
AI Engineering Academy : 2.10 Récupérateur de fusion automatisé
bref
Le chercheur de fusion automatisé estCadre de la génération de recherche améliorée (RAG)Une implémentation de haut niveau de l'approche L'approche vise à améliorer la connaissance du contexte et la cohérence des réponses générées par l'IA en fusionnant des contextes potentiellement fragmentés et plus petits en contextes plus larges et plus complets.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/05_Auto_Merging_RAG
Motivation générale
Les systèmes traditionnels de génération de recherche augmentée ont souvent du mal à maintenir la cohérence dans des contextes plus larges ou sont peu performants lorsqu'ils traitent des informations qui s'étendent sur plusieurs segments de texte. Les systèmes de récupération par fusion automatique remédient à cette limitation en fusionnant de manière récursive les ensembles de nœuds enfants qui font référence à un nœud parent dépassant un seuil spécifique, fournissant ainsi un contexte plus complet et cohérent dans le processus de récupération et de génération.
Détails méthodologiques
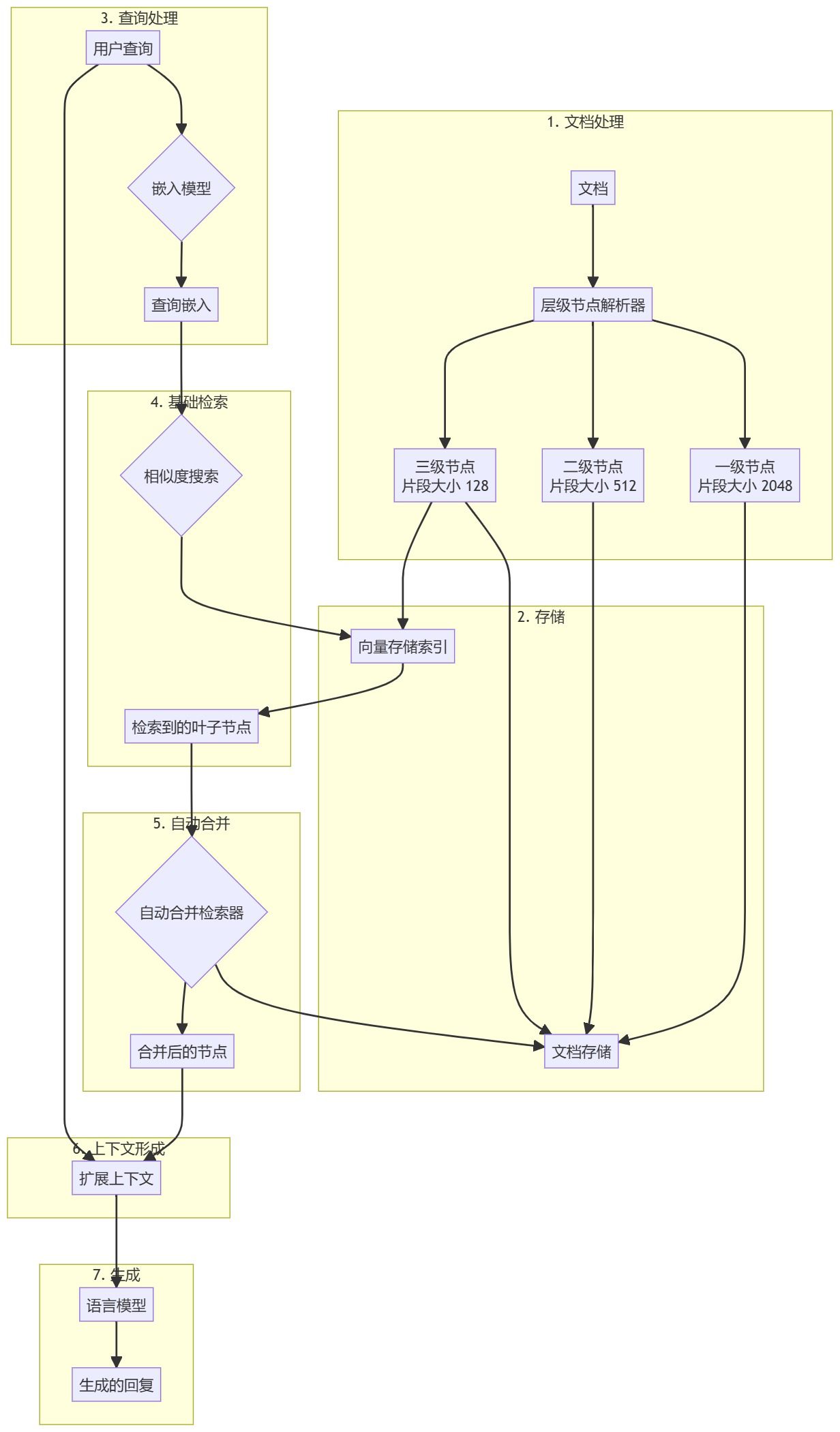
Prétraitement des documents et création de hiérarchies
- Chargement des documentsLes documents d'entrée (par exemple, les fichiers PDF) sont chargés et traités.
- résolution hiérarchique: Utilisation
HierarchicalNodeParserCrée une hiérarchie de nœuds à partir d'un document :- Niveau 1 : Taille du bloc 2048
- Niveau 2 : Taille du bloc 512
- Niveau 3 : Taille du bloc 128
- Stockage des nœudsLes nœuds des feuilles sont également indexés dans la base de données vectorielles.
Amélioration du processus de génération de recherche
- Prétraitement des requêtesLes blocs de documents : utiliser le même modèle d'intégration que pour les blocs de documents afin de traiter les requêtes des utilisateurs.
- Recherche de baseLe chercheur de base effectue une première recherche de similarité pour trouver les nœuds feuilles pertinents.
- Fusion automatique: :
AutoMergingRetrieverL'ensemble des nœuds feuilles récupérés est analysé et le sous-ensemble des nœuds feuilles qui font référence au nœud parent au-delà d'un seuil donné est récursivement "fusionné". - extension du contexte (informatique)Les nœuds fusionnés forment un contexte étendu et sont fusionnés avec la requête originale.
- Générer une réponseLes réponses sont générées en introduisant des contextes d'extension et des requêtes dans le modèle de langage étendu (LLM).
Principales caractéristiques de l'outil de recherche automatique de fusion
- Représentation hiérarchique des documentsLes blocs de documents : gérer une hiérarchie à plusieurs niveaux de blocs de documents.
- Recherche de base efficaceLe projet de recherche d'informations préliminaires rapides et précises à l'aide de recherches de similarités vectorielles.
- Extension du contexte dynamiqueLes services d'aide à la décision : fusionner automatiquement des blocs de texte apparentés dans des contextes plus vastes et plus cohérents.
- Une réalisation flexibleLes modèles linguistiques : Ils peuvent être utilisés pour un large éventail de types de documents et de modèles linguistiques.
Avantages de cette méthode
- Renforcer la cohérence contextuelleLes modèles linguistiques : Ils fournissent un contexte plus cohérent et plus complet pour le modèle linguistique plus large en fusionnant des morceaux de texte apparentés.
- Adaptabilité de la rechercheLe processus de fusion s'adapte automatiquement à la requête et aux résultats de la recherche pour fournir des informations pertinentes en fonction du contexte.
- Structure de stockage efficaceLe système d'information sur les nœuds de feuilles : une mise en œuvre rapide de l'extraction de base des nœuds de feuilles tout en conservant une structure hiérarchique.
- Possibilité d'améliorer la qualité des réponsesLe contexte élargi devrait permettre d'obtenir des réponses plus précises et plus détaillées à l'aide du modèle linguistique.
Résultats
Les résultats expérimentaux montrent que la comparaison entre le chercheur de fusion automatique et le chercheur de base :
- Des performances similaires en matière d'exactitude, de pertinence, de précision et de similarité sémantique.
- Dans les comparaisons par paire, 52,51 utilisateurs de TCP3T ont préféré la réponse du chercheur de fusion automatique.
Ces résultats montrent que les performances de la recherche automatisée de fusion sont comparables, voire légèrement supérieures, aux méthodes de recherche traditionnelles.
rendre un verdict
La recherche automatisée de fusion fournit une méthode avancée pour améliorer la qualité de l'information. RAG dans le système. En fusionnant dynamiquement des blocs de texte pertinents dans des contextes plus vastes et plus cohérents, il s'attaque à certaines des limites des méthodes de recherche traditionnelles basées sur les blocs de texte. Bien que les premiers résultats montrent des perspectives positives, des recherches et des optimisations supplémentaires devraient permettre d'améliorer de manière significative la qualité et la cohérence des réponses.
conditions préalables
Pour mettre en œuvre ce système, vous aurez besoin
- Un grand modèle linguistique capable de générer du texte (par exemple, GPT-3.5-turbo, GPT-4).
- Un modèle d'intégration pour convertir les blocs de texte et les requêtes en représentations vectorielles.
- Bases de données vectorielles pour une recherche efficace de similitudes (par exemple FAISS).
- Un magasin de documents pour stocker la hiérarchie complète des nœuds.
- offrir
LlamaIndexqui contientHierarchicalNodeParserrépondre en chantantAutoMergingRetrieverRéalisation. - Des ressources informatiques suffisantes pour le traitement et le stockage de grandes collections de documents.
- Familiarité avec le langage de programmation Python pour la mise en œuvre et les tests.
exemple d'utilisation
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.node_parser import HierarchicalNodeParser
from llama_index.core.retrievers import AutoMergingRetriever
# 将文档解析为节点层级
node_parser = HierarchicalNodeParser.from_defaults()
nodes = node_parser.get_nodes_from_documents(docs)
# 设置存储上下文
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
# 创建基础索引和检索器
leaf_nodes = get_leaf_nodes(nodes)
base_index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
base_retriever = base_index.as_retriever(similarity_top_k=6)
# 创建自动合并检索器
retriever = AutoMergingRetriever(base_retriever, storage_context, verbose=True)
# 在查询引擎中使用自动合并检索器
query_engine = RetrieverQueryEngine.from_args(retriever)
response = query_engine.query(query_str)© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...