
Top 5 des plateformes d'inférence IA qui utilisent gratuitement une version complète de DeepSeek-R1

En raison d'un trafic excessif et d'une cyberattaque, le site web et l'application DeepSeek ont connu des hauts et des bas pendant quelques jours et l'API ne fonctionne pas.

Nous avons déjà partagé la méthode de déploiement local de DeepSeek-R1 (voirDéploiement local de DeepSeek-R1), mais l'utilisateur moyen est limité à une configuration matérielle qui rend difficile l'utilisation d'un modèle 70b, sans parler d'un modèle 671b complet.
Heureusement, toutes les plateformes majeures ont accès à DeepSeek-R1, vous pouvez donc l'essayer en remplacement.
I. Microservices NVIDIA NIM
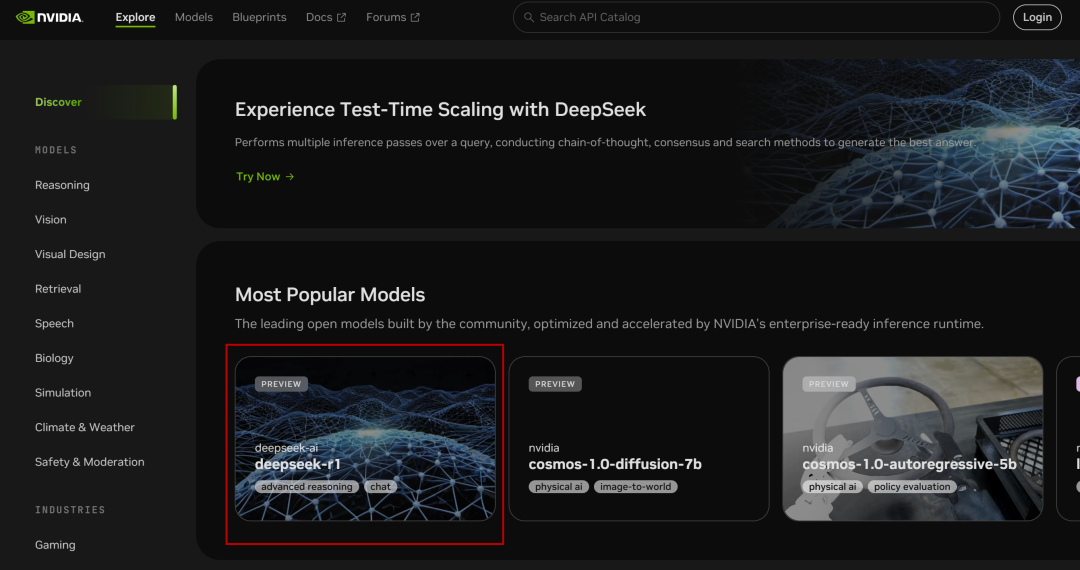
NVIDIA Build : intégrer plusieurs modèles d'IA et les expérimenter gratuitement
Site web : https://build.nvidia.com/deepseek-ai/deepseek-r1
NVIDIA a déployé le paramètre 671B du volume complet de la Profondeur de l'eau-R1 Modèles, la version web est simple à utiliser et vous pouvez voir la fenêtre de chat lorsque vous cliquez dessus :
La page de code figure également à droite :
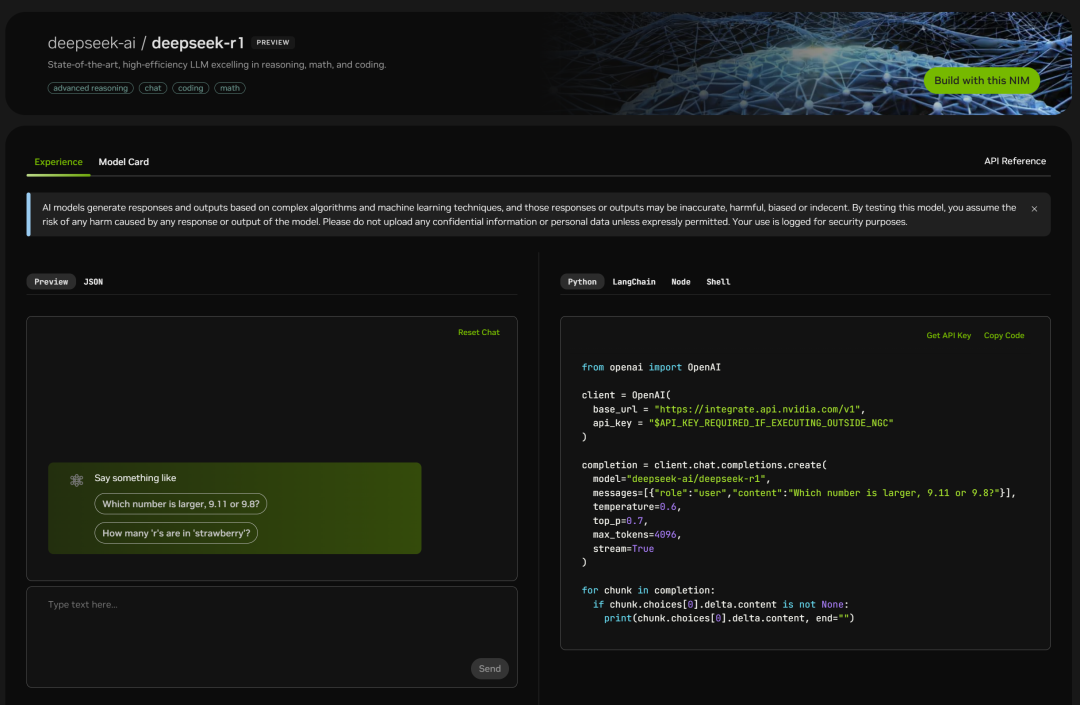
Il suffit de le tester :

Sous la boîte de dialogue, vous pouvez également activer certains paramètres (qui peuvent être définis par défaut dans la plupart des cas) :
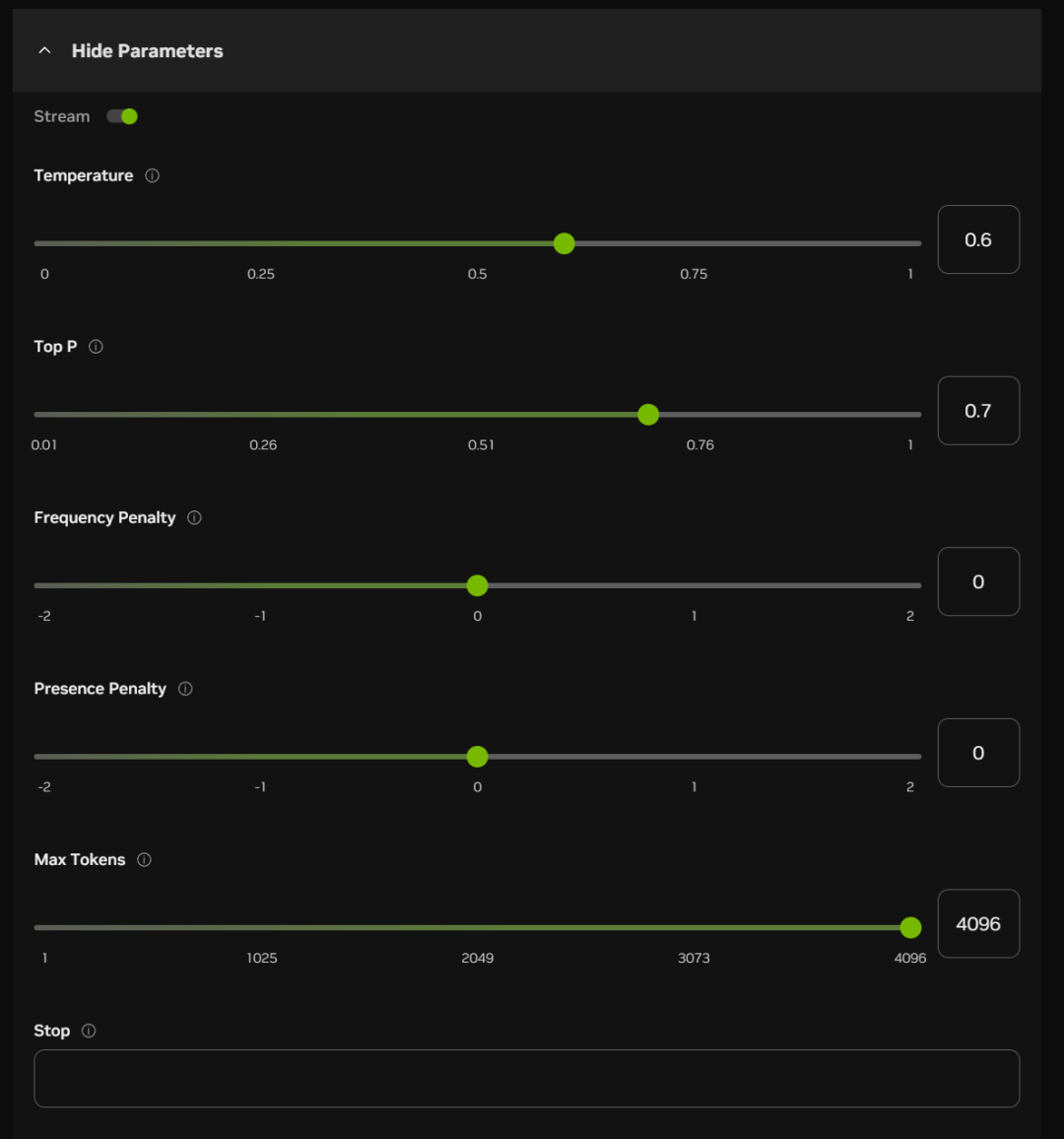
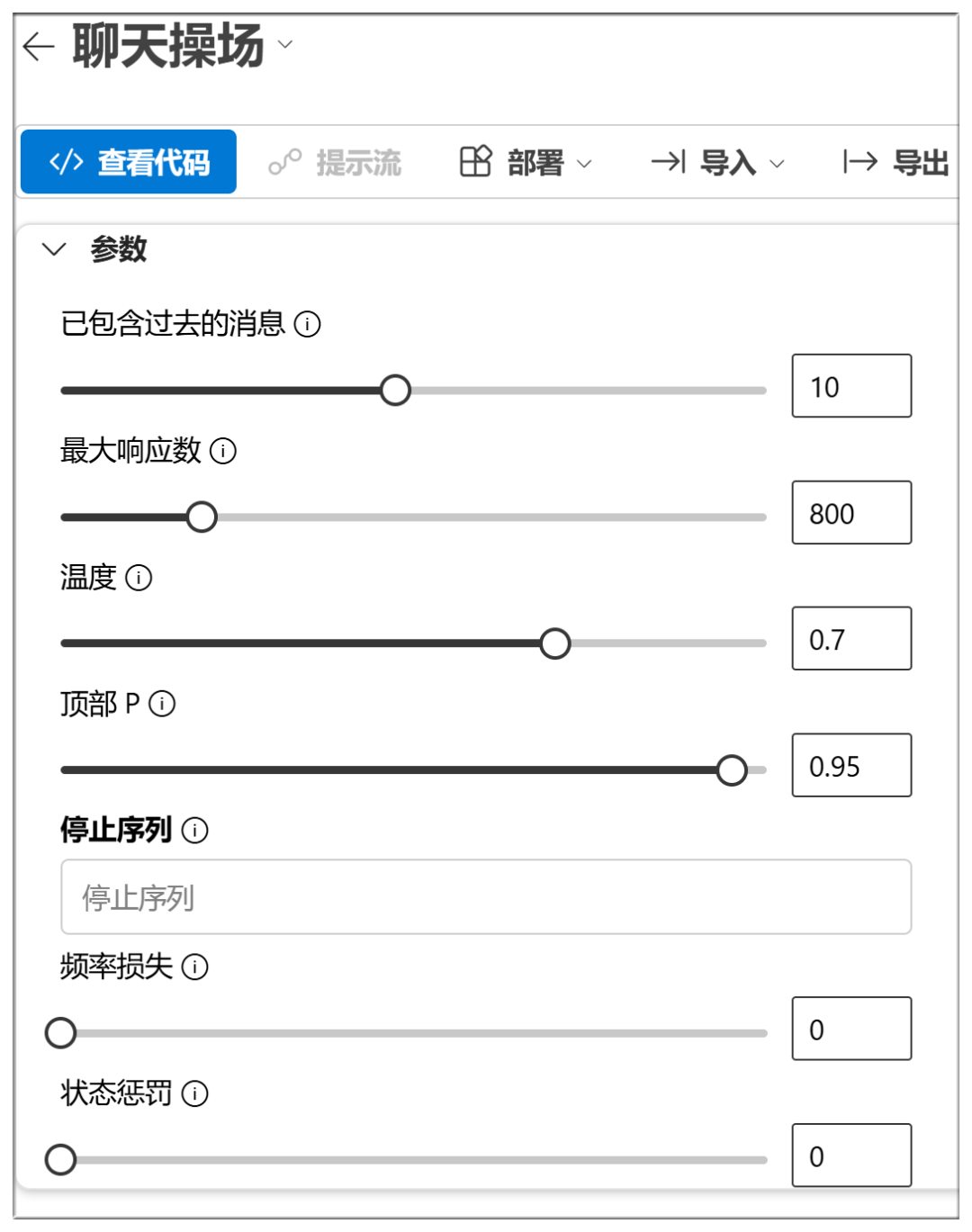
La signification approximative et les fonctions de ces options sont énumérées ci-dessous :
Température :
Plus la valeur est élevée, plus le résultat est aléatoire et plus il est possible de générer des réponses créatives.
Top P (échantillonnage nucléaire) :
Des valeurs plus élevées retiennent davantage de jetons de qualité probabiliste et génèrent une plus grande diversité.
Pénalité de fréquence :
Les valeurs élevées pénalisent davantage les mots de haute fréquence et réduisent la verbosité ou la répétition.
Pénalité de présence :
Plus la valeur est élevée, plus le modèle est enclin à essayer de nouveaux mots
Nombre maximal de jetons :
Plus la valeur est élevée, plus la longueur potentielle de la réponse est importante.
Arrêter :
Arrêter la sortie lors de la génération de certains caractères ou séquences, afin d'éviter une génération trop longue ou l'épuisement des sujets.
Actuellement, en raison du nombre croissant de clients blancs (voir le nombre de personnes dans la file d'attente dans le graphique ci-dessous), la marge nette d'autofinancement est parfois à la traîne :
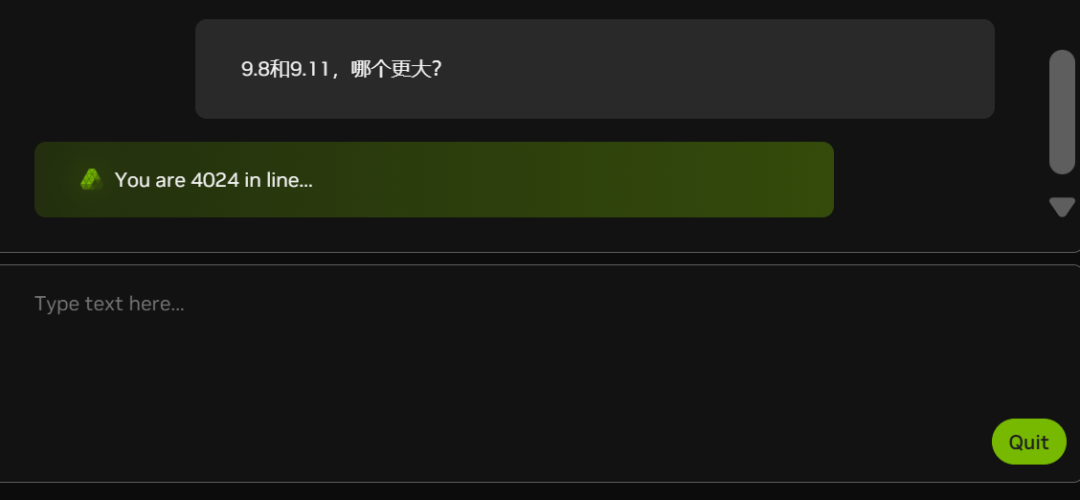
NVIDIA est-elle également à court de cartes graphiques ?
Les microservices NIM prennent également en charge les appels API vers DeepSeek-R1, mais vous devez vous inscrire pour obtenir un compte avec une adresse électronique :
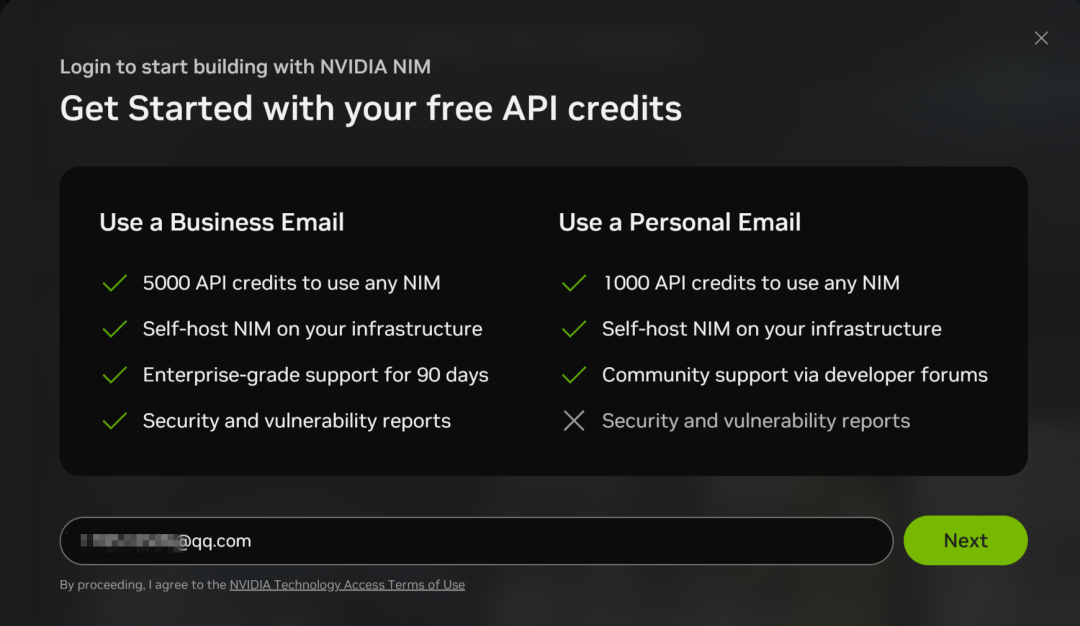
Le processus d'enregistrement est relativement simple, et ne nécessite qu'une vérification par courrier électronique :

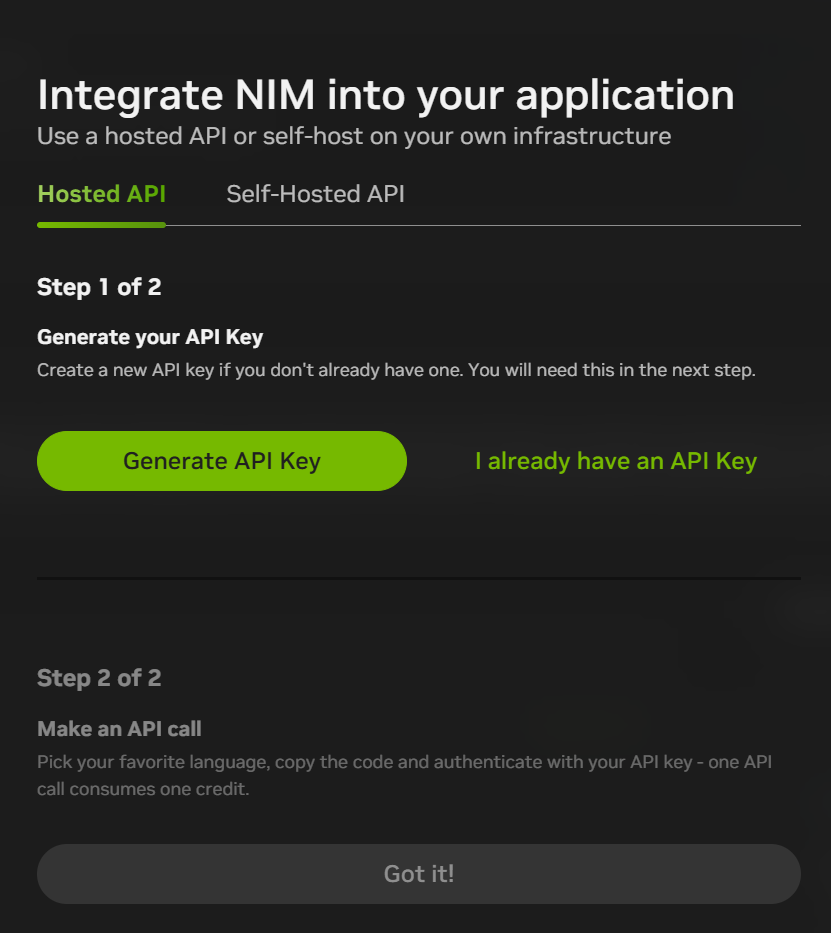
Après vous être inscrit, vous pouvez cliquer sur "Build with this NIM" en haut à droite de l'interface de chat pour générer une CLÉ API. Actuellement, vous obtenez 1 000 points (1 000 interactions) pour votre inscription, ce qui vous permet de les utiliser entièrement et de vous réinscrire avec une nouvelle adresse électronique.
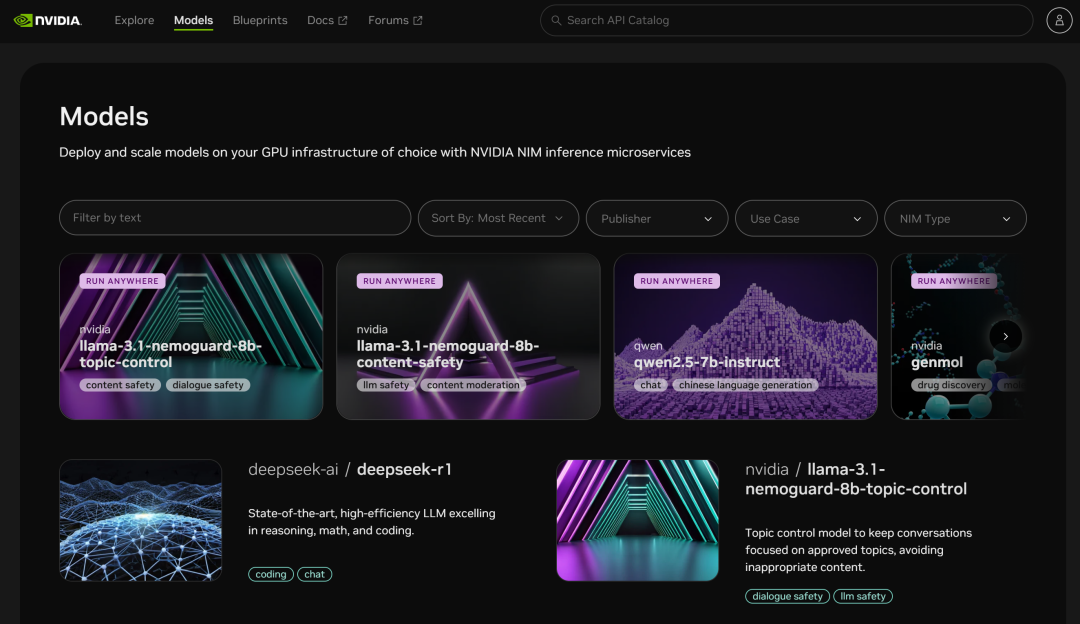
La plateforme de microservices NIM permet également d'accéder à de nombreux autres modèles :
II. Microsoft Azure
Site web :
https://ai.azure.com
Microsoft Azure vous permet de créer un chatbot et d'interagir avec le modèle par le biais d'une aire de jeu.
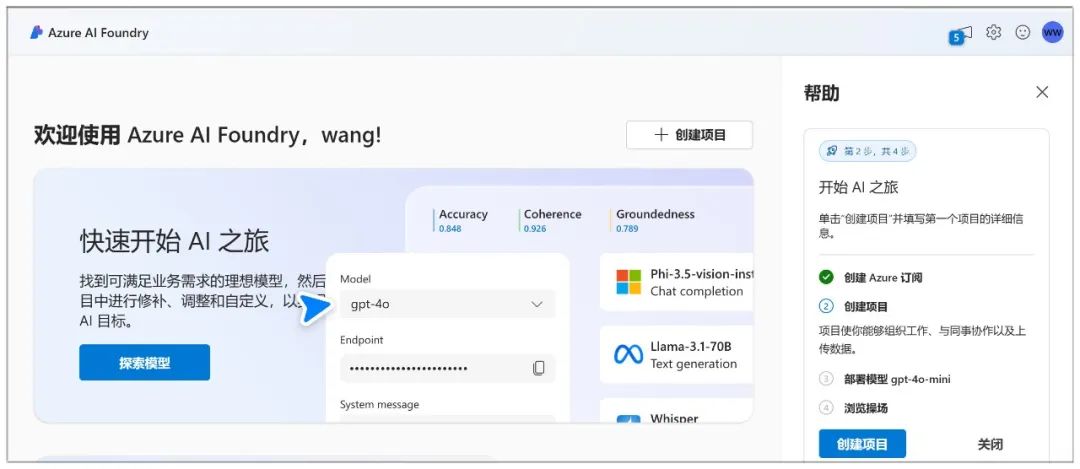
L'inscription à Azure est très compliquée. Vous devez d'abord créer un compte Microsoft (il vous suffit de vous connecter si vous en avez déjà un) :
La création d'un compte nécessite également la vérification de l'adresse électronique :
Terminez en prouvant que vous êtes humain en répondant à 10 questions consécutives sur le monde souterrain :

Il ne suffit pas d'arriver ici pour créer un abonnement :
Vérifiez le numéro de téléphone portable, le numéro de compte bancaire et d'autres informations :
Sélectionnez ensuite "Pas de support technique" :

Ici, vous pouvez commencer le déploiement dans le nuage, dans le "Catalogue de modèles" vous pouvez voir le modèle DeepSeek-R1 en évidence :
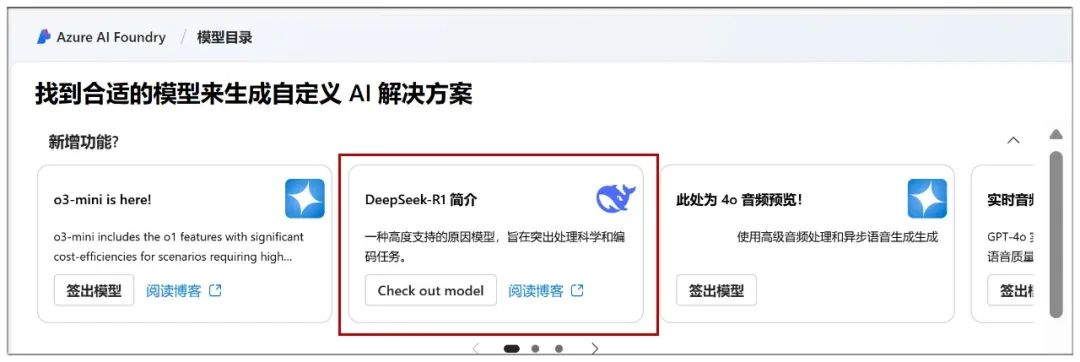
Une fois que vous avez cliqué, cliquez sur "Déployer" sur la page suivante :
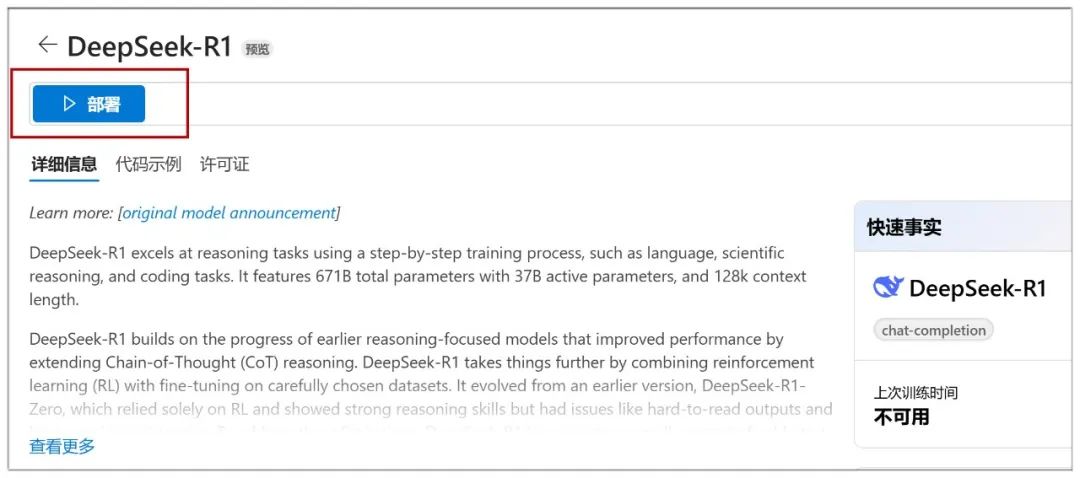
Ensuite, vous devez sélectionner "Créer un nouveau projet" :
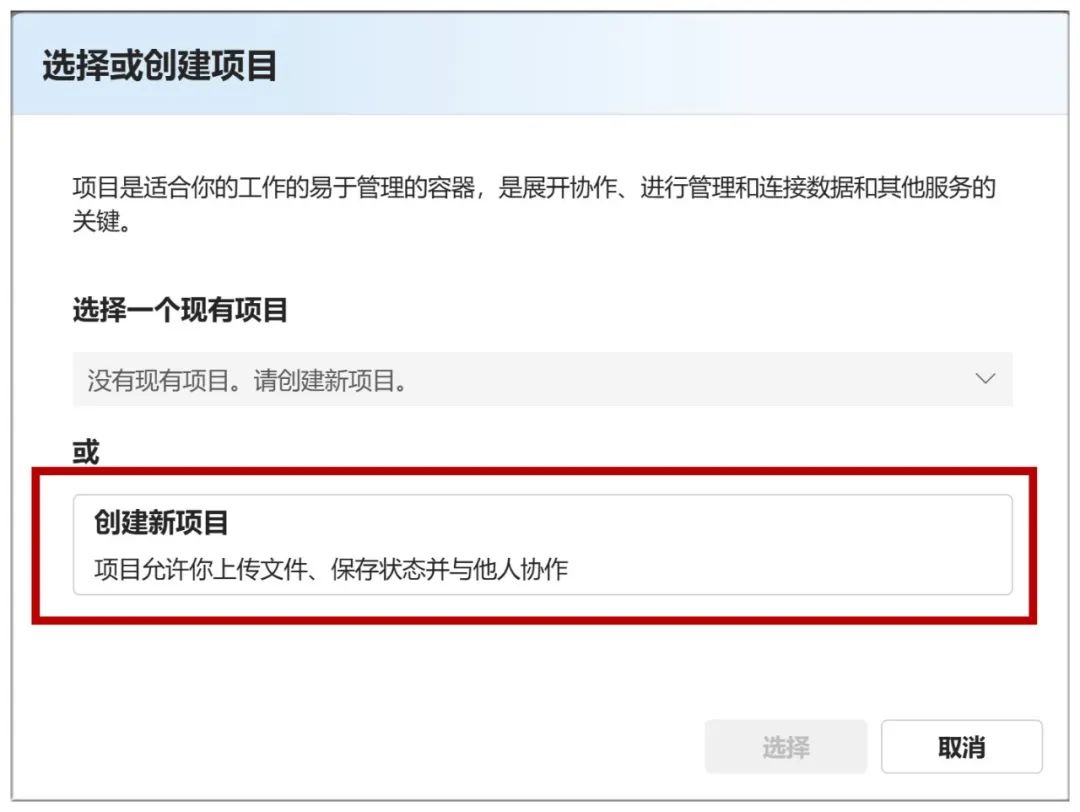
Ensuite, mettez-les tous par défaut et cliquez sur "Suivant" :
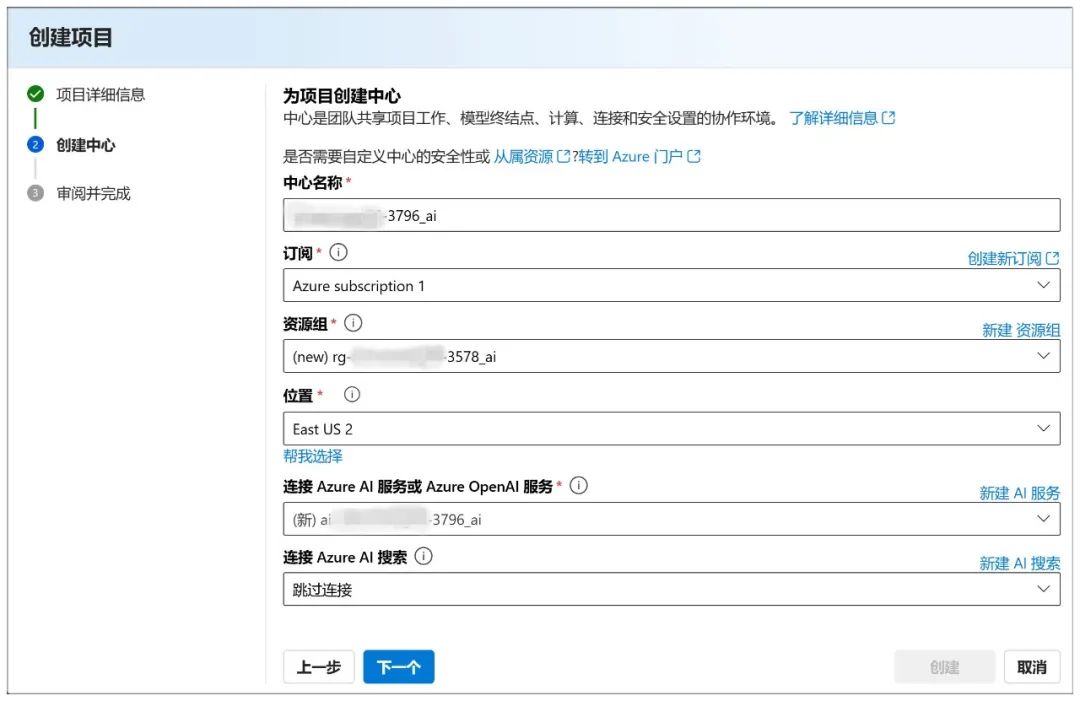
Cliquez ensuite sur "Créer" :
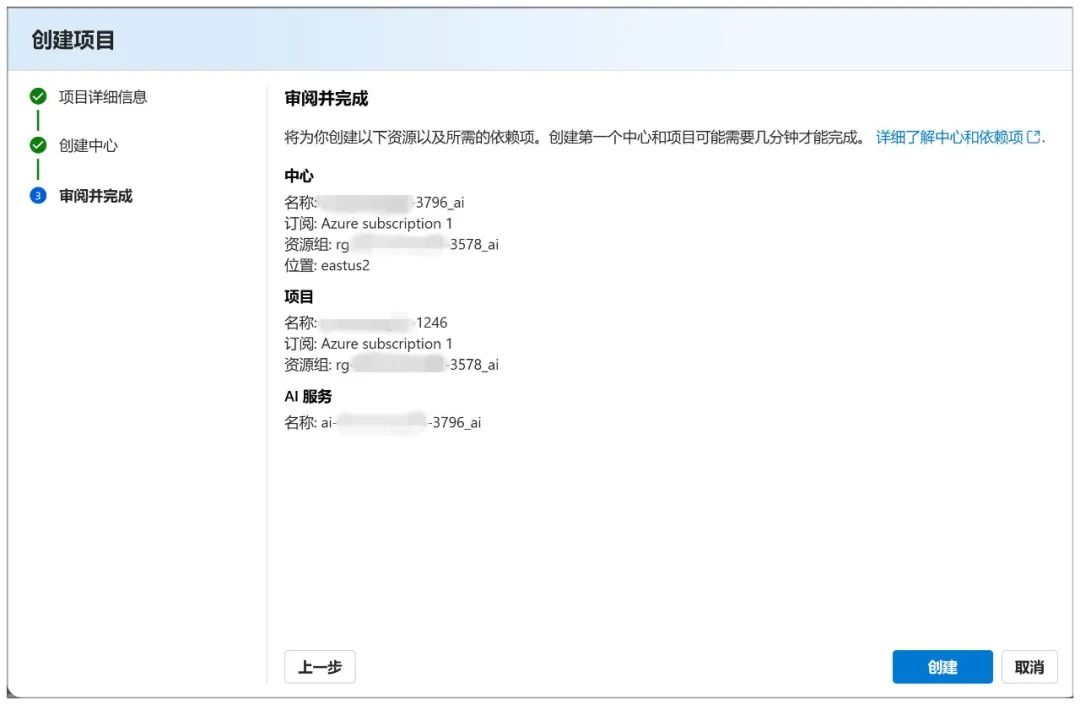
La création sous cette page démarre et prend un certain temps d'attente :
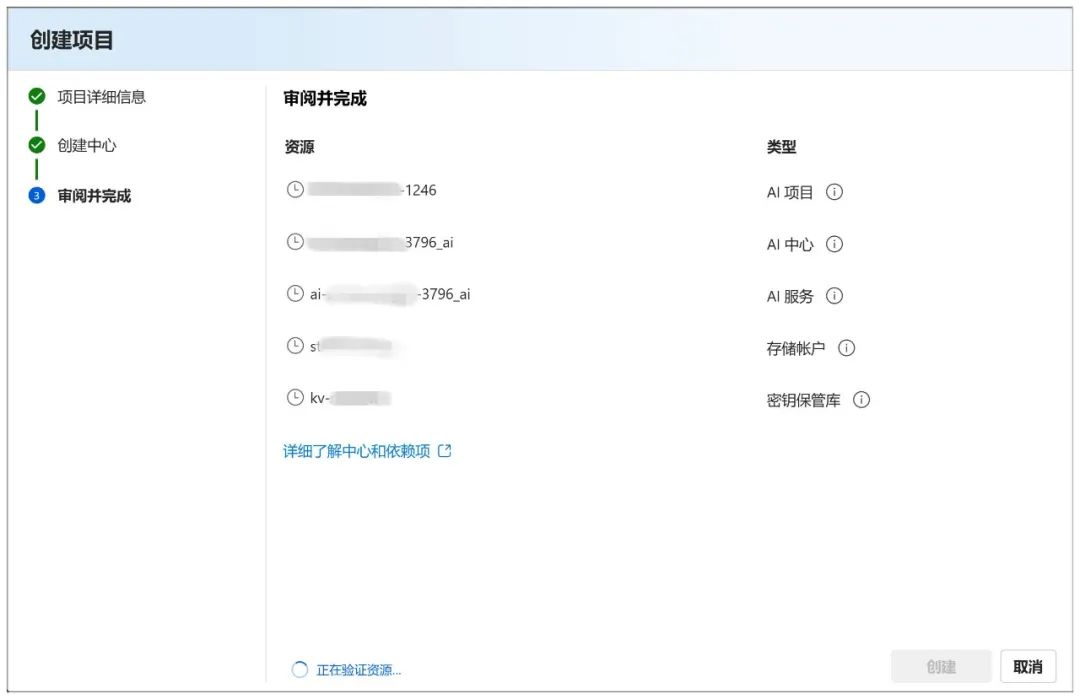
Lorsque vous avez terminé, vous arrivez sur cette page, où vous pouvez cliquer sur "Déployer" pour passer à l'étape suivante :
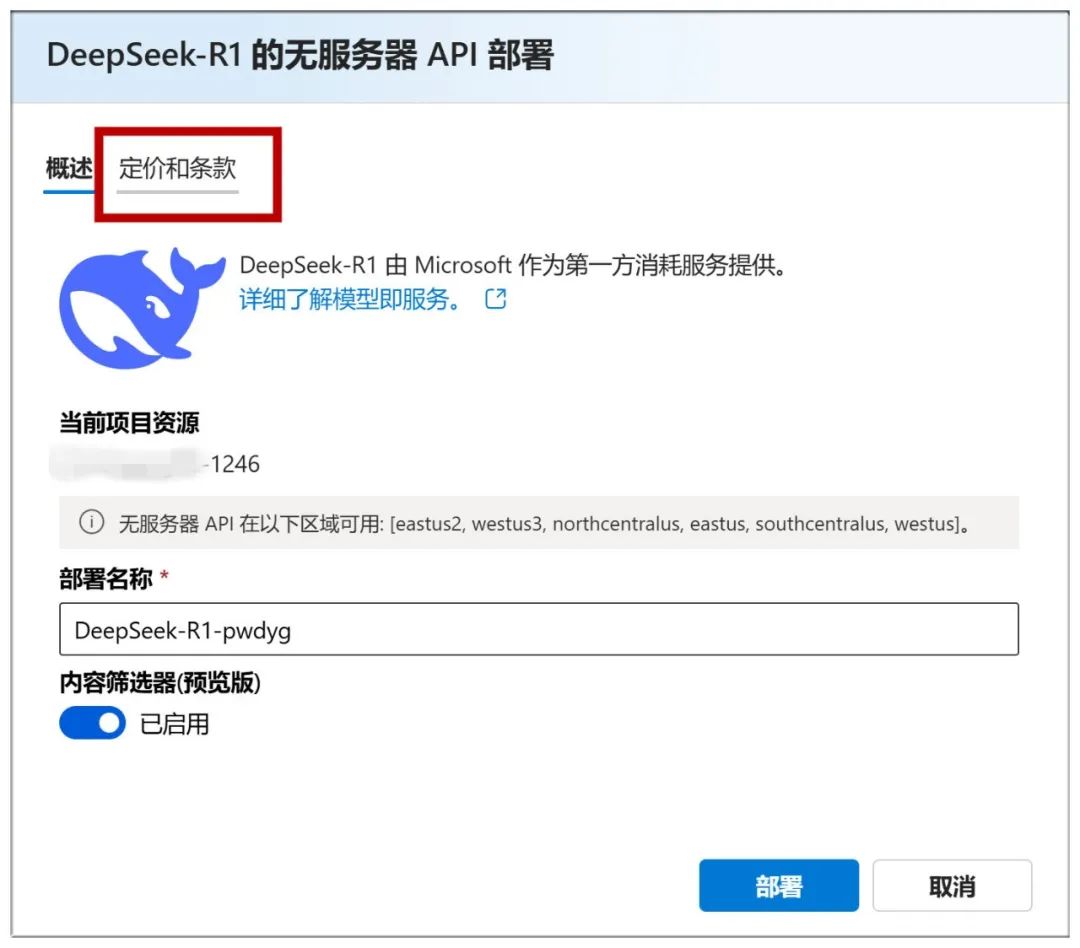
Vous pouvez également consulter la rubrique "Prix et conditions" ci-dessus pour constater que l'utilisation est gratuite :
Continuez sur cette page en cliquant sur "Deployment" et vous pouvez cliquer sur "Open in Playground" :
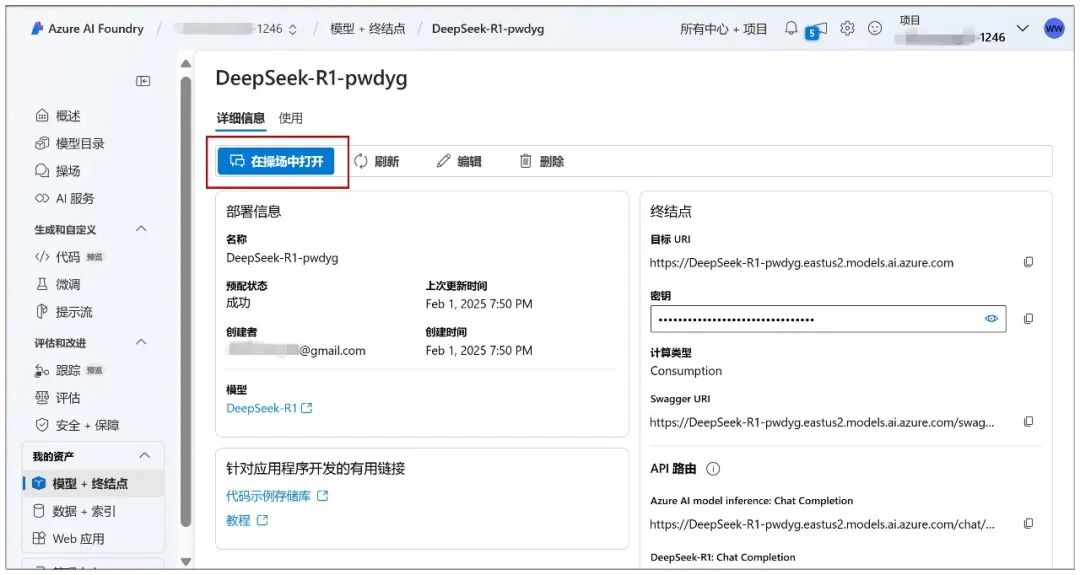
Le dialogue peut alors commencer :
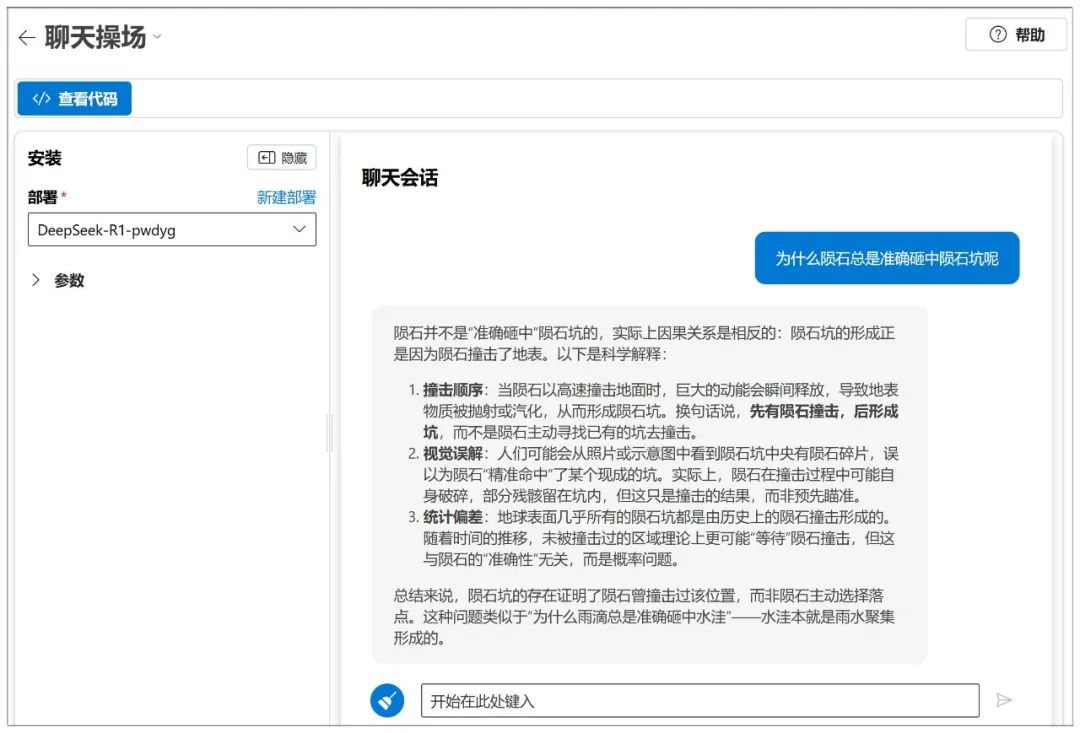
Azure dispose également d'un réglage des paramètres de type NIM :
En tant que plateforme, de nombreux modèles peuvent être déployés :
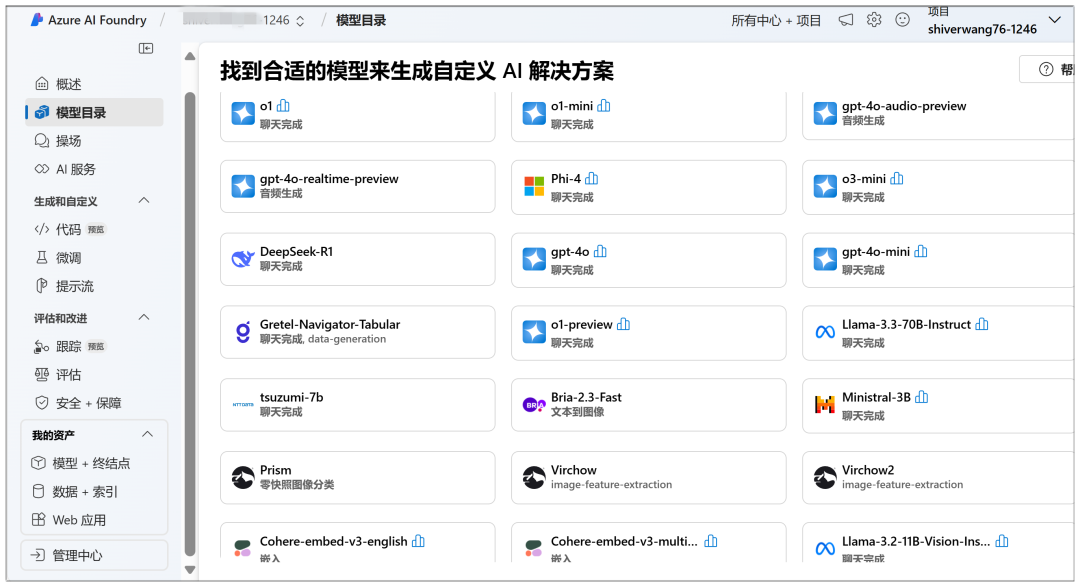
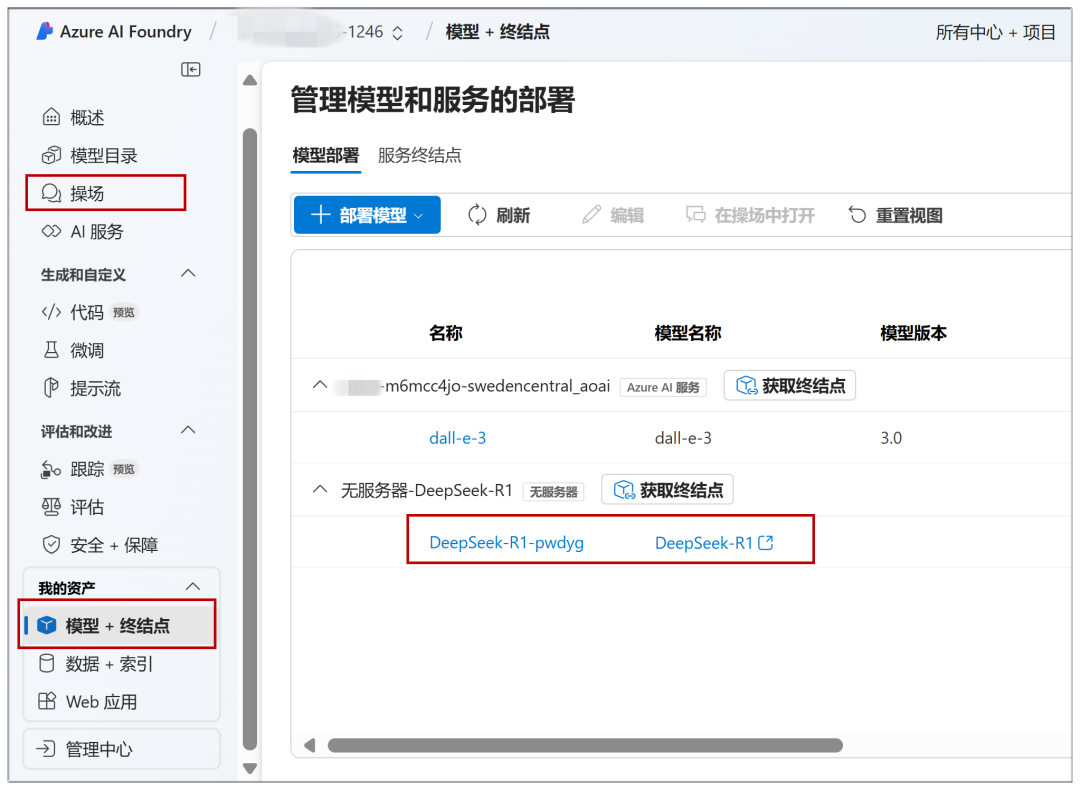
Les modèles déjà déployés peuvent être rapidement accessibles à l'avenir via "Playground" ou "Model + Endpoint" dans le menu de gauche :
III. Amazon AWS
Site web :
https://aws.amazon.com/cn/blogs/aws/deepseek-r1-models-now-available-on-aws
DeepSeek-R1 est également mis en évidence et aligné.

Le processus d'enregistrement d'Amazon AWS et de Microsoft Azure est presque aussi compliqué, les deux doivent remplir la méthode de paiement, mais aussi la vérification du téléphone et la vérification vocale, mais nous ne les décrirons pas en détail :
Le processus de déploiement est sensiblement le même que celui de Microsoft Azure :
IV. Cerebras
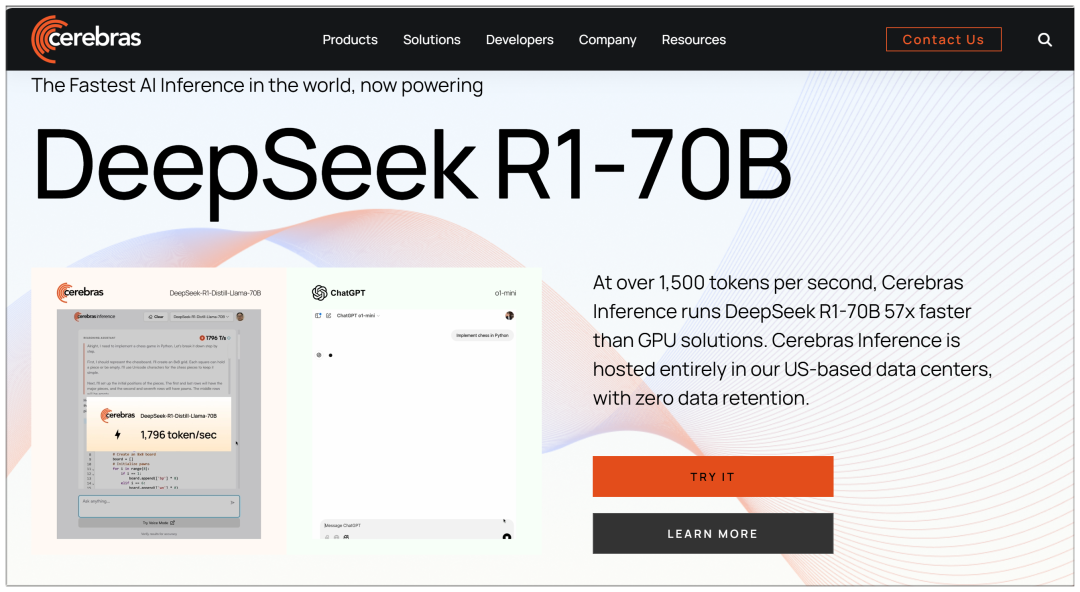
Cerebras : la plateforme de calcul à haute performance la plus rapide au monde pour l'inférence de l'IA, disponible dès aujourd'hui
Site web : https://cerebras.ai
Contrairement à plusieurs grandes plateformes, Cerebras utilise un modèle 70b, affirmant être "57 fois plus rapide que les solutions GPU" :
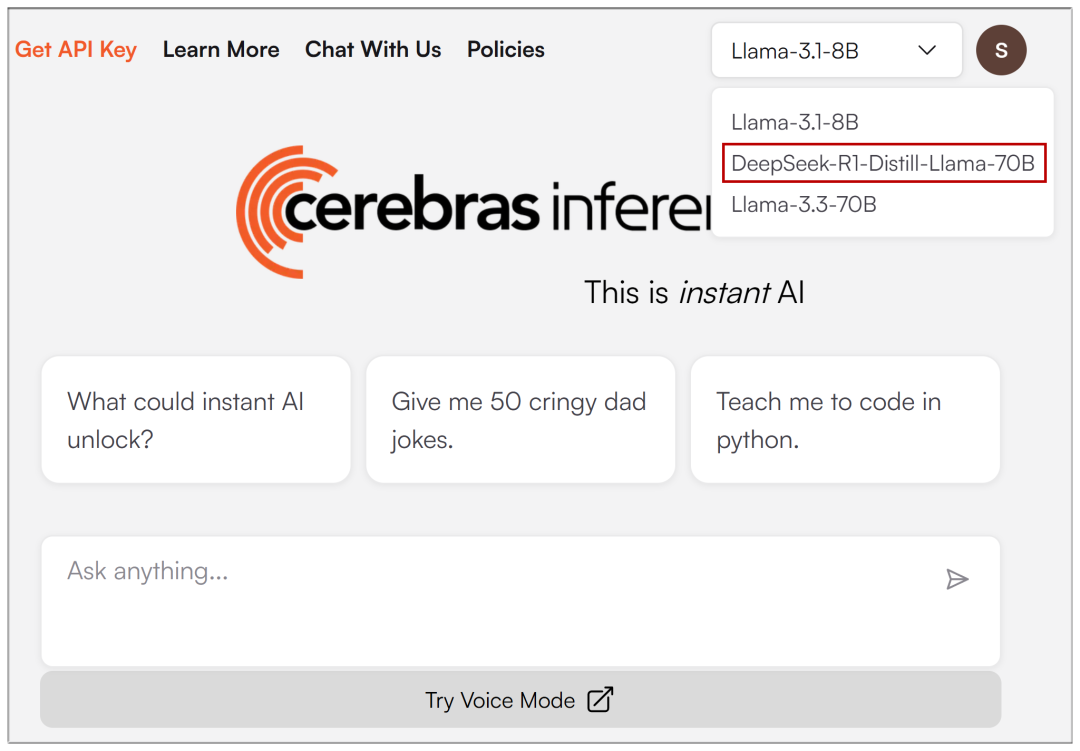
Une fois l'adresse électronique saisie, le menu déroulant en haut de la page vous permet de sélectionner DeepSeek-R1 :
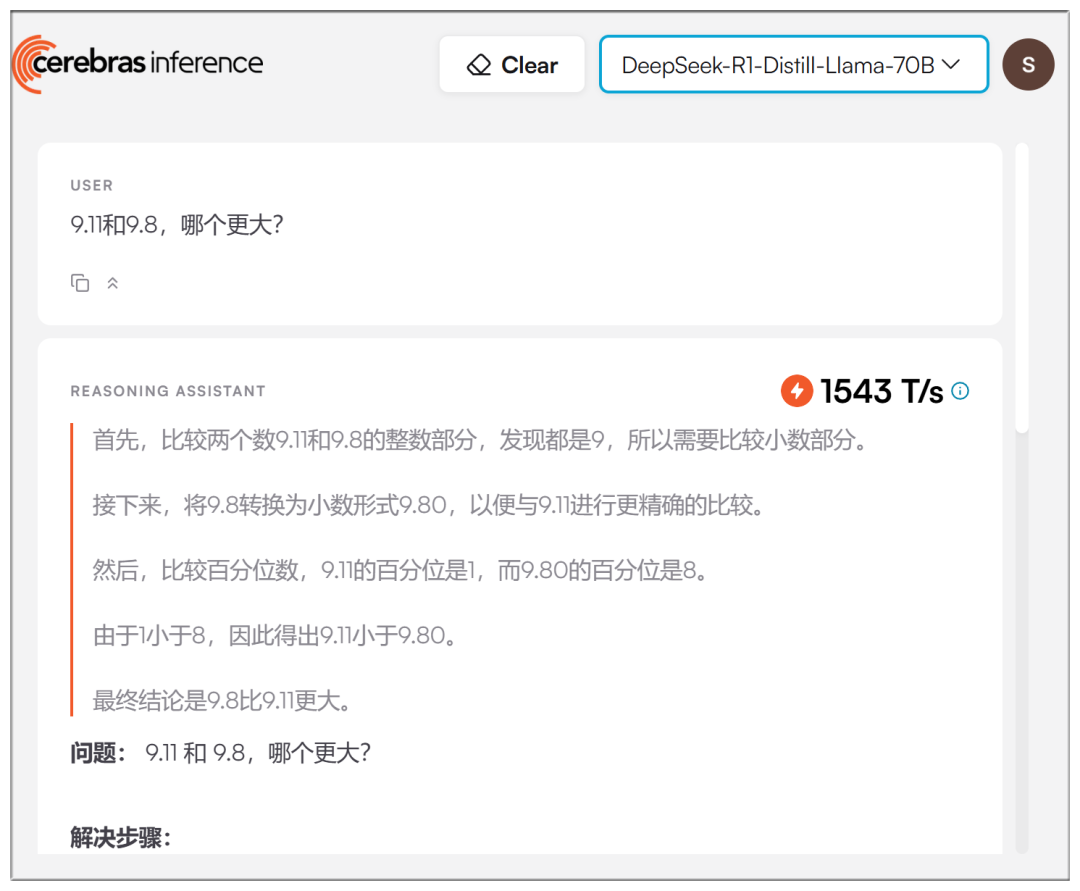
Les vitesses réelles sont effectivement plus élevées, mais pas aussi exagérées qu'on le prétend :
V. Groq
Groq : fournisseur de solutions d'accélération de l'inférence de grands modèles d'IA, interface de grands modèles gratuite et à grande vitesse
Site web : https://groq.com/groqcloud-makes-deepseek-r1-distill-llama-70b-available

Des modèles sont également disponibles pour la sélection une fois que l'e-mail est enregistré et saisi :

C'est rapide aussi, mais encore une fois, 70b semble un peu plus retardé que les Cerebras ?
Notez que l'interface de chat est accessible directement lorsque vous êtes connecté :
https://console.groq.com/playground?model=deepseek-r1-distill-llama-70b
Liste complète de DeepSeek V3 et R1 :
AMD
Les GPU AMD Instinct™ alimentent DeepSeek-V3 : révolutionner le développement de l'IA avec SGLang (Les GPU AMD Instinct™ alimentent DeepSeek-V3 : révolutionner le développement de l'IA avec SGLang)
NVIDIA
Carte modèle NVIDIA DeepSeek-R1 (Carte modèle NVIDIA DeepSeek-R1)
Microsoft Azure
Exécution de DeepSeek-R1 sur une seule VM NDv5 MI300X (Exécution de DeepSeek-R1 sur une seule VM NDv5 MI300X)
Baseten
https://www.baseten.co/library/deepseek-v3/
Novita AI
Novita AI utilise SGLang et DeepSeek-V3 pour OpenRouter (Novita AI utilise SGLang pour exécuter DeepSeek-V3 pour OpenRouter)
ByteDance Volcengine
La maquette grandeur nature de DeepSeek atterrit sur Volcano Engine !
DataCrunch
Déployer DeepSeek-R1 671B sur 8x NVIDIA H200 avec SGLang (Déploiement de DeepSeek-R1 671B sur 8x NVIDIA H200 en utilisant SGLang)
Hyperbolique
https://x.com/zjasper666/status/1872657228676895185
Vultr
Comment déployer Deepseek V3 Large Language Model (LLM) en utilisant SGLang (Comment déployer avec SGLang) Deepseek V3 Modélisation du langage étendu (LLM))
RunPod
Quoi de neuf pour l'utilisation de LLM sans serveur dans RunPod en 2025 ? (Quelles sont les nouvelles fonctionnalités utilisées par Serverless LLM dans RunPod en 2025 ?)
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...