sémantique.
- LLMSemanticChunkerLes élèves de l'enseignement secondaire et supérieur sont en mesure d'identifier les points de segmentation appropriés dans un texte grâce à la modélisation linguistique.
Utilisation
Pour utiliser ces méthodes de regroupement dans votre processus RAG :
- à travers (une brèche)
chunkerspour importer les chunkers nécessaires. - Initialiser le chunker avec les paramètres appropriés (par exemple, la taille maximale des morceaux, le chevauchement).
- Transmettez votre document à l'outil de découpage pour obtenir les résultats du découpage.
Exemple :
from chunkers import RecursiveCharacterTextSplitter
chunker = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = chunker.split_text(your_document)
Comment choisir une méthode de découpage en morceaux ?
Le choix de la méthode de découpage dépend de votre cas d'utilisation spécifique :
- Pour une division simple du texte, vous pouvez utiliser RecursiveCharacterTextSplitter ou TokenTextSplitter.
- Si une segmentation sémantique est nécessaire, envisagez KamradtSemanticChunker ou KamradtModifiedChunker.
- Pour un découpage sémantique plus avancé, utilisez ClusterSemanticChunker ou LLMSemanticChunker.
Facteurs à prendre en compte lors de la sélection d'une méthode :
- Structure du document et types de contenu
- Taille des morceaux et chevauchement requis
- Ressources informatiques disponibles
- Exigences spécifiques du système de recherche (par exemple, basé sur un vecteur ou sur un mot-clé)
Il est possible d'essayer différentes méthodes et de trouver celle qui répond le mieux à vos besoins en matière de documentation et de recherche.
Intégration avec les systèmes RAG
Une fois le découpage effectué, les étapes suivantes sont généralement exécutées :
- Générer des embeddings pour chaque morceau (pour les systèmes de recherche basés sur les vecteurs).
- Indexer ces morceaux dans le système de recherche sélectionné (par exemple, base de données vectorielle, index inversé).
- Lorsque vous répondez à une requête, utilisez les morceaux de l'index lors de l'étape de recherche.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...