
AI Engineering Academy : 2.1 Mise en œuvre de RAG à partir de zéro
esquissée
Ce guide vous guidera dans la création d'une simple génération d'amélioration de la recherche en utilisant purement Python (RAG). Nous utiliserons un modèle d'intégration et un grand modèle linguistique (LLM) pour récupérer les documents pertinents et générer des réponses basées sur les requêtes de l'utilisateur.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/00_RAG_from_Scratch
Étapes de la procédure
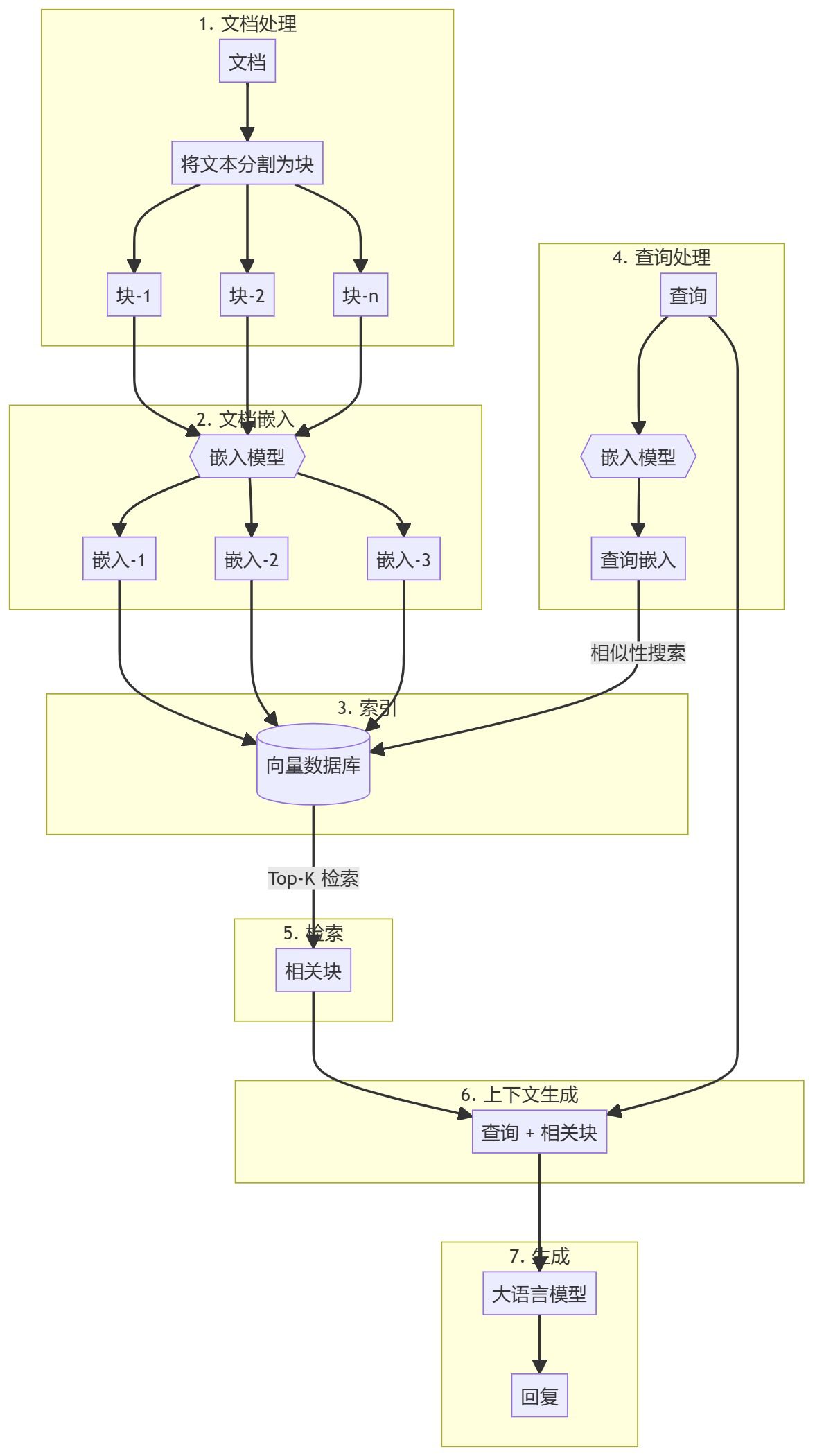
L'ensemble du processus peut être divisé en deux étapes principales :
- Création d'une base de connaissances
- partie générée
Création d'une base de connaissances
Tout d'abord, vous devez préparer une base de connaissances (documents, PDF, pages wiki). Il s'agit des données de base pour le modèle linguistique (LLM). Le processus spécifique comprend
- morceauLes documents de l'UE sont des documents qui peuvent être utilisés dans le cadre d'un programme d'éducation et de formation professionnelle.
- intégrationLes résultats de l'analyse de l'information sont présentés dans le tableau suivant : Calculer l'intégration numérique pour chaque bloc de sous-documents afin de comprendre la similarité sémantique de l'interrogation.
- stockStocker ces encastrements d'une manière qui permette de les retrouver rapidement. Bien qu'il soit courant d'utiliser des bases de données vectorielles, ce tutoriel montre que cela n'est pas nécessaire.
partie générée
Lorsqu'une requête est introduite par l'utilisateur, une intégration est calculée pour la requête et les blocs de sous-documents les plus pertinents sont extraits de la base de connaissances. Ces blocs pertinents sont ajoutés à la requête de l'utilisateur pour former un contexte et sont introduits dans le LLM pour générer une réponse.
1) Paramètres environnementaux
Quelques paquets doivent être installés avant de pouvoir commencer.
sentence-transformers: Utilisé pour générer des embeddings pour les documents et les requêtes.numpy: pour les comparaisons de similarité.scipyLe système d'information de la Commission européenne est le suivant : il permet d'effectuer des calculs de similarité avancés.wikipedia-api: Utilisé pour charger des pages Wikipédia en tant que bases de connaissances.textwrap: Utilisé pour formater le texte de sortie.
!pip install -q sentence-transformers
!pip install -q wikipedia-api
!pip install -q numpy
!pip install -q scipy
2. chargement du modèle d'intégration
Chargeons un modèle intégré. Ce tutoriel utilise le modèle gte-base-en-v1.5.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-base-en-v1.5", trust_remote_code=True)
A propos du modèle
gte-base-en-v1.5 Model est un modèle de langue anglaise open source fourni par l'équipe NLP d'Alibaba. Il fait partie de la famille GTE (Generic Text Embedding), conçue pour générer des embeddings de haute qualité pour une variété de tâches de traitement du langage naturel. Le modèle est optimisé pour capturer le sens sémantique du texte anglais et peut être utilisé pour des tâches telles que la similarité des phrases, la recherche sémantique et le regroupement.trust_remote_code=True Les paramètres permettent d'utiliser du code personnalisé associé au modèle pour s'assurer qu'il fonctionne comme prévu.
3. obtenir le contenu textuel de Wikipédia et le préparer
- Un article de Wikipédia est d'abord chargé comme une base de connaissances. Le texte est divisé en morceaux gérables (sous-documents), généralement en paragraphes.
from wikipediaapi import Wikipedia wiki = Wikipedia('RAGBot/0.0', 'en') doc = wiki.page('Hayao_Miyazaki').text paragraphs = doc.split('\n\n') # 分块 - Bien qu'il existe de nombreuses stratégies de découpage, beaucoup d'entre elles peuvent ne pas être applicables. Il est préférable de consulter votre base de connaissances pour déterminer la stratégie la plus appropriée. Dans cet exemple, nous procédons à un découpage par paragraphe.
- Si vous souhaitez voir à quoi ressemblent ces blocs, vous pouvez importer le fichier
textwrapet l'imprimer paragraphe par paragraphe.import textwrap for i, p in enumerate(paragraphs): wrapped_text = textwrap.fill(p, width=100) print("-----------------------------------------------------------------") print(wrapped_text) print("-----------------------------------------------------------------") - Si le document contient des images et des tableaux, il est recommandé de les extraire séparément et de les intégrer à l'aide d'un modèle visuel.
4. intégration de documents
- Ensuite, le modèle est créé en appelant la fonction
encodequi prend des données textuelles (par ex.paragraphs) codé comme intégré.docs_embed = model.encode(paragraphs, normalize_embeddings=True) - Ces encastrements sont des représentations vectorielles denses du texte, qui capturent le sens sémantique et permettent au modèle de comprendre et de traiter le texte sous une forme mathématique.
- Nous normalisons ici l'intégration.
- Qu'est-ce que la normalisation ? La normalisation est un processus d'ajustement des valeurs d'intégration pour obtenir un paradigme unitaire (c'est-à-dire une longueur de vecteur de 1).
- Pourquoi normaliser ? L'intégration normalisée garantit que les distances entre les vecteurs reflètent principalement les différences de direction plutôt que de taille. Cela améliore les performances du modèle dans les tâches de recherche de similarité où la "proximité" ou la "similarité" entre les textes est comparée.
- en fin de compte
docs_embedest une collection de représentations vectorielles de données textuelles, où chaque vecteur correspond àparagraphsUn paragraphe dans la liste. - utiliser
shapepour connaître le nombre de blocs et la dimension de chaque vecteur d'intégration (la taille du vecteur d'intégration dépend du type de modèle d'intégration).docs_embed.shape - Vous pouvez également voir à quoi ressemble l'intégration réelle, qui est un ensemble de valeurs normalisées.
docs_embed[0]
5. l'intégration des requêtes
Incorporer l'exemple de requête de l'utilisateur de la même manière que le document incorporé.
query = "What was Studio Ghibli's first film?"
query_embed = model.encode(query, normalize_embeddings=True)
Vous pouvez vérifier query_embed pour confirmer la dimension de la requête intégrée.
query_embed.shape
6. trouver le paragraphe le plus proche de la requête
L'un des moyens les plus simples de récupérer les morceaux de contenu les plus pertinents consiste à calculer le produit de points entre l'intégration des documents et l'intégration des requêtes.
a. Calcul du produit de points
Le produit point est une opération mathématique qui multiplie et additionne les éléments correspondants de deux vecteurs (ou matrices). Il est souvent utilisé pour mesurer la similarité entre deux vecteurs.
(Il est à noter que le produit de points est calculé en prenant le query_embed (transposition du vecteur).
import numpy as np
similarities = np.dot(docs_embed, query_embed.T)
b. Comprendre les produits de points et leurs formes
Tableaux NumPy de .shape renvoie un tuple représentant les dimensions du tableau.
similarities.shape
La forme attendue dans ce code est la suivante :
- au cas où
docs_embeda la forme de (n_docs, n_dim) :- n_docs est le nombre de documents.
- n_dim est la dimension intégrée dans chaque document.
query_embed.Taura la forme (n_dim, 1), puisque nous comparons avec une seule requête.- produit ponctuel
similaritiesLa forme du tableau sera (n_docs,), ce qui indique qu'il s'agit d'un tableau (vecteur) à une dimension contenant n_docs éléments. Chaque élément représente le score de similarité entre la requête et un document particulier. - Pourquoi vérifier la forme ? Le fait de s'assurer que la forme est conforme aux attentes (n_docs,) confirme que le produit de points a été effectué correctement et que les scores de similarité pour chaque document ont été calculés correctement.
Vous pouvez imprimer similarities pour vérifier les scores de similarité, où chaque valeur correspond à un résultat de produit de points :
print(similarities)
c. Interprétation du produit de points
Le produit de points entre deux vecteurs (embeddings) mesure leur similarité : des valeurs plus élevées indiquent une plus grande similarité entre la requête et le document. Si les embeddings sont normalisés, ces valeurs sont directement proportionnelles à la similarité cosinus entre les vecteurs. Si elles ne sont pas normalisées, elles indiquent toujours la similarité, mais reflètent également la taille de l'intégration.
d. Identifier les 3 documents les plus similaires
Pour trouver les 3 documents les plus similaires sur la base de leur score de similarité, vous pouvez utiliser le code suivant :
top_3_idx = np.argsort(similarities, axis=0)[-3:][::-1].tolist()
- np.argsort(similarités, axis=0). Cette fonction associe le
similaritiesL'index du tableau est trié. Par exemple, sisimilarities = [0.1, 0.7, 0.4](math.) genrenp.argsortrenverra[0, 2, 1]Les indices des valeurs minimales et maximales sont respectivement 0 et 1. - [-3:]: Cette opération de découpage sélectionne les 3 index ayant les scores de similarité les plus élevés (les 3 derniers éléments après le tri).
- [::-1]: Cette opération inverse l'ordre, de sorte que l'index est trié par ordre décroissant de similarité.
- tolist(). Convertit un tableau indexé en une liste Python. Résultat :
top_3_idxUn index contenant les 3 documents les plus similaires, par ordre décroissant de similarité.
e. Extraction des documents les plus similaires
most_similar_documents = [paragraphs[idx] for idx in top_3_idx]
- Liste des produits dérivés : Cette ligne crée un fichier nommé
most_similar_documentsLa liste desparagraphsLa liste correspondant autop_3_idxLe paragraphe actuel de l'index. - paragraphes[idx]. en ce qui concerne
top_3_idxCette opération permet d'extraire le paragraphe correspondant à chaque index de la base de données.
f. Formater et afficher les documents les plus similaires
CONTEXT La variable est initialement initialisée à une chaîne vide et sera ensuite complétée par le texte de la nouvelle ligne du document le plus similaire dans une boucle d'énumération.
CONTEXT = ""
for i, p in enumerate(most_similar_documents):
wrapped_text = textwrap.fill(p, width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT += wrapped_text + "\n\n"
7. générer une réponse
Nous disposons à présent d'une requête et de blocs de contenu connexes qui seront transmis ensemble au grand modèle linguistique (LLM).
a. Déclaration de recherche
query = "What was Studio Ghibli's first film?"
b. Créer une invite
prompt = f"""
use the following CONTEXT to answer the QUESTION at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
CONTEXT: {CONTEXT}
QUESTION: {query}
"""
c. Mise en place de l'OpenAI
- Installez OpenAI pour accéder et utiliser le Grand Modèle de Langage (LLM).
!pip install -q openai - Autoriser l'accès aux clés de l'API OpenAI (peut être défini dans les secrets de Google Colab).
from google.colab import userdata userdata.get('openai') import openai - Créer un client OpenAI.
from openai import OpenAI client = OpenAI(api_key=userdata.get('openai'))
d. Appeler l'API pour générer une réponse
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt},
]
)
- client.chat.completions.create. Cette méthode fait appel à un vaste modèle linguistique basé sur le chat pour créer une nouvelle réponse (générer).
- client. Représente un objet client API qui se connecte à un service (dans ce cas, OpenAI).
- chat.completions.create. Précisez que vous demandez la création d'une génération basée sur le chat.
Pour plus d'informations sur les paramètres transmis aux méthodes
- modèle="gpt-4o". Spécifie le modèle utilisé pour générer la réponse. gpt-4o" est une variante spécifique du modèle GPT-4. Des modèles différents peuvent avoir des comportements, des méthodes de réglage fin ou des capacités différentes. Il est donc important de spécifier le modèle pour s'assurer que l'on obtient le résultat souhaité.
- des messages. Ce paramètre est une liste d'objets de message représentant l'historique du dialogue. Cela permet au modèle de comprendre le contexte de la discussion. Dans cet exemple, nous ne fournissons qu'un seul message dans la liste :
{"role": "user", "content": prompt}. - rôle. "utilisateur" désigne le rôle de l'expéditeur du message, c'est-à-dire l'utilisateur qui interagit avec le modèle.
- le contenu. Contient le texte du message envoyé par l'utilisateur. La variable prompt contient ce texte, que le modèle utilisera comme entrée pour générer la réponse.
e. En ce qui concerne les réponses reçues
Lorsque vous faites une demande à une API comme le modèle OpenAI GPT pour générer une réponse de chat, la réponse est généralement renvoyée dans un format structuré, habituellement un dictionnaire.
Cette structure comprend généralement
- choix. Une liste (tableau) contenant plusieurs réponses possibles générées par le modèle. Chaque élément de cette liste représente une réponse ou un achèvement possible.
- message. Un objet ou un dictionnaire dans chaque sélection qui contient le contenu réel du message généré par le modèle.
- le contenu. Le contenu textuel du message, c'est-à-dire la réponse ou l'achèvement généré par le modèle.
f. Réponses imprimées
print(response.choices[0].message.content)
Nous choisissons choices Le premier élément de la liste, puis l'accès à l'un des éléments de la liste. message objet. Enfin, nous accédons à l'objet message a fait mouche content qui contient le texte généré par le modèle.
rendre un verdict
Ceci complète notre explication de la construction de systèmes RAG à partir de zéro. Il est fortement recommandé de construire votre premier système RAG en Python pur pour mieux comprendre le fonctionnement de ces systèmes.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...