HuggingFace renverse les détails techniques derrière o1 et le met en open-source !
Si l'on donne aux petits modèles plus de temps pour réfléchir, ils peuvent être plus performants que les grands modèles.
Ces derniers temps, l'industrie a fait preuve d'un enthousiasme sans précédent pour les petits modèles, avec quelques "astuces pratiques" leur permettant de surpasser les grands modèles en termes de performances.
On peut affirmer qu'il y a un corollaire à se concentrer sur l'amélioration des performances des modèles plus petits. Pour les modèles linguistiques de grande taille, la mise à l'échelle du calcul de la durée de formation a dominé leur développement. Bien que ce paradigme se soit avéré très efficace, les ressources nécessaires au pré-entraînement de modèles de plus en plus grands sont devenues prohibitives, et des grappes de plusieurs milliards de dollars ont vu le jour.
Par conséquent, cette tendance a suscité un grand intérêt pour une autre approche complémentaire, à savoir la mise à l'échelle des calculs en temps de test. Au lieu de s'appuyer sur des budgets de pré-entraînement toujours plus importants, les méthodes de test-temps utilisent des stratégies d'inférence dynamiques qui permettent aux modèles de "réfléchir plus longtemps" sur des problèmes plus difficiles. Le modèle o1 d'OpenAI en est un exemple frappant, qui a montré des progrès constants sur des problèmes mathématiques difficiles au fur et à mesure que la quantité de calcul en temps de test augmentait.
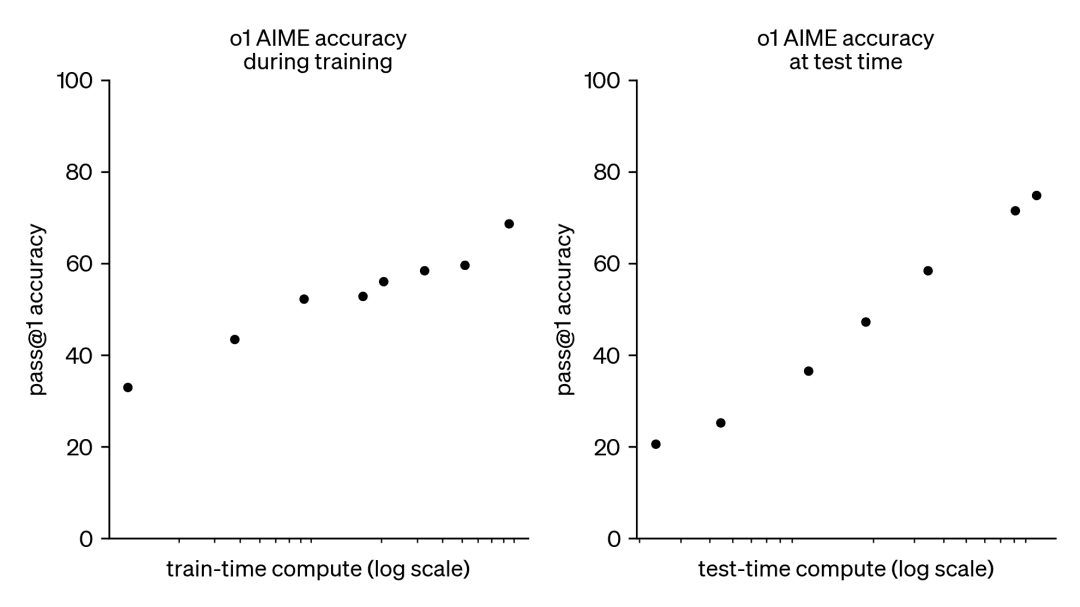
Bien que nous ne sachions pas exactement comment o1 est formé, des recherches récentes de DeepMind suggèrent qu'une mise à l'échelle optimale du calcul du temps de test peut être obtenue grâce à des stratégies telles que l'auto-amélioration itérative ou la recherche dans l'espace de solution à l'aide d'un modèle de récompense. En allouant de manière adaptative le calcul du temps de test, invite par invite, les modèles plus petits peuvent égaler et parfois même surpasser les modèles plus grands et gourmands en ressources. L'échelonnement du temps de calcul est particulièrement bénéfique lorsque la mémoire est limitée et que le matériel disponible est insuffisant pour faire fonctionner des modèles plus importants. Toutefois, cette approche prometteuse a été démontrée à l'aide d'un modèle à source fermée et aucun détail de mise en œuvre ou de code n'a été publié.
Document de DeepMind : https://arxiv.org/pdf/2408.03314
Au cours des derniers mois, HuggingFace s'est efforcé d'essayer d'inverser et de reproduire ces résultats. Ils vont les présenter dans ce billet de blog :
- Mise à l'échelle optimale du calcul (mise à l'échelle optimale du calcul) :Améliorer la puissance mathématique des modèles ouverts au moment des tests en mettant en œuvre les astuces de DeepMind.
- Recherche d'arbres de validation de la diversité (DVTS) :Il s'agit d'une extension développée pour la technique de recherche arborescente bootstrap du validateur. Cette approche simple et efficace permet d'accroître la diversité et d'améliorer les performances, en particulier lorsque les tests sont effectués avec un budget de calcul important.
- Cherchez et apprenez :Une boîte à outils légère pour la mise en œuvre de stratégies de recherche à l'aide de LLM avec l'outil de gestion de l'information. vLLM Obtenir des augmentations de vitesse.
Dans quelle mesure la mise à l'échelle optimale sur le plan informatique fonctionne-t-elle en pratique ? Dans le graphique ci-dessous, les très petits modèles 1B et 3B de l'Instructrice Lama surpassent les modèles beaucoup plus grands 8B, 70B sur le difficile benchmark MATH-500, si vous leur donnez suffisamment de "temps de réflexion".
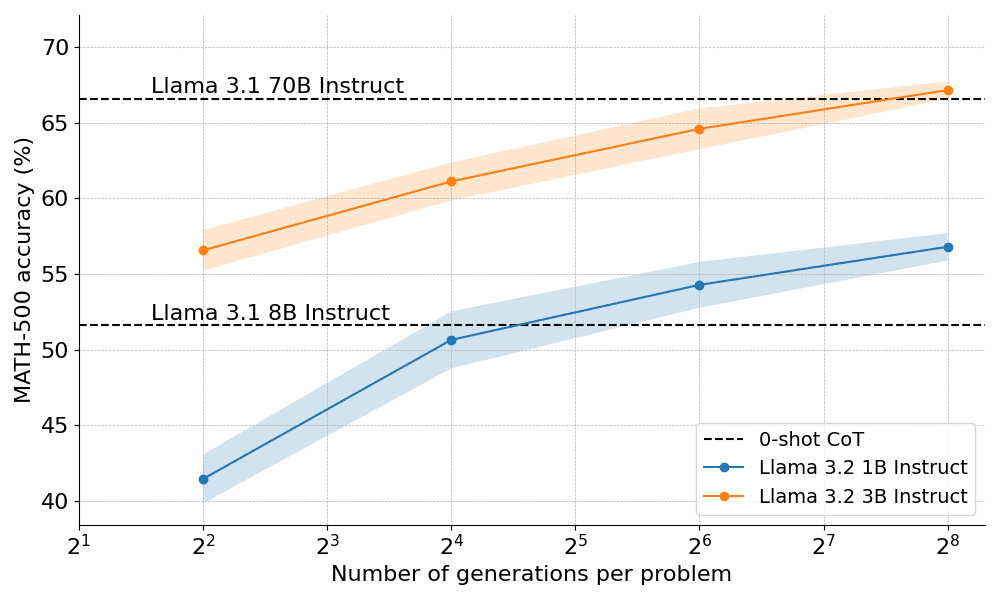
Dix jours seulement après la présentation publique d'OpenAI o1, nous sommes ravis de dévoiler une version open source de la technologie révolutionnaire à l'origine de son succès : Extended Test-Time Computing", a déclaré Clem Delangue, cofondateur et PDG de HuggingFace. En allongeant le "temps de réflexion" du modèle, le modèle 1B peut battre 8B, et le modèle 3B peut battre 70B.
Les net-citoyens de tous horizons ne sont pas tranquilles lorsqu'ils voient ces résultats, qu'ils qualifient d'incroyables et qu'ils considèrent comme une victoire pour les figurines.

Ensuite, HuggingFace se penche sur les raisons de ces résultats et aide les lecteurs à comprendre les stratégies pratiques de mise en œuvre de l'échelonnement des calculs lors des tests.
Stratégie étendue de calcul du temps d'essai
Il existe deux stratégies principales pour étendre le calcul du temps de test :
- Auto-amélioration : le modèle améliore itérativement son résultat ou son "idée" en identifiant et en corrigeant les erreurs dans les itérations suivantes. Bien que cette stratégie soit efficace pour certaines tâches, elle exige généralement que le modèle dispose d'un mécanisme d'auto-amélioration intégré, ce qui peut limiter son applicabilité.
- Recherche par rapport à un validateur : cette approche consiste à générer plusieurs réponses candidates et à utiliser un validateur pour sélectionner la meilleure réponse. Les validateurs peuvent être basés sur des heuristiques codées en dur ou sur des modèles de récompense appris. Dans le présent document, nous nous concentrerons sur les validateurs appris, qui comprennent des techniques telles que l'échantillonnage Best-of-N et la recherche arborescente. Ces stratégies de recherche sont plus flexibles et peuvent s'adapter à la difficulté du problème, bien que leurs performances soient limitées par la qualité du validateur.
HuggingFace est spécialisé dans les méthodes de recherche qui constituent des solutions pratiques et évolutives pour l'optimisation des calculs au moment des tests. Voici trois stratégies :
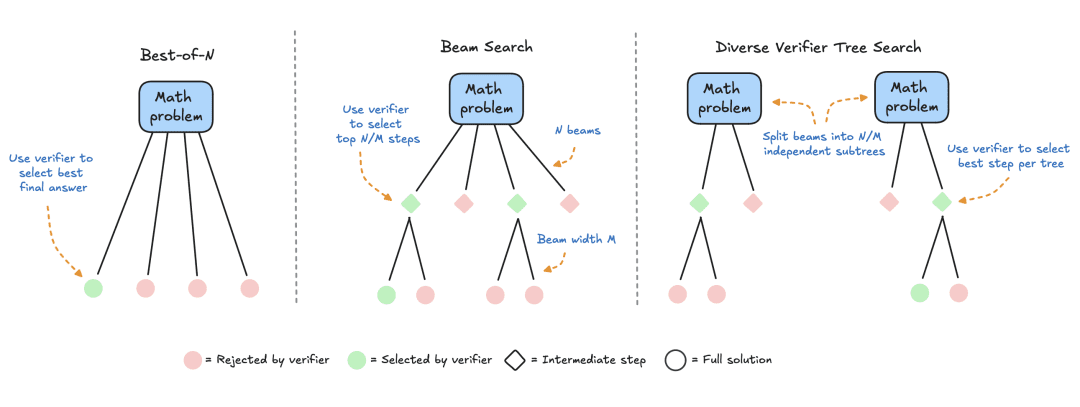
- Meilleure réponse : cette approche utilise généralement un modèle de récompense pour générer plusieurs réponses pour chaque question et attribue une note à chaque réponse candidate, puis sélectionne la réponse avec la récompense la plus élevée (ou une variante pondérée, comme nous le verrons plus loin). Cette approche met l'accent sur la qualité des réponses plutôt que sur leur fréquence.
- Recherche par grappes : méthode de recherche systématique pour explorer l'espace de solution, souvent utilisée en conjonction avec des modèles de récompense de processus (PRM) pour optimiser l'échantillonnage et l'évaluation des étapes intermédiaires dans la résolution de problèmes. Contrairement aux modèles de récompense traditionnels qui produisent une note unique pour la réponse finale, les MPR fournissent une série de notes, une pour chaque étape du processus de raisonnement. Cette capacité de rétroaction fine fait des MPR un choix naturel pour les méthodes de recherche LLM.
- Diversity Validator Tree Search (DVTS) : une extension de la recherche de grappes développée par HuggingFace qui divise la grappe initiale en sous-arbres distincts et étend ensuite ces sous-arbres avec avidité en utilisant le PRM. Cette approche améliore la diversité et les performances globales de la solution, en particulier si le budget de calcul est important au moment du test.
Dispositif expérimental
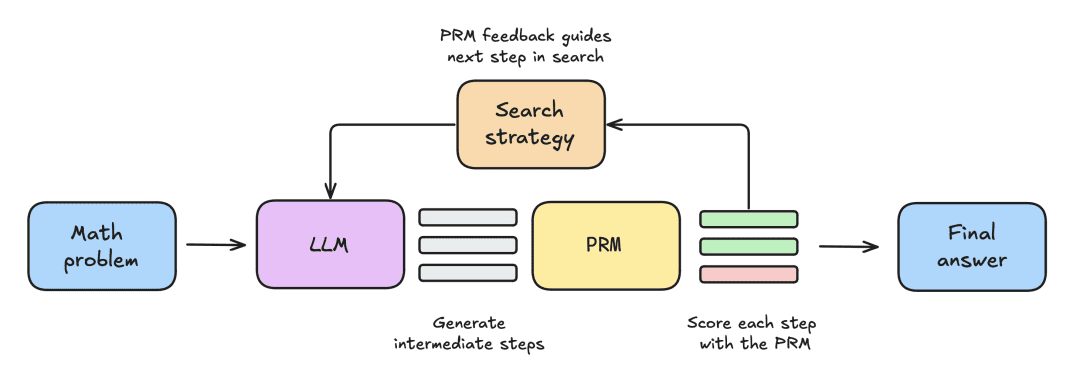
Le dispositif expérimental comprenait les étapes suivantes :
- Le LLM reçoit d'abord un problème mathématique pour générer N solutions partielles, c'est-à-dire des étapes intermédiaires dans le processus de dérivation.
- Chaque étape est évaluée par un MPR, qui estime la probabilité que chaque étape aboutisse à la bonne réponse.
- Une fois la stratégie de recherche terminée, les solutions candidates finales sont triées par le MRP pour produire la réponse finale.
Pour comparer les différentes stratégies de recherche, les modèles et ensembles de données open source suivants sont utilisés dans ce document :
- Modèles : utiliser meta-llama/Llama-3.2-1B-Instruct comme modèle principal pour les calculs de durée d'essai prolongée ;
- Modèle de récompense de processus PRM : pour guider la stratégie de recherche, cet article utilise RLHFlow/Llama3.1-8B-PRM-Deepseek-Data, un modèle de récompense de 8 milliards formé avec une supervision de processus. La supervision du processus est une méthode de formation dans laquelle le modèle reçoit un retour d'information à chaque étape du processus de raisonnement, et pas seulement au niveau du résultat final ;
- Ensemble de données : cet article a été évalué sur le sous-ensemble MATH-500, un ensemble de données de référence MATH publié par l'OpenAI dans le cadre d'une étude supervisée par le processus. Ces problèmes mathématiques couvrent sept sujets et représentent un défi à la fois pour les humains et pour la plupart des modèles de grands langages.
Cet article commence par une simple base de référence, puis incorpore progressivement d'autres techniques pour améliorer les performances.
vote à la majorité
Le vote majoritaire est le moyen le plus simple d'agréger les résultats du LLM. Pour un problème mathématique donné, N solutions candidates sont générées et la réponse ayant la plus grande fréquence d'apparition est sélectionnée. Dans toutes les expériences, cet article échantillonne jusqu'à N=256 solutions candidates, avec un paramètre de température T=0,8, et génère jusqu'à 2048 jetons pour chaque problème.
Voici comment la majorité des votes se sont comportés lorsqu'ils ont été appliqués à l'instructeur Llama 3.2 1B :
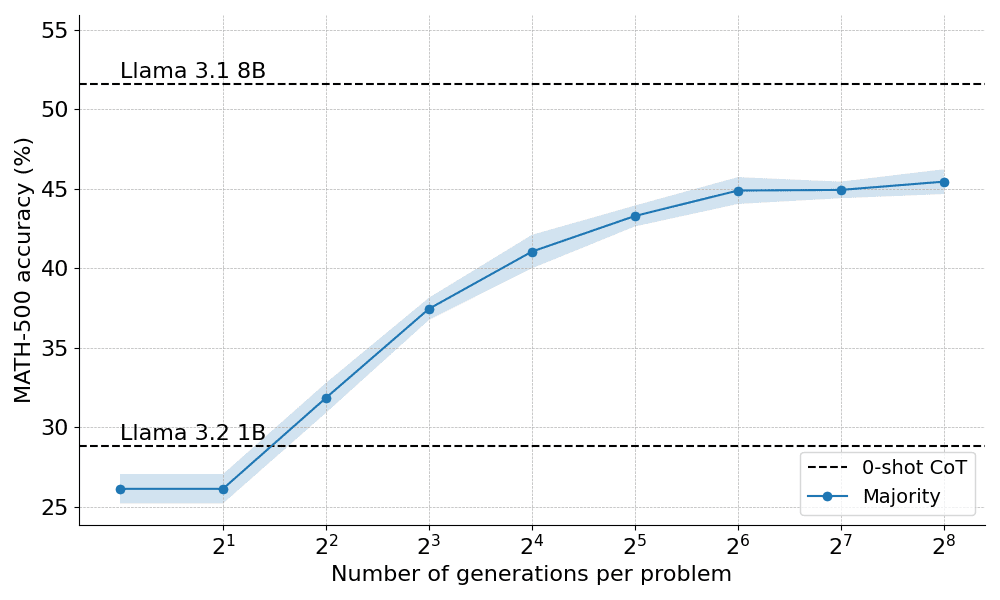
Les résultats montrent que le vote majoritaire apporte une amélioration significative par rapport à la ligne de base du décodage avide, mais que ses gains commencent à se stabiliser après environ N=64 générations. Cette limitation est due au fait que le vote majoritaire a du mal à résoudre les problèmes qui nécessitent un raisonnement minutieux.
Compte tenu des limites du vote à la majorité, voyons comment nous pouvons incorporer un modèle de récompense pour améliorer les performances.
Au-delà de la majorité : Best-of-N
Best-of-N est une extension simple et efficace de l'algorithme de vote majoritaire qui utilise un modèle de récompense pour déterminer la réponse la plus raisonnable. Il existe deux variantes principales de la méthode :
Best-of-N ordinaire : générer N réponses indépendantes et choisir celle qui a la récompense RM la plus élevée comme réponse finale. Cette méthode garantit le choix de la réponse la plus fiable, mais ne tient pas compte de la cohérence entre les réponses.
Best-of-N pondéré : résume les scores de toutes les réponses identiques et sélectionne celle dont la récompense totale est la plus élevée. Cette méthode donne la priorité aux réponses de haute qualité en augmentant le score par le biais d'occurrences répétées. Mathématiquement, les réponses sont pondérées a_i :
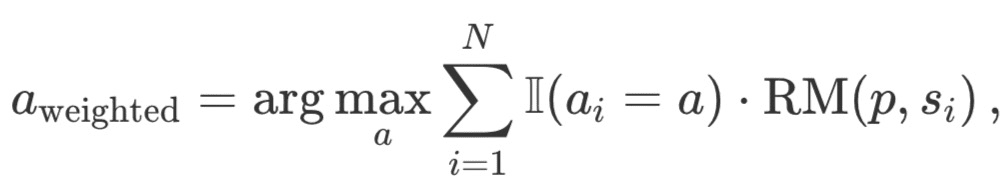
où RM (p,s_i) est le score du modèle de récompense pour la ième solution s_i du problème p.
En règle générale, on utilise le modèle de récompense des résultats (ORM) pour obtenir des scores au niveau des solutions individuelles. Toutefois, pour une comparaison équitable avec d'autres stratégies de recherche, le même MRP est utilisé pour noter les solutions Best-of-N. Comme le montre la figure ci-dessous, le MRP génère une séquence cumulative de scores au niveau des étapes pour chaque solution. Comme le montre la figure ci-dessous, le MRP génère une séquence cumulative de scores au niveau des étapes pour chaque solution, et les étapes doivent donc être notées statistiquement (de manière réductrice) pour obtenir des scores individuels au niveau de la solution :
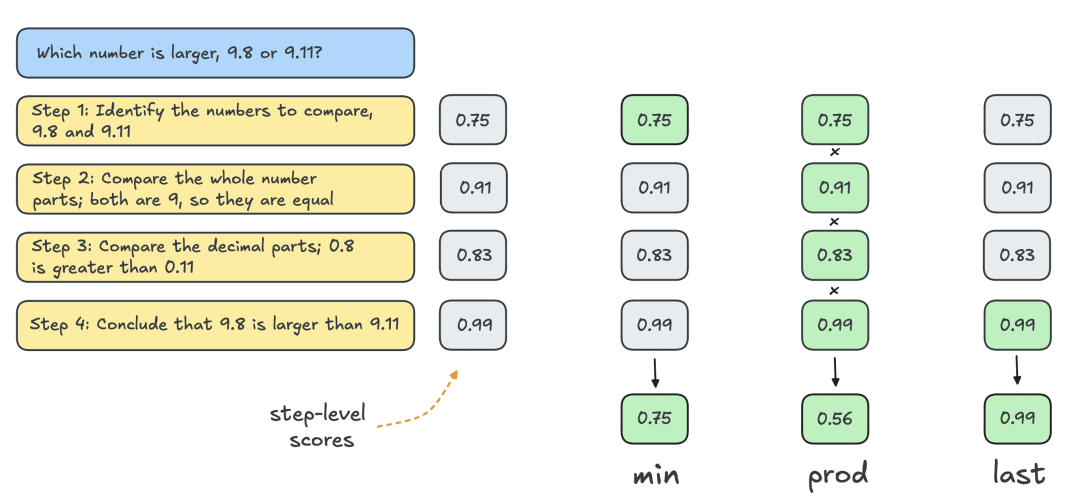
Les statuts les plus courants sont énumérés ci-dessous :
- Min : utiliser le score le plus bas de toutes les étapes.
- Prod : utiliser le produit de fractions échelonnées.
- Dernier : utilisez la note finale de l'étape. Cette note contient les informations cumulées de toutes les étapes précédentes. Il faut donc considérer le MRP comme un ORM capable de noter des solutions partielles.
Les résultats obtenus en appliquant les deux variantes de Best-of-N sont présentés ci-dessous :
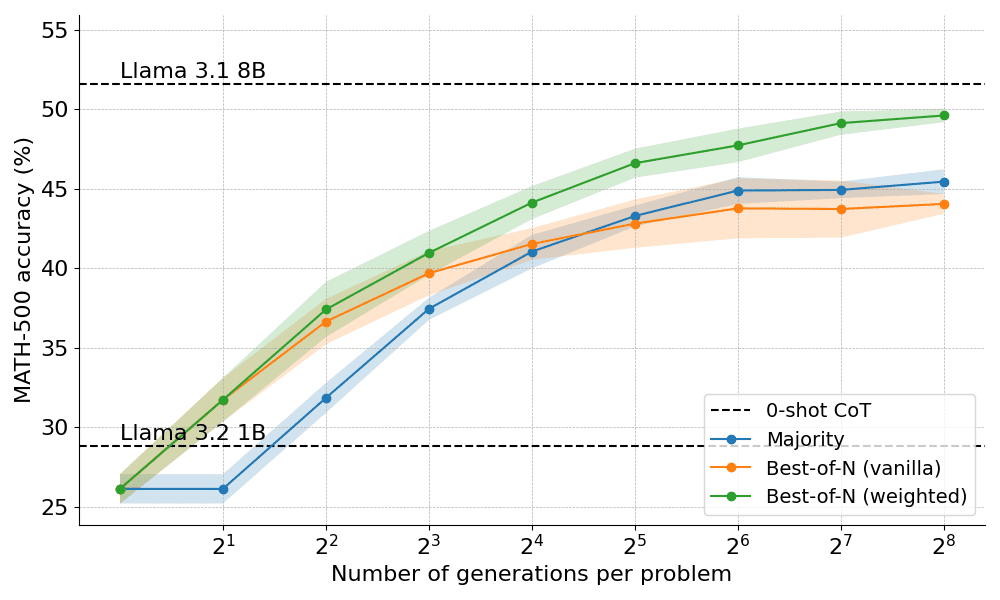
Les résultats révèlent un avantage évident : le Best-of-N pondéré surpasse systématiquement le Best-of-N normal, en particulier avec des budgets de génération plus importants. Sa capacité à agréger les scores des réponses identiques garantit que même les réponses moins fréquentes mais de meilleure qualité sont classées par ordre de priorité.
Cependant, malgré ces améliorations, elle reste en deçà des performances obtenues par le modèle Llama 8B et la méthode Best-of-N commence à se stabiliser à N=256.
Est-il possible de repousser les limites en contrôlant progressivement le processus de recherche ?
Recherche de grappes à l'aide du PRM
En tant que méthode de recherche structurée, la recherche par grappes permet l'exploration systématique de l'espace de solution, ce qui en fait un outil puissant pour améliorer les résultats des modèles au moment des tests. Lorsqu'elle est utilisée en conjonction avec la MPR, la recherche par grappes peut optimiser la génération et l'évaluation des étapes intermédiaires de la résolution de problèmes. La recherche par grappes fonctionne de la manière suivante :
- Plusieurs solutions candidates sont générées de manière itérative en conservant un nombre fixe de "grappes" ou de chemins actifs N .
- Dans la première itération, N étapes indépendantes sont prises à partir du LLM avec la température T pour introduire la diversité dans les réponses. Ces étapes sont généralement définies par un critère d'arrêt, par exemple la fin à la nouvelle ligne n ou le double de la nouvelle ligne nn.
- Chaque étape est évaluée à l'aide du MRP et les N/M meilleures étapes sont sélectionnées comme candidates pour le prochain cycle de génération. Ici, M représente la "largeur de la grappe" d'un chemin d'activité donné. Comme pour la méthode Best-of-N, le "dernier" statut est utilisé pour évaluer les solutions partielles pour chaque itération.
- Étendre les étapes sélectionnées à l'étape (3) en échantillonnant M étapes ultérieures de la solution.
- Répéter les étapes (3) et (4) jusqu'à ce que l'EOS soit atteint. jeton ou dépasse la profondeur de recherche maximale.
En permettant au MPR d'évaluer l'exactitude des étapes intermédiaires, la recherche par grappes peut identifier et hiérarchiser les chemins prometteurs dès le début du processus. Cette stratégie d'évaluation étape par étape est particulièrement utile pour les tâches de raisonnement complexes telles que les mathématiques, car la validation de solutions partielles peut améliorer considérablement le résultat final.
Détails de la mise en œuvre
Dans les expériences, HuggingFace a suivi la sélection d'hyperparamètres de DeepMind et a exécuté la recherche de grappes comme suit :
- Calculer N grappes lors d'une mise à l'échelle à 4, 16, 64, 256
- Largeur fixe de la grappe M=4
- Prélèvement à la température T=0,8
- Jusqu'à 40 itérations, c'est-à-dire un arbre d'une profondeur maximale de 40 pas.
Comme le montre la figure ci-dessous, les résultats sont stupéfiants : avec un budget de temps de test de N=4, la recherche par grappes atteint la même précision que Best-of-N avec N=16, c'est-à-dire une amélioration de 4 fois l'efficacité de calcul ! En outre, les performances de la recherche par grappes sont comparables à celles de Llama 3.1 8B, qui ne nécessite que N=32 solutions par problème. La performance moyenne des étudiants en doctorat d'informatique en mathématiques est d'environ 40%, de sorte que pour le modèle 1B, une performance proche de 55% est suffisante !
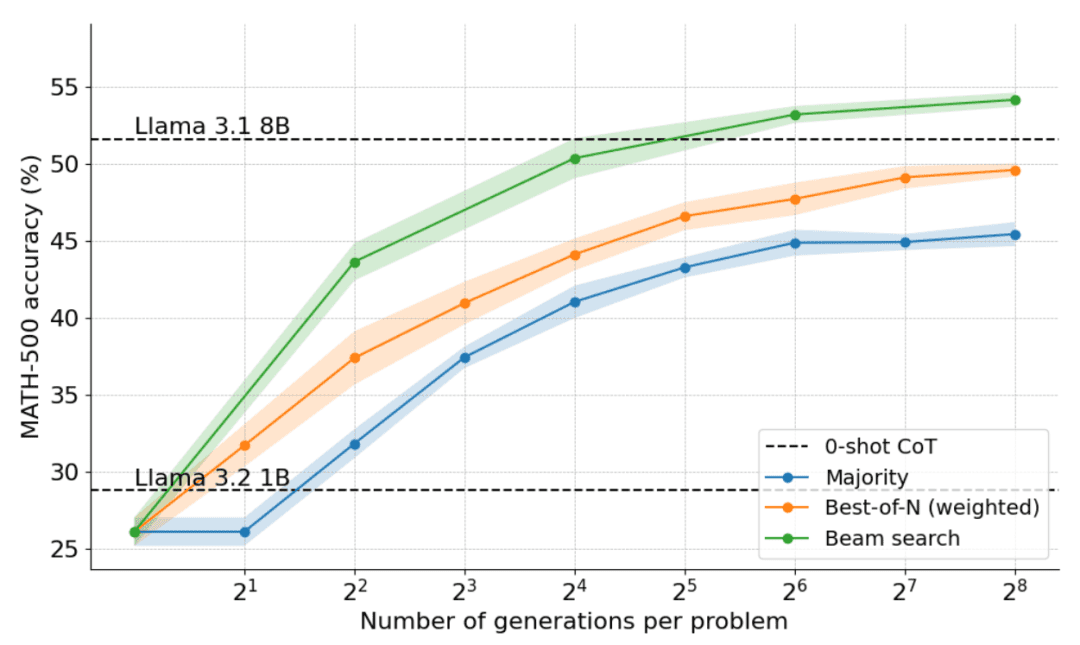
Quels sont les problèmes les mieux résolus par la recherche en grappes ?
S'il est clair que la recherche par grappes est une meilleure stratégie de recherche que la stratégie Best-of-N ou le vote majoritaire, l'article de DeepMind montre qu'il existe des compromis pour chaque stratégie, en fonction de la difficulté du problème et du budget de calcul au moment du test.
Pour comprendre quels problèmes conviennent le mieux à quelle stratégie, DeepMind a calculé la distribution de la difficulté estimée des problèmes et a divisé les résultats en quintiles. En d'autres termes, chaque problème a été classé dans l'un des cinq niveaux, le niveau 1 correspondant aux problèmes les plus faciles et le niveau 5 aux problèmes les plus difficiles. Pour estimer la difficulté du problème, DeepMind a généré 2048 solutions candidates pour chaque problème avec un échantillonnage standard et a ensuite proposé les heuristiques suivantes :
- Oracle : Estimer les scores de réussite@1 pour chaque question en utilisant des étiquettes de faits de base, et classer la distribution des scores de réussite@1 pour déterminer les quintiles.
- Modélisation : les quintiles sont déterminés à l'aide de la distribution des scores moyens au MRP pour chaque problème. L'intuition ici est que les questions plus difficiles auront des scores plus faibles.
La figure ci-dessous montre une répartition des différentes méthodes sur la base du score "pass@1" et du budget N=[4,16,64,256] calculé sur les quatre tests :
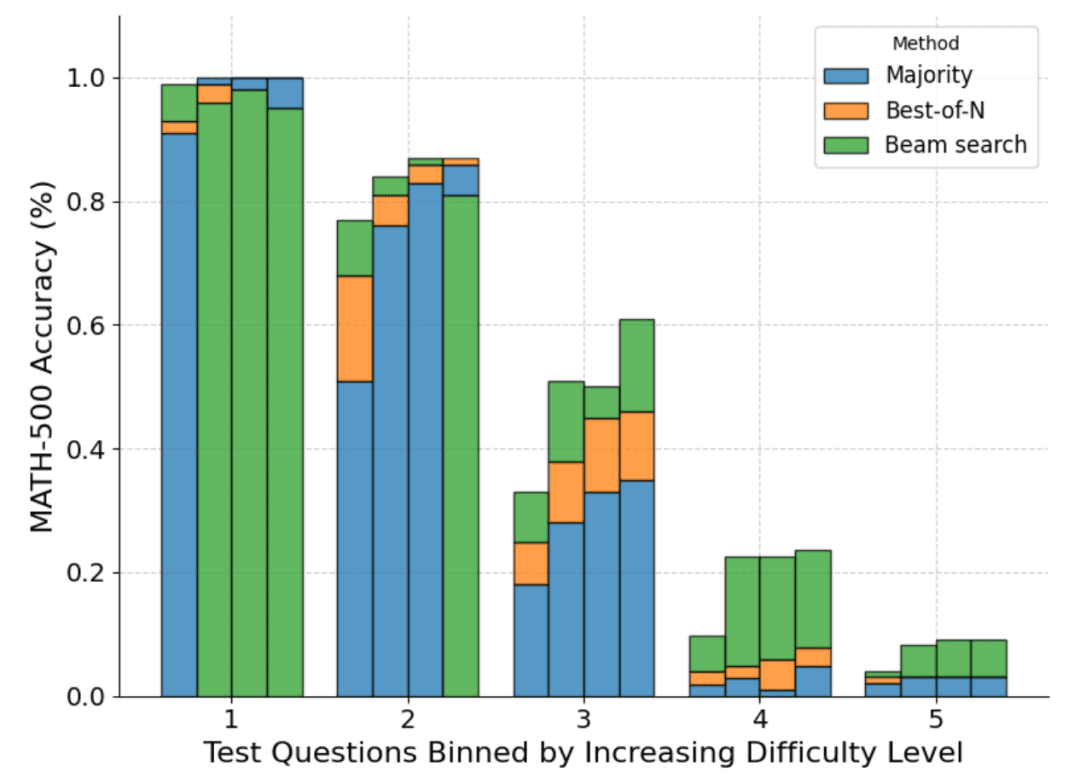
Comme on peut le voir, chaque barre représente le budget calculé au moment du test et la précision relative de chaque méthode est indiquée à l'intérieur de chaque barre. Par exemple, dans les quatre barres du niveau de difficulté 2 :
Le vote à la majorité est la méthode la moins performante pour tous les budgets de calcul, à l'exception de N=256 (la recherche par grappes est la moins performante).
La recherche par grappes est la meilleure pour N=[4,16,64], mais la méthode Best-of-N est la meilleure pour N=256.
Il convient de noter que la recherche par grappes a fait des progrès constants dans les problèmes de difficulté moyenne et difficile (niveaux 3 à 5), mais qu'elle a tendance à être moins performante que la méthode Best-of-N (ou même le vote à la majorité) pour les problèmes plus simples, en particulier avec des budgets de calcul plus importants.
En examinant l'arbre de résultats généré par la recherche par grappes, HuggingFace s'est rendu compte que si une seule étape se voyait attribuer une récompense élevée, l'ensemble de l'arbre s'effondrait sur cette trajectoire, ce qui affectait la diversité. Cette constatation les a incités à étudier une extension de la recherche par grappes qui maximise la diversité.
DVTS : Améliorer les performances grâce à la diversité
Comme nous l'avons vu ci-dessus, la recherche par grappes offre de meilleures performances que la recherche Best-of-N, mais a tendance à être moins performante lorsqu'il s'agit de problèmes simples et de budgets de calcul importants au moment de l'essai.
Pour résoudre ce problème, HuggingFace a développé une extension appelée "Diversity Validator Tree Search" (DVTS), qui vise à maximiser la diversité lorsque N est grand.
Le DVTS fonctionne de la même manière que la recherche en grappes, avec les modifications suivantes :
- Pour un N et un M donnés, l'ensemble initial est développé en sous-arbres N/M indépendants.
- Pour chaque sous-arbre, sélectionnez l'étape ayant le score PRM le plus élevé.
- Générer M nouvelles étapes à partir du nœud sélectionné à l'étape (2) et sélectionner l'étape ayant le score PRM le plus élevé.
- Répétez l'étape (3) jusqu'à ce que le jeton EOS ou la profondeur maximale de l'arbre soit atteint.
Le graphique suivant montre les résultats de l'application du DVTS au lama 1B :
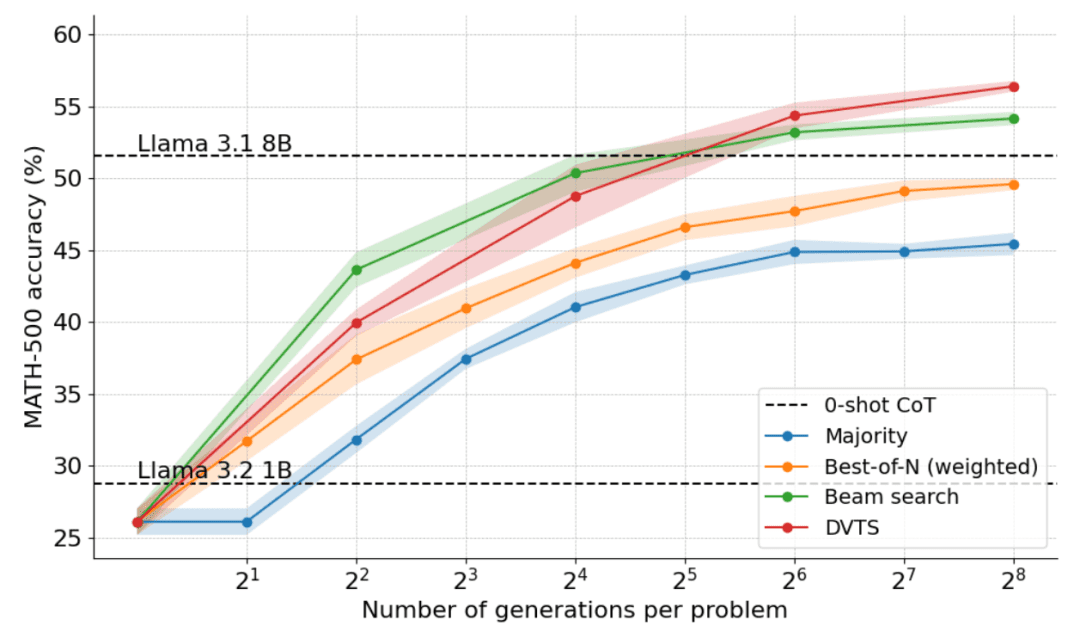
On constate que le DVTS constitue une stratégie complémentaire à la recherche par grappes : lorsque N est petit, la recherche par grappes est plus efficace pour trouver la bonne solution ; mais lorsque N est plus grand, la diversité des candidats DVTS entre en jeu et de meilleures performances peuvent être obtenues.
En outre, en ce qui concerne la répartition de la difficulté des problèmes, le DVTS améliore les performances des problèmes simples/moyens avec un grand N, tandis que la recherche par grappes donne les meilleurs résultats avec un petit N.
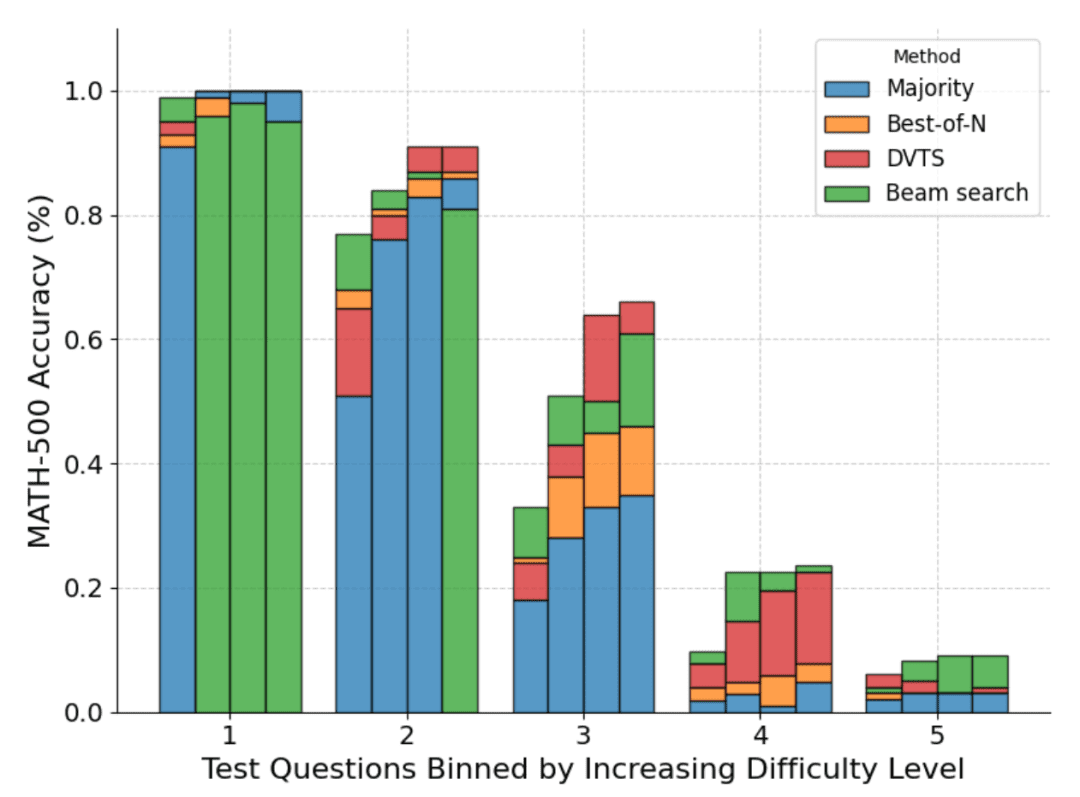
mise à l'échelle optimale (mise à l'échelle optimale)
Avec une grande variété de stratégies de recherche, une question naturelle est de savoir laquelle est la meilleure. Dans l'article de DeepMind (disponible sous le titre Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters ), ils proposent une stratégie de mise à l'échelle calculatoirement optimale qui sélectionne la méthode de recherche et l'hyper paramètre θ afin d'obtenir des performances optimales pour un budget de calcul donné N :
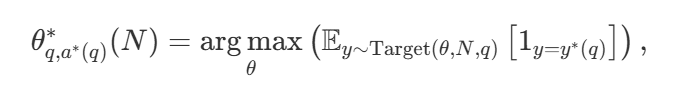
Parmi ceux-ci 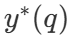 est la bonne réponse à la question q.
est la bonne réponse à la question q. 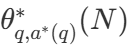 Calcul de représentation - Stratégie optimale de mise à l'échelle. Puisqu'il est facile de calculer
Calcul de représentation - Stratégie optimale de mise à l'échelle. Puisqu'il est facile de calculer 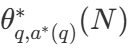 Quelque peu délicate, DeepMind propose une approximation basée sur la difficulté du problème, c'est-à-dire qu'elle alloue des ressources de calcul pendant les tests en fonction de la stratégie de recherche qui obtient les meilleures performances à un niveau de difficulté donné.
Quelque peu délicate, DeepMind propose une approximation basée sur la difficulté du problème, c'est-à-dire qu'elle alloue des ressources de calcul pendant les tests en fonction de la stratégie de recherche qui obtient les meilleures performances à un niveau de difficulté donné.
Par exemple, pour les problèmes les plus simples et les budgets de calcul les plus bas, il est préférable d'utiliser des stratégies telles que Best-of-N, tandis que pour les problèmes plus difficiles, la recherche ensembliste est un meilleur choix. La figure ci-dessous illustre la courbe d'optimisation des calculs !
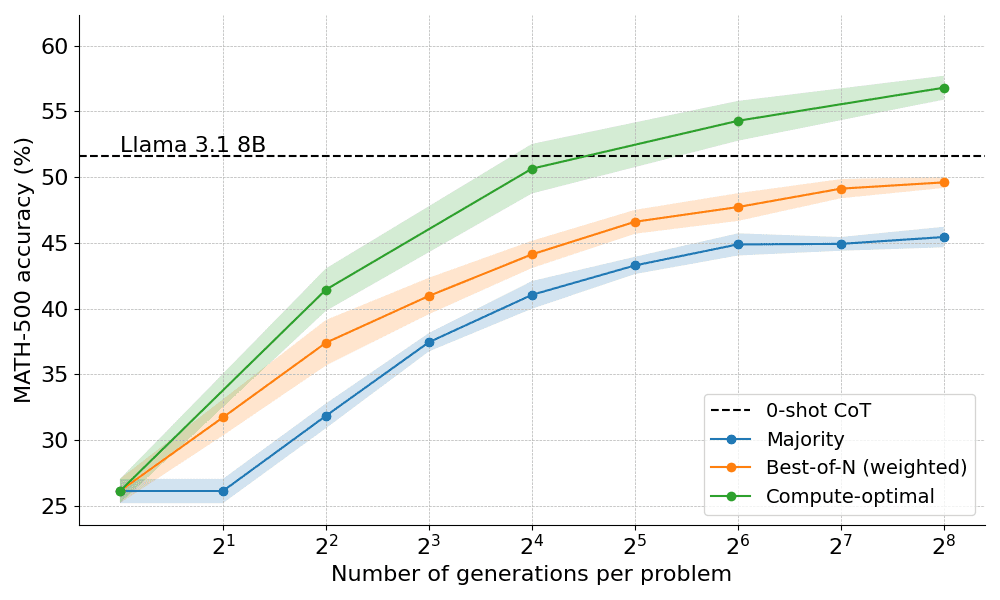
Extension à des modèles plus grands
Ce document explore également l'extension de l'approche calcul-optimale au modèle Llama 3.2 3B Instruct pour voir à partir de quel moment le MRP commence à s'affaiblir par rapport à la capacité de la politique elle-même. Les résultats montrent que l'extension optimale par calcul fonctionne très bien, le modèle 3B étant plus performant que le modèle Llama 3.1 70B Instruct (qui est 22 fois plus grand que le premier !). .

Quelle est la prochaine étape ?
L'exploration de la mise à l'échelle des calculs en temps de test révèle le potentiel et les défis de l'utilisation d'approches basées sur la recherche. Pour l'avenir, le présent document propose plusieurs orientations intéressantes :
- Validateurs solides : les validateurs solides jouent un rôle clé dans l'amélioration des performances, et l'amélioration de la robustesse et de la polyvalence des validateurs est essentielle pour faire progresser ces approches ;
- Autovalidation : l'objectif ultime est de parvenir à l'auto-validation, c'est-à-dire que le modèle puisse valider de manière autonome ses propres résultats. Cette approche semble être celle de modèles tels que o1, mais elle est encore difficile à réaliser dans la pratique. Contrairement au réglage fin supervisé standard (SFT), l'auto-validation nécessite une stratégie plus nuancée ;
- (a) Intégration de la réflexion dans le processus : l'intégration d'étapes intermédiaires explicites ou de la réflexion dans le processus génératif peut encore améliorer le raisonnement et la prise de décision. L'intégration d'un raisonnement structuré dans le processus de recherche permet d'obtenir de meilleures performances dans les tâches complexes ;
- La recherche en tant qu'outil de génération de données : la méthode peut également servir de processus puissant de génération de données pour créer des ensembles de données d'entraînement de haute qualité. Par exemple, la mise au point d'un modèle tel que Llama 1B sur la base des trajectoires correctes générées par la recherche peut apporter des avantages significatifs. Cette approche basée sur la stratégie est similaire à des techniques telles que ReST ou V-StaR, mais avec l'avantage supplémentaire de la recherche, offrant une direction prometteuse pour l'amélioration itérative ;
- Appel à davantage de MPR : il existe relativement peu de MPR, ce qui limite leur application à plus grande échelle. Le développement et le partage d'un plus grand nombre de MPR pour différents domaines est un domaine clé dans lequel la communauté peut apporter une contribution significative.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...