Académie d'ingénierie de l'IA : 2.2 Mise en œuvre du RAG de base
présenter (qqn pour un emploi, etc.)
Génération améliorée par la recherche (RAG) est une technique puissante qui combine les avantages des grands modèles de langage avec la capacité de récupérer des informations pertinentes à partir d'une base de connaissances. Cette approche améliore la qualité et la précision des réponses générées en les basant sur des informations spécifiques récupérées.a Ce carnet a pour but de fournir une introduction claire et concise à RAG et convient aux débutants qui souhaitent comprendre et mettre en œuvre cette technique.
Processus RAG
commencement
Carnet de notes
Vous pouvez exécuter le Notebook fourni dans ce dépôt. https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Basic_RAG
application de chat
- Installer les dépendances :
pip install -r requirements.txt - Exécuter l'application :
python app.py - Importation dynamique de données :
python app.py --ingest --data_dir /path/to/documents
serveur (ordinateur)
Utilisez la commande suivante pour lancer le serveur :
python server.py
Le serveur fournit deux points d'extrémité :
/api/ingest/api/query
locomotive
Les modèles linguistiques traditionnels génèrent du texte sur la base de modèles appris à partir de données d'apprentissage. Cependant, ils peuvent avoir du mal à fournir des réponses précises lorsqu'ils sont confrontés à des requêtes nécessitant des informations spécifiques, actualisées ou spécialisées. RAG remédie à cette limitation en introduisant une étape de recherche qui fournit au modèle de langage un contexte pertinent afin de générer des réponses plus précises.
Détails méthodologiques
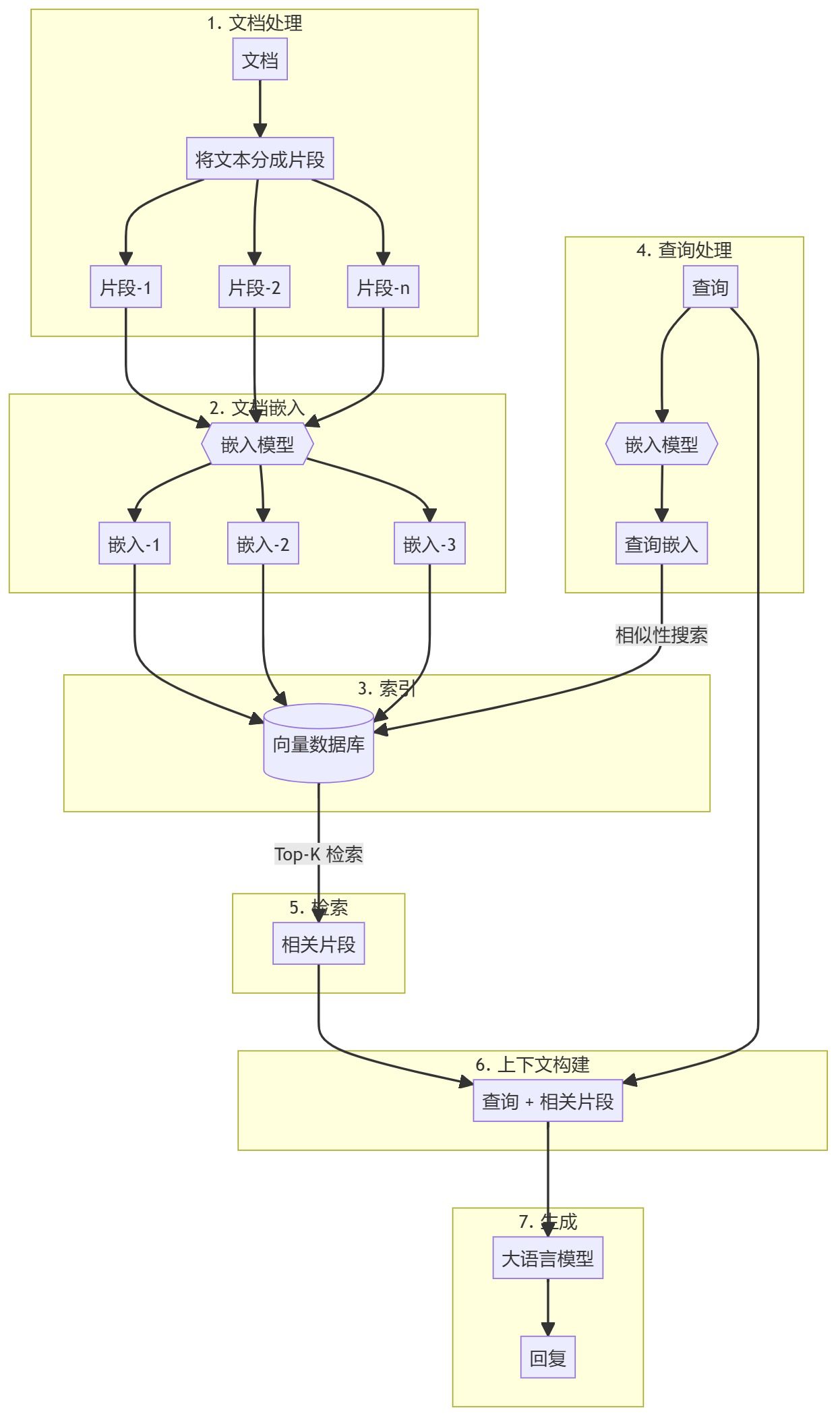
Prétraitement des documents et création d'une base de données vectorielles
- Regroupement de documentsLe traitement des documents de la base de connaissances : prétraiter et diviser les documents de la base de connaissances (par exemple, les PDF, les articles) en morceaux gérables. Cela permet de créer un corpus consultable pour des processus de recherche efficaces.
- Générer l'intégrationChaque bloc est converti en une représentation vectorielle à l'aide d'un algorithme d'intégration pré-entraîné (par exemple, l'algorithme d'intégration d'OpenAI). Ces documents sont ensuite stockés dans une base de données vectorielle (par exemple Qdrant) pour une recherche de similarité efficace.
Flux de travail de la génération d'augmentation de la recherche (RAG)
- Demande de renseignementsLes utilisateurs posent des questions auxquelles il faut répondre.
- étape de rechercheLa base de données vectorielle est constituée des éléments suivants : la requête est intégrée dans un vecteur à l'aide du même modèle d'intégration que celui utilisé pour les documents. Il effectue ensuite une recherche de similarité dans la base de données vectorielle pour trouver le bloc de documents le plus pertinent.
- Étapes de la génération: : Les morceaux de documents récupérés sont transmis en tant que contexte supplémentaire à un grand modèle linguistique (par exemple, GPT-4). Le modèle utilise ce contexte pour générer des réponses plus précises et plus pertinentes.
Principales caractéristiques du RAG
- pertinence contextuelleEn générant des réponses basées sur les informations effectivement récupérées, le modèle RAG peut générer des réponses plus pertinentes et plus exactes sur le plan contextuel.
- évolutivitéL'étape de recherche peut être étendue pour traiter de grandes bases de connaissances, ce qui permet au modèle d'extraire du contenu à partir de quantités massives d'informations.
- Flexibilité des cas d'utilisationLe RAG peut être adapté à une variété de scénarios d'application, y compris les questions-réponses, la génération de résumés, les systèmes de recommandation, etc.
- Amélioration de la précision: : La combinaison de la recherche et de la génération permet souvent d'obtenir des résultats plus précis, en particulier pour les requêtes qui nécessitent des informations spécifiques ou froides.
Avantages de cette méthode
- Combiner les avantages de la recherche et de la générationLe RAG combine efficacement une approche basée sur la recherche et un modèle génératif pour une recherche précise des faits et une génération de langage naturel.
- Amélioration de la gestion des requêtes à longue traîneLa méthode est particulièrement performante pour les requêtes qui nécessitent des informations spécifiques et peu courantes.
- Adaptation du domaineLes mécanismes de recherche peuvent être adaptés à des domaines spécifiques afin de garantir que les réponses générées sont basées sur les informations les plus pertinentes et les plus précises du domaine.
rendre un verdict
La génération améliorée par récupération (RAG) est une fusion innovante de technologies de récupération et de génération qui améliore efficacement les capacités d'un modèle linguistique en basant les résultats sur des informations externes pertinentes. Cette approche est particulièrement précieuse dans les scénarios de réponse qui nécessitent des réponses précises et adaptées au contexte (par exemple, l'assistance à la clientèle, la recherche universitaire, etc.) Alors que l'IA continue d'évoluer, RAG se distingue par son potentiel à construire des systèmes d'IA plus fiables et plus sensibles au contexte.
conditions préalables
- Préférence pour Python 3.11
- Jupyter Notebook ou JupyterLab
- Clé API LLM
- N'importe quel LLM peut être utilisé. Dans ce cahier, nous utilisons OpenAI et GPT-4o-mini.
Grâce à ces étapes, vous pouvez mettre en place un système RAG de base qui intègre des informations réelles et actualisées afin d'améliorer l'efficacité de votre modèle linguistique dans une variété d'applications.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...